2024 通义语音 AI 技术图景,大模型引领 AI 再进化

自 1956 年达特茅斯会议上,约翰·麦卡锡首次提出了“人工智能”这一术语。AI 在此后七十年的发展中呈现脉冲式趋势,每隔 5-10 年会出现一次技术革新和域定。在这一技术探索进程之中,预训练基础模型逐渐成为主流探索方向,受到学术界和工业界的关注。在此技术背景下,OpenAI 携应用级界面产品 ChatGPT 横空出世,使得人们对大语言模型的通用能力有了全新的认识,引燃了语义大语言模型的研究热潮。
与此同时,要模拟人类的超级大脑,就必须进行多模态理解。这是因为人类接受信息不仅仅通过语言,真实世界的信息反馈还包含语音、文本、图像、视频等多种模态。单一模态的信息难以对人类的信息获取、环境感知、知识学习与表达的过程进行全面有效的学习。
站在岁末交更之际,本文将回顾最近一年通义实验室在语音 AI 经典的原子能力,如语音识别、语音合成、说话人识别的研究进展,并介绍语音 AI 结合大模型的多模态研究及应用进展。最后开源是降低 AI 研究和应用门槛的最有效手段,本文将会总结当前团队的开源情况,供读者鉴阅。
一、语音识别
语音识别服务框架
语音识别服务除了语音识别声学模型以外,还包含很多对于实践应用非常关键的技术模块:语音端点检测、标点预测、逆文本正则化(ITN)等。进一步的,语音识别声学模型也包含很多配套的子技术模块,例如热词定制化技术、时间戳预测等。本小节会介绍通义实验室过去一年在语音识别声学模型、语音端点检测、语音识别热词定制化和时间戳预测上最新的研究和应用进展。

Paraformer 语音识别声学模型
过去一年,通义语音实验室研究提出和落地了 Paraformer 的非自回归端到端语音识别。非自回归模型相比于目前主流的自回归模型,可以并行的对整条句子输出目标文字,特别适合利用 GPU 进行并行推理。相同模型参数规模的 Paraformer 和 Transformer,Paraformer 结合 GPU 推理效率可以提升 5~10 倍。
Paraformer 是当前已知的首个在工业大数据上可以获得和自回归端到端模型相同性能的非自回归模型。
过往关于非自回归端到端语音识别的研究主要面临两个核心问题:1)如何一次性准确的预测输入的音频包含的输出文字数目;2)如何优化非自回归模型中条件独立假设导致的语义信息丢失。
针对第一个问题,我们采用一个预测器(Predictor)来预测文字个数并通过 Continuous integrate-and-fire (CIF)?机制来抽取文字对应的声学隐变量。针对第二个问题,受启发于机器翻译领域中的 Glancing language model(GLM),我们设计了一个基于 GLM 的 Sampler 模块来增强模型对上下文语义的建模。

Paraformer 模型结构如上图所示,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。Encoder 可以采用不同的网络结构,例如 self-attention,conformer,SAN-M 等。Predictor 为两层 FFN,预测目标文字个数以及抽取目标文字对应的声学向量。Sampler 为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。Decoder 结构与自回归模型类似,为双向建模(自回归为单向建模)。Loss function 部分,除了交叉熵(CE),还包括了 Predictor 优化目标 MAE。
目前基于 paraformer 的语音识别框架已经全量上线到阿里云语音 AI。同时在下文我们也会介绍 Paraformer 在 Modelscope 社区和 FunASR 的开源相关的工作。关于 Paraformer 的详细的技术细节也可以参阅论文。
https://arxiv.org/abs/2206.08317
RWKV-RNN-T 语音识别声学模型

过去一年,我们在语音识别声学模型上的另一个尝试是探索将最新的 RWKV 结构和 RNN-T 相结合应用于实时语音识别。
目前主流的 Transformer 和 Conformer 网络结构的核心组件是 self-attention。然而,全局 attention 机制使其不适用于流式识别场景。为了使 transformer 和 conformer 支持流式语音识别,常见的做法是使用 chunk attention。这一做法存在两个问题,一是存在延迟和识别率的 trade-off,即更低的识别错误率依赖更大的 chunk,但会造成更大的延迟;二是需要在推理时缓存历史 chunk 的 Key,Value 信息,这增大了推理时的存储开销。
我们提出将最新的 RWKV 网络结构和 RNN-T 相结合,应用于低延迟的实时语音识别。RWKV 是一种线性 attention 模型,在推理时,RWKV 的前向计算可以写成 RNN 的形式。因此将 RWKV 用作 ASR encoder 有两大优势,一是无需使用 chunk,因而不会引入额外的延时;二是推理时无需缓存 Key,Value 信息。
我们在 Aishell-1、Librispeech、Gigaspeech、Wenetspeech 上的结果表明,RWKV-RNN-T 在延迟更小的前提下,可以取得与 chunk-conformer 接近的性能。在工业量级上的评测结果也表明,RWKV-RNN-T 在低延迟限制下具有出色的识别准确率。?当前 RWKV-RNN-T 的相关模型已经通过 Modelscope 进行开源,相关的训练代码也通过了 FunASR 进行开源。
具体可以参阅如下的具体链接:
Modelscope 体验地址:
论文预印版地址:
https://arxiv.org/pdf/2309.14758.pdf
代码开源:
https://github.com/alibaba-damo-academy/FunASR
Semantic-VAD 语音端点检测
语音端点检测(Voice Activity Detection,VAD)是语音识别系统中重要的组成部分,它能够将输入音频的有效语音检出并输入识别引擎进行识别,减少无效语音带来的识别错误。目前应用比较广泛的是基于 DNN、FSMN、LSTM 的二分类或者 Monophone 建模方式。
传统的 VAD 模型只区分语音和静音,忽略了每个静音部分是否是完整的语义断点,通常情况下需要等待较长的连续尾部静音(例如 700 毫秒)才能进行尾点判停。这种传统模型在语音交互应用场景中会带来比较明显的体感延时;在翻译场景还存在切割出来的片段语义不完整,影响翻译效果。
为了解决这类问题,我们在传统的 VAD 模型中添加一个帧级标点预测任务。如果检测到一个结束标点(例如句号、问号),表明存在完整的语义断点,等待一个较短的尾部静音(例如 400 毫秒)则进行断句。当检测到非结束标点(例如逗号、顿号)的情况下,用于断句的尾部静音需要略长一些(例如 500 毫秒)。只有在无法预测标点的情况下,才会使用传统 VAD 的预设最大尾部静音(例如 700 毫秒)来确定分割点。传统 VAD 的是单任务训练方式,如下图(a)所示,通常采用 DNN、FSMN、LSTM 等模型结构。我们提出的语义 VAD,通过多任务训练框架,如下图(b)所示,引入了标点预测和自动语音识别(ASR)任务来增强 VAD 训练中的语义信息学习,从而提高了整个 VAD 系统的性能。

在实际应用场景中(例如智能交互场景),需要在考虑延时和实时率的同时来提高 VAD 系统的性能,我们采用的是基于 RWKV 的模型结构,如下图(c)所示,该模型结构结合了 RNN 和 Transformer 的优点,非常适合用于实时语音端点检测系统。而在离线系统中(例如客户质检场景),更注重片段的切割准确率,我们采用的是通义语音实验室自研的 SAN-M Chunk 结构,如下图(d)所示。

论文预印版下载地址:
http://arxiv.org/abs/2312.14860
热词定制化技术
大家在使用通用语音识别模型时,往往会遇到人名地名与专有名词识别不正确的问题,在这种情况下模型通常会输出同音异形的结果。热词定制化技术旨在支持用户通过预设热词列表的方式增强上述词汇的识别,是解决通用语音识别模型实际应用的最后一步中的关键技术之一。
通义实验室语音团队的热词定制化技术经过了从基于 WFST 解码图的热词激励到基于 Clas 的神经网络热词激励与二者耦合共同激励的演变,并且在今年针对 Paraformer 非自回归模型结构提出了 Semantic-Augmented Contextual Paraformer(SeACo-Paraformer),利用 Paraformer 的结构特点实现了热词协同解码的效果。其热词召回率较 Clas 模型显著提升,并且模型训练与生效的稳定性较 Clas 更优。
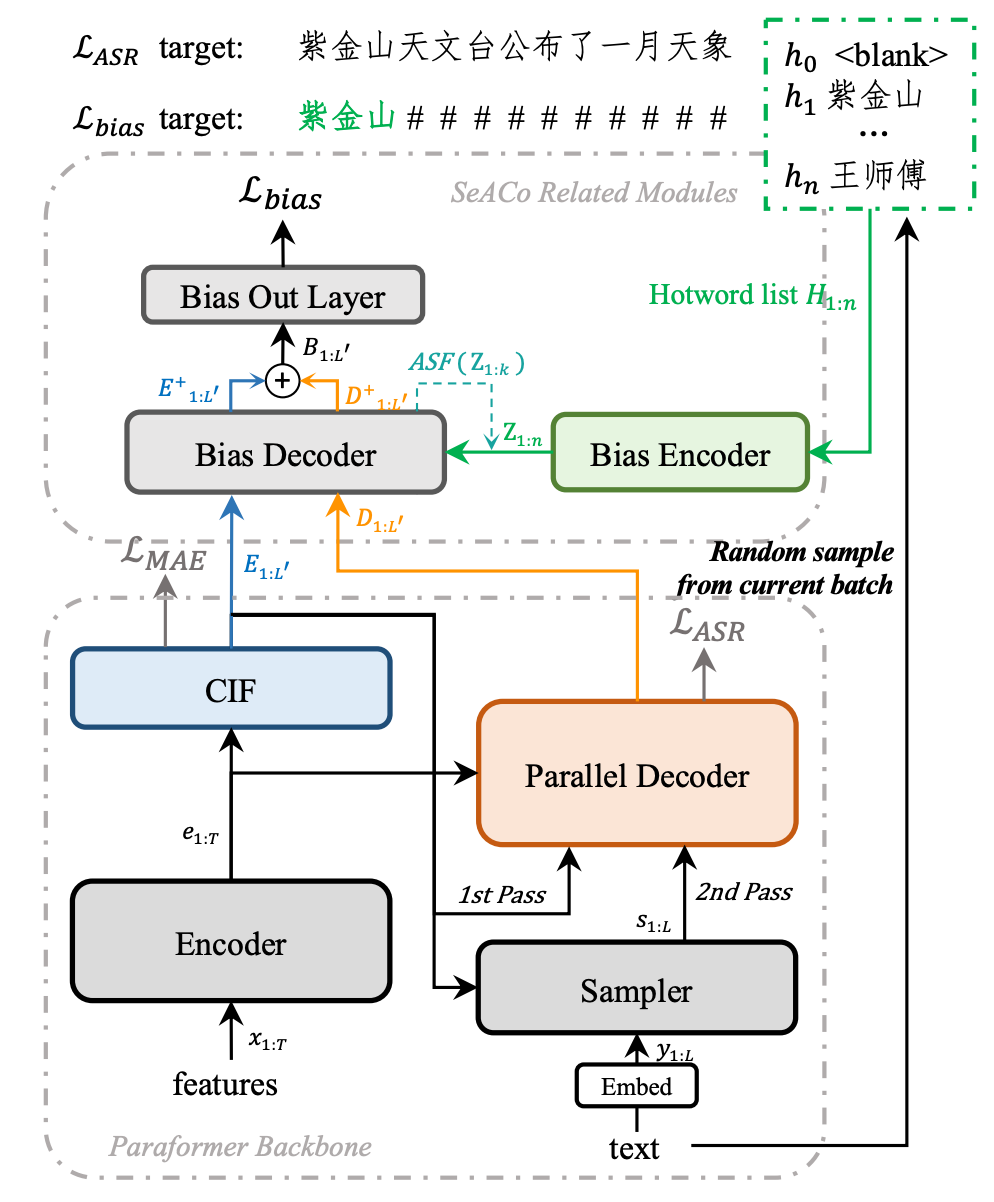
基于神经网络的热词定制化 ASR 模型的核心策略由两部分组成:训练过程中随机采样热词、通过 attention 机制捕捉热词信息与 decoder 信息的相关性。Clas 方案通过上述策略实现了隐式的热词激励,即热词部分的建模嵌入到了 ASR decoder 中,在基础 ASR 模型效果较好时网络的偏置部分可能会因不能得到充分训练而失效。SeACo-Paraformer 将热词建模功能从 ASR decoder 中解耦,通过显式的热词损失函数引导热词建模,网络结构与训练方式如上图所示。内部工业数据对比实验表明,SeACo-Paraformer 模型相较 Paraformer-Clas 模型在热词召回率上得到了约 18%的提升,并且解耦了 ASR 模型训练与热词模型训练,使训练过程更灵活。
论文预印版下载地址:
https://arxiv.org/pdf/2308.03266.pdf
一体化时间戳预测
语音识别的音字对齐功能是一些典型应用,例如自动字幕等的关键需求。在语音识别模型从传统的基于 HMM-DNN-WFST 融合系统迈进基于 CTC、Transformer、Transducer 等结构的端到端时代的过程中,时间戳预测问题是遗留问题之一。
传统模型基于 HMM 产生的帧级别强制对齐,能够天然的在解码器中获取输出 token 的时间戳。但是在端到端模型中,CTC/Transducer 模型面临尖峰偏移的问题、Transformer/LAS 模型进行非帧同步的解码,均无法天然的获取输出 token 的时间戳,需要借助传统 Force-Alignment 模型分两阶段生成时间戳,提升了模型训练的成本与难度。

基于 Paraformer 模型中 CIF-Predictor 的建模特性,我们发现 CIF 机制的权重累计过程可以被用于时间戳生成。针对工业模型 CIF 权重的特点,我们设计了包括延迟发射在内的优化策略,实现了在 ASR 模型解码的同时天然的获取输出 token 的时间戳(如上图所示)。在学术数据集与工业数据集的实验中,上述方法的时间戳精度与 Force-Alignment 系统相当。
论文预印版下载地址:
https://arxiv.org/pdf/2301.12343.pdf
音频多模态大模型
技术的发展日新月异,大模型也从单一的语义大模型快速的在向多模态大模型发展。例如 OpenAI 最新的 GPT-4V,解锁了文本和视觉的能力;GPT-4 的 VoiceChat 解锁了语义和语音的能力;Google 的 Gemini 从设计之初就是一个包含文本、视觉和音频的多模态大模型。通义实验室过去的一年也在前沿的音频多模态大模型上展开相应的探索:1)多模态语音识别;2)LauraGPT 语音大模型;3)Qwen-Audio 语音-语义大模型。
多模态语音识别
多模态语音识别技术旨在利用多种模态信息来提升语音识别系统的性能。现有的一些多模态方法主要关注视频或图像方面的信息(例如唇语、图片中物品的种类信息等),但却忽视了对视频中文本信息的利用。在线会议视频中通常包含大量幻灯片,这些幻灯片以文本和图像的形式提供了丰富的特定领域信息,并且幻灯片和语音是实时同步的,因而也提供了时间上的上下文关系。鉴于此,我们发布了一个包含大量幻灯片场景的大规模音视频多模态语料库 SlideSpeech(https://slidespeech.github.io)。
该语料库包含 1,705 个视频,1,000?多个小时,以及 473 个小时的高质量自动生成的语音转录抄本。在这项工作中,我们介绍了构建语料库的流水线,主要过程是结合 Youtube 外挂字幕和内部 VAD 和 ASR 系统进行数据挖掘生成。
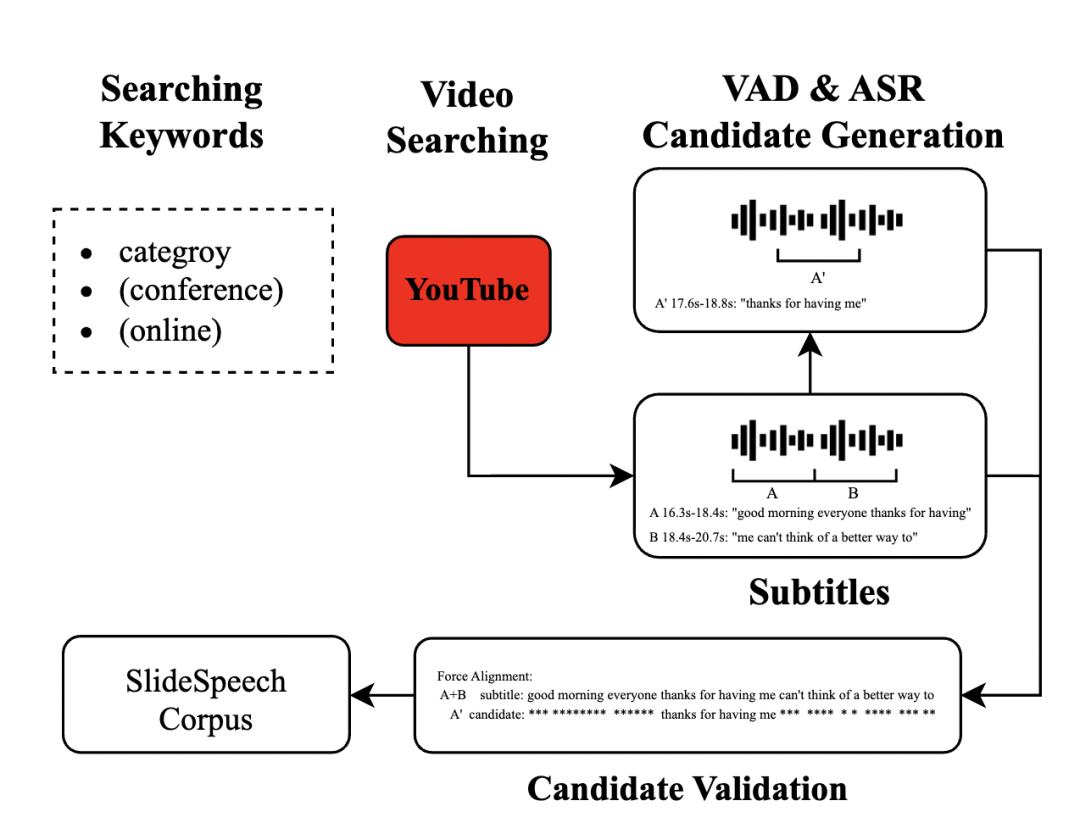
构建语料库的流水线示意图
同时我们还提出了在可视上下文幻灯片中利用文本信息的基准系统。通过应用关键词提取和上下文语音识别(Contextual ASR)方法于基准系统中,我们展示了整合补充视频幻灯片中的文本信息以提高语音识别性能的潜力。

利用幻灯片文本信息的基准系统示意图
论文预印版下载地址:
https://arxiv.org/abs/2309.05396
数据库开源地址:
https://slidespeech.github.io/
考虑到 SlideSpeech 语料中视频数据包含的幻灯片与语音实时同步,相比于统一的稀有词列表,其能够提供更长的上下文相关信息。因此,我们提出了一种创新的长上下文偏置网络(LCB-net)用于音频-视觉语音识别(Audio-Visual Speech Recognition,AVSR),以更好地利用视频中的长时上下文信息。
具体来说,我们首先使用 OCR 技术来检测和识别幻灯片中的文本内容,其次我们采用关键词提取技术来获取文本内容中的关键词短语,最后我们将关键词拼接成长上下文文本和音频同时输入到我们的 LCB-net 模型中进行识别。LCB-net 模型采用了双编码器结构,同时建模音频和长上下文文本信息。并且,我们还引入了一个显式的偏置词预测模块,通过使用二元交叉熵(BCE)损失函数显式预测长上下文文本中在音频中出现的关键偏置词。此外,为了增强 LCB-net 的泛化能力和稳健性,我们还采用了动态的关键词模拟策略。实验证明,我们提出的 LCB-net 热词模型,不仅能够显著提升关键词的识别效果,同时也能够提升非关键词的识别效果。

LCB-net?模型结构
从技术与场景的接近性角度看,教育网课是该技术落地应用的重要方向之一,其通常采用的授课形式是 PPT 的视频讲解。网课种类丰富包含学术课程(数理化等)、语言课程(英语、日语等)、人工智能课程(计算机、编程、网页开发等)、职业培训课程(软件开发、市场营销等)等,包含了大量的专有名词,为语音识别带来了巨大的挑战,并且面对海量的 PPT 视频课程,学生很难进行笔记整理、课件沉淀、重点精听。未来我们的听悟,将针对该领域推动多模态技术的落地应用,帮助用户在教育网课学习中转录上课内容、总结筛选重点知识、沉淀学习笔记等。
LauraGPT 语音大模型?
ChatGPT 证明一个模型通过生成式预训练(GPT)能够统一处理各种各样的文本任务,包括机器翻译、文本摘要、口语语言理解等。语音作为人类最自然的沟通交流方式之一,也是一种重要的信号模态,那么,不禁会产生这样的疑问,能否将不同的语音任务统一到一个模型框架中,只需训练一个模型就可以原生的支持语音的识别、理解和生成,而不是通过不同模型之间的级联?带着这样的疑问和愿景,语音-文本多任务大模型应运而生,例如微软的 VALL-E、VioLA 和 SpeechT5,谷歌的 AudioPaLM 和 Gemini 等模型。
然而,现有语音-文本多任务大模型支持的语音-文本多模态任务比较有限,要么仅支持语音识别和理解任务,要么仅支持语音生成任务,缺乏对其他语音相关的信号处理、情感识别等任务的支持。此外,已有的语音-文本多任务大模型缺乏充分的定量评估,或者在性能上低于单任务的最优(SOTA)模型,并未体现出大模型的性能优势。这主要是由于现有的语音-文本大模型多使用离散化的语音表示来同意语音和文本的建模,而语音本身是一种连续信号,离散化的过程会造成严重的信息丢失,从而导致识别和理解类语音任务性能严重下降。
基于上述发现和分析,我们提出了 LauraGPT,它连续的语音表示作为输入来保证识别和理解类任务的性能,同时使用离散的语言表示作为输出来统一生成语音和文本的 token,从而在保证模型通用能力的前提下,尽可能的提高了模型性能。
LauraGPT 的模型结构如下图所示,在 LauraGPT 中,我们将不同的语音-文本任务统一为如下形式的序列生成问题:?"Task Inputs, Task ID, Task outputs"。其中任务输入可以是音频信号、文本或者他们的组合,其中音频信号通过 AudioEncoder 转变为连续的音频表征,而文本则通过 Qwen Tokenizer 进行子词拆分,而后经过 Embedding 层转换为词嵌入向量。其输出根据任务 ID 的不同,可能是离散化的语音 token 或者子词拆分后的文本 token,其中离散化的语音 token 通过我们提出的 FunCodec 语音编码器得到,我们会在后面对其进行介绍。
此外,我们还提出了 one-step codec vocoder,它能够根据提供的条件序列和 LauraGPT 生成的 token 序列生成质量更高的音频信号。通过上述的建模方式,我们将不同的语音-文本任务统一使用 LauraGPT 进行建模,挖掘了不同任务之间可能存在的协同关系。LauraGPT 直接支持的任务包括:语音识别(ASR)、语音翻译(S2TT)、语音合成(TTS)、机器翻译(MT)、语音增强(SE)、音频描述(AAC)、语音/文本情感识别(SER)和口语语言理解(SLU)。此外,通过将不同任务进行组合,LauraGPT 还能够进行更加复杂的任务,例如同声传译、富文本转写、富文本翻译、噪声鲁邦语音识别等。
为了保证可复现性,我们在开源的中英文双语种数据集上进行了实验验证,结果表明,LauraGPT 在各种音频-本文处理任务的基准测试上达到了与现有 SOTA 模型相当或更优的性能。此外,我们还发现,不同的任务之间存在着不同程度的协同作用,例如,拥有大量的数据的 ASR 任务能够帮助数量较小的语音翻译任务做的更加准确。LauraGPT 的提出使我们能够在未来仅需做不同任务的数据收集和整理就能够不断地提升性能;于此同时,还能够通过不同任务之间的协同作用,使用数据量较大的任务来帮助模型学习数据有限的任务。

LauraGPT 模型结构图
Demo?Page:?
论文预印版下载地址:
https://arxiv.org/abs/2310.04673
Qwen-Audio 音频-语义大模型?
语义大语言模型(LLM)相比于人类对于世界的感知,存在的一个短板是模型无法直观地感知和解析图像与音频信息。作为一种关键的信息表达方式,音频携带了丰富的、超越文字的信号细节,例如:人声中蕴含的情绪、语气和意图;自然界中的各类声响,像是火车的汽笛、钟声;以及音乐所传达的旋律和节奏等。因此,让语言模型掌握对这些丰富音频信号的感知与理解,并能够实现有效的音频互动,将语义大模型进化到多模态大模型是当前的一个研究和应用热点。
最近,遵循指令的音频-语言模型因其在与人类的音频交互中所表现出的潜力而受到了广泛关注。然而,缺少能够处理多种音频类型和任务的预训练音频模型,这限制了这一领域的发展。因此,大多数现有的研究只能支持有限范围的交互能力。
为此,通义实验室研究发布了 Qwen-Audio 音频-语义大模型。Qwen-Audio 通过扩大音频-语言预训练的规模来解决这一局限性,涵盖了超过 30 种任务和各种音频类型,如人类语音、自然声音、音乐和歌曲,以促进全面的音频理解能力。然而,直接共同训练所有任务和数据集可能会导致干扰问题,因为不同数据集相关联的文本标签由于任务焦点、语言、注释粒度和文本结构的差异而显示出相当大的变化。
为了克服这种一对多的干扰,Qwen-Audio 仔细设计了如下图的多任务训练框架,通过向解码器引入一系列层级标签来鼓励知识共享,并分别通过共享和指定的标签来避免干扰。

通过采用多任务预训练的 Qwen-Audio 模型,在公开的多个基准任务上都获得了 SOTA 的性能,如下图所示,在语音识别的 AISHELL-1、AISHELL-2、Librispeech,语音翻译的 CoVoST2 任务,音频事件描述的 Clotho 任务等 Qwen-Audio 相比于开源的其他工作均有明显的性能优势,并且是当前这些任务的 SOTA。

Qwen-Aduio 通过多任务预训练具备了对音频的广泛理解能力。在此基础上,我们采用基于指令的微调技术来提升模型与人类意图对齐的能力,从而开发出名为 Qwen-Audio-Chat 的交互式聊天模型。
当前 Qwen-Audio(https://modelscope.cn/models/qwen/Qwen-Audio/summary)和 Qwen-Audio-Chat(https://modelscope.cn/models/qwen/Qwen-Audio-Chat/summary)模型已经发布到了 Modelscope。可以到 Modelscope 进行在线体验。
同时 Qwen-Audio 相关的代码也通过 Github 进行了开源。
Github 开源仓库:
?https://github.com/QwenLM/Qwen-Audio
二、音频分析与语音合成
说话人基础模型研究
基于上下文感知的说话人识别网络
在说话人识别领域中,主流的说话人识别模型大多是基于时延神经网络或者二维卷积网络,这些模型获得理想性能的同时,通常伴随着较多的参数量和较大的计算量。如何兼具准确识别和高效计算,是当前说话人识别领域的研究热点之一。
因此我们提出高效的说话人识别模型 CAM++。该模型主干部分采用基于密集型连接的时延网络(D-TDNN),每一层的输入均由前面所有层的输出拼接而成,这种层级特征复用可以显著提高网络的计算效率。同时,D-TDNN 的每一层都嵌入了一个轻量级的上下文相关的掩蔽(Context-aware Mask,CAM)模块。
CAM 模块通过全局和段级的池化操作,提取不同尺度的上下文信息,生成的 mask 可以去除掉特征中的无关噪声。TDNN-CAM 形成了局部-段级-全局特征的统一建模,可以学习到特征中更加丰富的说话人信息。CAM++前端嵌入了一个轻量的残差二维卷积网络,可以捕获更加局部和精细的频域信息,同时还对输入特征中可能存在的说话人特定频率模式偏移具有鲁棒性。

图示:CAM++模型结构示意图
VoxCeleb 和 CN-Celeb 公开数据集上的实验结果显示,对比主流的 ECAPA-TDNN 和 ResNet34 模型,CAM++具有更高的识别准确率,同时在计算量和推理速度上有着明显的优势。
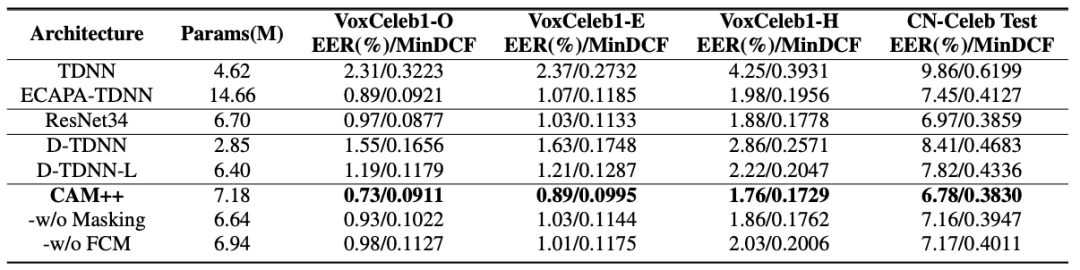
图示:VoxCeleb 和 CN-Celeb 数据集实验结果

图示:计算复杂度对比
相关论文:https://www.isca-speech.org/archive/pdfs/interspeech_2023/wang23ha_interspeech.pdf
基于全局和局部特征融合的增强式网络
有效融合多尺度特征对于提高说话人识别性能至关重要。现有的大多数方法通过简单的操作,如特征求和或拼接,并采用逐层聚合的方式获取多尺度特征。本文提出了一种新的架构,称为增强式 Res2Net(ERes2Net),通过局部和全局特征融合提高说话人识别性能。局部特征融合将一个单一残差块内的特征融合提取局部信号;全局特征融合使用不同层级输出的不同尺度声学特征聚合全局信号。为了实现有效的特征融合,ERes2Net 架构中采用了注意力特征融合模块,代替了求和或串联操作。
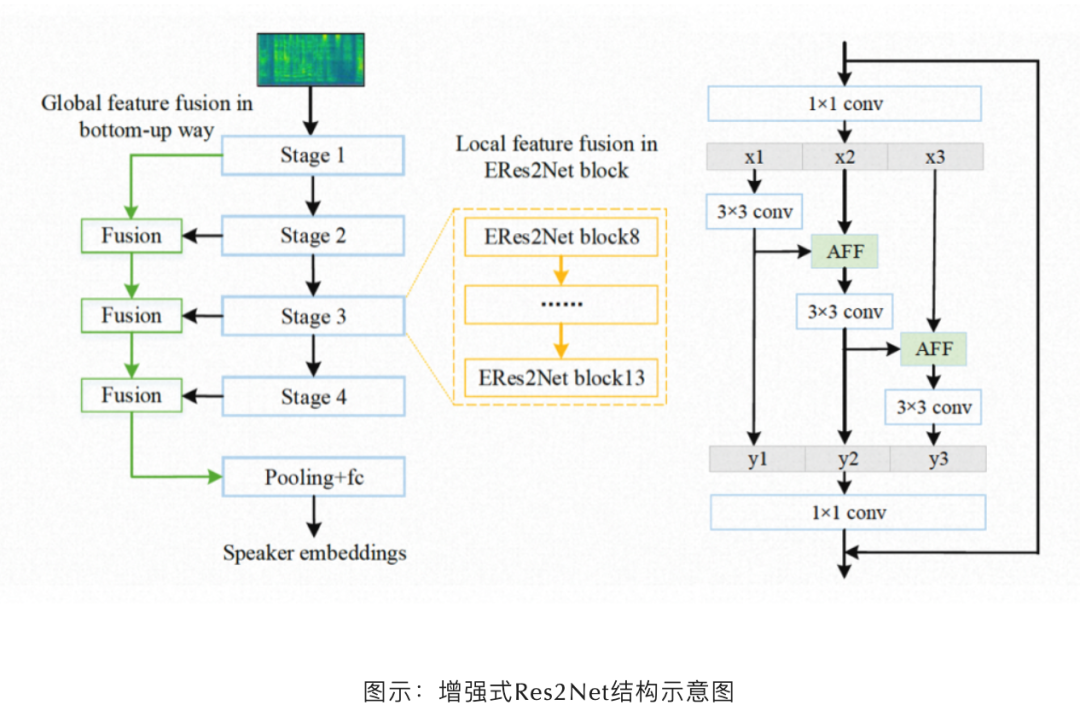
ERes2Net 在公开测试集 VoxCeleb 中取得优异性能,在模型参数量相近条件下,各模型识别性能对比如下所示:
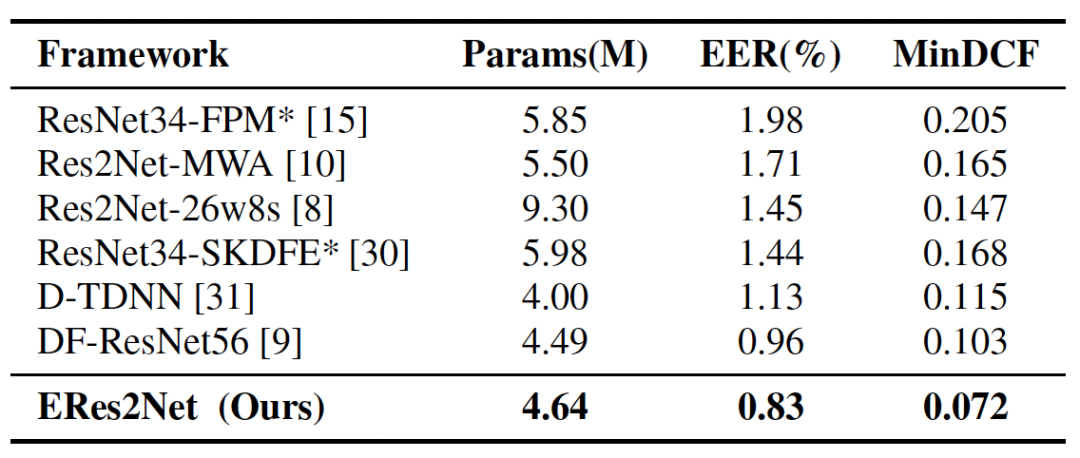
论文下载地址:
https://www.iscaspeech.org/archive/interspeech_2023/chen23o_interspeech.html
基于非对比自监督学习的说话人识别
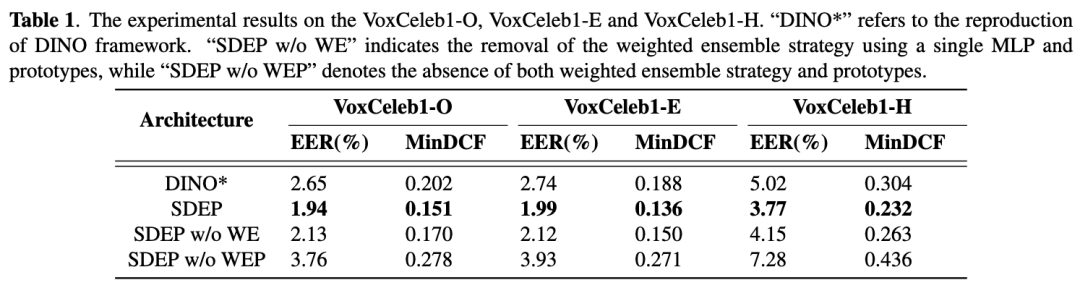
正则化 DINO 框架的自监督说话人识别
在无法获得说话人标签的语音数据条件下,训练一个鲁棒性强的说话人识别系统是一个极具挑战性的任务。研究表明全监督说话人识别和自监督说话人识别之间仍存在不小的性能差距。在这篇文章中,我们将自监督学习框架 DINO 应用于说话人识别任务,并针对说话人识别任务提出多样性正则和冗余度消除正则。多样性正则提高特征多样性,冗余度正则减小特征冗余度。不同数据增强方案的优劣在该系统中得以验证。大量的实验在公开数据集 VoxCeleb 上开展,表现出 Regularized DINO 框架的优越性。

正则化 DINO 框架在公开测试集 VoxCeleb 中取得优异性能,与同时期发表的相关模型性能对比如下:

论文下载地址:
https://arxiv.org/pdf/2211.04168.pdf
基于自蒸馏原型网络的自监督说话人识别
深度学习在说话人识别中广泛应用并取得优异性能,但是利用大量有标签语音数据训练神经网络提取说话人嵌入矢量需要耗费极大的人工成本,所以如何利用海量无标签数据获取优质说话人矢量成为一大研究痛点。而自监督学习利用自身监督信息学习对网络进行训练,有效降低了标注数据等步骤成本,因此我们提出一种基于自蒸馏原型网络的自监督学习说话人确认方法,提高说话人嵌入矢量的泛化性能。
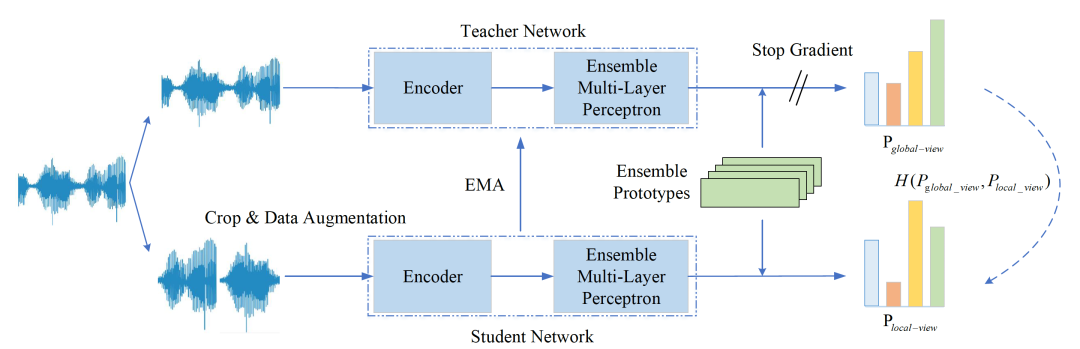
自蒸馏原型网络由教师模型和学生模型构成,如上图所示,将同一条语音切分成若干长时和短时语音,长时语音输入教师特征编码器,教师多层感知机以及原型网络,短时语音输入学生特征编码器,学生多层感知机以及原型网络,使用教师模型输出指导学生模型输出,完成自蒸馏过程。基于自蒸馏原型网络的说话人识别性能如下:
论文下载地址:
https://arxiv.org/pdf/2308.02774.pdf
多模态说话人区分
结合语义的说话人日志技术
说话人日志(Speaker Diarization,SD)系统的目标是解决“谁在什么时间说话”的说话人识别问题,是一种可以广泛应用于客服、会议等多轮对话场景的语音技术。现有的相关技术大致分为两类,一类是基于分割聚类的传统方法,另一类则是基于深度神经网络的端到端方法,它们都是依赖纯语音信息的方案,在说话人音色相近、声学环境复杂的情况下往往容易产生说话人混淆、说话人转换点不清晰等错误。为此,我们着重探索了结合其他模态信息的说话人日志技术。
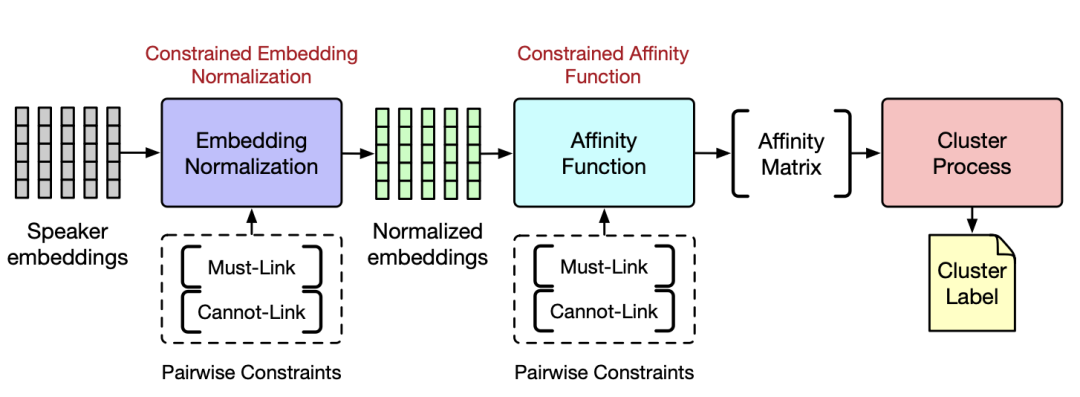
结合局部语义说话人日志系统
针对现有方法存在的问题,我们提出了结合语义的说话人日志系统。我们的系统如下图所示,区别于传统说话人日志系统的 pipeline(VAD - Embedding - Cluster)的过程,我们通过引入 Forced-Alignment 模块来对齐文本和 speaker embedding 过程,并且将 ASR 输出的文本结果输入到语义模块中来提取说话人相关的语义信息。
关于语义部分,我们提出了两个用于提取语义中说话人信息的模块:对话预测(Dialogue Detection)和说话人转换预测(Speaker-Turn Detection),这两个模型基于 Bert 模型,使用大量带说话人 ID 的会议文本进行训练,可以用于判断多人对话的局部是否有说话人转换发生以及说话人转换发生的具体文本位置。

由于语义模块的结果也包含一些错误,尤其是在 ASR 系统解码出的文本上,文本错误会使得语义模型的性能有所下降,我们设计了一系列简单而有效的 fusion 策略来结合语音信息的说话人聚类结果,可以显著提升上述两个子模块的效果。
通过结合传统说话人聚类的结果和语义说话人信息,我们可以对纯音频信息的说话人日志结果进行优化。我们在 AIShell-4 和 M2MeT(Alimeeting)数据上的结果表明,结合语义的说话人日志系统在 speaker-wer 和 cp-wer 上都有显著提升。

相关论文:
https://aclanthology.org/2023.findings-acl.884.pdf
局部语义说话人信息的全局扩散
上一系统语义说话人信息模块对说话人日志系统的主要作用在于说话人日志局部结果的修正,缺少对于全局说话人结果的优化。因此,我们提出了基于成对约束扩散方法的说话人日志系统,将局部说话人语义信息对全局说话人日志结果产生影响。
首先我们将语义模块得到的说话人信息总结成两类成对约束(Pairwise Constraints):Must-Link 和 Cannot-Link。例如 Dialogue Detection 判断为非多人对话的一段时间中所有的 speaker embedding 都在 Must-Link 中,而 Speaker-Turn Detection 判断为转换点前后两段的 speaker embeddings 都在 Cannot-Link 中,这样我们就可以将语义信息抽象成方便使用的约束信息。
我们提出了 JPCP(Joint Pairwise Constraints Propagation)方法,将这些成对约束用于 speaker embedding 降维和说话人聚类过程中:(1)利用 SSDR(semi-supervised dimension reduction)策略,利用特征值优化将成对约束引入到 speaker embedding 降维之中,调整了其用于聚类的 speaker embedding 分布。(2)引入了 E2CP(exhaustive and efficient constraint propagation)方法,利用成对约束调整聚类相似度矩阵,从而改进说话人聚类的效果。(3)提出了 E2CPM 的改进方法,有效减少了语义结果解码错误所带来的负收益,对于高置信度的说话人相似度进行保留和强调。
我们的实验基于 AIShell-4 数据集,该数据集包括人数较多的多说话人会议,输入进入语义模块的文本则来自于 ASR 系统的解码结果(JPCP-I)。可以看到我们提出的 JPCP 方案可以有效提高说话人聚类的效果,其中我们提出的 E2CPM 方法起到了关键作用,并且说话人人数预测错误也得到一定的缓解。
考虑到语言模型的蓬勃发展,为了充分探索我们方案的上限,我们还在仿真的成对约束(JPCP-S)上充分探索了我们方案的上限,可以看到当 constraints 的质量和数量进一步提升时,最终的结果有显著的提升,并且可以更好的减少说话人日志系统说话人人数预测错误。

相关论文:https://arxiv.org/pdf/2309.10456.pdf
结合视觉信息的说话人日志技术?
在现实场景中部分声学环境可能非常复杂,存在背景噪声、混响和信道等干扰因素,这些因素会导致难以获取高质量的语音信息或转写文本信息。为了更准确地识别不同的说话人,结合视觉信息的说话人日志技术是一种非常具有潜力的解决方案,可以弥补语音信息受限的问题,进一步提升对说话人的理解和识别能力。
为此,我们设计了一套结合音频、图像信息的多模态说话人日志系统。除了传统的基于声学的识别模块,我们添加了额外的视觉说话人日志模块。首先输入的视频流数据会进行场景检测分段,由于在每帧画面中可能存在不止一个人,说话人检测模块(Active speaker detector)会基于连续的视频帧进行说话者检测,输出当前正在说话的说话者信息,后续人脸识别模块会提取该说话者的人脸特征,并和音频特征进行对齐,修正说话人全局聚类的结果。
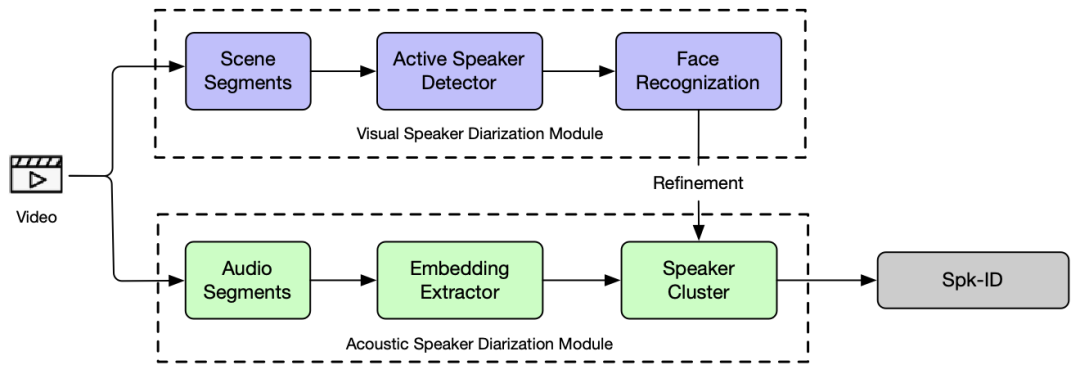
在一个包含访谈、综艺等多种类型视频数据上的实验结果表明,结合了视觉信息的说话人日志系统在分割错误率(Diarization Error Rate)上有着显著的提升。

?说话人识别,说话人分割以及语种识别

说话人识别包括全监督和自监督说话人识别。全监督说话人识别中,包含自研模型 CAM++, ERes2Net 和经典模型 ECAPA-TDNN 在各公开训练集 3D-Speaker, CN-Celeb 和 VoxCeleb 上训练,推理代码。
自监督说话人识别包含正则化 DINO 框架的训练,推理代码。说话人分割使用经典的分割聚类算法,首先使用 VAD 模型去除语音中静音片段,再通过说话人特征提取模型 CAM++或 ERes2Net 提取鲁棒性的说话人矢量,最后使用经典聚类算法 K-均值或谱聚类得到各说话人的时间戳对原语音片段进行分割。语种识别包括自研模型 CAM++, ERes2Net 在公开训练集 3D-Speaker 进行训练推理代码。
除此之外,在平台 ModelScope 上开源上述所有预训练模型,模型下载量 40w+。
语音合成模型
CSP 语音合成模型

为了提高 TTS 的生成效果和流式推理高效性,通义实验室语音团队今年在自回归 TTS 声学模型(SAMBERT)的已有积累上升级到非自回归声学模型 CSP (Chunk Streaming Parallel)?。其中多个子模块均进行了相应打磨:
-
在韵律建模方面融合显隐式进行多尺度建模,并结合深度生成模型(Flow,LCM)进行韵律预测,使得声学模型在具有控制能力鲁棒性的同时对韵律有较好的预测刻画效果。
-
采用 chunk cache based decoder 支持高效的非自回归流式推理,满足工业应用需求。chunk 内可以并行计算提高推理效率,非自回归建模避免 teacher-forcing 带来的 mismatch,便于模型效果整体端到端优化。
-
采用深度生成模型(Flow,GAN)的 Post-Net 对 decoder 生成的 mel-spectrogram 进行 refine, 在引入 look-ahead 减少 chunk 带来的流式损失的同时避免 over-smoothing 进一步提升 mel-spectrogram 的生成质量。
非自回归声学模型 CSP 相较于自回归声学模型 SAMBERT 在语速停顿等韵律方面具有一定优势,多音色评测 CMOS avg +0.07, 推理效率 CPU 提升 4 倍,进一步结合 GPU 后推理效率提升 18 倍。该方案正结合具体的业务场景做进一步的细致优化,并逐渐进行线上音色的模型升级。相关代码及模型也将通过 KAN-TTS 和 ModelScope 进行开源。
个人声音定制
个人声音定制是基于 KAN-TTS 训练框架、AutoLabel 自动标注工具以及 SambertHifigan 个性化语音合成基模型搭建的一款 ModelScope Studio 应用,用户可以在应用主页录制 20 句话等待数分钟后即可复刻自己的声音。

个人声音定制 ModelScope 地址:
https://www.modelscope.cn/studios/damo/personal_tts/summary
三、多模态语义大模型?
通义听悟应用实践
过去一年,得益于以 OpenAI 为首提出的大规模语言模型(LLM)的飞速发展,我们基于通义实验室的通义千问底座结合过往的口语语言处理经验进行了进一步的基础算法探索以及应用落地;本话题先针对语义板块结合大模型以及多模态在通义听悟场景下的应用实践进行讨论,再介绍口语语言处理领域的应用研究工作。
算法能力架构图
通义听悟是通义家族首个消费者端应用产品,聚焦于音视频内容记录和理解分析,期望在多媒体时代帮助用户梳理和挖掘音视频信息价值并沉淀为知识资产;针对听悟中用到的文本、语音、视觉、翻译等相关算法进行梳理,得到以下的算法架构图。

多模态分割
PPT 视觉边界检测及大模型摘要
PPT 视觉边界检测及大模型摘要是指提取视频中的 PPT 画面,并将每页 PPT 展示时所讲述的内容,提炼成摘要总结,便于快速回顾 PPT 及讲解内容。算法基本流程如下图所示,我们针对 PPT 展示的特点设计了结合视觉和文本的检测任务;具体为以固定时间间隔从视频中采集视频帧得到视频帧序列,首先进行前景物体过滤,之后依据运动和静止事件检测结果锚定 PPT 切换的时间戳,并进行时间戳校准、相似度去重、OCR 识别 PPT 内容等后处理操作,最后对齐视频转写的文本和 PPT 内容,输入到通义听悟摘要大模型得到每张 PPT 对应讲解内容的摘要总结。

语义结构分割
文本语义主题分割旨在将长篇章文本按照各部分所表达的中心思想分割成一系列语义片段,该能力是通义听悟中“文本分段”以及“章节速览分话题”的基石。我们提出了两种方法来增强预训练语言模型感知文本连贯性的能力并提升主题分割性能,一是主题感知句子结构预测(Topic-aware Sentence Structure Prediction ,TSSP)任务,该任务首先构造主题和句子级别扰乱的文档作为增强数据,之后训练模型学习增强文档中相邻句子的原始逻辑结构关系;二是对比语义相似性学习(Contrastive Semantic Similarity Learning ,CSSL),该任务利用主题边界信息构造对比样本,确保同一主题中的句子表示具有较高的相似度,而不同主题的句子表示相似度较低。

实验结果表明,TSSP 和 CSSL 任务能提升 BERT、BigBird 和 Longformer 等预训练语言模型的主题分割效果,并且 Longformer+TSSP+CSSL 在 Intra-domain 和 Out-of-domain 下均显著优于现有方法,并且在不同上下文长度下均能提升基准模型性能。此外,我们探索了不同的 Prompt 来测试 ChatGPT3.5 在长篇章文档的主题分割性能,结果显示 Longformer+TSSP+CSSL 模型在 Out-of-domain 配置下效果优于 ChatGPT3.5 的 zero-shot 和 one-shot 性能。
更多技术细节可以参考我们发表在 EMNLP2023 的技术论文:
https://aclanthology.org/2023.emnlp-main.341/
智能待办??
在智能待办方面,根据不同策略的对比结果最终采用了“小模型识别+大模型总结”的两段式方法,基于小模型行动项识别结果,通过大模型进行总结,以期提高用户体验。
行动项识别(action item detection)旨在识别会议记录中待办相关内容,通常建模为句子级别的二分类任务。然而,该任务面临着数据量少、标注质量低、类别不均衡等问题。为此,我们构建并开源了第一个带有行动项标注的中文会议数据集。在此基础上,我们提出了 Context-Drop 的方法,通过对比学习建模同时建模局部和全局上下文,在行动项识别表现和鲁棒性方面均取得更好的效果。
此外,我们探索了 Lightweight model ensemble 的方法,利用不同的预训练模型,提高行动项识别的表现。

另一方面通过对大模型的效果摸底,可以观察到其在智能待办生成方面具有“准确率较低而可读性强”的特点。
因此,我们先通过小模型召回待办相关片段,然后再通过大模型结合上下文内容进行总结,返回待办事项的任务描述、负责人、时间期限等要素信息,并通过探索上下文长度、Prompt、待办提示、聚合策略等方面的设置,不断改善行动项识别及总结的数据标注质量,优化大模型的总结表现。此外,训练过程中引入高难度负例样本强化了大模型的拒识能力,进一步激活大模型能力提高返回结果的准确率。
最终,业务侧主观评测结果显示上述的?两段式方法?显著优于单独的小模型检测和大模型端到端生成方法。
更多技术细节可以参考我们发表在 ICASSP2023 的技术论文:
https://ieeexplore.ieee.org/document/10096053
口语语义理解研究
ICASSP2023?MUG 会议理解和生成大挑战??
以往的研究表明,会议记录的口语语言处理(Spoken Language Processing, 简称 SLP)?如关键词提取和摘要生成,对于会议的理解和生成?(Meeting Understanding and Generation)?包括信息的提取、组织排序及加工至关重要,可以显著提高用户获取重要信息的效率。
然而由于会议数据的高度保密性,会议内容理解和生成技术的发展一直受到大规模公开数据集缺失的制约。为了促进会议理解和生成技术的研究和发展,阿里巴巴通义语音实验室构建并发布了目前为止规模最大的中文会议数据集 Alimeeting4MUG Corpus(AMC),并基于会议人工转写结果进行了多项 SLP 任务的人工标注。AMC 也是目前为止支持最多 SLP 任务开发的会议数据集。基于 AMC 举办的 ICASSP2023 MUG 挑战目标是推动 SLP 在会议文本处理场景的研究并应对其中的多项核心挑战,包括人人交互场景下多样化的口语现象、会议场景下的长篇章文档建模等。
MUG 挑战赛总共包含五个赛道:Track1-话题分割,Track2-话题及篇章抽取式摘要,Track3-话题标题生成,Track4-关键词抽取,Track5-行动项抽取。
数据集及基线系统见 Github 链接:https://github.com/alibaba-damo-academy/SpokenNLP
竞赛相关技术论文:
https://arxiv.org/abs/2303.13932?Overview?of?the?ICASSP?2023?General?Meeting?Understanding?and?Generation?Challenge?(MUG)
Ditto:?一种简单而有效的改进句子嵌入的方法 ?
以前的研究诊断了预训练语言模型(例如 BERT)在没有进行微调的情况下,其句子表示存在的各向异性问题。我们的分析揭示了 BERT 生成的句子嵌入对无信息词有偏向,这限制了它们在语义文本相似性(STS)任务中的性能。为了解决这种偏差,我们提出了一种简单而有效的无监督方法,即对角线注意力池化(Ditto),该方法利用基于模型的重要性估计对单词进行加权,并计算预训练模型中单词表示的加权平均值作为句子嵌入。Ditto 可以轻松地作为后处理操作应用于任何预训练语言模型。与以往的句子嵌入方法相比,Ditto 既不增加参数,也不需要任何学习。实证评估表明,我们提出的 Ditto 可以缓解各向异性问题,并改善各种预训练模型在 STS 基准上的表现。
观察 1:强调了信息丰富单词的组合对于生成高质量句子嵌入的重要性。?
我们使用了一种无需参数的探究技术——扰动掩码,用于分析预训练语言模型(例如 BERT)。该技术通过对每对标记(x_i, x_j)施加两阶段的扰动过程,来衡量一个标记 x_j 对预测另一个标记 x_i 的影响。与以往研究不同,我们使用扰动掩码技术来分析原始的 BERT 和强大的句子嵌入模型 SBERT。
下图展示了代表英语 PUD 树库中示例句子的影响矩阵 F 的热图。比较 BERT 和 SBERT 的影响矩阵,发现 SBERT 的影响矩阵在诸如“social media”、“Capitol Hill”和“different”等信息丰富的标记上呈现出明显的垂直线,这表明信息丰富的标记对预测其他标记有很大的影响,因此掩盖这些标记可能严重影响句子中其他标记的预测结果。相比之下,BERT 没有呈现这种模式。这一观察表明,信息丰富标记的组合可能是 SBERT 高质量句子嵌入的强有力指标。此外,我们计算了影响矩阵与 TF-IDF 的相关性,发现 SBERT 的影响矩阵与 TF-IDF 的相关性要比 BERT 的影响矩阵高得多,这与上述观察一致。值得注意的是,ELECTRA 在 STS 任务上表现不佳,并且与 TF-IDF 之间的相关性较弱。因此,我们推测原始的 BERT 和 ELECTRA 的句子嵌入可能存在对无信息单词的偏向,从而限制了它们在 STS 任务上的性能。

观察 2:指出了 BERT 的某些自注意力头对应于单词的重要性。
尽管在观察 1 中已经验证 SBERT 与 TF-IDF 的相关性要高于 BERT,但 BERT 仍然显示出了适度的相关性。因此,我们假设信息丰富单词的语义信息已经被编码在 BERT 中,但尚未被充分利用。以往的研究通过将 BERT 的每个自注意头视为一个简单的、无需训练的分类器来分析 BERT 的注意机制,该分类器可根据输入的单词输出其最关注的其他单词。
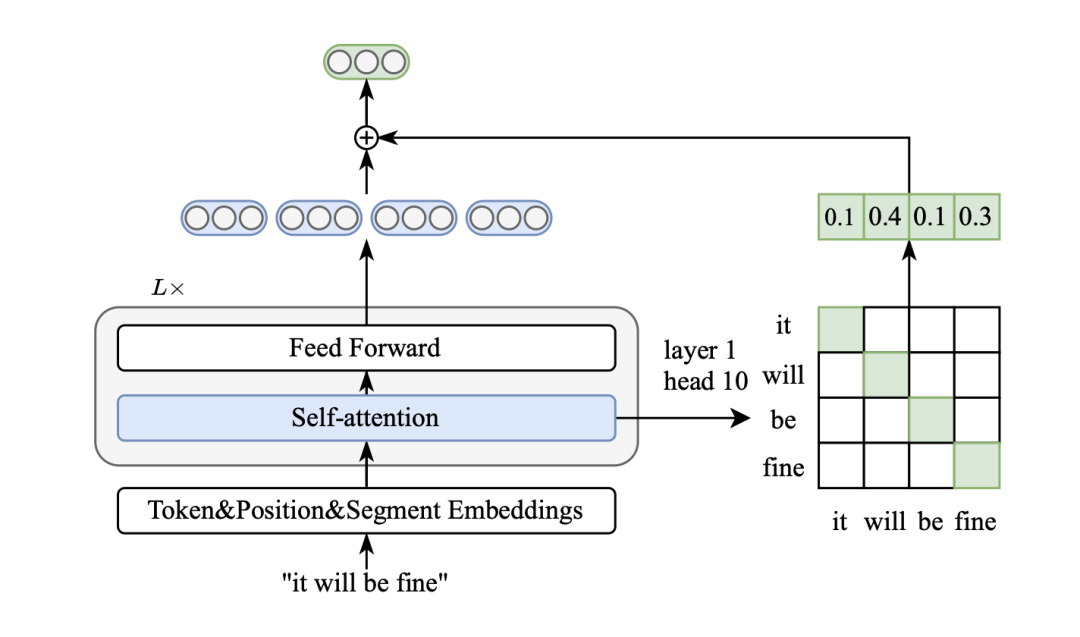
研究发现,某些自注意力头与语法和指代的语言概念相对应,例如,那些关注动词的直接宾语、名词的限定词、介词的宾语和指代性提及的自注意力头的准确性非常高。我们认为 BERT 中的注意力信息需要进一步利用。我们将特定的自注意力头表示为层-头编号(l-h),对于尺寸为 BERT-base 的模型,层的取值范围为 1 至 12,头编号的取值范围为 1 至 12。我们可视化了 BERT 每一层中每个头的注意权重,并关注信息丰富的单词。我们发现,某些自注意力头的从单词到自身的自注意力(即注意力矩阵的对角线值,称为对角线注意力)可能与单词的重要性相关。
正如下图所示,信息丰富的单词“social media transitions”、“hill”和“little”在头 1-10 的注意力矩阵的对角线值较高。BERT 头部 1-10 的注意力权重示意图(左侧)和头部 11-11 的注意力权重示意图(右侧)。线条的深浅代表着注意力权重的数值。注意力矩阵的前五个对角线数值用蓝色标示。

根据在观察部分的两个发现,我们提出了一种新的无需训练的方法,称为"Diagonal Attention Pooling"(Ditto),旨在改善 PLM 的句子嵌入。该方法通过权衡某个头部的对角线注意力来加权隐藏状态,从而获得更好的句子嵌入。Ditto 通过计算 BERT 特定头部的注意力矩阵的对角线值,然后利用这些值加权计算句子嵌入。与基于计算影响矩阵的方法相比,Ditto 更加高效,因为影响矩阵的计算代价较高。该方法的有效性得到了实验证实,同时也具有更高的计算效率。示意图如下图所示。
更多技术细节可以参考我们发表在 EMNLP 2023 的技术论文:
Ditto:?A?Simple?and?Efficient?Approach?to?Improve?Sentence?Embeddings
https://aclanthology.org/2023.emnlp-main.359/
开源代码:https://github.com/alibaba-damo-academy/SpokenNLP/tree/main/ditto
加权采样的掩码语言建模 ?
掩码语言建模(MLM)被广泛用于预训练语言模型。然而,MLM 中的标准随机掩码策略导致了预训练语言模型(PLM)偏向高频标记,罕见标记的表示学习效果不佳,从而限制了 PLM 在下游任务上的性能。为了解决这一频率偏差问题,我们提出了两种简单有效的基于标记频率和训练损失的加权采样策略,用于掩盖标记。通过将这两种策略应用于 BERT,我们得到了加权采样 BERT(WSBERT)。实验表明,WSBERT 在语义文本相似性基准(STS)上的性能显著优于 BERT。在对 WSBERT 进行微调并与校准方法和提示学习相结合后,进一步改善了句子嵌入。我们还研究了在 GLUE 基准上对 WSBERT 进行微调,并展示了加权采样提高了骨干 PLM 的迁移学习能力。我们进一步分析并提供了有关 WSBERT 如何改善标记嵌入的见解。
首先,我们提出了一种对标记频率进行转换的方法,以减少罕见标记的影响。然后,根据转换后的频率计算了每个标记的采样权重。对于句子中的每个标记,根据其计算得到的采样权重进行归一化,计算出掩码该标记的采样概率。
其次,我们提出了动态加权采样策略,旨在解决传统频率加权采样不考虑骨干掩码语言模型学习状态的问题。动态加权采样通过存储每个标记的采样权重并在每个迭代的每个批次之后更新权重字典,而不是在迭代结束后更新权重。在每个小批次中,当前模型预测掩码标记并计算标记的交叉熵损失,然后使用损失值计算采样权重。动态加权采样的设计目的在于扩大不同标记之间的采样权重差异,进一步提高罕见标记的采样概率。在预训练的每个迭代中,权重字典会更新为每个标记的最新采样权重,以便在下一个迭代中使用。

以上是提出的动态加权采样的示意图,用于掩码语言建模(MLM)。选择掩盖标记的采样权重是基于当前 PLM 对该标记的预测损失计算得出的。我们将每个标记的采样权重存储在权重字典中。
更多技术细节可以参考我们发表在 ICASSP 2023 (Top 3% Paper Recognition)?的技术论文:Weighted Sampling for Masked Language Modeling
https://arxiv.org/abs/2302.14225
四、开源概况?
经过 2023 年的建设,Modelscope 魔搭社区语音板块已经初具规模。不仅包含音频领域数十个研究方向的,大量工业级的开源模型,也包含相应的工具包,以及进一步打通了模型的推理、训练、微调和部署的 pipeline。

以下会就 modelscope 配套的几个 github 开源项目进行进一步的介绍。
FunASR 开源项目
前面我们介绍了语音识别服务基本框架,包含语音识别声学模型、音端点检测、标点恢复、时间戳预测等模块。Modelscope 上在各个技术方向上均有性能优越的开源模型。但是如何进一步讲这些开源模型有效的组成服务,打通学术研究和工业应用。
基于此,我们在 github 上发布了 FunASR 工具包。FunASR 希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。
FunASR 开源仓库:https://github.com/alibaba-damo-academy/FunASR
FunASR 社区软件包地址:
https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/readme_cn.md
围绕上述语音识别链路能力,FunASR 提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR 提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。同时推出了语音识别服务部署社区软件包,支持用户便捷高效的部署工业级的语音识别服务。

离线文件转写软件包目前支持中文、英文离线文件转写软件包,结合了通义语音实验室在 Modelscope 社区开源的 FSMN-VAD 语音端点检测、Paraformer 语音识别声学模型、CT-Transformer 标点断句等模型,并提供了可方便快捷部署到本地或者云端服务器的部署流程。开发者可以基于软件包,便捷的构建高精度、高并发、高效率的离线文件转写服务。典型应用场景为,录音文件转写,电话质检,音视频字幕等。
离线文件转写软件包集成了 ffmpeg,支持多种音视频文件格式,包括音频(flac, mp3, ogg, opus, m4a, wav, pcm 等)、视频(mp4、mov、avi、mkv、wmv、flv 等)格式;同时支持时间戳输出,可输出字级别、句子级别时间戳;支持加载 Ngram 语言模型,采用 TLG(Token、Lexicon、Grammar)结构构建统一解码网络,直接将音素/字符序列、发音词典、语言模型编译形成 T、L、G 三个 wfst 子网络,再通过 composition、determinization、minimization 等一系列操作生成统一解码网络,支持从原始语料和发音词典到最终解码资源的全流程编译,便于用户自行定制适合自身的解码资源。
离线文件转写软件包同时支持 Contextual-Paraformer 热词与 wfst 热词增强。Contextual-Paraformer 将 Paraformer 模型作为主体,在 NAR decoder 中引入了一个 multi-headed attention 与最后一层的 cross attention 并列,分别计算 decoder 表征与热词表征、encoder 输出的注意力再进行结合,在解码时支持对用户输入的任意热词进行激励。
wfst 热词增强采用 AC 自动机结构进行热词网络构图,解决热词前缀重叠场景下难以有效激励的问题;采用对主解码网络弧上 ilabel 音素/字符序列信息进行热词发现及匹配,而非在网络搜索出词时再对整词匹配,能够更早实现对尚未出词热词路径激励,避免热词路径被过早误裁减,其次也可避免由于热词分词结构不一致而导致匹配失败;采用过程渐进激励和整词激励相结合的方式,既可以过程中每匹配成功一步即进行等量激励,也可以支持用户针对不同的热词做差异化的激励分配置,在热词整词出词时进一步施加对应的补偿或惩罚,进而提高热词综合效果。

实时语音听写软件包集成了实时语音端点检测模型(FSMN-VAD-realtime),语音识别实时模型(Paraformer-online),语音识别非流式模型(Paraformer-offline),标点预测模型(CT-Transformer)。
采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,开发者可以基于软件包,便捷的构建高精度、高并发、高效率的实时语音听写服务。典型应用场景为,会议场景实时听写,人机交互场景对话,数字人/虚拟人,大语言模型语音输入等。
实时语音听写支持以下几种推理模式:
1)实时语音听写服务(ASR-realtime-transcribe):客户端连续音频数据,服务端检测到音频数据后,每隔 600ms 进行一次流式模型推理,并将识别结果发送给客户端。同时,服务端会在说话停顿处,做标点断句恢复,修正识别文字。
2)非实时一句话转写(ASR-offline-transcribe):客户端连续音频数据,服务端检测到音频数据后,在说话停顿处进行一次非流式模型推理,输出带有标点文字,并将识别结果发送给客户端。
3)实时与非实时一体化协同(ASR-realtime&offline-twoPass):客户端连续音频数据,服务端检测到音频数据后,每隔 600ms 进行一次流式模型推理,并将识别结果发送给客户端。同时,服务端会在说话停顿处,进行一次非流式模型推理,输出带有标点文字,修正识别文字。
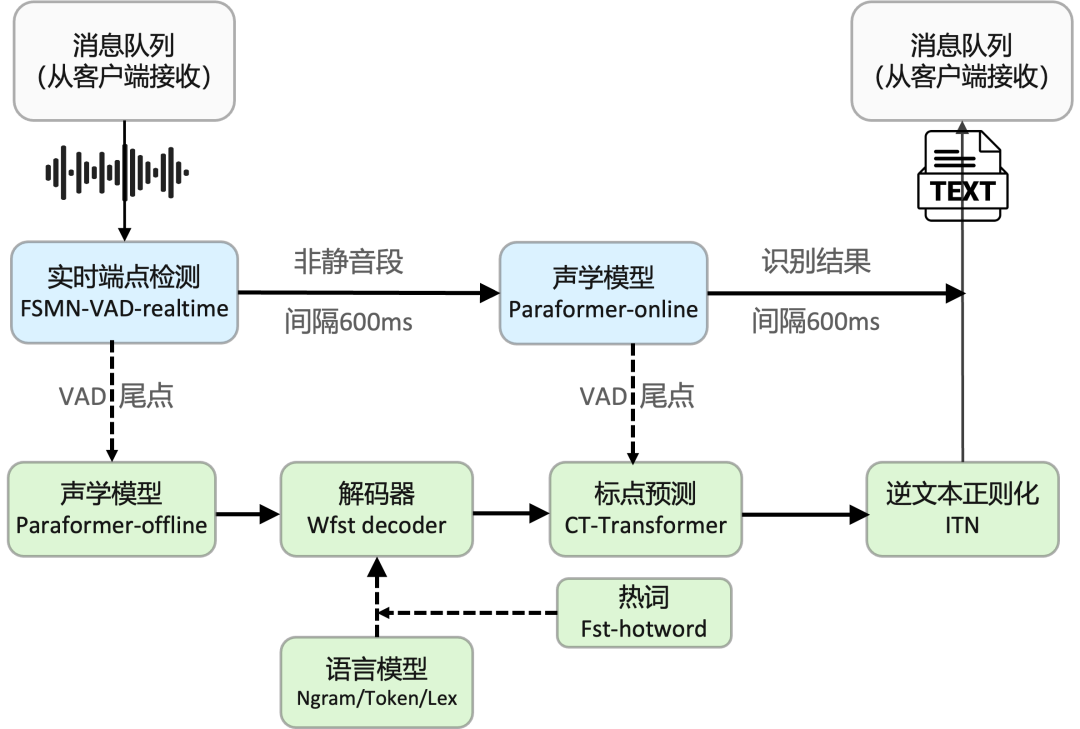
FunCodec
FunASR 的主要功能集中在对语音的识别和理解方面,相当于给机器加上了耳朵,而 FunCodec 的主要目标则是语音的量化表示与生成,即给机器加上嘴巴的能力。
语音量化(Speech Codec)的目的是将语音信号编码为一个个离散的 token,在语音通信和存储领域具有广泛的应用场景。近些年,得益于深度神经网络的快速发展,研究者们提出了基于神经编解码的语音量化模型。与基于专家知识的传统语音量化方法相比,基于神经网络的模型在更低的码率下获得了更高的语音质量。
与此同时,语音的量化编码也使大规模语言模型 LLM 具备了统一建模语音和文本的能力,例如 VALL-E 语音合成模型、VioLA、AudioPALM 等语音-文本理解模型等。在此背景下,我们开源了 FunCodec 语音量化编码工具包。
-
它提供了 SoundStream、Encodec 等 SOTA 模型的开源实现,以及我们在标准学术数据和内部大规模数据上的预训练模型,希望以此加速该领域的相关研究;
-
考虑到语音在时频域上的结构性,我们进一步提出了时频域的量化模型,它能够在保证量化语音质量的基础上,只需更少的参数和计算量。我们发现频域模型对包括语音在内的音频信号具备更好的建模能力,未来我们将会在 FunCodec 发布统一音频量化模型,能够处理各种各样的音频信号,包括:语音、声学事件、音乐等;
-
为了探究声学-语义解耦对语音量化带来的影响,我们提出了 semantic augmented 的 residual vector quantizer 模块,在极低比特率下展现了较高的语音质量。
以上所有模型都已在 ModelScope 开源。与语音量化模型一同,我们还会在 FunCodec 中发布 LauraGPT、VALL-E、SpearTTS 等基于离散 token 的语音合成模型。

FunCodec?模型结构
论文预印版下载地址:
https://arxiv.org/abs/2309.07405v2
FunCodec 开源代码:
https://github.com/alibaba-damo-academy/FunCodec
FunCodec 开源模型:
https://www.modelscope.cn/models?page=1&tasks=audio-codec&type=audio
3D-Speaker 开源项目
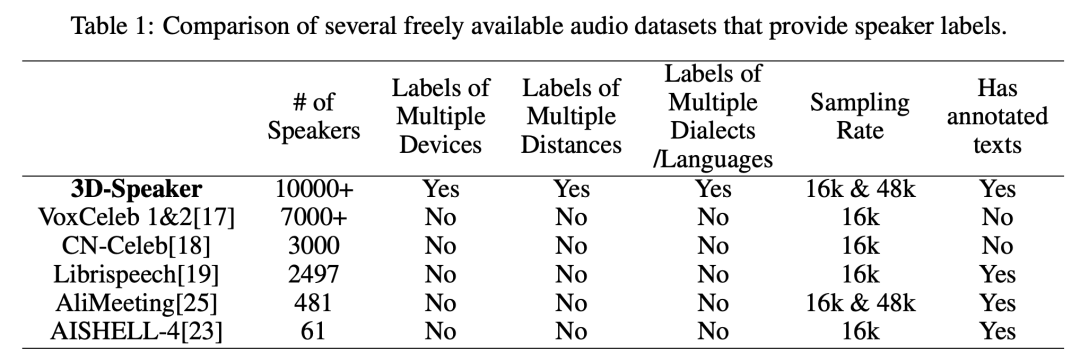
3D-Speaker 是通义实验室语音团队今年推出的说话人相关的开源项目。3D-Speaker 的名称有两层含义,一是包含声学信息、语义信息、视觉信息 3 种模态的说话人识别技术,二是开源了一个多设备(multi-Device)、多距离(multi-Distance)和多方言(multi-Dialect)中文说话人语音数据集。
3D-Speaker 开源项目包含说话人识别,说话人确认以及说话人分割任务的训练及推理代码,以及 ModelScope 上开源的相关预训练模型。
项目地址:https://github.com/alibaba-damo-academy/3D-Speaker

3D-Speaker 数据集,包含超过 1 万名说话人,其中训练集 10000 人,测试集 240 人。我们数据在录制时每个说话人同时在多个设备上进行录音,多个设备距离声源不同位置,有些说话人还使用多种方言。我们的数据集包括 8 种设备、14 种中文方言以及 0.1m~4m 等 12 种距离。
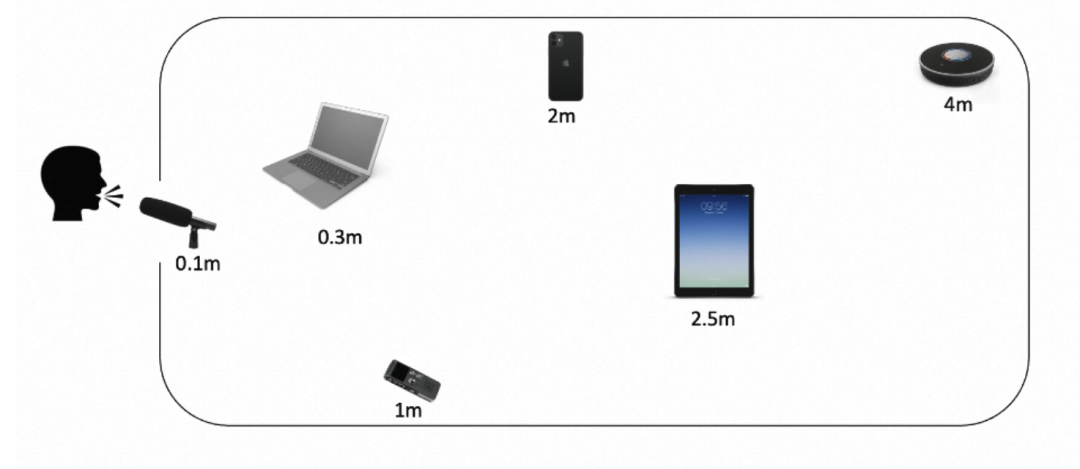
针对说话人验证任务,我们提供了三个标准测试 trials:Trials Cross-Device、Trials Cross-Distance 和 Trials Cross-Dialect。针对方言语种识别(LID)任务,我们也提供了一个标准测试集以让结果容易比较。3D-Speaker 数据使用 CC BY-SA 4.0 协议。
我们数据网站地址:https://3dspeaker.github.io/,提供了数据下载链接以及发布的 baseline 等信息。我们在文章中汇报的相关模型(ERes2Net、CAM++等)以及数据的一些预处理代码也已开源,请参考我们的开源项目https://github.com/alibaba-damo-academy/3D-Speaker。如果您基于 3D-Speaker 数据做出了优秀的结果,也非常欢迎向我们的榜单上提交您的结果。
相关论文:https://arxiv.org/pdf/2306.15354.pdf
Autolabeling 开源项目
Autolabel 是我们今年推出的音频自动化标注工具,该工具集成了语音实验室多种原子能力,如语音降噪(ANS)、语音识别(ASR)、语音端点检测(VAD)、时间戳预测(FA)、韵律标注(PWPP)等,使得用户可以使用已有的音频,直接通过?一个 Autolabel 工具,获取音频所对应的文本、音素、音素时间戳、韵律标注等多种标注信息,适配于后续的语音合成及其他相关任务,如轻量化定制和大规模语音数据标注等。目前该工具的下载量达到 11w+。
Modelscope 地址:https://modelscope.cn/models/damo/speech_ptts_autolabel_16k

在 Autolabel 中,支持三种采样率(16k 24k 48k)音频的输入,首先通过 ANS 对其进行降噪,其次为保证切分后的音频长度合适且尽可能保留语音完整性,对降噪后音频进行多个阈值的 VAD 切分和 ASR 获取对应文本,然后通过文本转音素和 FA 获取音素及其对应时间戳,再根据文本和真实音频标注 PWPP 进行韵律标注预测,最后整理所有生成对应标注。其中如 ANS 和 VAD 对音频有特殊处理等为可选工具。
KAN-TTS 开源项目
KAN-TTS 是通义实验室语音团队开源的一套语音合成模型训练框架,包含 Sambert、nsf-hifigan 等模型的训练、推理脚本,能够训练出具有高自然度和韵律丰富度的语音合成模型。
KAN-TTS 支持中、英、日、德、韩等十一种外语和上海话、四川话、粤语等多地方言的数据处理,目前 KAN-TTS 已在 ModelScope 开源社区贡献了 40 多个语音合成模型,覆盖多情感、多语言、个性化人声定制等多个类别。同时 KAN-TTS 还配套了自动化数据标注工具 AutoLabel,开发者可根据这套 toolkit 自由定制自己的语音合成模型。
KAN-TTS github 仓库地址:https://github.com/alibaba-damo-academy/KAN-TTS
KAN-TTS ModelScope 模型列表:https://www.modelscope.cn/models?page=1&tasks=text-to-speech&type=audio

我们不断完善和更新开源项目内容,建立开放的开发者社区答疑,如果您有相关项目切磋交流,欢迎在项目中给我们留言。
特别鸣谢本文作者(排名不分先后):游雁、可渊、凌匀、维石、语帆、志浩、嘉渊、雾聪、谵良、实一、云楚、斯奇、神霄、浮名、格真、童牧、恕黎、则济、虎跑、潭清、温良、明斋、翼海、琋达。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 沃尔玛、亚马逊、美客多新手快速出单,如何通过自养号测评提升销量和评价?
- [NOIP2014 提高组] 生活大爆炸版石头剪刀布#洛谷
- 【leetcode题解C++】459.重复的子字符串 and 28.找出字符串中第一个匹配项的下标
- 代码随想Day57 | 647. 回文子串、516.最长回文子序列
- word段落对齐
- 程序员必备的面试技巧
- 【温故而知新】HTML5 服务器发送事件
- Springboot整合Flowable Modeler(flowable6.4.0)
- 计算机毕业设计----ssm大学生兼职论坛
- java mango