gem5学习(10):创建一个简单的配置脚本——Creating a simple configuration script
目录
(2) Syscall Emulation vs Full System
官方教程:gem5: Creating a simple configuration script
教程(9)中已经完成了一个简单的模拟脚本,并首次运行了gem5。此时我们已经成功构建了带有可执行文件build/X86/gem5.opt的gem5。
本教程中的配置脚本将模拟一个非常简单的系统,只有一个简单的CPU核心。这个CPU核心将连接到一个系统级的内存总线。还有一个单独的DDR3内存通道,连接到内存总线。
一、gem5 configuration scripts
gem5二进制文件(gem5 binary)接受一个Python脚本作为参数,该脚本用于设置和执行模拟。在这个脚本中,可以创建要模拟的系统,并创建系统的所有组件,并为这些组件指定参数。然后,可以通过脚本开始模拟。
这个脚本完全由用户定义,可以选择使用任何有效的Python代码来编写配置脚本。gem5中附带了一些示例配置脚本,位于configs/examples目录下(但是部分已经被弃用,无法运行了)。这些脚本通常包含了各种选项的设置。本教程将从一个最简单的脚本开始,并逐步扩展。通过本节的学习,对模拟脚本的工作原理有一个大概的了解。


1、An aside on SimObjects
关于SimObjects的一点说明
gem5的模块化设计是围绕SimObject类构建的。模拟系统中的大多数组件都是SimObjects:CPU、缓存、内存控制器、总线等等(CPUs, caches, memory controllers, buses, etc)。gem5将所有这些对象从它们的C++实现导出到Python。因此,从Python配置脚本中,可以创建任何SimObject,设置其参数,并指定SimObjects之间的交互。
二、Creating a config file
说明:本文中使用的配置脚本在configs/learning_gem5/part1/目录中,名称为simple.py。
接下来就是配置文件的内容。
这只是一个普通的Python文件,将由gem5可执行文件中的嵌入式Python执行。因此,可以使用Python中可用的任何功能和库。
1、导入m5库和SimObjects
在这个文件中,首先要导入m5库和需要编译的所有SimObjects。
import m5
from m5.objects import *2、创建模拟系统
接下来,将创建第一个SimObject:要模拟的系统。System对象是模拟系统中所有其他对象的父对象。System对象包含许多功能性(而非时序级别)的信息,例如物理内存范围、根时钟域、根电压域、内核(在全系统模拟中)等。要创建系统SimObject,只需像创建普通的Python类一样实例化。
system = System()3、设置系统时钟
现在有了要模拟的系统的引用,可以设置系统的时钟。首先需要创建一个时钟域,然后在该域上设置时钟频率。设置SimObject的参数与在Python中设置对象成员完全相同,因此可以简单地将时钟设置为1 GHz。最后,需要为该时钟域指定一个电压域。由于目前不关注系统功耗,可以使用电压域的默认选项。
system.clk_domain = SrcClockDomain()
system.clk_domain.clock = '1GHz'
system.clk_domain.voltage_domain = VoltageDomain()4、设置内存模拟方式
一旦有了系统,设置内存的模拟方式。除非在特殊情况下(快进和从检查点恢复),使用时序模式进行内存模拟几乎是标准做法。设置一个大小为512MB的单个内存范围,这是一个非常小的系统。在Python配置脚本中,当需要指定大小时,可以使用常见的语言和单位,如'512MB'。同样,对于时间,可以使用时间单位(例如'5ns')。它们将自动转换为通用的表示形式。
system.mem_mode = 'timing'
system.mem_ranges = [AddrRange('512MB')]5、创建CPU
现在可以创建一个CPU。从gem5中最简单的基于时序的X86 ISA CPU,即X86TimingSimpleCPU开始。该CPU模型会在一个时钟周期内执行每条指令,除了通过内存系统的内存请求。要创建CPU,只需实例化该对象即可。
说明:这个X86TimingSimpleCPU类的实现在/src/arch/x86/X86CPU.py中被定义,所以可以直接用来实例化。
system.cpu = X86TimingSimpleCPU()如果我们想使用RISCV ISA,可以使用RiscvTimingSimpleCPU(已经定义并实现),如果想使用ARM ISA,可以使用ArmTimingSimpleCPU。但是在这个示例中,我们将继续使用X86 ISA。
6、创建系统级内存总线
(system-wide memory bus)
system.membus = SystemXBar()7、连接请求-响应端口
现在有了一个内存总线,将CPU上的缓存端口连接到它上面。在这种情况下,由于要模拟的系统没有任何缓存,将I-cache和D-cache端口直接连接到内存总线上。在这个示例系统中,没有缓存。
system.cpu.icache_port = system.membus.cpu_side_ports
system.cpu.dcache_port = system.membus.cpu_side_ports(1)An aside on SimObjects
连接内存系统组件时,gem5使用端口抽象。每个内存对象可以拥有两种类型的端口:请求端口和响应端口。请求从请求端口发送到响应端口,响应从响应端口发送到请求端口。在连接端口时,需要将请求端口连接到响应端口。
从Python配置文件中连接端口非常简单。只需将请求端口设置为响应端口,它们就会自动连接在一起。
system.cpu.icache_port = system.l1_cache.cpu_side在这个示例中,CPU的icache_port是一个请求端口,缓存的cpu_side是一个响应端口。请求端口和响应端口可以在=的任一侧,进行连接。建立连接后,请求者可以向响应者发送请求。在gem5的Python配置中,
=操作符有一个有趣的特性,可以在一侧使用一个端口,而在另一侧使用一个端口数组。
system.cpu.icache_port = system.membus.cpu_side_ports在这个示例中,CPU的icache_port是一个请求端口,membus的cpu_side_ports是一个响应端口的数组。在这种情况下,会在cpu_side_ports上生成一个新的响应端口,并将这个新创建的端口与请求端口连接起来。
更多端口说明:
gem5学习(7):内存系统中创建 SimObjects--Creating SimObjects in the memory system-CSDN博客
8、连接其他端口
接下来,需要连接几个其他的端口,以确保系统能够正确运行。需要在CPU上创建一个I/O控制器,并将其连接到内存总线。此外,还需要将系统中的一个特殊端口连接到内存总线上。这个端口是一个仅用于功能的端口,允许系统读写内存。
将PIO和中断端口连接到内存总线是x86特定的要求。其他ISA(例如ARM)不需要这三行额外的连接。
system.cpu.createInterruptController()
system.cpu.interrupts[0].pio = system.membus.mem_side_ports
system.cpu.interrupts[0].int_requestor = system.membus.cpu_side_ports
system.cpu.interrupts[0].int_responder = system.membus.mem_side_ports
system.system_port = system.membus.cpu_side_ports9、创建内存控制器并连接到内存总线
接下来,需要创建一个内存控制器并将其连接到内存总线。对于这个系统,使用一个简单的DDR3控制器,它将负责系统的整个内存范围。
system.mem_ctrl = MemCtrl()
system.mem_ctrl.dram = DDR3_1600_8x8()
system.mem_ctrl.dram.range = system.mem_ranges[0]
system.mem_ctrl.port = system.membus.mem_side_ports完成了最后的连接后,就已经完成了模拟系统的实例化。系统应该如下图所示。

接下来,需要设置CPU要执行的进程。由于我们是在系统调用仿真模式(SE模式)下执行,只需将CPU指向编译后的可执行文件即可。
gem5已经附带了一个已编译的程序(tests/test-progs/hello/bin/x86/linux/hello),可以直接使用。该程序为一个简单的“Hello world”程序。或者用户可以指定任何为x86构建并进行静态编译的应用程序。
(2) Syscall Emulation vs Full System
gem5可以在两种不同的模式下运行,分别称为“系统调用仿真”模式和“完整系统”模式,也称为SE模式和FS模式。在完整系统模式下,gem5模拟整个硬件系统,并运行未经修改的内核。完整系统模式类似于运行虚拟机。
另一方面,系统调用仿真模式不会模拟系统中的所有设备,而是专注于模拟CPU和内存系统。系统调用仿真模式的配置更加简单,因为不需要实例化实际系统中所需的所有硬件设备。然而,系统调用仿真只模拟Linux系统调用,因此只模拟用户模式代码。
如果您的研究问题不需要模拟操作系统,并且需要更高的性能,应该使用SE模式。然而,如果您需要对系统进行高保真建模,或者像页表遍历这样的操作系统交互很重要,那么应该使用FS模式。
10、创建进程
首先,需要创建进程process(另一个SimObject)。然后,将进程的命令设置为要运行的命令。这是一个类似于argv的列表,第一个位置是可执行文件,列表的其余部分是可执行文件的参数。然后,将CPU设置为使用该进程作为其工作负载,并在CPU中创建功能执行上下文。
binary = 'tests/test-progs/hello/bin/x86/linux/hello'
# for gem5 V21 and beyond
system.workload = SEWorkload.init_compatible(binary)
process = Process()
process.cmd = [binary]
system.cpu.workload = process
system.cpu.createThreads()11、实例化系统并执行
最后,需要实例化系统并开始执行。首先,创建Root对象。然后,实例化仿真。实例化过程会遍历在Python中创建的所有SimObjects,并创建对应的C++对象【进一步理解:Gem5的实例化过程会遍历所有在Python中创建的SimObjects,并为每个SimObject创建对应的C++对象。这个过程通过调用每个SimObject的构造函数来完成。构造函数是一个特殊的方法,用于初始化对象并设置其属性。在构造函数中,gem5会根据SimObject的定义,初始化C++对象并将其与相应的SimObject关联起来。】。
需要注意的是,不必先实例化Python类,然后将参数显式指定为成员变量。也可以将参数作为命名参数传递,就像下面的Root对象一样。
root = Root(full_system = False, system = system)
m5.instantiate()12、实际仿真
gem5现在使用的是Python 3风格的打印函数,因此print不再是一个语句,而是必须作为函数调用。
print("Beginning simulation!")
exit_event = m5.simulate()13、检查系统状态
当仿真完成后,可以检查系统的状态
print('Exiting @ tick {} because {}'
.format(m5.curTick(), exit_event.getCause()))三、Running gem5
gem5可以接受许多参数,但只需要一个位置参数,即仿真脚本。因此,可以直接从gem5的根目录运行gem5。
build/X86/gem5.debug configs/learning_gem5/part1/simple.py结果
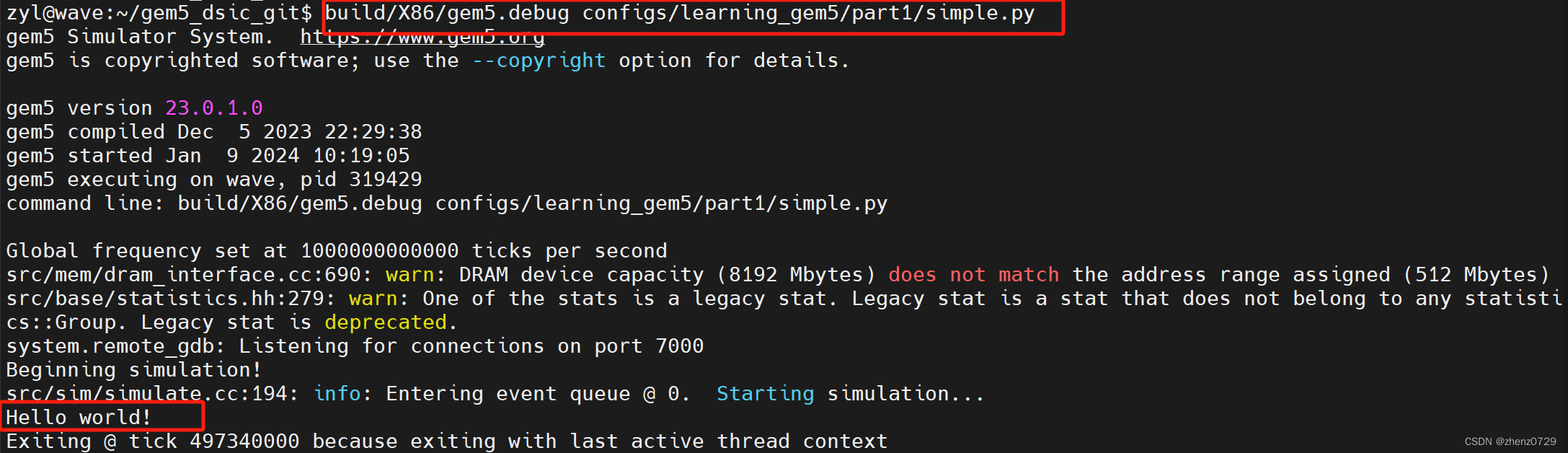
ISAs和CPU types的其他说明
配置文件中的参数可以更改,从而产生不同的结果。例如,如果将系统时钟加倍,仿真的完成时间应该更快。或者,如果将DDR控制器更改为DDR4,性能应该会更好。
另外,可以将CPU模型更改为X86MinorCPU以模拟顺序执行的CPU,或者更改为X86O3CPU以模拟乱序执行的CPU。注意,X86O3CPU目前无法与simple.py一起使用,因为X86O3CPU需要一个具有单独的指令和数据缓存的系统。
gem5的所有BaseCPU都采用{ISA}{Type}CPU的命名格式。因此,如果想要一个RISCV的Minor CPU,可以使用RiscvMinorCPU。
The Valid ISAs are:
- Riscv——RISC-V(RISC Five)是一种基于精简指令集计算机(RISC)原则的开放指令集架构(ISA)。它具有可扩展性和可配置性,可以适应不同的应用和系统需求。RISC-V的架构是模块化的,提供了基本的指令集和可选的扩展指令集,可以根据需求进行定制。
- Arm——ARM(Advanced RISC Machines)是一种广泛使用的32位和64位指令集架构,被广泛应用于移动设备、嵌入式系统和低功耗应用。ARM架构具有高效的能耗管理和出色的性能,适用于广泛的应用领域。
- X86——x86是一种基于复杂指令集计算机(CISC)架构的指令集,主要用于个人计算机和服务器领域。x86架构最初由Intel开发,后来被AMD等公司广泛采用。x86架构具有广泛的软件支持和丰富的生态系统。
- Sparc——SPARC(Scalable Processor Architecture)是一种RISC指令集架构,最初由Sun Microsystems开发。SPARC架构在服务器和高性能计算领域具有一定的影响力,具备可扩展性和高性能特点。
- Power——Power架构(以前称为PowerPC)是一种RISC指令集架构,最初由IBM、Motorola和Apple共同开发。Power架构广泛应用于服务器、超级计算机和嵌入式领域,具有高性能和可靠性。
- Mips——MIPS(Microprocessor without Interlocked Pipeline Stages)是一种RISC架构的指令集,最初由美国斯坦福大学开发。MIPS架构在嵌入式领域被广泛采用,具有简单、高效的特点。
这些ISA之间的主要区别在于其指令集的设计和特点,包括指令的类型、寻址模式、寄存器数量、编码方式等
The CPU types are:
- AtomicSimpleCPU——这是一个简单的原子CPU模型,它执行指令的过程是原子的,不考虑任何流水线或乱序执行的优化。它适用于对性能要求不高的简单任务。
- O3CPU——这是一个乱序执行的CPU模型,它使用了乱序执行和流水线技术来提高指令级并行性和性能。O3CPU是gem5中最复杂和功能最强大的CPU模型之一,适用于需要较高性能的应用。
- TimingSimpleCPu——这是一个简单的时序CPU模型,它按照指令的顺序逐条执行,并考虑了指令之间的依赖关系和数据相关性。它适用于一些基本的仿真和性能评估。
- KvmCPU——这是一个基于内核虚拟机(KVM)的CPU模型,它利用硬件虚拟化技术将虚拟机监视器(VMM)的功能委托给底层的硬件,以提高虚拟机的性能。
- MinorCPU——这是一个简单的顺序CPU模型,它按照指令的顺序逐条执行,不使用乱序执行或流水线技术。MinorCPU适用于一些简单的仿真场景和教学目的。
这些CPU类型之间的区别在于它们的执行模型、性能特点和功能复杂性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- redis三主三从集群搭建
- 网络安全(黑客)—自学笔记
- Gooxi受邀出席操作系统与AI技术应用实践沙龙·OC城市行·深圳站活动
- 【工作技术栈】【备忘笔记】创建自签证书及使用过程
- vscode连接linux服务器
- 分布式(2)
- tomcat部署及优化
- 轻量封装WebGPU渲染系统示例<50>- Json数据描述材质等3D渲染场景信息
- 【Hadoop】ZooKeeper数据模型Znode
- 【CV】使用 matplotlib 画统计图,并用 OpenCV 显示静图和动图