SEO中的实体:它们是什么以及为什么它们很重要?
从了解搜索历史到区分实体与关键字,真正了解实体是什么,以便获得更有针对性的搜索流量。

关于SEO专业人士应该如何理解,更重要的是,如何利用SEO中的“实体”,存在很多困惑。
我明白这是从哪里来的,尤其是传统的SEO方法是围绕单词和短语的。
事实上,第一波SEO专业人士(像我一样)长大的大多数算法在搜索中没有“实体”的概念。SEO原则–从内容写作到链接中的锚文本,再到SERPs跟踪–是(而且在很大程度上仍然是)关键词驱动的,许多人仍然很难理解发生了什么变化。
但在过去的十年里,所有的搜索都朝着将世界理解为一串单词和一系列相互关联的实体的方向发展。
在 SEO 中与实体合作是面向未来的搜索策略的基础。
它们对于生成式人工智能和 ChatGPT 的未来也很重要。
本文将讨论原因。它包括:
- 什么是实体?
- 什么是知识图谱?
- 搜索中实体的简史:Freebase、Wikidata 和实体。
- 实体的工作原理以及它们如何用于排名。
- Google 中的实体示例。
- 如何针对实体进行优化。
- 使用 Schema 帮助定义实体。
什么是实体?
SEO经常将实体与关键字混淆。
实体(在搜索词中)是数据库中的记录。实体通常具有特定的记录标识。
在 Google 中,这可能是:
“MREID=/m/23456”或“KGMID=/g/121y50m4”。
它当然不是一个“词”或“短语”。我认为,对关键词的混淆源于两个根本原因:
- 首先,SEO专业人士在2010年之前在关键词和短语方面学习了他们的手艺。许多人仍然这样做。
- 其次,每个实体都有一个标签——通常是关键字或描述符。
因此,虽然“埃菲尔铁塔”对我们人类来说似乎是一个完全可识别的“实体”,但谷歌将其视为“KGMID=/m/02j81”,并且真的不在乎你是否称它为“埃菲尔铁塔”或“埃菲尔铁塔”或“???? ?????”(这是阿塞拜疆的“埃菲尔铁塔”)。它知道您可能在其知识图谱中引用了该基础实体。
这就涉及到下一点:
什么是“知识图谱”?
“知识图谱”、“知识图谱”和“知识面板”之间存在细微但重要的区别。
- 知识图谱是一个包含实体的半结构化数据库。
- 知识图谱通常是谷歌知识图谱的名称,尽管存在数千个其他知识图谱。维基数据(本身就是一个知识图谱)试图交叉引用来自不同信誉良好的数据源的标识符。
- 知识面板是 Google 知识图谱结果的特定表示形式。它是桌面搜索中通常显示在结果 (SERP) 右侧的窗格,提供有关人员、地点、事件或其他实体的更多详细信息。
搜索实体简史
元网页
2005 年,Metaweb 开始构建一个数据库,当时称为 Freebase,它将其描述为“世界知识的开放、共享数据库”。
我会把它描述为一本半结构化的百科全书。
它为每个“实体”(或文章,以扩展比喻)提供了自己唯一的 ID 号——从那里开始,系统试图通过文章与系统中其他 ID 号的关系来连接文章,而不是传统的文字文章。
大约5000万美元的资本资金,5年后,该项目被卖给了谷歌。
从未构建过任何商业产品,但为谷歌从基于关键字的搜索引擎到基于实体的搜索引擎的 10 年过渡奠定了基础。
维基数据
2016 年,也就是收购大约六年后,谷歌正式关闭了 Freebase,因为它已经将这些想法迁移并发展到自己的“知识图谱”中,这是这些数据库的现代术语。
当时,值得一提的是,谷歌公开表示,它已经将其大部分实体数据与维基数据同步,并且,展望未来,维基数据(支撑维基百科中使用的数据)是谷歌知识图谱与外界交互的一种方式。
实体如何工作以及如何使用它们进行排名
核心算法中的实体
实体主要用于消除想法的歧义,而不是对具有相同想法的页面进行排名。
这并不是说巧妙地使用实体不能帮助你的网站内容更有效地排名。它可以。但是,当谷歌试图为用户搜索提供结果时,它的首要目标是获得准确的答案。
不一定是最值得的。
因此,谷歌花费了相当多的时间将文本段落转换为底层实体。在为网站编制索引和分析用户查询时,都会发生这种情况。
例如,如果我输入“埃菲尔铁塔下的餐馆名称”,谷歌就知道搜索者不是在寻找“名称”或“埃菲尔铁塔”。
他们正在寻找餐馆。不是任何餐厅,而是特定位置的餐厅。本次搜索中的两个相关实体是“Champ de Mars, 5 Av. Anatole France, Paris”(埃菲尔铁塔的地址)中的“餐厅”。
这有助于 Google 决定如何混合其各种搜索结果——图像、地图、Google 业务、广告和自然网页,仅举几例。
最重要的是,对于SEO专业人士来说,如果希望谷歌认识到该页面与此搜索查询相关,那么(比如)儒勒·凡尔纳餐厅的网站谈论其埃菲尔铁塔的壮丽景色非常重要。
这可能很棘手,因为儒勒·凡尔纳餐厅位于埃菲尔铁塔内。
与语言无关
实体非常适合搜索引擎,因为它们与语言无关。此外,这个想法意味着一个实体可以通过多种媒体来描述。
图像是描述埃菲尔铁塔的明显方式,因为它是如此具有标志性。它也可能是语音文件或塔的官方页面。
这些都表示实体的有效标签,在某些情况下,还表示其他知识图谱中的有效标识符。
实体之间的连接
实体之间的相互作用使SEO专家能够制定连贯的策略来开发相关的自然流量。
当然,埃菲尔铁塔最“权威”的页面很可能是官方页面或维基百科。除非你真的是埃菲尔铁塔的SEO专家,否则你几乎无能为力来挑战这一事实。
但是,实体之间的相互作用允许您编写将排名的内容。我们已经提到了“餐厅”和“埃菲尔铁塔”——但“地铁”和“埃菲尔铁塔”或“折扣”和“埃菲尔铁塔”呢?
一旦两个实体发挥作用,相关搜索结果的数量就会急剧下降。当您到达“乘坐地铁旅行时的埃菲尔铁塔折扣门票”时,您已成为专注于地铁门票、埃菲尔铁塔门票和折扣之间并列的一小部分页面之一。
输入此短语的人要少得多,但转化率会高得多。
对您来说,它也可能被证明是一个更可货币化的概念!(这个例子是为了解释原理。我不知道是否存在这样的折扣。但他们应该这样做。
通过首先将搜索短语的所有竞争页面分解到一个表中,显示基础实体及其对主查询的相对重要性,可以扩展此概念以创建异常强大的页面。
然后,这可以作为作家的内容计划,以建立一个比任何其他竞争作品都更具权威性的新内容。
因此,尽管搜索引擎可能声称实体不是排名因素,但该策略的核心是“如果你写出好的内容,他们就会来”。
Google 中的实体示例
图像搜索中的实体
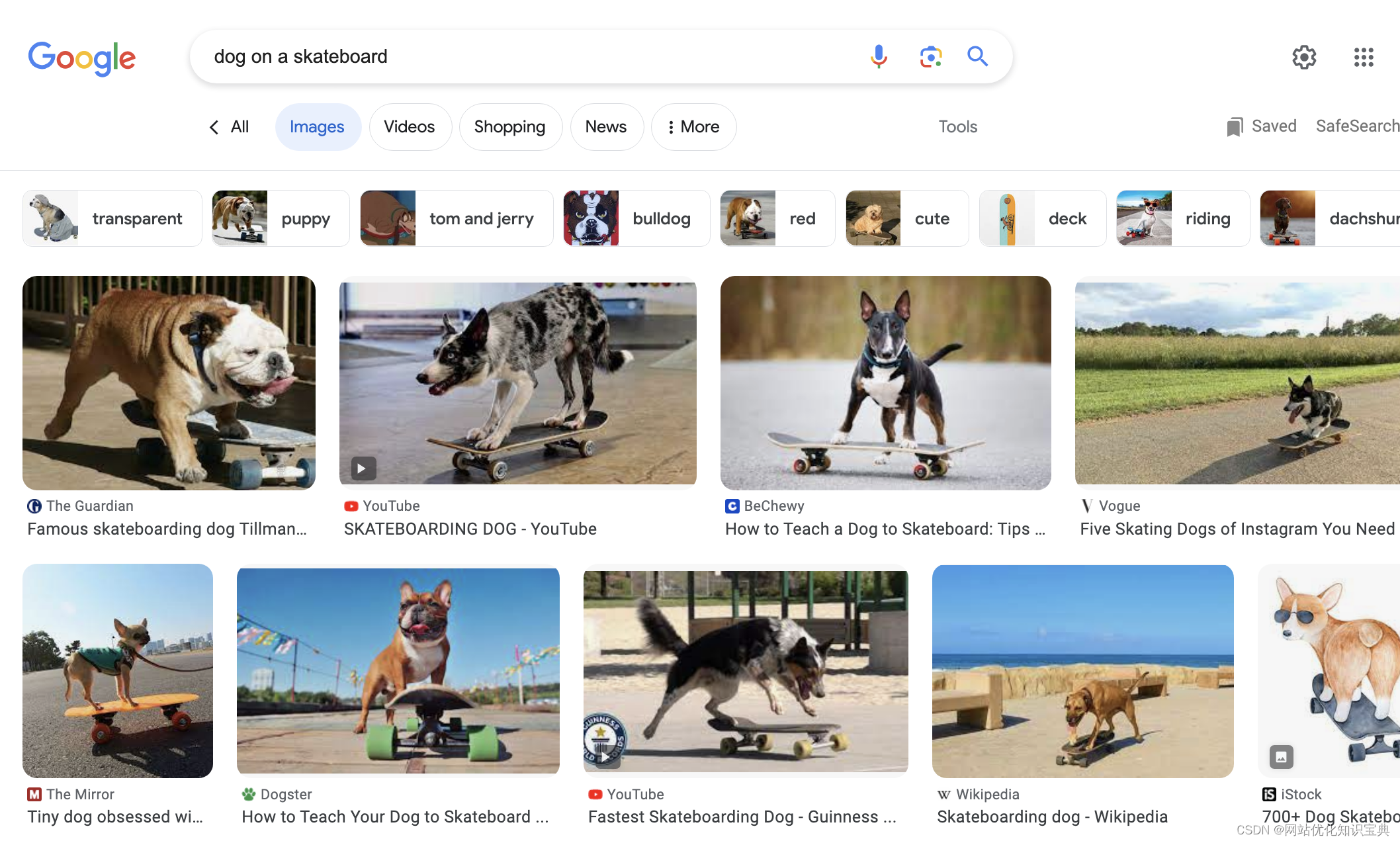
实体在优化图像方面也非常有帮助。
谷歌一直在努力使用机器学习来分析图像。因此,通常情况下,谷歌知道大多数照片中的主要图像。
因此,以[滑板上的狗]作为搜索词…确保您的内容完全支持图像可以帮助您的内容在用户搜索时更加明显。
Google 探索中的实体
SEO专业人士最被低估的流量来源之一是谷歌发现。
谷歌为用户提供了一个有趣的页面提要,即使他们没有积极寻找一些东西。
这发生在 Android 手机和 iPhone 上的 Google 应用程序中。虽然新闻对这个提要有很大的影响,但非新闻网站可以从“发现”中获得流量。
如何?好吧——我相信实体起着重要作用!
GSC 中的 Google Discover 数据截图来自 Google Search Console,2023 年 8 月
如果您在 Google Search Console 中没有看到“发现”选项卡,请不要灰心。但是,当您这样做时,这可能是一个可喜的迹象,表明您的至少一个网页已经与实体保持一致,以至于至少有一个人的兴趣与您的内容重叠,足以使该页面在提要中专门针对用户。
在上面的示例中,即使“发现”结果未在用户搜索的确切时间显示,但仍有 4.2% 的点击率。
这是因为谷歌可以通过映射实体来使其许多用户的兴趣和习惯与互联网上的内容保持一致。
在发生强相关性的情况下,谷歌可以为用户提供一个页面。
如何针对实体进行优化
来自 Google 员工的一些研究
2014 年,一篇论文问世,我发现这篇论文非常有助于证明谷歌(或者至少是它的研究人员)热衷于将使用关键字来理解主题的想法与使用实体的想法区分开来。
在这篇论文中,Dunietz 和 Gillick 指出了 NLP 系统如何转向基于实体的处理。他们强调了如何在大型数据集上使用二进制“显著性”系统来定义文档(网页)中的实体。
“二元评分系统”表明,谷歌可能会决定一个文档是关于任何给定实体的“是”或“不是”。
后来的线索表明,“显著性”现在由谷歌以从 0 到 1 的滑动等级来衡量(例如,其 NLP API 中给出的评分)。
即便如此,我发现这篇论文确实有助于了解谷歌的研究认为“实体”应该出现在页面上的哪些位置,以“算作”突出。
我建议阅读这篇论文进行严肃的研究,但他们列出了他们如何将“显著性归类为对《纽约时报》文章的研究”。
具体来说,他们引用了:
第一位置
这是第一次提到实体的第一句话。
建议是在网页的早期提及该实体可能会增加某个实体被视为文章“突出”的机会。
人数
这基本上是实体第一次提及的“头部”一词出现的次数。
文章中没有明确定义“标题词”,但我认为它是指连接到最简单形式的词。
提到
这不仅指实体的文字/标签,还指其他因素,例如实体(他/她/它)的推荐
标题
实体出现在标题中的位置。
Head-lex
被描述为“第一次提及的小写头词”。
实体中心性
这篇论文还谈到了使用PageRank的变体 - 他们为Freebase文章切换了网页!
他们分享的例子是参议院辩论,涉及联邦紧急事务管理局、共和党、(总统)奥巴马和共和党参议员。
在将类似PageRank的迭代算法应用于这些实体以及它们在知识图谱中彼此之间的接近程度后,他们能够改变这些实体在文档中的重要性权重。
在SEO中将这些实体信号放在一起
在不特定于 Google 的情况下,这里的算法将为 NLP 或命名实体提取程序 (NEEP) 在文本页面上找到的每个实体(或者,就此而言,图像中识别的所有实体)创建上述所有变量的值。
然后对每个变量进行加权以给出分数。在讨论的论文中,这个分数变成了 1 或 0(突出或不突出),但 0-1 之间的值更有可能。
谷歌永远不会分享这些权重的细节,但该论文还表明,只有在“阅读”数亿页后才能确定权重。
这就是大型语言学习模型的本质。
但是,对于想要围绕两个或多个实体对内容进行排名的 SEO 专业人士来说,这里有一些重要提示。回到“埃菲尔铁塔附近的餐馆”这个例子:
- 为每个实体确定一个“死”术语。我可能会选择“餐厅”、“埃菲尔铁塔”和“距离”,因为距离在维基百科中具有有效的含义和条目。Cafe 可能是餐厅的合适同义词,复数形式的“餐厅”也可能是。
- 目标是在标题和第一句话中包含所有三个实体。例如:“距离埃菲尔铁塔不远的餐厅。
- 在文本中旨在讨论这些实体之间的相互关系。例如:“儒勒-凡尔纳餐厅就在里面。假设“它”在写作的上下文中明确指的是埃菲尔铁塔,那么它不需要每次都写出来。保持语言自然。
这对实体SEO来说足够了吗?
不。(欢迎你读我的书!但是,并非所有因素都在您作为作家或网站所有者的控制范围内。
不过,似乎确实有影响的两个想法是在上下文中链接来自其他页面的内容,并添加模式以帮助定义。
使用架构帮助定义实体
通过使用“关于”和“提及”模式来帮助搜索引擎消除内容的歧义,可以进一步明确搜索引擎。
这两种架构类型有助于描述页面正在谈论的内容。
通过制作一个页面“关于”一两个实体并“提及”更多实体,SEO专业人员可以以一种现成的方式快速将一长段内容总结到其关键领域,供知识图谱使用。
不过,应该注意的是,谷歌并没有明确说明它是否在其核心算法中使用了这种模式。
我可能会将此架构添加到我的文章中:
<脚本类型=“application/ld+json”> {
“@context”: “https://schema.org”,
“@type”: “网页”,
“@id”: “https://www.yoursite.com/yourURL#ContentSchema”,
“headline”: “距离埃菲尔铁塔不远的餐厅”,
“url”: “https://www.yoursite.com/yourURL”,
“关于”:[
{“@type”: “事物”, “name”: “餐厅”, “sameAs”: “https://en.wikipedia.org/wiki/Restaurant”},
{“@type”: “地点”, “name”: “埃菲尔铁塔”, “sameAs”: “https://en.wikipedia.org/wiki/Eiffel_Tower”}
],
“提及”:[
{“@type”: “事物”, “name”: “距离”, “sameAs”: “https://en.wikipedia.org/wiki/Distance”},
{“@type”: “地点”, “name”: “巴黎”, “sameAs”: “https://en.wikipedia.org/wiki/Paris”}
]
} </脚本>
模式的确切选择与SEO问题一样是一个哲学问题。
但是,将您使用的架构视为“消除歧义”您的内容而不是“优化您的内容”,您最终有望获得更有针对性的搜索流量。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!