pandas 多进程与并发
1. 背景
??????? 在大规模数据之间完成一些操作,往往会浪费大量的时间,为了充分利用软硬件资源,演化出了2种主流的优化方式,即“向量化” 和“并行化” 。
2. swifter
??????? swifter 是一款用于给使用在 pandas DataFrame 或者 Series 上的 function 进行加速的包,它综合使用了“向量化” 和“并行化”方式。
安装:
pip install -U pandas # upgrade pandas
pip install swifter # first time installation
pip install -U swifter # upgrade to latest version if already installed
或 conda 安装
conda install -c conda-forge swifter???
2.1 一个demo
import pandas as pd
import swifter
df = pd.DataFrame({'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
df['outCol'] = df[['col1', 'col2']].swifter.apply(my_func)
df['outCol'] = df[['col1', 'col2', 'col3']].swifter.apply(my_func,
positional_arg, keyword_arg=keyword_argval)2.2 swifter 提效原理
1、它会判断apply中的函数是否能被向量化vectorization,如果可以,那么他就会自动选择向量化后函数的进行应用(此时是效果最好的);
2、如果apply的函数无法向量化,则自动选择使用 dask parallel processing 和 simple pandas apply 中较快的一种;
3、在分组apply的场景下,swifter也能达到更好的效果。
注意:并行化在小规模的数据集上可能达不到预期的效果,所以并行化操作是根据应用场景酌情使用的,而向量化不管数据集规模的大小都能带一些性能的提升。
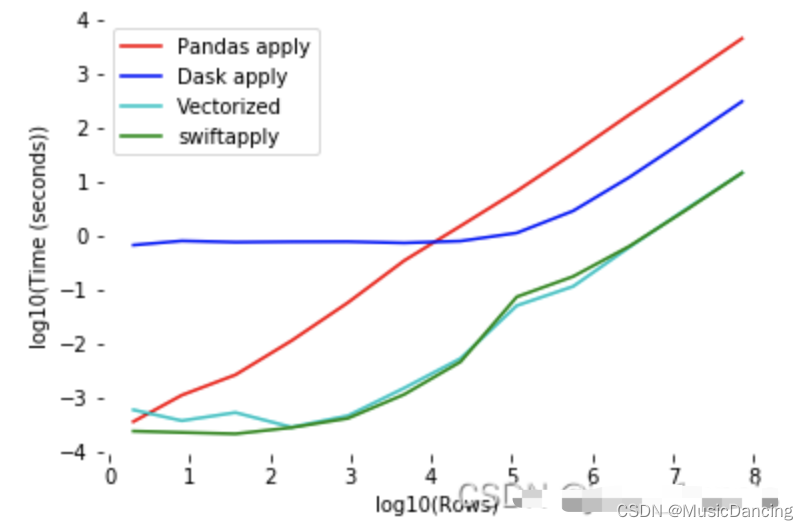
??????? 可以看到Swifter的个特点,即无论数据大小如何,使用向量化效果几乎总是更好;如果数据量较小,那么普通 Pandas 操作有最佳速度,直到数据足够大为止;一旦超过阈值,并行处理就会是处理更快。
3. 多进程 pandarallel
??????? pandarallel 和?pandas 无缝衔接,是实现多线程的一个非常友好的工具。
安装:pip3 install pandarallel
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from pandarallel import pandarallel
# shm_size_mb 分配的内存空间大小
# nb_workers 调用的核数
pandarallel.initialize(nb_workers=10, use_memory_fs=False, progress_bar=True)
def func(x):
return x**3
df = pd.DataFrame(np.random.rand(1000,1000))调用
# 处理一行
df.parallel_apply(func, axis=1)
# 按列处理
df['col1'].parallel_apply(func)下面的这些pandas原来的方法都有对应的pandarallel的并行的实现。

参考:pandas apply 并行处理的几种方法_parallel_apply-CSDN博客
4. joblib
from math import sqrt
from joblib import Parallel, delayed
def test():
start = time.time()
result = Parallel(n_jobs=8)(delayed(sqrt)(i**2) for i in range(10000))
# results = Parallel(n_jobs=8)(delayed(key_func)(group) for name, group in tqdm(data_grouped))
end = time.time()
print(end-end)11
5. multiprocessing
import multiprocessing as mp
with mp.Pool(mp.cpu_count()) as pool:
df['newcol'] = pool.map(fun, df['col'])multiprocessing.cpu_count()? # 返回系统的CPU数量。
该数量不同于当前进程可以使用的CPU数量。可用的CPU数量可以由?
len(os.sched_getaffinity(0))?方法获得。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机网络基础
- Python画皮卡丘
- 秒级弹性!探索弹性调度与虚拟节点如何迅速响应瞬时算力需求?
- 小马识途解析知乎老问答回复推广
- 强大的电子书阅读器:OmniReader Pro for mac
- NTFS权限与CIFS(学习笔记)
- Day50| Leetcode 123. 买卖股票的最佳时机 III Leetcode 188. 买卖股票的最佳时机 IV
- 200倍速!基于 HDF5 的证券数据存储方案
- SSH隧道简单的VPN替代方案
- 总结HarmonyOS的技术特点