建立分位制,用标准去量化优化效果 - 启动优化为例
Android开发的四年多时间中,逐渐将自己的工作重心从业务移动到小型项目的架构设计,在此过程中代码的书写有了更高的标准和要求,性能优化从此伴随着工作脚步, 为什么要进行性能优化呢?
- 页面访问时长从1s增加到3s,用户跳出率增加32%
- 崩溃率直接影响用户留存
- 卡顿会让用户选择放弃
等等
在互联网蓝海逐渐缩小的时代,圈人依然是每个互联网公司的目标,当有足够大的使用人数时变现、营销等都将能实现,所以提升用户体验是不可或缺的部分
背景:
在团队开发中,如何定义优化的效果,我想是可以进行量化的,将自己的应用的各个部分进行解体,完全掌握,然后和业内特别是竞品进行比较,做到知己知彼,才能百战百胜。
以下以启动优化作为案例:
一、建立启动优化耗时标准
针对优化我们需要知道优化的当前目标和优化后的目标是多少?该目标就是 — 启动耗时
3.1 统计启动耗时
很多应用把启动结束时间的统计放到首页刚出现的时候,这对用户是不负责任的,看到一个首页,但是停住十几秒都不能滑动,这对用户来说完全没有意义 ,所以我们需要着眼于从点击图标到用户可操作的整个过程
3.2 建立分位置
- 比如应用启动耗时从500ms~1500ms对应分为值为100 ~ 0(分)
比如应用启动耗时80分位值为我们APP的标准启动耗时分位值,而80分位值的对应时间为600ms, 所有用户的启动分位值计算出满足80分位值的用户,占比就说明有多少的情况下用户启动APP都能在 600ms 内完成,而我们需要做的就是让更多的用户达到指定的分位值。
- 此时我们通过在线上打点统计用户实际的启动耗时、机型归属(确定低、中、高端机)
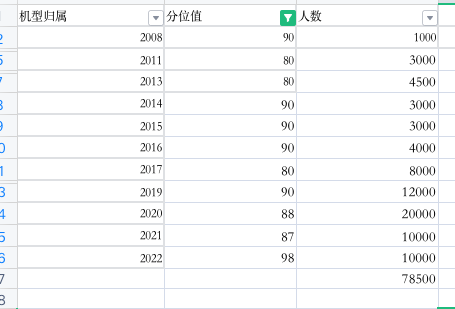
(以下为假设APP启动机型和分位值统计所得数据)
| 机型归属 | 分位值 | 人数 |
|---|---|---|
| 2008 | 90 | 1000 |
| 2009 | 70 | 1200 |
| 2010 | 60 | 200 |
| 2011 | 80 | 3000 |
| 2012 | 20 | 4000 |
| 2013 | 80 | 4500 |
| 2014 | 90 | 3000 |
| 2015 | 90 | 3000 |
| 2016 | 90 | 4000 |
| 2017 | 80 | 8000 |
| 2018 | 70 | 10000 |
| 2019 | 90 | 12000 |
| 2020 | 88 | 20000 |
| 2021 | 87 | 10000 |
| 2022 | 98 | 10000 |
(以下为数据对应图表)

(以下针对上述图表进行结论总结)

- 达到分位值的用户
总人数为93900人,达标用户总数为78500人,其中高端机用户为74500人,低端机用户为4000人
达标率 = 78500/93900 ≈ 84%
低端机占比 = 4000 / 78500 ≈ 5%
总人数:

达标用户
其中高端机
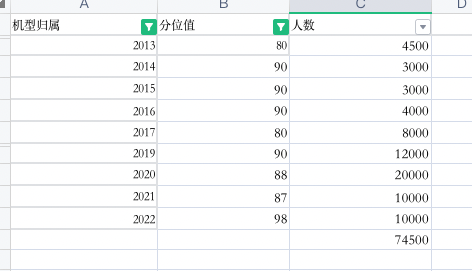
低端机占比

至此我们就知道了应用目前的情况
一、启动过程分析

- T1 预览窗口显示
系统在拉起进APP程之前,会先根据APP的 Theme 属性创建预览窗口。当然如果我们禁用预览窗口或者将预览窗口指定为透明,用户在这段时间依然看到的是桌面。(用户可能觉得是手机卡顿而非应用卡顿)
- T2 闪屏显示
在APP进程和闪屏窗口页面创建完毕,并且完成一系列 inflate view、onmeasure、onlayout 等准备工作后,用户终于可以看到欢迎页面。
- T3 主页显示
在完成主窗口创建和页面显示的准备工作后,用户可以看到APP的主界面。
- T4 界面可以操作
在启动完成后,APP会有比较多的工作需要继续执行(初始化的东西按需分配至不同阶段),(比如微信聊天和朋友圈界面的预加载、小程序框架和进程的准备等。在这些工作完成后,用户才可以真正开始愉快地聊天。)
二、启动问题分析
以上4个启动的关键阶段,可以推测一下启动过程中越到的问题和平常在使用中会出现的问题相结合,基本为以下三个:
- 点击图标之后很久不响应
如果我们禁用了预览窗口或者指定了透明的皮肤,那用户点击了图标之后,需要 T2 时间才能真正看到应用闪屏。对于用户体验来说,点击了图标,过了几秒还是停留在桌面,看起来就像没有点击成功,这在中低端机中更加明显。
- 首页显示太慢
现在应用启动流程越来越复杂,闪屏广告、
热修复框架、插件化框架、大前端框架,所有准备工作都需要集中在启动阶段完成。上面说的 T3 首页显示时间对于中低端机来说简直就是噩梦,经常会达到十几秒的时间。
- 首页显示后无法操作
既然首页显示那么慢,那我能不能把尽量多的工作都通过异步化延后执行呢?很多应用的确就是这么做的,但这会造成两种后果:要么首页会出现白屏,要么首页出来后用户根本无法操作。
四、优化工具
对于优化Android拥有非常多的优化工具,Traceview、Nanoscope (非常真实,不过暂时只支持 Nexus 6P 和 x86 模拟器,无法针对中低端机做测试)。
systrace 可以很方便地追踪关键系统调用的耗时情况,但是不支持应用程序代码的耗时分析。
综合来看,“systrace + 函数插桩”似乎是比较理想的方案,而且它还可以看到系统的一些关键事件,例如 GC、System Server、CPU 调度等。
- 查看支持的类型
python systrace.py --list-categories
通过插桩,我们可以看到应用主线程和其他线程的函数调用流程。它的实现原理非常简单,就是将下面的两个函数分别插入到每个方法的入口和出口。
class Trace {
public static void i(String tag) {
Trace.beginSection(name);
}
public static void o() {
Trace.endSection();
}
}
当然这里面有非常多的细节需要考虑,比如怎么样降低插桩对性能的影响、哪些函数需要被排除掉(可在debug环境下使用)
只有准确的数据评估才能指引优化的方向,这一步是非常非常重要的。
五、优化方式
在拿到整个启动流程的全景图之后,我们可以清楚地看到这段时间内系统、应用各个进程和线程的运行情况
可分为以下优化模块:
5.1 闪屏优化
- 预览窗口window属性设置,让体验出现跟手感觉
- 合并闪屏和主页面的Activity,减少一个Activity会给线上带来100ms的优化 (管理复杂)
5.2 业务梳理
我们首先需要梳理清楚
- 当前启动过程正在运行的每一个模块,哪些是一定需要的、哪些可以砍掉、哪些可以懒加载。
- 可以根据业务场景来决定不同的启动模式,例如通过扫一扫启动只需要加载需要的几个模块即可。对于中低端机器,我们要学会降级,学会推动产品经理做一些功能取舍。但是需要注意的是,懒加载要防止集中化,否则容易出现首页显示后用户无法操作的情形。
5.3 线程优化
- 线程优化就像做填空题和解锁题,我们希望能把所有的时间片都利用上,因此主线程和各个线程都是一直满载的。当然我们也希望每个线程都开足马力向前跑,而不是作为接力棒。所以线程的优化主要在于减少 CPU 调度带来的波动,让应用的启动时间更加稳定
从具体的做法来看,线程的优化一方面是控制线程数量,线程数量太多会相互竞争 CPU 资源,因此要有统一的线程池,并且根据机器性能来控制数量。
线程切换的数据我们可以通过卡顿优化中学到的 sched 文件查看,这里特别需要注意 nr_involuntary_switches 被动切换的次数。
可以使用命令
proc/[pid]/sched
- 其中:
-
- nr_voluntary_switches: 主动上下文切换次数,因为线程无法获取所需资源导致上下文切换,最普遍的是IO。
- nr_involuntary_switches: 被动上下文切换次数,线程被系统强制调度导致上下文切换,例如大量线程在抢占CPU。
- 另一方面是检查线程间的锁
各APP做启动优化时并行初始化是优化的手段之一,但是有的情况下并发初始化会因为书写而不起作用
线程内部会持有一个锁,主线程很快就执行完了,其他任务因为这个锁而等待。这样的话主线程就出现了空转的场景,可以通过systrace看锁等待事件,我们要以此排查是否需要做对应的优化
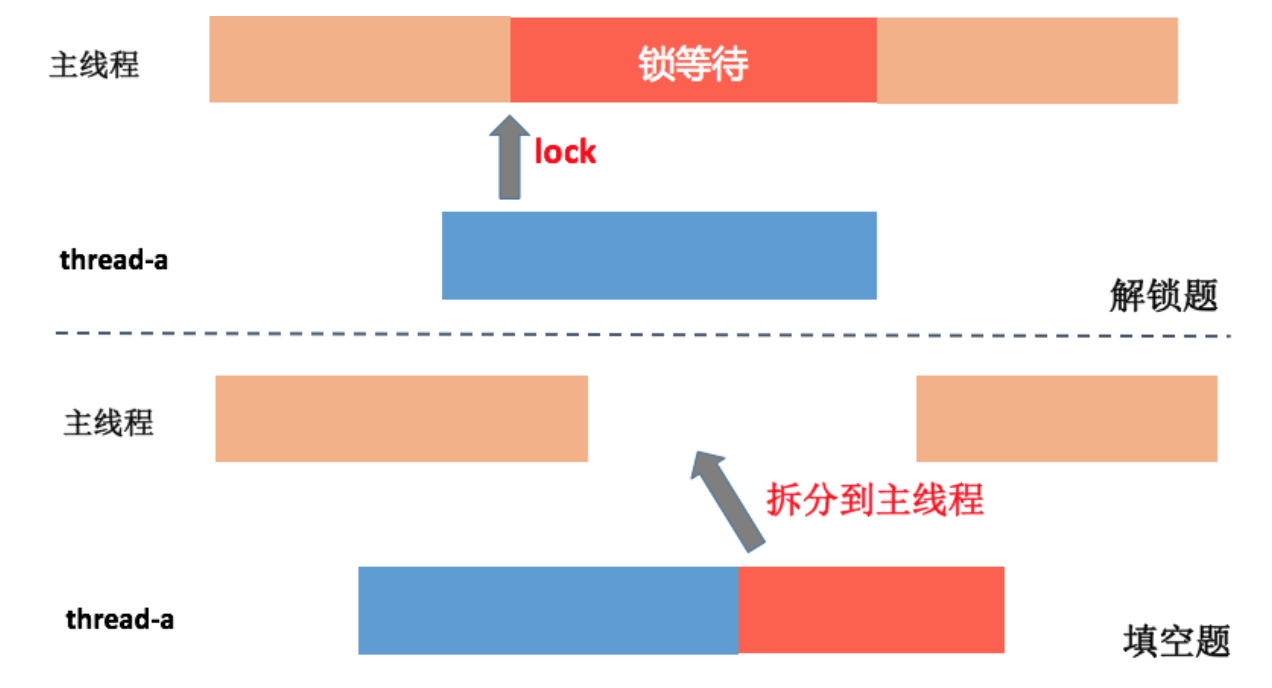
在做初始化优化时,一般会将业务进行优先级区分,业务优先级规定业务初始化的时机,比较火的启动框架大多采用:为各个人物建立依赖关系,最终构成一个有向无环图,对于可以并发的任务,会通过线程池最大程度提升启动速度。
当出现并-总模式时,配置不恰当就会出现以下问题:

即:主线程一直等待taskC 结束,空转2950ms
5.4 GC优化
在启动过程,要尽量减少 GC 的次数,避免造成主线程长时间的卡顿,特别是对 Dalvik 来说,我们可以通过 systrace 单独查看整个启动过程 GC 的时间。
python systrace.py dalvik -b 90960 -a com.sample.gc
也可以采用Debug.startAllocCounting 来监控启动过程中GC的耗时情况,特别是阻塞式同步 GC 的总次数和耗时
// GC使用的总耗时,单位是毫秒
Debug.getRuntimeStat("art.gc.gc-time");
// 阻塞式GC的总耗时
Debug.getRuntimeStat("art.gc.blocking-gc-time");
如果我们发现主线程出现比较多的 GC 同步等待,那就需要通过 Allocation 工具做进一步的分析启动过程避免进行大量的字符串操作,特别是序列化跟反序列化过程。一些频繁创建的对象,例如网络库和图片库中的 Byte 数组、Buffer 可以复用。如果一些模块实在需要频繁创建对象,可以考虑移到 Native 实现。
Java 对象的逃逸也很容易引起 GC 问题,我们在写代码的时候比较容易忽略这个点。我们应该保证对象生命周期尽量的短,在栈上就进行销毁。
Java 逃逸分析 https://segmentfault.com/a/1190000016803174
5.5 系统调用优化
- 通过 systrace 的 System Service 类型,我们可以看到启动过程 System Server 的 CPU 工作情况。在启动过程,我们尽量不要做系统调用,例如 PackageManagerService 操作、Binder 调用等待。
- 在启动过程也不要过早地拉起应用的其他进程,System Server 和新的进程都会竞争 CPU 资源。特别是系统内存不足的时候,当我们拉起一个新的进程,可能会成为“压死骆驼的最后一根稻草”。它可能会触发系统的 low memory killer 机制,导致系统杀死和拉起(保活)大量的进程,从而影响前台进程的 CPU。
在我们应用中IM进程和File下载进程的拉起时机需要做调整
5.6 高级性能优化
可以更多的参考腾讯的matrix, 从性能的根本问题上进行了解决 https://github.com/Tencent/matrix
设备分级:
上文提到的设备分级,在这里说明一下
核心思想:
设备分级是指Device-year-class ,它是Facebook 开源的一个Android库,实现原理是将一个手机的内存(RAM)、CPU内存和clock speed((主频)时钟速度)三个方面映射到指定的一个组合中,通过这个验证来判断你是那一年的,规格的高低决定你是”那一年“的而不是手机的生产年份。(当然我们可以根据自己的需求定义这些参数,比如音视频公司可以从CPU、GPU等音视频相关参数出发定位等)
实现流程图
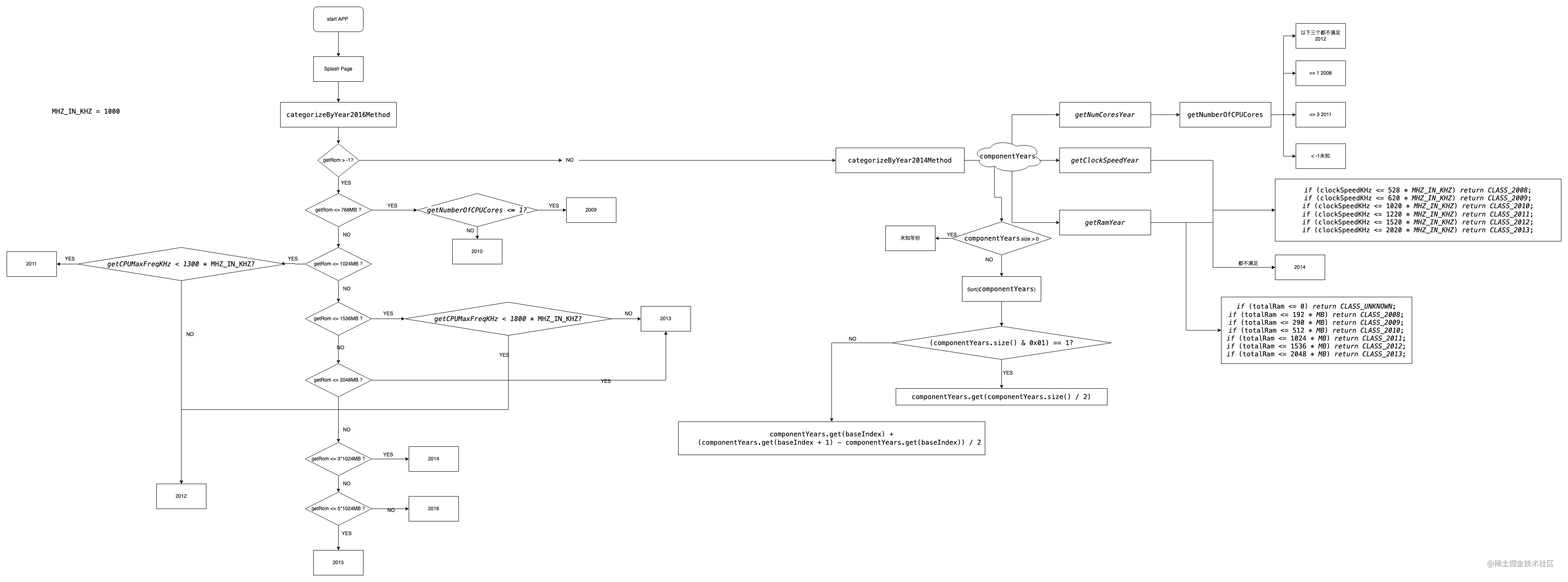
作用
针对机型进行适配,让每一份努力都能展现到对应的用户面前
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码获取方式
- 婴儿洗衣机哪款性价比高?希亦、RUUFFY、觉飞全维度测评对比
- ML Design Pattern——Batch Serving
- 网络基础知识
- spring web接收请求日志,动态调整
- 性能测试-jemeter:安装 / 基础使用
- Simulink|电力系统风储联合一次调频仿真模型
- RabbitMQ之延迟队列解读
- 蓝桥杯、编程考级、NOC、全国青少年信息素养大赛—scratch列表考点
- yarn install禁止运行脚本