C# 提取PDF中指定文本、图片的坐标
发布时间:2023年12月20日
获取PDF文件中文字或图片的坐标可以实现精确定位,这对于快速提取指定区域的元素,以及在PDF中添加注释、标记或自动盖章等操作非常有用。本文将详解如何使用国产PDF库通过C# 提取PDF中指定文本或图片的坐标位置(X, Y轴)。
? 用于操作PDF文件的第三方库为Spire.PDF for .NET。可以下载产品包后手动安装或者直接通用Nuget安装。
开始前我们首先了解该库关于PDF中坐标系的一些信息:
Spire.PDF for .NET使用?PdfPageBase?类表示PDF页面,由内容区域和四周的页边距组成。页面上坐标系的原点位于内容区域的左上角,x 轴从原点开始水平向右延伸,y 轴从原点开始垂直向下延伸 (如下图所示)。

通过指定坐标XY轴,我们可以在PDF页面指定位置处绘制文本、图片、表格等元素。当然Spire.PDF for .NET也提供了相应的接口来帮助大家获取已有PDF文件中指定文本或图片的坐标信息。具体操作如下。
C# 获取 PDF 中指定文本的坐标
要指定文本的坐标,主要分为两步实现:
- 首先需要使用?PdfTextFinder.Find()?方法查找PDF文件中所有指定文本;
- 查找到文本后,再通过?PdfTextFragment.Positions 属性进一步获取其 (X, Y) 坐标信息。
代码:
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Drawing;
namespace GetCoordinatesOfText
{
class Program
{
static void Main(string[] args)
{
//创建PdfDocument对象
PdfDocument pdf = new PdfDocument();
//加载PDF文件
pdf.LoadFromFile("大数据.pdf");
//遍历所有页面
foreach (PdfPageBase page in pdf.Pages)
{
//创建PdfTextFinder对象
PdfTextFinder finder = new PdfTextFinder(page);
//设置查找选项
PdfTextFindOptions options = new PdfTextFindOptions();
options.Parameter = TextFindParameter.IgnoreCase;
finder.Options = options;
//查找页面中所有指定文本
List<PdfTextFragment> fragments = finder.Find("海量");
//遍历所有查找的文本
foreach (PdfTextFragment fragment in fragments)
{
//获取文本的坐标信息
PointF found = fragment.Positions[0];
Console.WriteLine(found);
}
}
}
}
}
C# 获取 PDF 中指定图片的坐标
与获取文字坐标类似,获取图片坐标主要也分为两步:
- 首先使用?PdfImageHelper.GetImagesInfo()?方法获取某个PDF页面中所有图片信息;
- 获取图片后,再通过?PdfImageInfo.Bounds?属性获取其 (X, Y) 坐标信息。
代码:
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System;
namespace GetCoordinatesOfImage
{
class Program
{
static void Main(string[] args)
{
//创建PdfDocument对象
PdfDocument pdf = new PdfDocument();
//加载PDF文件
pdf.LoadFromFile("大数据.pdf");
//获取指定页面
PdfPageBase page = pdf.Pages[0];
//创建PdfImageHelper对象
PdfImageHelper helper = new PdfImageHelper();
//获取页面中的图片信息
PdfImageInfo[] images = helper.GetImagesInfo(page);
//获取第一张图片的 X、Y 坐标
float xPos = images[0].Bounds.X;
float yPos = images[0].Bounds.Y;
Console.WriteLine("图片坐标为({0},{1})", xPos, yPos);
}
}
}
加载的示例文档:

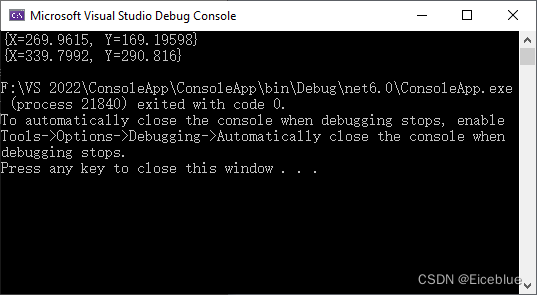
获取PDF中文字坐标的返回结果:
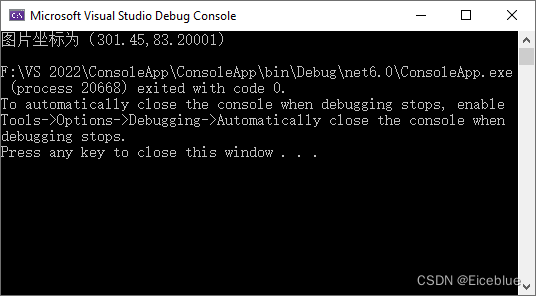
获取PDF中图片坐标的返回结果:
相关推荐阅读:
文章来源:https://blog.csdn.net/Eiceblue/article/details/134971671
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【力扣每日一题】力扣2788用分隔符拆分字符串
- P1309 [NOIP2011 普及组] 瑞士轮————C++
- UOS python+pyqt5实现USB测试
- 国家开放大学 河南开放大学 形成性考核 平时作业 考试题 参考资料
- 企业微信开发:自建应用:获取企业微信IP段(用于防火墙配置)
- 垂直领域大模型落地思考
- 计算机视觉CV技术的优势和挑战
- Python-for循环的嵌套(九九乘法表)
- YOLOv8 损失函数改进 | 引入 Shape-IoU 考虑边框形状与尺度的度量
- JVM问题分析处理手册