文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《市场环境下考虑全周期经济效益的工业园区共享储能优化配置》
这个标题涉及到工业园区中共享储能系统的优化配置,考虑了市场环境和全周期经济效益。以下是对标题中各个要素的解读:
-
市场环境下: 指的是工业园区所处的商业和经济背景。这可能包括市场竞争状况、电力市场价格波动、政策法规等因素。在这一环境下,储能系统的配置需要灵活应对市场变化。
-
考虑全周期经济效益: 强调了在储能系统配置中,不仅仅关注短期内的经济效益,还要考虑整个使用寿命周期内的效益。这可能包括投资回收期、总成本、运营效率等方面的因素。
-
工业园区: 指的是一个集中了多个工业企业的区域。在这种环境下,能源需求通常较大,因此储能系统的优化配置对于提高能源利用效率、降低成本具有重要意义。
-
共享储能: 意味着多个工业企业可以共同使用同一储能系统。这种共享模式可能带来更高的灵活性和更好的经济效益。
-
优化配置: 指的是通过合理的设计和设置,使储能系统在各种条件下能够达到最佳性能。这可能涉及到技术参数的优化、充放电策略的制定等方面。
综合而言,这个标题表明研究的焦点是在市场环境中,通过考虑储能系统的全寿命周期,对工业园区内的共享储能进行优化配置,以实现最佳的经济效益。这种研究有望为工业园区提供更可持续、经济高效的能源解决方案。
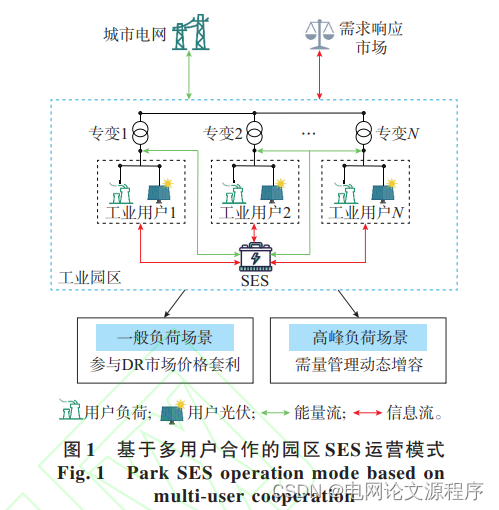
摘要:为提升用户侧储能运行效率、改善投资成效,提出一种在市场环境下考虑全周期经济效益的工业园区共享储能(SES)优化配置方法。一方面,通过协调不同用户间的差异化调节需求,减少储能容量要求;另一方面,通过整合用户与SES的灵活调节能力,参与需求响应市场拓宽盈利渠道,并且考虑了SES全运行周期经济效益测算以降低投资风险。首先,结合电力市场交易规则,提出了多工业用户组建合作联盟的园区共享储能运营模式。其次,以运营周期内联盟总成本最小为目标,建立SES双层优化配置模型,其中,上层模型旨在形成最大化投资成效的共享储能规划方案,而下层模型则综合考虑分时电价、需求响应违约风险等因素形成储能的最优投标调度方式,并结合市场时序演变规律精准量化共享储能在全运行周期内的运营收益,对上层结果进行修正。接着,利用近似KKT(Karush-Kuhn-Tucker)条件将该模型转化为单层模型进行求解,结合雨流计数法与迭代法量化SES容量衰减对其配置方案的影响,并利用双边Shapley值法分摊各工业用户的投资成本。最后,算例仿真验证了所提方法的有效性并且分析了储能盈利模式、SES容量衰减以及DR违约风险等因素对SES投资经济效益的影响。
这段摘要描述了一种针对工业园区中用户侧储能系统(SES)的优化配置方法,其目标是提高运行效率并改善投资成效。以下是对摘要的详细解读:
-
目标与背景: 研究的目标是提升用户侧储能运行效率和改善投资成效。这是出于对全球能源问题的关注,尤其是在市场环境中,更为重要。提到的市场环境可能包括市场价格波动、政策法规等。
-
方法概述: 方法主要包括两个方面的考虑。首先,通过协调不同用户的需求,减少储能容量的需求。其次,通过整合用户和储能系统的调节能力,参与需求响应市场,扩大盈利渠道。这两方面的考虑都与提高储能系统在市场中的经济效益有关。
-
运营模式: 提出了一种新的运营模式,即多个工业用户组成合作联盟,共享储能系统。这可以提高系统的整体效率,并通过联盟形式参与市场活动。
-
优化配置模型: 建立了双层的SES优化配置模型。上层模型旨在形成最大化投资成效的共享储能规划方案,而下层模型考虑了多种因素,包括分时电价、需求响应违约风险等,形成储能的最优投标调度方式。
-
数学建模与求解: 使用了近似KKT条件将模型转化为单层模型进行求解。此外,采用雨流计数法和迭代法量化SES容量衰减对配置方案的影响,以及利用双边Shapley值法分摊各工业用户的投资成本。
-
仿真验证和分析: 通过算例仿真验证了方法的有效性,并对储能盈利模式、SES容量衰减以及DR(需求响应)违约风险等因素对SES投资经济效益的影响进行了分析。
总体而言,这个研究提出了一种复杂而全面的SES优化配置方法,该方法不仅考虑了经济效益,还关注了市场因素和全周期的经济效益。
关键词:市场时序演变; 工业园区;共享储能;需求响应市场;优化配置;双层模型;
-
市场时序演变: 这指的是市场在时间上的演变和变化。在这个上下文中,可能涉及到电力市场的价格波动、不同时段的用电需求变化等因素。考虑市场时序演变意味着方法不仅仅关注静态条件下的优化,还考虑了市场在不同时间点的动态变化。
-
工业园区: 指的是一个集中了多个工业企业的区域。在这个研究中,工业园区可能是一个重要的背景,因为共享储能系统很可能服务于该园区内的多个工业用户。
-
共享储能: 表示多个用户或企业共同使用一套储能系统。这种共享可以带来更高的效益和资源利用率。
-
需求响应市场: 指的是一种市场机制,其中用户根据市场价格或其他激励措施调整其用电行为,以响应系统需求或优化自身成本。在这里,共享储能系统可能通过参与需求响应市场来提高盈利。
-
优化配置: 意味着通过调整储能系统的参数、容量等来最大化投资效益。在这个上下文中,可能包括考虑不同用户需求、市场条件等因素,以找到最优的储能配置方案。
-
双层模型: 提到建立了双层的SES优化配置模型。这种模型结构一般包括上层和下层,上层目标是形成最大化投资效益的共享储能规划方案,而下层模型则综合考虑多种因素,如电价、需求响应违约风险等,形成储能的最优投标调度方式。这种层次结构可以更好地捕捉不同层面的决策和优化过程。
仿真算例:为验证所提方法的有效性,本文基于中国浙江 某工业园区内 4 个中小型工业用户的真实负荷数据 进行仿真实验,各用户的最大用电负荷在 1 MW 左 右且装有少量屋顶光伏。算例中所涉及的原始数据 及分时电价、DR 补贴价格等关键参数见附录 F,其 中部分储能相关参数参考文献[8]。为对所提方法进行全面分析,本文共设计了以 下 6 个算例。首先,通过对比算例 1~4 的结果,对不 同盈利模式下的储能经济效益进行分析。然后,通 过对比算例 4 和 5 的结果,分析 SES 容量衰减对其 经济效益的影响并以此说明在 SES 优化配置问题 中考虑其容量衰减特性的必要性。最后,通过对比 算例 4 和 6 的结果,分析 DR 违约风险对约定响应量 制定策略以及 SES 经济效益的影响,并以此说明在 本文所提模式中考虑 DR 违约风险的必要性。 算例 1:用户不配置储能,不参与 DR 市场。 算例 2:用户单独配置储能但不参与 DR 市场。 算例 3:用户共同投资 SES 但不参与 DR 市场。 算例 4:用户共同投资 SES 且联合参与 DR 市场,即本文所提出的模式。 算例 5:用户共同投资 SES 且联合参与 DR 市 场,但不考虑 SES 的容量衰减,SES 配置容量与算 例 4 相同。 算例 6:用户共同投资 SES 且联合参与 DR 市 场,但不考虑 DR 违约风险,SES 配置容量与算例 4 相同。
仿真程序复现思路:
复现上述仿真实验可以分为以下几个步骤,我将以Python为例进行简要的伪代码表示。请注意,实际的实现可能需要使用专业的仿真工具和库,而这里的伪代码仅用于概念性的描述。
- 设计算例:
- 设计六个不同的算例,按照描述中的用户配置和市场参与情况进行设置。
- 执行仿真:
- 使用所设计的算例,执行仿真实验,计算每个算例的经济效益。
- 考虑不同的盈利模式、SES容量衰减、DR违约风险等因素。
- 分析和比较结果:
- 对仿真结果进行分析,比较不同算例下的储能经济效益。
- 关注 SES 容量衰减和 DR 违约风险对经济效益的影响。
- 结论和可视化:
- 根据分析结果得出结论,可视化展示不同算例的经济效益变化趋势。

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 步骤1:准备数据
def load_from_appendix(file_path):
# 实际情况下,你可能需要使用Pandas等库来加载数据
return pd.read_csv(file_path)
def load_from_reference(file_path):
# 加载储能相关参数
return pd.read_csv(file_path)
load_data = load_from_appendix("user_load_data.csv")
electricity_price = load_from_appendix("electricity_price.csv")
dr_subsidy_price = load_from_appendix("dr_subsidy_price.csv")
storage_parameters = load_from_reference("storage_parameters.csv")
# 步骤2:设计算例
cases = [
{"storage_config": None, "dr_participation": False},
{"storage_config": {"type": "individual"}, "dr_participation": False},
# ... 添加其它算例
]
# 步骤3:执行仿真
def run_simulation(load_data, electricity_price, dr_subsidy_price, storage_parameters, case):
# 实际情况下,这里应该有一个复杂的模型来进行仿真
# 此处只是一个简单的示例
total_cost = np.sum(load_data * electricity_price)
if case["storage_config"]:
# 如果配置了储能,可能会有不同的计算方式
total_cost -= calculate_storage_cost(load_data, storage_parameters)
if case["dr_participation"]:
total_cost -= calculate_dr_revenue(load_data, dr_subsidy_price)
return total_cost
def calculate_storage_cost(load_data, storage_parameters):
# 根据储能参数和用户负荷数据计算储能成本
return 0 # 简化示例,实际应该有更复杂的计算
def calculate_dr_revenue(load_data, dr_subsidy_price):
# 根据用户负荷数据和DR补贴价格计算DR收入
return 0 # 简化示例,实际应该有更复杂的计算
results = {}
for case in cases:
result = run_simulation(load_data, electricity_price, dr_subsidy_price, storage_parameters, case)
results[str(case)] = result
# 步骤4:分析和比较结果
def analyze_and_compare(results):
# 分析结果,可能涉及到统计分析、图表绘制等
for case, result in results.items():
print(f"{case}: {result}")
# 步骤5:结论和可视化
def draw_conclusions_and_visualize(results):
# 画图等可视化操作
labels, values = zip(*results.items())
plt.bar(labels, values)
plt.xlabel('Cases')
plt.ylabel('Total Cost')
plt.title('Simulation Results')
plt.show()
analyze_and_compare(results)
draw_conclusions_and_visualize(results)
请注意,上述代码是伪代码,实际的仿真实验可能涉及更多细节和专业工具。在实际实现中,你可能需要使用数据科学和仿真相关的Python库,例如NumPy、Pandas、Matplotlib等,以及可能的仿真工具或库,具体取决于你的具体需求和研究领域。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【智能家电】离在线语音方案为厨电企业赋能,实现厨房智能化控制
- AWS 专题学习 P7 (FSx、SQS、SNS)
- 精通推荐算法2:推荐系统分类(面试必备)
- 装饰者模式学习
- 什么是安全SCDN,有什么作用?
- vscode mysql cmake windows 常见问题和推荐文章
- Java Stream 比较两个 List 的差异,并取出不同的对象
- MySQL之视图&外连接、内连接和子查询的使用
- 【Java动态代理如何实现】
- RTX20系开启超分辨率