SQL语句 - 查询语句
Data Query Language
文章目录
数据查询(DQL)
关系结构数据库是以表格形式进行数据存储,由“行”和“列”组成。
| id | name | sex |
|---|---|---|
| 1 | 张三 | 男 |
| 2 | 李四 | 女 |
| 3 | 王五 | 男 |
| 4 | 赵六 | 女 |
- row:行(代表一条记录)
- col:列(代表一个字段)
执行数据库查询时,返回的结果集是一张虚拟表。
基础查询
1 基本查询
语法:SELECT 列名 FROM 表名;
| 关键字 | 描述 |
|---|---|
| SELECT | 指定要查询的列 |
| FROM | 指定要查询的表 |
注意:
- 生产环境下,优先使用列名查询。
- * 的方式需转换成全列名,效率低,可读性差。
1.1 查询所有列:
代码演示:
#1 查询所有列 * 表示所有列
#需求:查询员工表的所有列
select * from t_employees;
1.2 查询部分列:
代码演示:
#2 查询部分列, 根据列名查询
#需求 查询员工的编号,姓名,薪资
select employee_id,first_name,salary from t_employees;
1.3 对查询到的列中数据进行运算
| 算数运算符 | 描述 |
|---|---|
| + | 加法运算 |
| - | 减法运算 |
| * | 乘法运算 |
| / | 除法运算 |
| % (作为模运算,也可以作为占位符) | 取模运算 |
代码演示:
#3 对查询中的列进行运算
#需求 查询员工的编号,姓名,月薪,年薪
select employee_id,first_name,salary,salary*12 from t_employees;
1.4 列的别名:
代码演示:
#4 对查询的列起别名
#需求 查询员工的编号,姓名,年薪,并起别名
select employee_id as 编号, first_name as 名字, salary*12 as 年薪 from t_employees;
1.5 查询结果去重:
代码演示:
#5 对查询结果去重,distinct
#需求 查询月薪
select salary from t_employees
#去重后
select distinct salary from t_employees
#需求 查询月薪、提成
select distinct salary, commission_pct from t_employees
2 排序查询
对查询的结果进行排序
语法:SELECT 列名 FROM 表名 ORDER BY 排序列 [排序规则];
| 排序规则 | 描述 |
|---|---|
| ASC | 对前面排序的列做升序排序 |
| DESC | 对前面排序的列做降序排序 |
2.1 依据单列排序:
代码演示:
#1 依据单列
#需求: 查询员工的编号,名字,工资,并按照工资降序排列
select employee_id,first_name,salary from t_employees order by salary desc;
2.2 依据多列排序:
代码演示:
#2 依据多列
#需求:查询员工的编号,名字,工资,
#并按照工资降序排列,如果工资一样,按照员工的编升序排列
select employee_id,first_name,salary from t_employees order by salary desc,employee_id asc;
3 条件查询
语法:SELECT 列名 FROM 表名 WHERE 条件;
| 关键字 | 描述 |
|---|---|
| WHERE | 在查询结果中,筛选符合条件的查询结果,条件为布尔表达式 |
3.1 等值判断(=): 既可以判断,也可以赋值
**注意:**与java不同(==),mysql中等值判断使用=
代码演示:
#1 等值判断, 使用 = 判断
#需求: 查询工资等于11000的员工的编号,姓名,工资
select employee_id ,first_name ,salary
from t_employees
where salary = 11000;
3.2 逻辑判断(AND、OR、NOT)
代码演示:
#2 逻辑判断, and 并且; or 或; not 非;
#需求: 查询工资等于11000并且提成为0.3的员工编号,姓名,工资,提成
select employee_id ,first_name ,salary ,commission_pct
from t_employees
where salary = 11000 and commission_pct = 0.3;
3.3 不等值判断(> 、< 、>= 、<= 、!= )
代码演示:
#3 不等值判断 > < >= <= !=
#需求: 查询工资大于等于6000并且小于等于10000的员工信息
select employee_id, first_name, salary
from t_employees
where salary >= 6000 and salary <= 10000;
3.4 区间判断(BETWEEN AND)
代码演示:
#4 区间判断, between and
#需求: 查询工资大于等于6000并且小于等于10000的员工信息,并以工资的升序排列
select employee_id, first_name, salary
from t_employees
where salary between 6000 and 10000
order by salary asc;
注意:在区间判断语法中,小值在前,大值在后,反之,得不到正确结果。
3.5 NULL 值判断
- 列名 IS NULL。
- 列名 IS NOT NULL。
代码演示:
#5 null值判断, 使用 is null 为空 is not null 不为空
#需求: 查询提成为空的员工信息
select employee_id ,first_name ,salary ,commission_pct
from t_employees
where commission_pct is null;
3.6 枚举查询, in(值1,值2,…,值n)
代码演示:
#6 枚举查询, in(值1,值2,...,值n)
#查询部门编号为70,80,90的员工信息
select employee_id ,first_name ,salary, department_id
from t_employees
where department_id in(70,80,90);
注:in的查询效率较低,可通过多条件拼接。
3.7 模糊查询(LIKE 通配符)
- 列名 LIKE ‘张_’ 单个任意字符。
- 列名 LIKE ‘张%’ 任意长度的任意字符。
代码演示:
#模糊查询(like 通配符)
#列名 like '张_' : 表示任意单个字符
#列名 like '张%' : 任意长度的任意字符
#需求: 查询名字以"L"开头的员工信息
select employee_id, first_name, department_id
from t_employees
where first_name like 'L%'
#需求: 查询姓为L开头的长度为4个的名字
select employee_id, first_name, department_id
from t_employees
where first_name like 'L___'
注意:模糊查询只能和LIKE关键字结合使用。
4 分支结构查询
语法: 通过使用CASE END进行条件判断,每条数据对应一个结果。
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
ELSE 结果4
END
执行流程:
- 如果条件1满足,则显示结果1。
- 如果条件2满足,则显示结果2。
- 如果条件3满足,则显示结果3。
- 如果以上条件均不满足,显示结果4。
**经验:**类似Java中的多重选择结构。
代码演示:
#需求: 查询员工工资,按照等级显示
#工资大于等于15000显示高, 大于等于10000显示中, 大于等于5000显示一般, 否则显示低
select employee_id,first_name,salary,
case
when salary >= 15000 then '高'
when salary >= 10000 then '中'
when salary >= 5000 then '一般'
else '低'
end as level
from t_employees
5 查询函数
**经验:**执行函数查询,会自动生成一张虚拟表(一行一列)。
5.1 时间函数
语法:SELECT 时间函数([参数列表]);
| 时间函数 | 描述 |
|---|---|
| SYSDATE()、NOW() | 当前系统时间(日、月、年、时、分、秒)。 |
| CURDATE() | 获取当前日期。 |
| CURTIME() | 获取当前时间。 |
| WEEK(DATE) | 获取指定日期为一年中的第几周。 |
| YEAR(DATE) | 获取指定日期的年份。 |
| HOUR(TIME) | 获取指定时间的小时值。 |
| MINUTE(TIME) | 获取时间的分钟值。 |
| DATEDIFF(DATE1,DATE2) | 获取DATE1和DATE2之间相隔的天数。 |
| ADDDATE(DATE,N) | 计算DATE加上N天后的日期。 |
代码演示:
#函数: 封装特定功能的一段代码, 类似于Java中的方法
#1 时间函数
# sysdate(),now() 获取当前日期时间
select sysdate(),now();
# curdate(); 获取当前日期
select curdate();
# curtime(); 获取当前时间
select curtime();
# year() month() day() hour() minute() second() week()
select year(now()),month(now()),day(now()),hour(now()),minute(now()),second(now()),week(now())
# datediff(); 获取两个日期之间相隔的天数
select datediff('2024-1-24','2024-1-1');
# adddated(); 在指定日期后加上指定的天数
select adddate('2024-1-24',10);
5.2 字符串函数
语法:SELECT 字符串函数 ([参数列表]);
| 字符串函数 | 描述 |
|---|---|
| CONCAT(str1,str2,str…) | 将多个字符串连接。 |
| INSERT(str,pos,len,newStr) | 将str中指定pos位置开始len长度的内容替换为newStr。下标从1 开始 |
| LOWER(str) | 将指定字符串转换为小写。 |
| UPPER(str) | 将指定字符串转换为大写。 |
| SUBSTRING(str,pos,len) | 将str字符串指定pos位置开始截取len个内容。下标从1开始 |
| LENGTH | 获取字符串的字节长度 |
| CHAR_LENGTH | 获取字符串字符长度 |
代码演示:
#2 字符串函数
# concat(); 字符串合并
select concat('hello','world');
# insert(); 插入替换指定的字符
select insert('MySQL是世上最流行的关系型数据库',1,0,'Oracle');
# lower(); upper();
select lower('HELLO'),upper('hello');
# substring(); 字符串截取, 位置从1开始
select substring('MySQL是世上最流行的关系型数据库',1,5);
# length();获取字节长度 char_length();获取字符长度
select length('MySQL是世上最流行的关系型数据库'),char_length('MySQL是世上最流行的关系型数据库');
5.3 聚合函数
语法:SELECT 聚合函数(列名) FROM 表名;
| 聚合函数 | 描述 |
|---|---|
| SUM() | 求所有行中单列结果的总和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| COUNT() | 总行数 |
代码演示:
#3 聚合函数
# sum() 求和 avg() 求平均值 max() 最大值 min() 最小值 count() 数据个数
select sum(salary),avg(salary),max(salary),min(salary) from t_employees;
# 需求: 查询所有员工的个数,count(*), count(数字), 不要写字段(不包含值为null的数据)
select count(*) from t_employees;
5.4 其他函数
| 函数名称 | 描述 |
|---|---|
| DATABASE() | 获取当前选择的数据库 |
| IFNULL(str,0) | 如果str为NULL,则返回0 |
| USER() | 返回当前用户 |
| VERSION() | 返回MySQL版本 |
代码演示:
#4 其他函数
# database(); 获取当前选择的数据库
select database();
# ifnull(); 判断是否为null,如果为null,可设置默认值
#需求: 查询所有员工的工资+提成
select salary+(salary*ifnull(commission_pct,0)) from t_employees;
# user(); 获取当前用户
select user();
# version(); MySQL版本
select version();
6 分组查询
语法:SELECT 列名 FROM 表名 GROUP BY 分组依据(列);
代码演示:
#分组查询
#语法 SELECT 列名 FROM 表名 GROUP BY 分组依据(列);
#注意: 分组后的查询列,只能是分组列, 或聚合函数列
#需求: 查询各部门总人数, 平局工资
SELECT department_id, avg(salary),count(*)
FROM t_employees
GROUP BY department_id;
**注意:分组查询中,select显示的列只能是分组依据列,或者聚合函数列,不能出现其他列。**4
7 分组过滤查询
语法:SELECT 列名 FROM 表名 GROUP BY 分组列 HAVING 过滤规则;
代码演示:
#分组过滤查询
#语法 SELECT 列名 FROM 表名 GROUP BY 分组列 HAVING 过滤规则;
#需求: 查询各部门平局工资, 筛选平均工资大于等于10000的部门
SELECT department_id, avg(salary)
FROM t_employees
GROUP BY department_id
HAVING avg(salary) >= 10000;
注意:HAVING是对分组之后的数据做过滤。
8 限定查询
语法:SELECT 列名 FROM 表名 LIMIT 起始行,查询行数;
| 关键字 | 描述 |
|---|---|
| LIMIT offset_start,row_count | 限定查询结果的起始行和总行数 |
代码演示:
#限定查询
#语法: SELECT 列名 FROM 表名 LIMIT 起始行,查询行数;
#需求: 查询员工表的前五条数据
SELECT employee_id, first_name, salary
FROM t_employees
LIMIT 0,5;
#需求: 查询员工表的第二个五条数据
SELECT employee_id, first_name, salary
FROM t_employees
LIMIT 5,5;
#需求: 查询员工表的第三个五条数据
SELECT employee_id, first_name, salary
FROM t_employees
LIMIT 10,5;
注意:
- 起始行是从 0 开始,代表了第一行。
- 第二个参数代表的是从指定行开始查询几行。
9 基础查询总结
SQL语句编写顺序:
-
SELECT 列名
-
FROM 表名
-
WHERE 条件
-
GROUP BY 分组
-
HAVING 过滤条件
-
ORDER BY 排序列(ASC|DESC)
-
LIMIT 起始行,数据个数
SQL语句执行顺序:
-
FROM: 指定数据来源表
-
WHERE:对查询数据做第一次过滤
-
GROUP BY:分组
-
HAVING:对分组后数据做第二次过滤
-
SELECT:查询各字段的值
-
ORDER BY:排序
-
LIMIT:限定查询结果
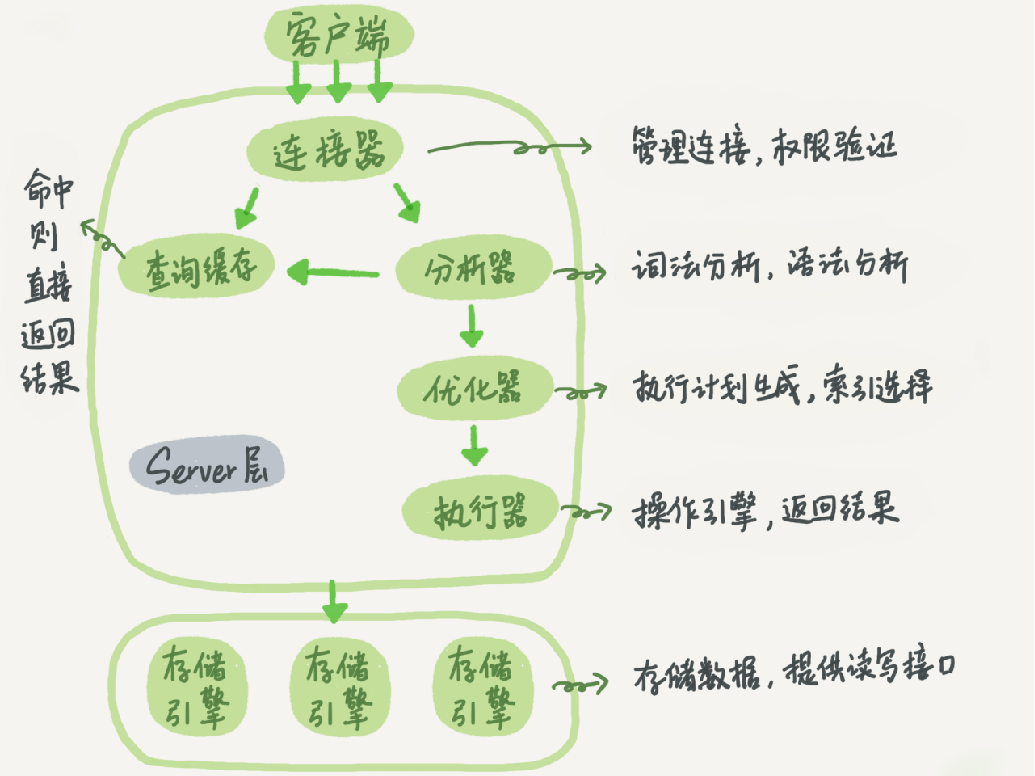
面试题:一条SQL查询语句的执行流程
当一条SQL语句在客户端和服务器之间执行时,其流程大致如下:
- 客户端发送SQL语句:客户端应用程序构建SQL查询语句,并通过数据库连接发送给服务器。这通常涉及使用预定义的JDBC连接、ODBC连接或其他数据库连接方法。
- 连接器/驱动接收SQL语句:数据库连接器或驱动程序负责接收客户端发送的SQL语句。连接器将消息解码并传递给服务器上的解析器。
- 词法分析:解析器接收到SQL语句后,首先进行词法分析。它将SQL查询语句分解为一系列的词素或标记,这些词素对应于SQL语言中的关键字、标识符、操作符等。
- 语法分析:解析器在词法分析之后,会根据SQL语言的语法规则构建一个解析树。这个解析树表示了SQL查询语句的语法结构。如果查询语句有语法错误,解析器会返回错误信息给客户端,并终止执行流程。
- 语义分析:在语法分析之后,数据库系统会进行语义分析。这个阶段检查SQL查询语句的语义正确性,例如检查引用的表和列是否存在、数据类型是否正确等。如果查询语句有语义错误,系统会返回错误信息给客户端。
- 查询优化:如果SQL查询语句通过了语法和语义分析,数据库系统会进入查询优化阶段。优化器会生成一个或多个查询执行计划,并评估这些计划以选择一个最优的执行策略。这个最优的执行计划是基于系统的统计信息和查询结构来确定的。
- 执行计划执行:一旦选择了最优的执行计划,数据库系统会按照该计划执行SQL查询语句。这涉及到从存储引擎检索数据、计算结果等操作。执行过程中可能会使用索引、临时表等机制来提高查询性能。
- 返回结果:最后,执行器将查询结果返回给客户端。这通常以表格的形式呈现,客户端应用程序可以解析这些结果并呈现给用户。
- 关闭连接:查询完成后,客户端和服务器之间的连接将被关闭或释放,以便其他请求可以使用相同的连接资源。
这个流程是数据库管理系统(DBMS)处理SQL查询的标准过程。实际的执行细节可能因不同的数据库系统而有所不同,但大体上遵循类似的逻辑和组件交互。
高级查询
1 子查询
概念:一个查询中嵌套一个查询,内层的查询称为子查询,外层查询时父查询。
- 执行时先执行子查询、再执行父查询。
1.1 子查询作为条件判断
**语法:**SELECT 列名 FROM 表名 WHERE 条件 (子查询结果);
代码演示:
#1 子查询作为条件判断
#需求: 查询工资大于Bruce的员工信息
# 不使用子查询
# 先查询到Bruce的工资(一行一列)
SELECT
salary
FROM
t_employees
WHERE
first_name = 'Bruce';
# 再查询工资大于Bruce的员工信息
SELECT
employee_id,
frist_name,
salary
FROM
t_employees
WHERE
salary > 6000;
# 使用子查询
SELECT
employee_id,
first_name,
salary
FROM
t_employees
WHERE
salary > ( SELECT salary FROM t_employees WHERE first_name = 'Bruce' );
注意:一行一列的结果才能作为外部查询的等值判断条件或不等值条件判断。
1.2 子查询作为枚举查询条件
**语法:**SELECT 列名 FROM 表名 WHERE 列名 in(子查询结果);
代码演示:
#2 子查询作为枚举查询条件
#需求: 查询与姓为'King'同一部门的员工信息;
#不使用子查询
#先查询 'King' 所在的部门编号(多行单列)
SELECT
department_id
FROM
t_employees
WHERE
last_name = 'king';
#再查询80、90号部门的员工信息
SELECT
employee_id,
first_name,
last_name,
salary,
department_id
FROM
t_employees
WHERE
department_id IN ( 80, 90 );
#使用子查询
SELECT
employee_id,
first_name,
last_name,
salary,
department_id
FROM
t_employees
WHERE
department_id IN ( SELECT department_id FROM t_employees WHERE last_name = 'king' );
1.3 当子查询结果集形式为多行单列时可以使用ANY或ALL关键字
代码演示:
#3 当子查询结果集形式为多行单列时可以使用ANY或ALL关键字。
#需求1: 查询高于 60 部门所有人的工资的员工信息(高于最高)
SELECT
employee_id,
first_name,
salary
FROM
t_employees
WHERE
salary > ALL ( SELECT salary FROM t_employees WHERE department_id = 60 );
#不是用ALL,使用MAX()查询函数,取最大值
SELECT
employee_id,
first_name,
salary
FROM
t_employees
WHERE
salary > ( SELECT MAX( salary ) FROM t_employees WHERE department_id = 60 );
#需求2: 查询高于 60 部门的工资的员工信息(高于最低)
SELECT
employee_id,
first_name,
salary
FROM
t_employees
WHERE
salary > ANY ( SELECT salary FROM t_employees WHERE department_id = 60 );
#不是用ANY,使用MIN()查询函数,取最小值
SELECT
employee_id,
first_name,
salary
FROM
t_employees
WHERE
salary > ( SELECT MIN( salary ) FROM t_employees WHERE department_id = 60 );
1.4 子查询作为一张临时表
**语法: **SELECT 列名 FROM(子查询的结果集)AS 别名 WHERE 条件;
代码演示:
#子查询作为一张临时表
#语法: SELECT 列名 FROM(子查询的结果集)AS 别名 WHERE 条件;
#需求:查询员工表中工资排名前 5 名的员工信息
SELECT
*
FROM (SElECT employee_id, first_name, salary FROM t_employees ORDER BY salary DESC)
AS temp
LIMIT 0,5;
注意:子查询作为临时表,需要为其赋予一个临时表名。
2 合并查询
UNION: 合并两张表的结果,去除重复记录
**语法:**SELECT * FROM 表名1 UNION SELECT * FROM 表名2;
代码演示:
#2 合并查询
# 合并查询的字段的列必须相同
# union 自动去掉重复数据
SELECT
*
FROM
stu1 UNION
SELECT
*
FROM
stu2
经验:UNION连接的结果集会去除重复的记录。
注意:合并结果的两张表,列数必须相同,列的数据类型可以不同。
UNION ALL: 合并两张表的结果,保留重复记录
**语法:**SELECT * FROM 表名1 UNION ALL SELECT * FROM 表名2;
代码演示:
# union all 保留重复数据
SELECT
*
FROM
stu1 UNION ALL
SELECT
*
FROM
stu2
经验:UNION ALL连接的结果集会保留重复的记录。
3 连接查询
3.1 表之间关系
表之间关系主要包括三种:
3.1.1 一对多关系
eg: 客户和订单,分类和商品,部门和员工。
建表原则:在多的一方创建一个字段,字段作为外键指向一方的主键。

3.1.2 多对多关系
eg: 学生和课程。
建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键。

3.1.3 一对一关系
eg:一个员工对应一个简历
在实际的开发中应用不多,因为一对一可以创建成一张表。
两种建表原则:
- 唯一外键对应:在多的一方创建一个外键指向一方的主键,将外键设置为unique和非空。
- 主键对应:让一对一的双方的主键建立关系。

3.2 交叉连接查询(笛卡尔积)
语法:
- SELECT 列名 FROM 表1 CROSS JOIN 表2; SQL标准
- SELECT 列名 FROM 表1,表2; 传统写法
代码演示:
#连接查询
#1 交叉链接 [笛卡尔积] 重复数据太多
#标准写法
SELECT
*
FROM
t_employees
CROSS JOIN t_departments
#传统写法
SELECT
*
FROM
t_employees,
t_departments;
3.3 内连接查询(INNER JOIN)
**语法:**SELECT 列名 FROM 表1 连接方式 表2 ON 连接条件;
代码演示:
#2 内连接查询
#标准写法
SELECT
*
FROM
t_employees AS e
INNER JOIN t_departments AS d ON e.department_id = d.department_id;
#传统写法
SELECT
*
FROM
t_employees AS e,
t_departments AS d
WHERE
e.department_id = d.department_id;
经验:
- 第一种属于SQL标准,与其他关系型数据库通用。
- 在MySql中,第二种方式也可以作为内连接查询,但是不符合SQL标准。
3.4 左外连接(LEFT OUTER JOIN)
代码演示:
#3 外连接查询
# 左外连接(LEFT OUTER JOIN)
# 注意:左外连接,是以左表为主表,依次向右匹配。
# 匹配到,返回结果。匹配不到,则返回NULL值填充。
# 需求: 查询所有员工信息,以及所对应的部门名称(没有部门的员工,也在查询结果中,部门名称以NULL 填充
SELECT
*
FROM
t_employees AS e
LEFT OUTER JOIN t_departments AS d ON e.department_id = d.department_id;
注意:
- 左外连接,是以左表为主表,依次向右匹配。
- 匹配到,返回结果。匹配不到,则返回NULL值填充。
3.5 右外连接(RIGHT JOIN)
代码演示:
# 右外连接(RIGHT JOIN)
# 注意:
# 右外连接,是以右表为主表,依次向左匹配。匹配到,返回结果。
# 匹配不到,则返回NULL值填充。
# 需求: 查询所有部门信息,以及此部门中的所有员工信息(没有员工的部门,也在查询结果中,员工信息以NULL 填充
SELECT
*
FROM
t_employees AS e
RIGHT OUTER JOIN t_departments AS d ON e.department_id = d.department_id;
注意:
- 右外连接,是以右表为主表,依次向左匹配。
- 匹配到,返回结果。匹配不到,则返回NULL值填充。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于Java+Vue的课外知识学习平台设计与实现
- [Kafka 常见面试题]如何保证消息的不重复不丢失
- STM32时钟频率相关知识
- 【AI】RTX2060 6G Ubuntu 22.04.1 LTS (Jammy Jellyfish) 部署chatglm2-6b 开源中英双语对话模型
- 从学习投研流程的角度学习Qlib
- 2024年六西格玛证书高效备考计划 - 张驰课堂深度解析
- 【数据库原理】(7)关系数据库的完整性约束
- MySQL练习题
- 【教3妹学编程-算法题】美丽塔 II
- 线性代数基础【5】特征值和特征向量