JAVA 学习 面试(八)集合类
集合类
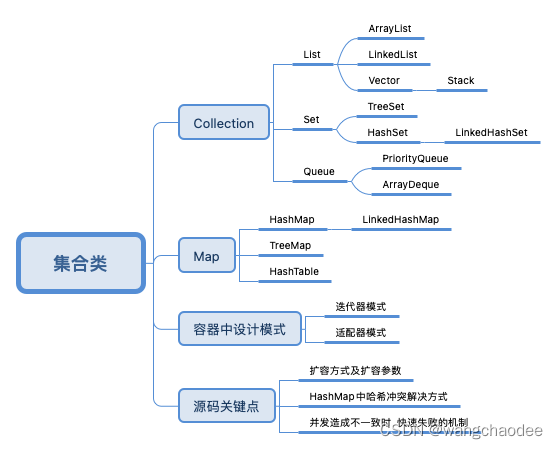
集合(Collection)
1、 List列表 : 有序 可重复
1、ArrayList : 数组列表 ,内部是通过Array实现,对数据列表进行插入、删除操作时都需要对数组进行拷贝并重排序,因此在知道存储数据量时,尽量初始化初始容量,提升性能 。
2、LinkedList : 双向链表 每个元素都有指向前后元素的指针,顺序读取的效率较高,随机读取的效率较低
3、Vector : 向量 , 线程安全的列表,与ArrayList 一样也是通过数组实现的
4、Stack : 栈 , 后进先出 LIFO , 继承自Vector,也是用数组,线程安全的栈
| 类型 | 底层实现 | 线程安全 | 扩容方式 | 特点 |
|---|---|---|---|---|
| ArrayList | 数组 | 否 | 初始容量是 10,扩容因子是 0.5 | 查询快,增删慢 |
| LinkedList | 链表 | 否 | 没有扩容的机制 | 查询慢,增删快 |
| Vector | 数组 | 是 | 默认初始容量为10,扩容因子是 1 | 查询快,增删慢 |
2、Queue队列:有序 可重复
1、ArrayDeque : 数组实现的的双端队列, 可以在队列两端插入和删除元素
2、LinkedList : 也属于双端队列
3、PriorityQueue : 优先队列 ,数组实现的二叉树, 完全二叉树实现的小顶堆(可改变比较方法)
3、Set集合: 无序 不重复
1、HashSet 基于哈希实现的集合, 链表形式
2、LinkedHashSet
3、TreeSet 红黑树结构
| 类型 | 底层实现 | 线程安全 | 扩容方式 | 特点 |
|---|---|---|---|---|
| HashSet | 基于HashMap实现 | 否 | 添加元素时,table数组扩容为16,加载因子为0.75 | 无序 |
| LinkedHashSet | 基于LinkedHashMap | 否 | 初始容量为16,临界值为12,以后再次扩容,扩容2倍 | 有序 |
| TreeSet | 基于TreeMap实现 | 否 | 容量翻倍 | 有序 |
集合(Collection)和数组的区别
- 2、数组的长度是固定的,集合长度是可以改变的,提供很多成员方法。
- 3、数组的存放的类型只能是一种(基本类型/引用类型),集合存放的类型可以不是一种(不加泛型时添加的类型是Object)。(当将元素放入集合时,它们会被转换成Object类型,之后在访问集合中的元素时需要进行强制类型转换。这种设计虽然方便,但也带来了类型不安全的隐患,以及类型转换的性能损失。)
- 4、数组是java语言中内置的数据类型,是线性排列的,执行效率或者类型检查都是最快的。
工具
- 遍历集合:Iterator 和 Enumeration
- 操作集合:Arrays 和 Collections
Map
1、HashMap 哈希映射 无序 , key 和 value 都可以为null
2、TreeMap 红黑树实现的, 可排序, 红黑树是一种自平衡二叉查找树
3、LinkedHashMap 链表映射 ,继承于HashMap,又实现了双向链表的特性 ,保留了元素插入顺序
| 类型 | 底层实现 | 线程安全 | 扩容方式 | 特点 |
|---|---|---|---|---|
| HashMap | 数组+红黑树 | 否 | 初始容量是 16,2倍扩容 | 无序集合 |
| LinkedHashMap | 基于HashMap,并自己维持了一个双向链表,按照插入顺序进行访问,实现了LRU算法 | 否 | 初始容量是 16,2倍扩容 | 有序集合 |
| CocurrentHashMap | Segments数组+ReentrantHashMap(作为互斥锁来控制并发访问)+链表,采用分段锁保证安全 | 是 | 链表元素超8个,数组大小超64,转红黑树 | 无序集合,性能比HashTable好 |
| HashTable | 数组+链表 | 是 | 初始大小为11,扩容为2n+1 | 无序集合 |
| TreeMap | 基于红黑树 | 不 | 2倍 | 有序集合 |
- List:有序、可重复。
- Set:无序、不可重复的集合。重复元素会覆盖掉。
- Map:键值对,键唯一、值不唯一。Map 集合中存储的是键值对,键不能重复,值可以重复。
LinkedHashMap
LinkedHashMap继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。在一些场景下,该特性很有用,比如缓存。
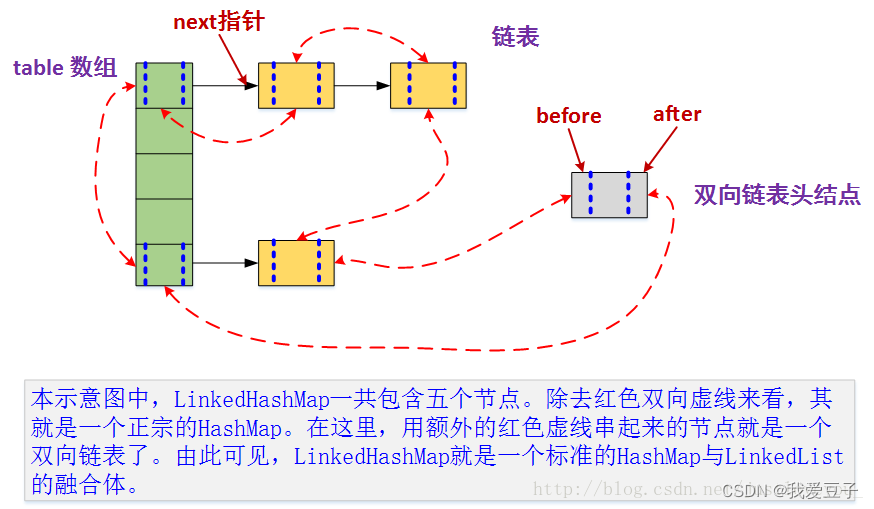
LinkedHashMap实现LRU
accessOrder用于决定具体的迭代顺序:
当accessOrder标志位为true时,put和get方法均有调用recordAccess方法,将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部,双向链表中的元素按照访问的先后顺序排列。
当标志位accessOrder的值为false时,只有put方法会调用recordAccess,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,按照Entry插入LinkedHashMap到中的先后顺序排序
public class LRU<K,V> extends LinkedHashMap<K, V> implements Map<K, V>{
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* @description 重写LinkedHashMap中的removeEldestEntry方法,当LRU中元素多余6个时,
* 删除最不经常使用的元素 **/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// TODO Auto-generated method stub
if(size() > 6){
return true;
}
return false;
}
public static void main(String[] args) {
LRU<Character, Integer> lru = new LRU<Character, Integer>(
16, 0.75f, true);
String s = "abcdefghijkl";
for (int i = 0; i < s.length(); i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key为h的Entry的值为: " + lru.get('h'));
System.out.println("LRU的大小 :" + lru.size());
System.out.println("LRU :" + lru);
}
}
hashMap和LinkedHashMap区别
- 插入顺序:HashMap不保证映射的顺序,而LinkedHashMap会根据元素插入的顺序维护一个双向链表,因此保证了映射的顺序,可以通过get操作访问元素的插入顺序。
迭代顺序:LinkedHashMap迭代元素的顺序是插入顺序,而HashMap的迭代顺序是随机的。性能:由于LinkedHashMap在底层额外维护了一个双向链表,因此在插入或删除元素时需要更多的操作,因此LinkedHashMap的性能通常比HashMap要低,内存占用通常比HashMap要高一些。
hashMap和TreeMap区别
插入顺序:HashMap不保证映射的顺序,而TreeMap会根据元素的键值进行排序,因此保证了映射的顺序。元素访问时间复杂度:HashMap的元素访问时间复杂度是常数级别的,即O(1),而TreeMap的元素访问时间复杂度是基于红黑树的复杂度,通常是O(log(n))。键的类型:HashMap可以使用任何类型的对象作为键,只要它们能正确的实现hashCode()和equals()方法,而TreeMap的键必须实现Comparable接口或提供自定义的Comparator比较器来进行比较。内存占用:由于TreeMap需要维护红黑树的结构,因此它的内存占用相对较高。而HashMap在元素较少时,占用内存较小。
HashMap原理
-
HashMap在Jdk1.8以后是基于数组+链表+红黑树来实现的,特点是,key不能重复,可以为null,线程不安全
-
HashMap的扩容机制:
HashMap的默认容量为16,默认的负载因子为0.75,当HashMap中元素个数超过容量乘以负载因子的个数时,就创建一个大小为前一次两倍的新数组,再将原来数组中的数据复制到新数组中。当数组长度到达64且链表长度大于8时,链表转为红黑树
- HashMap存取原理:
(1)计算key的hash值,然后进行二次hash,根据二次hash结果找到对应的索引位置
(2)如果这个位置有值,先进性equals比较,若结果为true则取代该元素,若结果为false,就使用高低位平移法将节点插入链表
- 为什么不一开始就使用红黑树?
? 因为直接采用红黑树的话每次加入元素需要进行平衡,而在超过8时再旋转变为红黑树可以达成平衡,因为大部分哈希槽的元素个数正态分布在8个左右,所以此时变为红黑树也满足了查找的效率。
- 想要线程安全的哈希表
(1)使用ConcurrentHashMap
(2)使用HashTable
(3)Collections.synchronizedHashMap()方法
## hash表:
构造:① 直接定址法;②平方取中法;③折叠法;④除留取余法
冲突解决:① 开放定址法(线性探测)② 链地址法
HashTable与HashMap的区别
-
(1)HashTable的每个方法都用synchronized修饰,因此是线程安全的,但同时读写效率很低
-
(2)HashTable的Key不允许为null
-
(3)HashTable只对key进行一次hash,HashMap进行了两次Hash
-
(4)HashTable底层使用的数组加链表
ConcurrenHashMap与HashTable的区别
ConcurrentHashMap性能更高,它基于分段锁+CAS 保证线程安全,分段锁基于 synchronized 实现,它仅仅锁住某个数组的某个槽位,而不是整个数组
- ConcurrentHashMap 没有大量使用
synchronsize这种重量级锁。而是在一些关键位置使用乐观锁(CAS), 线程可以无阻塞的运行。 - ConcurrentHashMap读方法没有加锁
- ConcurrentHashMap扩容时老数据的转移是并发执行的,这样扩容的效率更高。
ArrayList和LinkedList的区别
ArratList的底层使用动态数组,默认容量为10,当元素数量到达容量时,生成一个新的数组,大小为前一次的1.5倍,然后将原来的数组copy过来;
因为数组有索引,所以ArrayList查找数据更快,但是添加数据效率更低
LinkedList的底层使用链表,在内存中是离散的,没有扩容机制;LinkedList在查找数据时需要从头遍历,所以查找慢,但是添加数据效率更高
如何保证ArrayList的线程安全?
(1)使用collentions.synchronizedList()方法为ArrayList加锁
(2)使用Vector,Vector底层与Arraylist相同,但是每个方法都由synchronized修饰,速度很慢
在Queue接口中, poll() 和 remove() 方法都用于从队列中移除并返回队头的元素。
如果队列为空,即没有元素可供移除时, pol0 方法会返回null。它是一个安全的方法不会抛出异常。
remove()在没有元素可供移除时,会抛出NoSuchElementException 异常。
怎么确保集合不可更改?
Java 集合框架提供了一些不可变集合类,如不可变列表(ImmutableList)、不可变集合(ImmutableSet)和不可变映射(ImmutableMap)。
List<String> list = ImmutableList.of("a", "b", "c");
Set<String> set = ImmutableSet.of("x", "y", "z");
Map<String, Integer> map = ImmutableMap.of("a", 1, "b", 2, "c", 3);
List<String> list2 = ImmutableList.<String>builder().addAll(list1).add("d").build();
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Spring Cloud】组件概念详解
- springboot 学生信息管理
- 互联网加竞赛 python+大数据校园卡数据分析
- cmd命令指南
- Java 设计模式
- YOLO在深度学习视觉应用中的使用场景与部署
- 从vue小白到高手,从一个内容管理网站开始实战开发第九天,登录功能后台功能设计--业务逻辑层基础接口和基础服务实现
- django高校毕业班校务管理系统(程序+开题报告)
- react中使用ref属性获取元素,并判断该元素内是否含有子元素
- SSM—Mybatis