大数据处理与分析
- 掌握分布式并行编程框架MapReduce
- 掌握基于内存的分布式计算框架Spark
- 理解MapReduce的工作流程、Spark运行原理
- 熟悉机器学习概念
一.MapReduce
Hadoop?MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。这个定义里面有着这些关键词,一是软件框架,二是并行处理,三是可靠且容错,四是大规模集群,五是海量数据集
因此,对于MapReduce,可以简洁地认为,它是一个软件框架,海量数据是它的“菜”,它在大规模集群上以一种可靠且容错的方式并行地“烹饪这道菜”。
1.?MapReduce做什么(分散任务,汇总结果!)

2.MapReduce模型简介

MapReduce核心函数:
MapReduce之策略:

MapReduce之理念:
计算向数据靠拢而不是数据向计算靠拢
要完成一次数据分析时,选择一个计算节点,把运行数据分析的程序放在计算节点上运行
然后把它所涉及的数据,全部从各个不同节点上面拉过来,传输到计算发生的地方
二.MapReduce之Map函数和Reduce函数
Map函数

Reduce函数

三.MapReduce的工作流程
1.工作流程

2.各个执行的阶段

1.从HDFS里加载文件读取文件-(IputFormat)对输入进行格式验证,然后,将输入文件切分为逻辑上的多个(IputSplit)实际是逻辑切分概念,只是记录了要处理的数据的位置和长度。
2.RR根据InputSplit中的信息来处理InputSplit中的具体记录,加载数据并转换为适合Map任务读取的键值对,输入给Map任务。
3.中间结果shuffle(洗牌),分区,排序,合并,归并,从无序<key,value>到有序的<key,value-list>
4.Reduce 执行用户定义的逻辑,输出结果给到OutputFormat模块
5.OutputFormat模块会验证输出目录是否已经存在以及输出结果类型是否符合配置文件中的配置类型,如果都满足,就输出Reduce的结果到分布式文件系统(如HDFS)。
3.MapReduce核心环节-Shuffle过程
所谓Shuffle,是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。因此,Shuffle过程分为Map端的操作和Reduce端的操作,主要执行以下操作。

Map端的Shuffle过程

a输入数据和执行Map任务
b写入缓存
c溢写(分区,排序和合并)
d文件归并
Reduce端的Shufflu过程
- Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据
- Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘
- 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- 当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce

MapReduce应用程序执行过程

四.实例分析:WordCount
- WordCount程序任务
- WordCount设计思路
- 一个WordCount执行过程的实例
4.1WordCount程序任务

一个WordCount程序任务
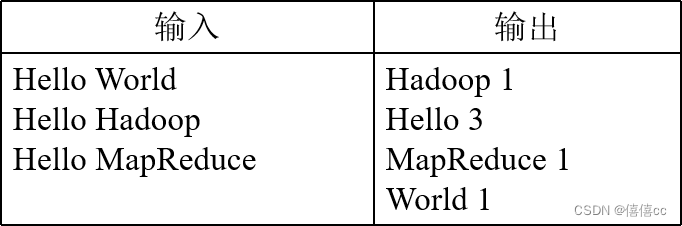
4.2WordCount设计思路
首先,需要检查WordCount程序任务是否可以采用MapReduce来实现
其次,确定MapReduce程序的设计思路
最后,确定MapReduce程序的执行过程
4.3一个WordCount执行过程的实例
Map过程示意图

用户没有定义Combiner时的Reduce过程示意图

用户定义Combiner时的Reduce过程示意图

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!