爬取IT之家新闻-2
发布时间:2024年01月16日
爬取IT之家新闻
it之家新闻最新发布的新闻更新在这9条中,所以只需要循环抓取这9条内容就可以获取最新的新闻
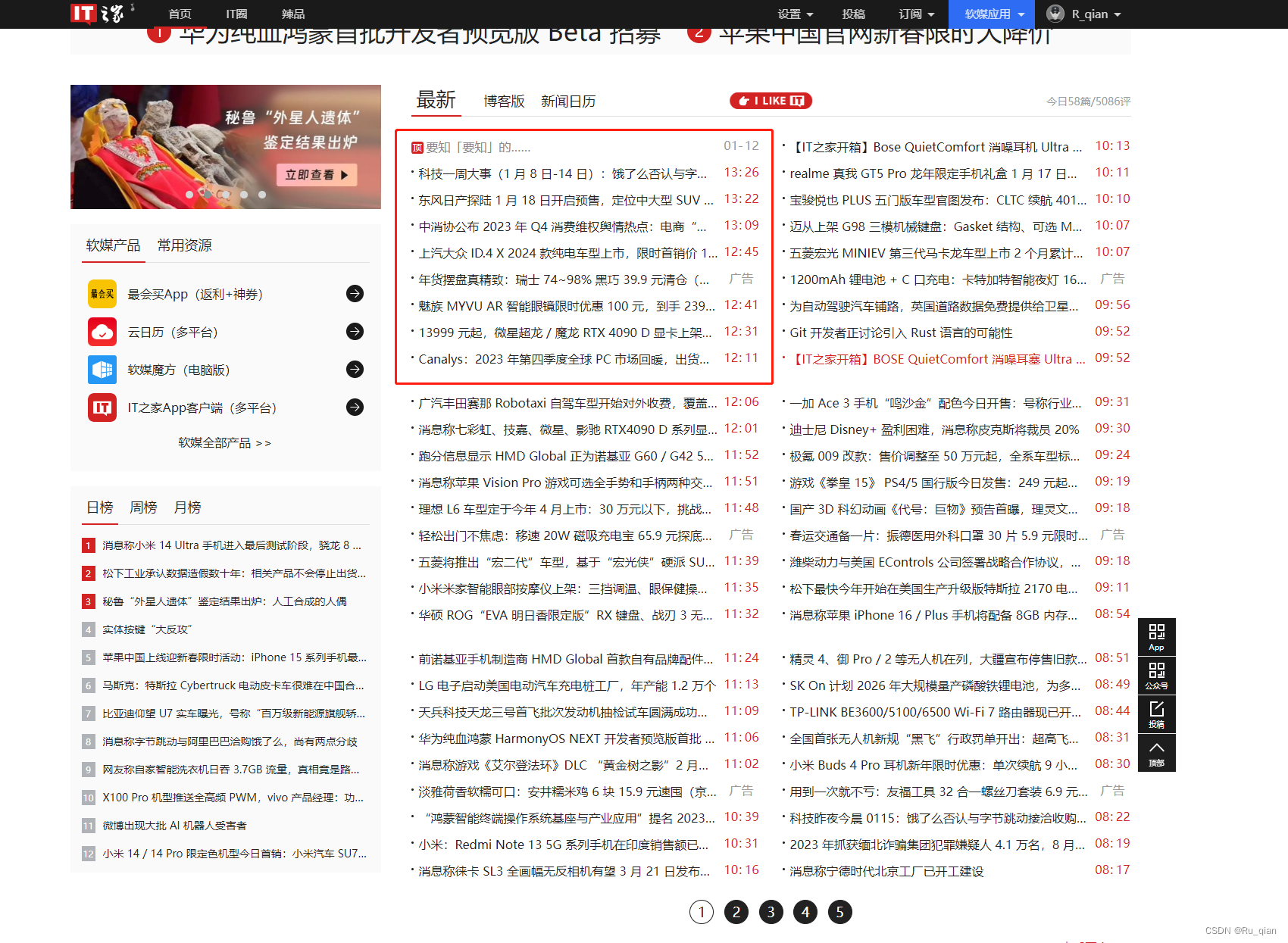
python代码,it之家新闻更新频率大概是5分钟左右一条,9条是45分钟才会全部覆盖,所有只要半小时左右去请求一次就可以了,一天最多也请求48次基本上就可以获取全部的新闻了。这次的代码相比于上次可以少很多次请求
import requests,time,random
from lxml import etree
url = 'https://www.ithome.com/'
ua = {'User-agent':'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'}
pag = '广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。'
#读取文本内容
def content_text():
with open('node3.txt','r') as r:
cont = r.read()
return cont
#对内容进行获取并写入
def estimate(content_url,content_title):
html_content = requests.get(url=content_url,headers=ua)
html_content.encoding='utf-8'
if html_content.status_code == 200:
content = etree.HTML(html_content.text).xpath('//*[@id="paragraph"]//text()')
content = [text.strip() for text in content if text.strip()]#遍历上一步提取出的所有文本片段,并使用strip()方法去除每个文本片段两端的空白字符(包括空格、制表符和换行符)。同时,通过条件if text.strip()确保只保留非空的文本片段
con = ''.join(content)
con = con.replace(pag,'')#去除尾部
with open('./node3.txt','r+') as r:
neirong = r.read()
r.seek(0)
if '广告' not in con: #去除广告
r.write(f'{content_title}\n\t{con}\n\n{neirong}')
r.close()
else:
print('【广告内容不进行写入】')
else:
print('请求失败')
response = requests.get(url=url, headers=ua)
response.encoding = 'utf-8'
title_to_href = {}#初始化一个空字典来存储标题与链接的关系
content_text = content_text()#将读取到的内容进行赋值
#循环请求
while True:
# 提取所有标题及其对应的链接
for i in range(1, 10):
xpath_title = f'//*[@id="nnews"]/div[3]/ul[1]/li[{i}]/a/text()'
xpath_href = f'//*[@id="nnews"]/div[3]/ul[1]/li[{i}]/a/@href'
html_title = etree.HTML(response.text).xpath(xpath_title)[0]
html_href = etree.HTML(response.text).xpath(xpath_href)[0]
title_to_href[html_title] = html_href
# 遍历字典进行判断和打印
for title,href in title_to_href.items():
if title in content_text:
print(f'标题【{title}】存在,不在执行写入')
else:
try:
estimate(href,title)
except Exception as e:
print('请求发生错误,请检查网络状况')
break
print(f'标题【{title}】 和内容已写入')
time.sleep(random.randint(600,1200))#10分钟到20分钟之间随机执行一次
运行效果,对于已经写入的内容则不进行写入,对于没有的则进行写入。注:运行代码之前先要在当前目录新建一个node3.txt文件

文章来源:https://blog.csdn.net/LEITANAN/article/details/135599118
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在Node.js中停止使用dotenv
- JavaWeb会议管理系统
- 内网穿透的应用-如何使用Docker部署Redis数据库并结合内网穿透工具实现公网远程访问
- 回家用go?还是go to?
- 第六站:C++面向对象关键字解释说明
- pygame里实现导弹追踪效果,同时对python的指针机制有一点点思考
- 【微服务核心笔记】
- Hyperledger Fabric 权限策略和访问控制
- R语言【taxa】——n_subtaxa(),n_supertaxa():每个类群的子类群数量和父类群数量
- 解密 Java ForEach 提前终止问题