Flink|《Flink 官方文档 - DataStream API - 算子 - 概览》学习笔记
学习文档:《Flink 官方文档 - DataStream API - 算子 - 概览》
学习笔记如下:
算子:能将一个或多个 DataStream 转换成新的 DataStream,在应用程序中可以将多个数据转换算子合并成一个复杂的数据流拓扑。
数据流转换类算子
Map(DataStream → DataStream)
输入一个元素同时输出一个元素。
样例:将输入流中的元素加倍
DataStream<Integer> dataStream = //... dataStream.map(new MapFunction<Integer, Integer>() { @Override public Integer map(Integer value) throws Exception { return 2 * value; } });
FlatMap(DataStream → DataStream)
输入一个元素同时产生零个、一个或多个元素。
示例:将句子根据空格拆分为单词
dataStream.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { for(String word: value.split(" ")){ out.collect(word); } } });
Filter(DataStream → DataStream)
为每个元素执行一个布尔 function,并保留那些 function 输出值为 true 的元素。
示例:过滤掉零值
dataStream.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value != 0; } });
KeyBy(DataStream → KeyedStream)
在逻辑上将流划分为不相交的分区。具有相同 key 的记录都分配到同一个分区。在内部, keyBy() 是通过哈希分区实现的。
示例:根据
value.getSomeKey()的返回值分区dataStream.keyBy(value -> value.getSomeKey());
示例:根据元组的第 0 个元素分区
dataStream.keyBy(value -> value.f0);
需要注意的是:没有重写 hashCode() 方法的 POJO 类以及任意类的数组均不能作为 key。
Reduce(KeyedStream → DataStream)
在相同 key 的数据流上 “滚动” 执行 reduce。将当前元素与最后一次 reduce 得到的值组合然后输出新值。
示例:按 key 局部求和
keyedStream.reduce(new ReduceFunction<Integer>() { @Override public Integer reduce(Integer value1, Integer value2) throws Exception { return value1 + value2; } });
Window(KeyedStream → WindowedStream)
可以在已经分区的 KeyedStreams 上定义 Window。Window 根据某些特征(例如,最近 5 秒内到达的数据)对每个 key Stream 中的数据进行分组。
示例:按 5 秒的滚动窗口构建窗口
dataStream .keyBy(value -> value.f0) .window(TumblingEventTimeWindows.of(Time.seconds(5)));
WindowAll(DataStream → AllWindowedStream)
可以在普通 DataStream 上定义 Window。Window 根据某些特征(例如,最近 5 秒内到达的数据)对所有流事件进行分组。这适用于 非并行 转换的大多数场景,所有记录都将收集到 windowAll 算子对应的一个任务中。
示例:按 5 秒的滚动窗口构建窗口
dataStream .windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
Window Apply(WindowedStream → DataStream 或 AllWindowedStream → DataStream)
将通用 function 应用于整个窗口。如果处理 WindowedStream 流,则使用 WindowFunction 方法;如果处理 AllWindowedStream 流,则使用 AllWindowFunction 方法。
示例:在 windowedStream 中对窗口内元素求和
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() { public void apply (Tuple tuple, Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception { int sum = 0; for (value t: values) { sum += t.f1; } out.collect (new Integer(sum)); } });
示例:在 AllWindowedStream 中对窗口内元素求和
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() { public void apply (Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception { int sum = 0; for (value t: values) { sum += t.f1; } out.collect (new Integer(sum)); } });
WindowReduce(WindowedStream → DataStream)
对窗口应用 reduce function 并返回 reduce 后的值。
示例:对窗口内元素求和
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() { public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception { return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1); } });
Union(DataStream* → DataStream)
将两个或多个数据流联合来创建一个包含所有流中数据的新流。如果一个数据流和自身进行联合,这个流中的每个数据将在合并后的流中出现两次。
示例:合并数据流
otherStream1和otherStream2dataStream.union(otherStream1, otherStream2, ...);
Window Join(DataStream,DataStream → DataStream)
根据指定的 key 和窗口 join 两个数据流。
示例:根据两个
<key select>的规则,按 3 秒中的滚动窗口,JOIN 数据流dataStream和数据流otherStreamdataStream.join(otherStream) .where(<key selector>).equalTo(<key selector>) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply (new JoinFunction () {...});
Interval Join(KeyedStream,KeyedStream → DataStream)
根据 key 相等并且满足指定的时间范围内(e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound)的条件将分别属于两个 keyed stream 的元素 e1 和 e2 Join 在一起。
示例:将数据流 keyedStream 和 otherKeyedStream 使用 key 关联起来
// this will join the two streams so that // key1 == key2 && leftTs - 2 < rightTs < leftTs + 2 keyedStream.intervalJoin(otherKeyedStream) .between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper bound .upperBoundExclusive(true) // optional .lowerBoundExclusive(true) // optional .process(new IntervalJoinFunction() {...});其中
upperBoundExclusive(true)标识不包括上界,lowerBoundExclusive(true)表示不包括下界。
Window CoGroup(DataStream,DataStream → DataStream)
根据指定的 key 和窗口将两个数据流组合在一起。
示例:将数据流
dataStream和otherStream使用 3 秒的时间窗口关联起来dataStream.coGroup(otherStream) .where(0).equalTo(1) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply (new CoGroupFunction () {...});
Connect(DataStream,DataStream → ConnectedStream)
“连接” 两个数据流并保留各自的类型。connect 允许在两个流的处理逻辑之间共享状态。
示例:连接数据流
someStream和otherStreamDataStream<Integer> someStream = //... DataStream<String> otherStream = //... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
CoMap(ConnectedStream → DataStream)
类似于在连接的数据流上进行 map。
示例:
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() { @Override public Boolean map1(Integer value) { return true; } @Override public Boolean map2(String value) { return false; } });
CoFlatMap(ConnectedStream → DataStream)
类似于在连接的数据流上进行 flatMap。
示例:
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() { @Override public void flatMap1(Integer value, Collector<String> out) { out.collect(value.toString()); } @Override public void flatMap2(String value, Collector<String> out) { for (String word: value.split(" ")) { out.collect(word); } } });
Iterate(DataStream → IterativeStream → ConnectedStream)
通过将一个算子的输出重定向到某个之前的算子来在流中创建 “反馈” 循环。这对于定义持续更新模型的算法特别有用。下面的代码从一个流开始,并不断地应用迭代自身。大于 0 的元素被发送回反馈通道,其余元素被转发到下游。
示例:从
initialStream流开始,不断地迭代自身,将大于 0 的元素发送到回反馈通道,并将其他元素转发到下游output。IterativeStream<Long> iteration = initialStream.iterate(); DataStream<Long> iterationBody = iteration.map (/*do something*/); DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){ @Override public boolean filter(Long value) throws Exception { return value > 0; } }); iteration.closeWith(feedback); DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){ @Override public boolean filter(Long value) throws Exception { return value <= 0; } });
Cache(DataStream → CachedDataStream)
把算子的结果缓存起来(仅支持批执行模式下运行的作业)。算子的结果在算子第一次执行的时候会被缓存起来,之后的作业中会复用该算子缓存的结果。如果算子的结果丢失了,它会被原来的算子重新计算并缓存。
示例:
DataStream<Integer> dataStream = //... CachedDataStream<Integer> cachedDataStream = dataStream.cache(); cachedDataStream.print(); // Do anything with the cachedDataStream ... env.execute(); // Execute and create cache. cachedDataStream.print(); // Consume cached result. env.execute();
调整数据分区的算子
自定义分区(DataStream → DataStream)
使用用户定义的分区键(partitioner)进行重分区(即为每个元素选择目标任务)。
示例:
dataStream.partitionCustom(partitioner, "someKey");dataStream.partitionCustom(partitioner, 0);
随机重分区(DataStream → DataStream)
将元素随机地均匀划分到分区。
示例:
dataStream.shuffle();
调整并行度 Rescaling(DataStream → DataStream)
将元素以 Round-robin 轮询的方式分发到下游算子。上游算子将元素发往哪些下游的算子实例集合同时取决于上游和下游算子的并行度。例如,如果上游算子并行度为 2,下游算子的并行度为 6,那么上游算子的其中一个并行实例会将数据分发到下游算子的三个并行实例, 另外一个上游算子的并行实例则将数据分发到下游算子的另外三个并行实例中。再如,当下游算子的并行度为2,而上游算子的并行度为 6 的时候,那么上游算子中的三个并行实例将会分发数据至下游算子的其中一个并行实例,而另外三个上游算子的并行实例则将数据分发至另下游算子的另外一个并行实例。
当算子的并行度不是彼此的倍数时,一个或多个下游算子将从上游算子获取到不同数量的输入。
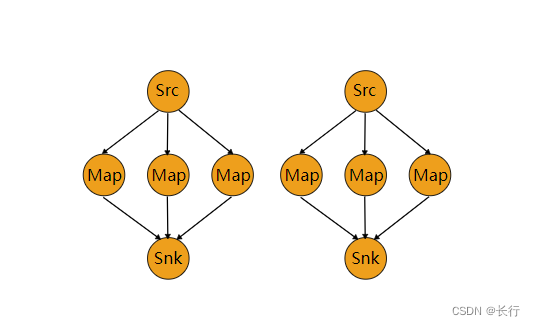
示例:
dataStream.rescale();
广播(DataStream → DataStream)
将元素广播到每个分区 。
示例:
dataStream.broadcast();
算子链和资源组
将两个算子链接在一起能使得它们在同一个线程中执行,从而提升性能。Flink 默认会将能链接的算子尽可能地进行链接,例如链接两个 map 转换操作。
同时,Flink 也提供了对链接更细粒度控制的 API 以满足更多需求:
示例:对整个作业禁用算子链
StreamExecutionEnvironment.disableOperatorChaining()
创建新链(只能在 DataStream 转换操作后调用,对前一次数据转换生效)
基于当前算子创建一个新的算子链。
示例:后面两个 map 将被链接起来,而 filter 和第一个 map 不会链接在一起
someStream.filter(...).map(...).startNewChain().map(...);
禁止链接(只能在 DataStream 转换操作后调用,对前一次数据转换生效)
示例:禁止和 map 算子链接在一起
someStream.map(...).disableChaining();
配置 Slot 共享组(只能在 DataStream 转换操作后调用,对前一次数据转换生效)
为某个算子设置 slot 共享组。Flink 会将同一个 slot 共享组的算子放在同一个 slot 中,而将不在同一 slot 共享组的算子保留在其它 slot 中。这可用于隔离 slot 。如果所有输入算子都属于同一个 slot 共享组,那么 slot 共享组从继承输入算子所在的 slot。slot 共享组的默认名称是 “default”,可以调用 slotSharingGroup("default") 来显式地将算子放入该组。
示例:将 filter 算子放到名为 name 的 slot 共享组
someStream.filter(...).slotSharingGroup("name");
名字和描述
Flink 里的算子和作业节点会有一个名字和一个描述。名字和描述都是用来介绍一个算子或者节点是在做什么操作,但是他们会被用在不同地方。
名字会用在用户界面、线程名、日志、指标等场景,因此名字需要尽可能的简洁,避免对外部系统产生大的压力。节点的名字会根据节点中算子的名字来构建。
描述主要用在执行计划展示,以及用户界面展示。节点的描述同样是根据节点中算子的描述来构建。描述可以包括详细的算子行为的信息,以便我们在运行时进行 debug 分析。
示例:为 filter 算子设置名字和描述
someStream.filter(...).name("filter").setDescription("x in (1, 2, 3, 4) and y > 1");
相关设置:
pipeline.vertex-description-mode = CASCADING:使用老版本的单行递归模式的描述,而不是多行的树形结构table.exec.simplify-operator-name-enabled = false:将名字改为和以前版本一样的详细描述,而不是由算子类型以及 id 构成的名字pipeline.vertex-name-include-index-prefix = true:在节点的名字前增加一个拓扑序的前缀,适用于作业拓扑很复杂的场景
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!