GLEE:一个模型搞定目标检测/实例分割/定位/跟踪/交互式分割等任务!性能SOTA!


GLEE,这是一个面向目标级别的基础模型,用于定位和识别图像和视频中的目标。通过一个统一的框架,GLEE实现了对开放世界场景中任意目标的检测、分割、跟踪、定位和识别,适用于各种目标感知任务。采用了一种协同学习策略,GLEE从具有不同监督级别的多源数据中获取知识,形成通用的目标表示,在zero-shot迁移到新数据和任务方面表现出色。具体而言,采用图像编码器、文本编码器和视觉提示器来处理多模态输入,使其能够同时解决各种以目标为中心的下游任务,同时保持最先进的性能。通过在超过五百万张来自不同基准数据集的图像上进行广泛训练,GLEE展现出卓越的多功能性和改进的泛化性能,能够高效地处理下游任务,无需进行任务特定的调整。通过集成大量自动标注的数据,进一步增强了其zero-shot泛化能力。此外,GLEE能够集成到大语言模型中,作为一个基础模型,为多模态任务提供通用的目标级别信息。希望该方法的多功能性和通用性将在高级智能系统的高效视觉基础模型的发展中迈出重要一步。
GLEE模型和代码发布地址: https://glee-vision.github.io/
引言
基础模型是构建通用人工智能系统(AGI)的新兴范式,意味着在广泛数据上训练的模型,能够适应通用范式中的各种下游任务。最近,采用统一的输入-输出范式和大规模预训练的NLP基础模型,如BERT、GPT-3、T5,已经取得了显著的泛化能力,能够解决几乎所有NLP任务。
在计算机视觉领域,任务类型的多样性和缺乏统一形式使得视觉基础模型只能为特定子领域提供服务,例如CLIP用于多模态视觉模型,MAE用于视觉表示模型,SAM用于分割模型。尽管当前的视觉基础模型已经得到广泛研究,但仍然主要集中在建立全局图像特征与语言描述之间的相关性或学习图像级别的特征表示。然而,定位和识别目标构成了计算机视觉系统中的基础能力,为解决复杂或高级视觉任务提供基础,如分割、场景理解、目标跟踪、事件检测和行为识别,并支持广泛的应用。
在这项工作中,本文推动了视觉领域中目标级别基础模型的发展。为了解决前述的局限性,即提供通用且准确的目标级信息,引入了一种通用的目标视觉基础模型,被称为GLEE,它可以同时解决广泛的以目标为中心的任务,确保最先进的性能,包括目标检测、实例分割、定位、目标跟踪、交互式分割和跟踪等,如下图1所示。
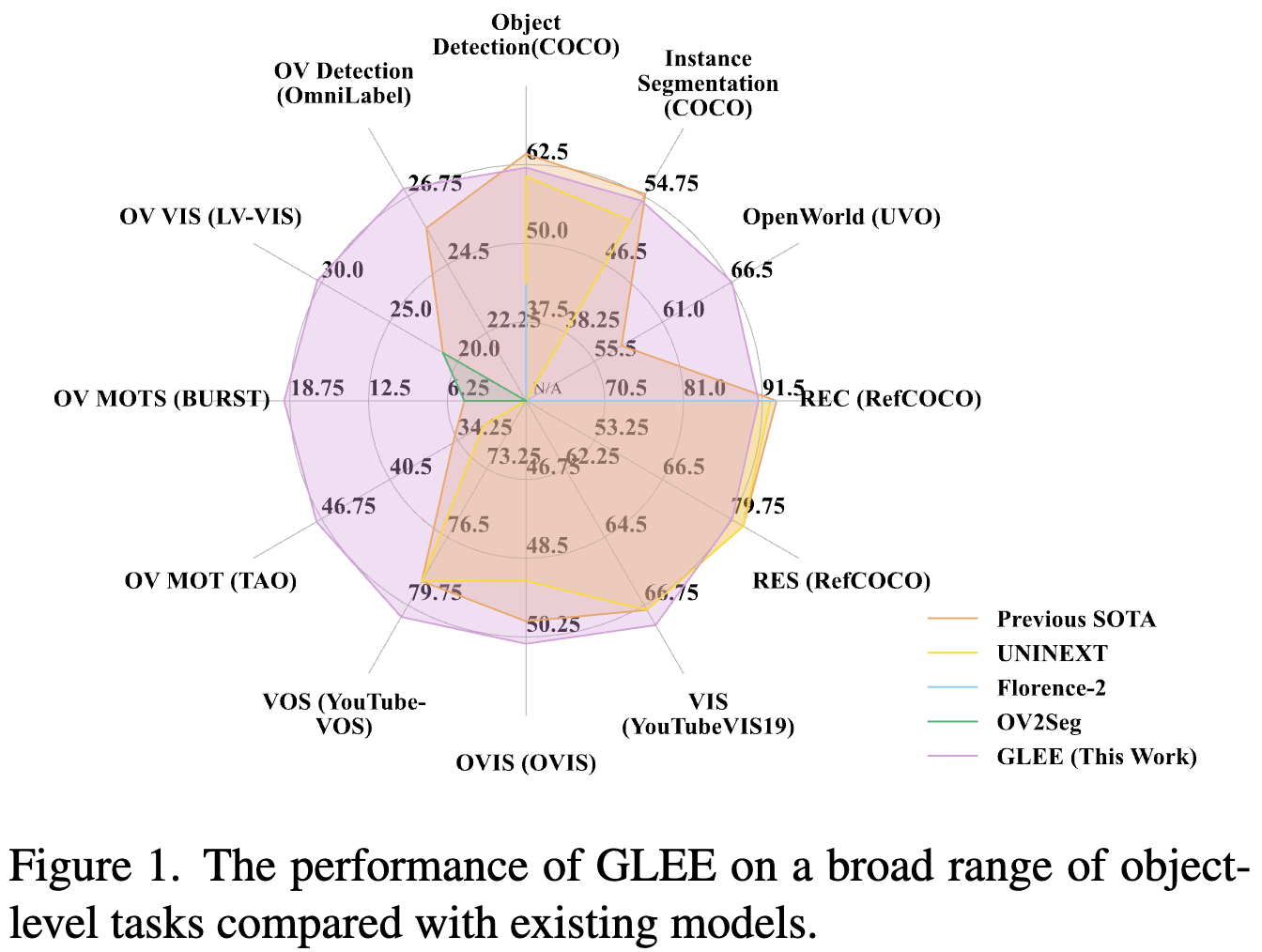
通过统一的输入和输出范式定义,该模型能够从各种多样的数据中学习,并预测通用的目标表示,使其能够以zero-shot的方式很好地推广到新的数据和任务,并取得出色的性能。此外,由于统一的范式,通过引入大量自动标注的数据,可以以低成本扩大训练数据,并进一步提高模型的zero-shot泛化能力。
「通用目标基础模型框架」。本文的目标是构建一个能够同时处理广泛的以目标为中心任务的目标视觉基础模型。具体而言,采用图像编码器、文本编码器和视觉提示器来编码多模态输入。它们被集成到一个检测器中,根据文本和视觉输入从图像中提取目标。这种处理多模态的统一方法使我们能够同时解决各种以目标为中心的任务,包括检测、实例分割、目标指代理解、交互式分割、多目标跟踪、视频目标分割、视频实例分割以及视频指代分割,同时保持最先进的性能。
「多粒度联合监督和可扩展训练范式」。设计能够处理多个任务的统一框架使得可以在来自不同基准和不同监督级别的超过五百万张图像上进行联合训练。现有数据集在标注粒度上存在差异:像Objects365 和OpenImages这样的检测数据集提供边界框和类别名称;COCO和LVIS提供更细粒度的mask标注;RefCOCO和Visual Genome提供详细的目标描述。此外,视频数据增强了模型的时序一致性,而开放世界数据贡献了类别无关的目标标注。下图2直观地展示了使用的数据集的监督类型和数据规模。
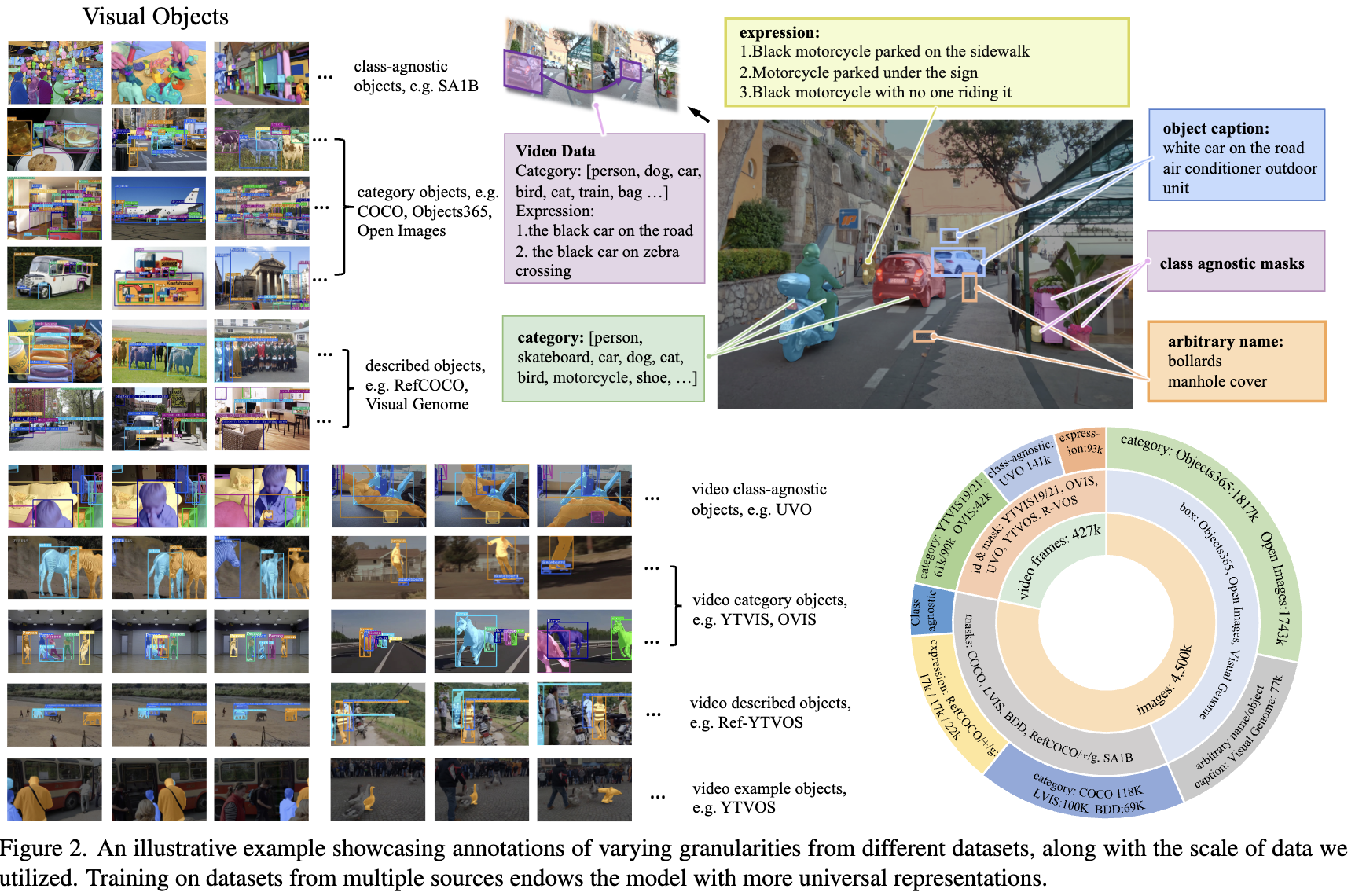
本文方法对多源数据的统一支持极大地促进了额外手动或自动标注数据的整合,实现了数据集的轻松扩大。此外,跨任务的模型优化对齐意味着联合训练不仅作为一种统一策略,还作为提升各个任务性能的机制。
「对广泛的目标级图像和视频任务的强大zero-shot可迁移性」。在来自不同来源的数据上进行联合训练后,GLEE展现出卓越的多功能性和zero-shot泛化能力。大量实验证明,与现有的专业和通用模型相比,GLEE在目标级别图像任务(如检测、目标指代理解和开放世界检测)方面取得了最先进的性能,而无需任何特定于任务的设计或微调。此外,还展示了GLEE在大规模词汇开放世界视频跟踪任务中的卓越泛化和zero-shot能力,即使在zero-shot迁移的情况下,其性能显著优于现有模型。并且通过引入像SA1B和GRIT这样的自动标注数据,能够以较低成本将训练数据集扩大到惊人的1000万张图像,这通常对于目标级任务而言是具有挑战性的,进一步增强了泛化性能。此外,在多模态大语言模型(mLLM)中用GLEE替换了SAM组件,并观察到其取得了可比的结果。这表明GLEE能够为现代LLMs提供它们目前缺乏的视觉目标级信息,从而为以目标为中心的mLLMs奠定了坚实的基础。
相关工作
视觉基础模型
随着NLP领域的基础模型取得了显著成功,视觉基础模型的构建引起了越来越多的关注。与主要统一在文本到文本范式下的NLP任务不同,计算机视觉中的任务在形式和定义上仍然存在显著差异。这种差异导致视觉基础模型通常在单任务学习框架下训练,限制了它们对特定子领域任务的适用性。例如,像CLIP、ALIGN、Florence、BEIT3、Flamingo这样的多模态视觉基础模型通过对大规模图像-文本对进行对比学习和屏蔽数据建模,在视觉语言任务上展现了出色的zero-shot能力,取得了显著进展。DALL-E和Stable Diffusion在大量图像和标题对上进行训练,使它们能够生成受文本指令调节的详细图像内容。DINO、MAE、EVA、ImageGPT通过对大规模图像数据进行自监督训练获得强大的视觉表示,然后将其用于下游任务的迁移。这些基础模型学习的是图像级别的特征,直接应用于目标级任务存在困难。最近提出的SAM能够基于视觉提示(如点和框)对给定图像中的任何目标进行分割,提供了丰富的目标级信息并展现了强大的泛化能力。然而,该目标信息缺乏语义上下文,限制了其在目标级任务中的应用。与现有的视觉基础模型不同,本文的目标是开发一个目标基础模型,直接解决下游任务,无需额外的参数或微调。
统一和通用模型
统一模型在多任务统一方面与基础模型相似,因为它们具有在单一模型内处理多个视觉或多模态任务的能力。MuST和Intern建议跨多个视觉任务进行训练并同时解决它们。受到sequence-to-sequence NLP模型的成功启发,诸如Uni-Perceiver、OFA、Unified-IO、Pix2Seq v2和UniTAB的模型提出将各种任务建模为统一范式下的序列生成任务。尽管这些方法已经展示了有希望的跨任务泛化能力,但它们主要关注图像级别的理解任务。此外,它们自回归生成框和mask,导致推断速度明显较慢,并且性能仍然不及最先进的特定任务模型。基于检测器的工作,Uni-Perceiver v2和UNINEXT利用统一的最大似然估计和目标检索来支持各种任务,有效解决了定位的挑战。然而,它们是在封闭集数据上训练的,因此没有展现出zero-shot泛化能力。
X-decoder和SEEM构建了一个通用的解码模型,能够预测像素级分割和语言标注。与统一模型不同,提出的GLEE不仅以统一的方式直接解决目标级任务,而且提供通用的目标表示,可以很好地推广到新的数据和任务,为需要详细目标信息的更广泛任务奠定基础。
视觉语言理解
开放词汇检测(OVD)和Grounding模型都需要尽可能多地定位和识别目标。随着最近在视觉语言预训练方面的进展,OVD的一种常见策略是将预训练的视觉语言模型(VLMs)的知识迁移给目标检测器。另一组研究利用大量的图像-文本对数据集扩展检测词汇。然而,这些基于语言的检测器在本质上受到语言模型的能力和偏见的限制,使得在定位和识别两方面同时取得卓越表现变得具有挑战性。本文的目标是最大程度地利用现有数据集构建一个通用的目标级基础模型,旨在不仅有效地检测和识别目标,而且为各种下游任务提供通用的目标表示。
方法
表述
提出的GLEE包括图像编码器、文本编码器、视觉提示器和目标解码器,如下图3所示。
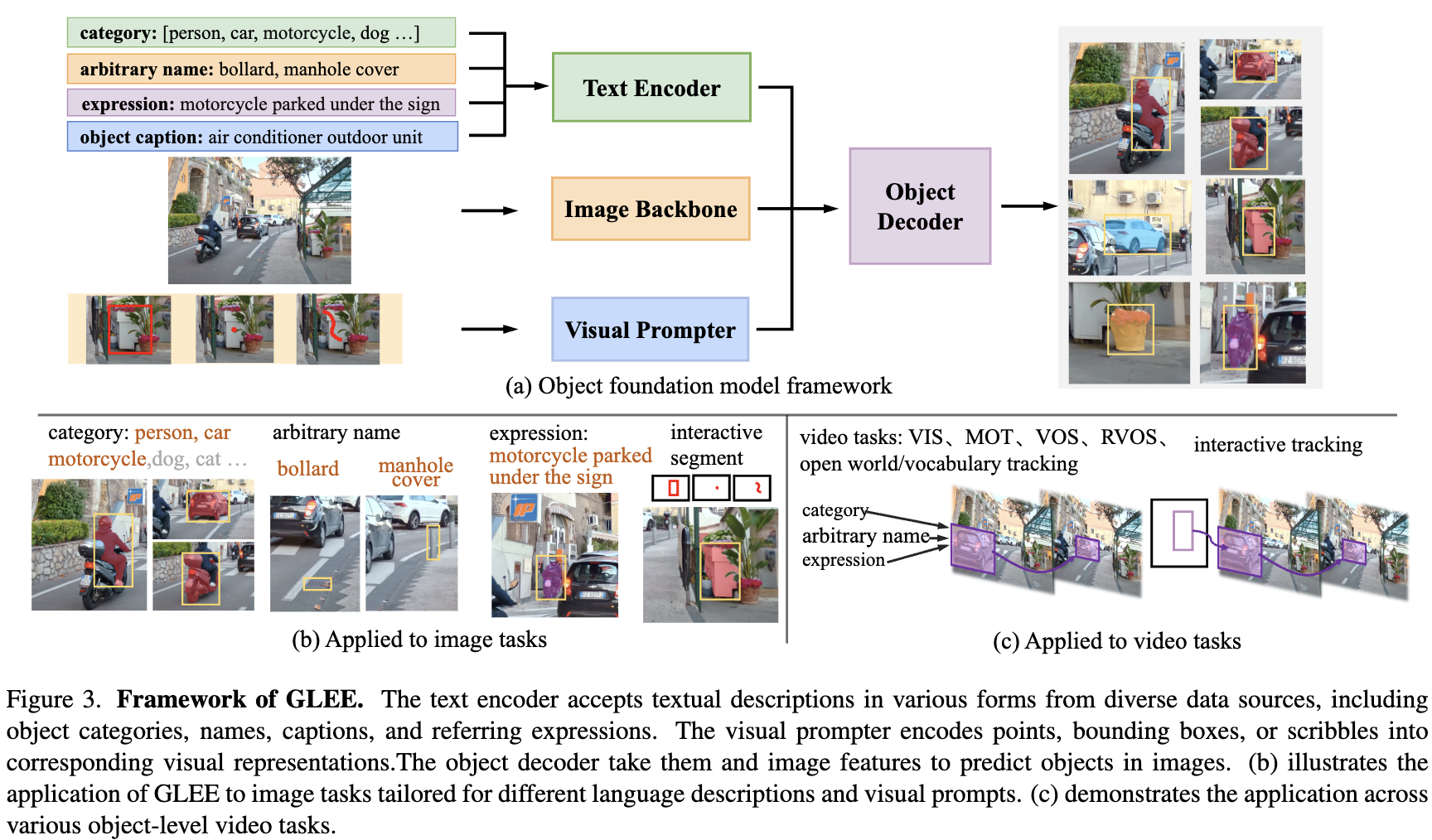
文本编码器处理与任务相关的任意描述,包括目标类别、以任何形式呈现的名称、关于目标的标题以及指代表达式。视觉提示器将用户输入(如点、边界框或涂鸦)编码为与目标目标相对应的视觉表示,特别是在交互式分割期间。然后,它们被集成到一个检测器中,根据文本和视觉输入从图像中提取目标。基于MaskDINO构建了目标解码器,其中包含一个具有动态类别头的网络,通过计算来自检测器的目标embedding和文本编码器的文本embedding之间的相似性。给定输入图像I ∈ ,首先使用ResNet等主干提取多尺度特征Z。然后,将它们输入到目标解码器,并在解码器输出的embedding上采用三个预测头(分类、检测和分割)。在其他目标分割模型之后,构建一个1/4分辨率的像素embedding图,通过对主干和Transformer编码器的多尺度特征图进行上采样和融合得到。最后,通过N个mask embedding和像素embedding图之间的点积,得到每个二值mask预测。
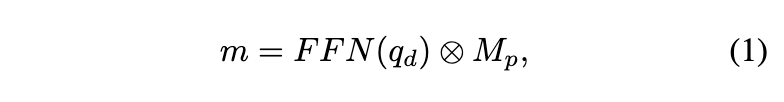
其中,FFN是一个具有ReLU激活函数和线性投影层的3层前馈head。
为了支持任意词汇和目标描述,将FFN分类器替换为文本embedding,遵循DetCLIP的方法。具体而言,将K个类别名称作为单独的句子输入到文本编码器EncL,并使用每个句子tokens的平均值作为每个类别或描述的输出文本embedding。然后,计算目标embedding和文本embedding之间的对齐分数:
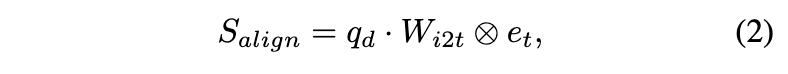
这里, 是图像到文本的投影权重矩阵。
使用对齐分数替代传统的分类logits来计算训练过程中的Hungarian匹配成本,并在推理过程中为目标分配类别。为了使原始的视觉特征具有提示感知能力,在Transformer编码器之前采用了一个早融合模块,该模块按照UNINEXT的方法,将来自主干的图像特征和提示embedding作为输入,进行双向的交叉注意力操作。
任务统一
基于上述设计,GLEE 可以无缝地统一图像和视频中的各种目标感知任务,包括目标检测、实例分割、定位、多目标跟踪(MOT)、视频实例分割(VIS)、视频目标分割(VOS)、交互式分割和跟踪,并支持开放世界/大规模词汇图像和视频检测和分割任务。
「检测和实例分割」。对于检测任务,给定一个固定长度的类别列表,需要检测类别列表中的所有目标。对于类别列表长度为 K 的数据集,文本输入可以被表示为 ,其中 代表第 k 个类别名称,例如,对于 COCO,P = ["person", "bicycle", "car", ... , "toothbrush"]。对于具有大词汇的数据集,计算所有类别的文本embedding非常耗时且多余。因此,对于类别数量大于 100 的数据集,例如 Objects365 和 LVIS,假设图像中存在 个正类别,取这 个正类别,然后通过从负类别中随机采样来填充类别数到 100。对于实例分割,启用了mask分支,并使用mask损失添加了mask匹配成本。
「Grounding和Referring分割」。这些任务提供了引用文本表达,其中目标使用属性描述,例如,Referring Expression Comprehension (REC)、Referring Expression Segmentation (RES) 和 Referring Video Object Segmentation (R-VOS)旨在找到与给定语言表达(如“从左边数第四个人”)匹配的目标。对于每个图像,将所有目标表达作为文本提示,并将其馈送到文本编码器。对于每个表达,沿序列维度应用全局平均池化以获得文本embedding 。文本embedding被馈送到早融合模块,并通过解码器中的自注意力模块与目标query进一步交互。
「MOT 和 VIS」。多目标跟踪(MOT)和视频实例分割(VIS)都需要检测和跟踪预定义类别列表中的所有目标,而 VIS 需要为目标提供附加的mask。这两个任务可以被视为视频上检测和实例分割的扩展任务。在有足够图像曝光的情况下,解码器中的目标embedding能够有效地区分视频中的目标,显示出强烈的可区分性和时间一致性。因此,它们可以直接用于跟踪,无需额外的跟踪head。在图像级别数据上的训练可以处理直接的跟踪场景,但在存在严重遮挡的场景中,例如 OVIS,图像级别的训练不能保证模型在遮挡条件下表现出强烈的时间一致性。因此,对于遮挡场景,有必要利用视频数据进行训练。按照 IDOL 的方法,本文从视频中采样两帧,并在帧之间引入对比学习,使同一目标实例的embedding在embedding空间中更加接近,而不同目标实例的embedding更远。在推理过程中,通过对应目标query的简单二分匹配来跟踪检测到的目标,遵循 MinVIS 的方法。
「视觉提示分割」。交互式分割采用各种形式的视觉提示,例如点、框或涂鸦,来分割图像中指定的目标。另一方面,VOS 的目标是基于视频的第一帧中提供的mask,在整个视频中分割整个目标。在模型中提取两次视觉提示embedding。首先,从 RGB 图像中裁剪提示的正方形区域,并将其发送到主干以获取相应区域的视觉提示特征,并将其发送到 Transformer 编码器之前的早融合模块。其次,根据视觉提示从像素embedding图 中采样细粒度的视觉embedding,并使其通过 Transformer 解码器层中的自注意力模块与目标query交互,与文本embedding相同。
训练统一
「具有动态损失的任务」。在超过5百万张来自不同基准数据集的图像上以端到端的方式联合训练 GLEE,采用各种监督级别。对于在不同数据集上的训练,选择不同的损失函数。GLEE 有六种损失类型:语义Loss、框Loss、mask Loss、置信度Loss、对比跟踪Loss和蒸馏Loss。对于所有具有类别列表或目标表达的任务,将focal loss作为语义损失应用在对齐文本概念和目标特征的 logits 上。对于框预测,使用 L1 Loss和广义 IoU Loss的组合。mask Loss定义为 Dice Loss和focal loss的组合。对于视觉提示分割任务,使用额外的 FFN 来预测每个目标query的置信度分数,由focal loss监督。按照 IDOL,对于视频任务,采样两帧,并在解码器的最后一层上对目标query应用对比跟踪Loss:
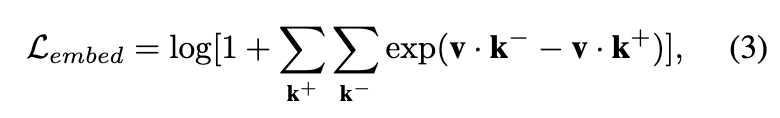
其中, 和 分别是来自参考帧的属于同一目标的目标query和其他目标的目标query。对于文本编码器,从教师 CLIP 文本编码器中提取知识,以确保在预训练的视觉语言embedding空间中的文本embedding。应用 L1 损失在使用的的文本编码器和 CLIP 文本编码器之间,以最小化它们之间的距离:

「数据规模扩大」。一个视觉基础模型应该能够轻松扩大训练数据并实现更好的泛化性能。由于统一的训练范式,可以通过引入大量来自 SA1B和 GRIT的自动标注数据来以较低的成本扩大训练数据。SA1B 提供了大量且详细的mask标注,增强了模型的目标感知能力,而 GRIT 提供了更广泛的指称表达和边界框对,提高了目标识别能力和对描述的理解能力。最终,引入了 200 万个 SA1B 数据点和 500 万个 GRIT 数据点到训练过程中,将总训练数据扩大到 1000 万。
实验
实验设置
「数据集和训练策略」。进行了三个阶段的训练。最初,在 Objects365 和 OpenImages 上执行目标检测任务的预训练,在这一阶段,使用预训练的 CLIP 权重初始化文本编码器,并保持参数冻结。在第二个训练步骤中,引入了额外的实例分割数据集,包括 COCO、LVIS和 BDD。此外,又将三个 VIS 数据集:YTVIS19、YTVIS21和 OVIS视为独立的图像数据,以丰富场景。对于提供目标描述的数据集,包括 RefCOCO、RefCOCO+、RefCOCOg、Visual Genome和 RVOS。由于 Visual Genome 在单个图像中包含多个目标,将其视为检测任务,并将目标描述和目标名词短语作为类别,每批次总共有 200 个动态类别列表。此外,引入了两个开放世界实例分割数据集,UVO 和 SA1B 的一个子集。对于这两个数据集,将每个目标的类别名称设置为 'object',并在实例分割范式中进行训练。在第二步中,文本编码器解冻,但通过蒸馏损失监督,以确保在 CLIP embedding空间中的预测文本embedding。在第二步之后,GLEE 在一系列图像和视频任务中展示了最先进的性能,并展现了强大的zero-shot泛化能力,除非另有说明,下面呈现的所有实验结果均由模型在这个阶段获得。
基于此,引入了 SA1B 和 GRIT 数据集以扩大训练集,得到了一个名为 GLEE-scale 的模型,该模型在各种下游任务上展现出更强的zero-shot性能。由于仅图像数据不足以使模型学习到时间一致性特征,从 YTVIS、OVIS、RVOS、UVO 和 VOS 中引入了序列视频数据,以提高其性能,如果有特别说明。
「实现细节」。实验中,分别使用 ResNet-50、Swin-Large和 EVA-02 Large作为视觉编码器,开发了 GLEE-Lite、GLEE-Plus 和 GLEE-Pro。与 MaskDINO一样,在目标解码器中采用可变形 transformer,使用 300 个目标query。为了加速收敛并提高性能,保留了query去噪和混合匹配。在预训练期间,在 64 个 A100 GPU 上将小批量设置为 128,进行 50 万次迭代。对于联合训练,在 64 个 A100 GPU 上对 GLEE 进行 50 万次迭代的训练。
与通用模型的比较
本文展示了GLEE模型作为一个目标级别的视觉基础模型的普适性和有效性,直接适用于各种以目标为中心的任务,同时确保在无需微调的情况下保持最先进的性能。将该方法与现有的专业模型和通用模型在图像级任务上进行比较,包括检测、目标指代理解和开放世界实例分割。在 COCO 验证集和 LVIS val v1.0上报告了检测和实例分割的结果。虽然两者几乎共享相同的图像集,但 LVIS 的标注涵盖了超过 1,200 个目标类别,展示了一种长尾分布。这种区别使 LVIS 在更广泛的类别覆盖范围中更具代表性,更能反映具有挑战性的真实场景。如下表1所示,该模型在COCO和LVIS基准上均优于所有通用模型。
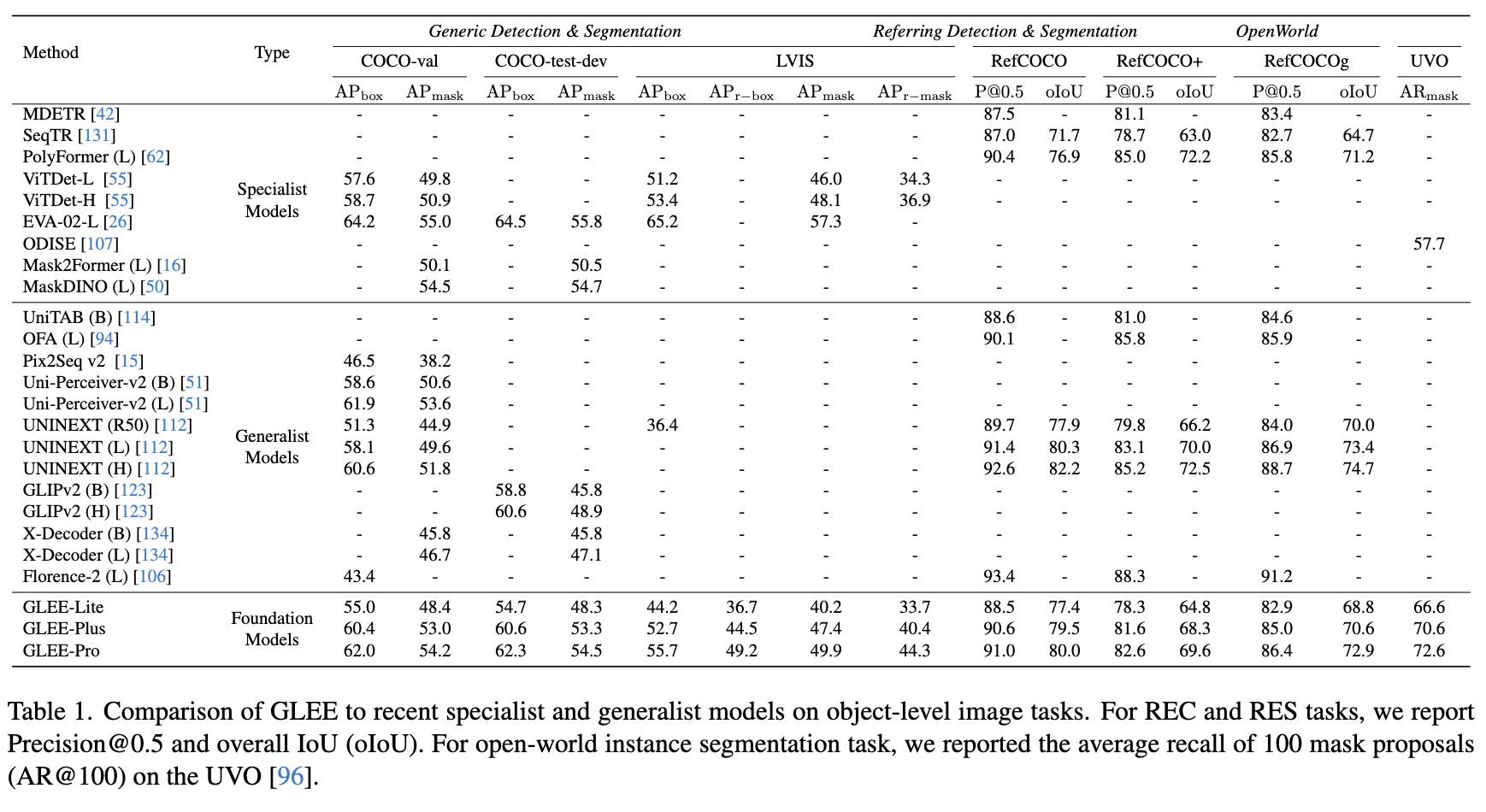
即使与其他最先进的专业方法相比,这些方法通过特定设计定制,GLEE模型仍然具有很高的竞争力。这表明,GLEE在掌握通用和一般的目标表示的同时,同时在目标检测和分割方面保持了先进的能力。这个特点对于适应需要精确目标定位的广泛下游任务是至关重要的。对于 REF 和 RES 任务,在 RefCOCO、RefCOCO+和 RefCOCOg上评估了GLEE模型,如前面表1所示,GLEE在理解文本描述方面取得了与 PolyFormer等最先进专业方法相媲美的结果,展示了理解文本描述的强大能力,并展示了适应更广泛的多模态下游任务的潜力。在开放世界实例分割任务中,将“object”作为类别名称,指示模型以类别无关的方式识别图像中的所有可能实例。GLEE超越了以前的技术 ODISE 8.9 分,展示了在开放世界场景中识别所有可能存在的实例的能力。
跨任务zero-shot评估
「zero-shot迁移至视频任务」。本文提出的 GLEE 能够以zero-shot的方式适应新的数据,甚至是新的任务,无需额外的微调。在三个大规模、大规模词汇量的开放世界视频跟踪数据集上评估其zero-shot能力:TAO、BURST和 LV-VIS。TAO 包括 2,907 个高分辨率视频,涵盖了 833 个类别。BURST 建立在 TAO 的基础上,包含了 425 个基础类别和 57 个新类别。LV-VIS 提供了 1,196 个明确定义的目标类别中的 4,828 个视频。这三个基准要求模型在视频中检测、分类和跟踪所有目标,而 BURST 和 LV-VIS 还需要模型的分割结果。在下表2中,提出的模型的性能与现有的专业模型进行了比较。
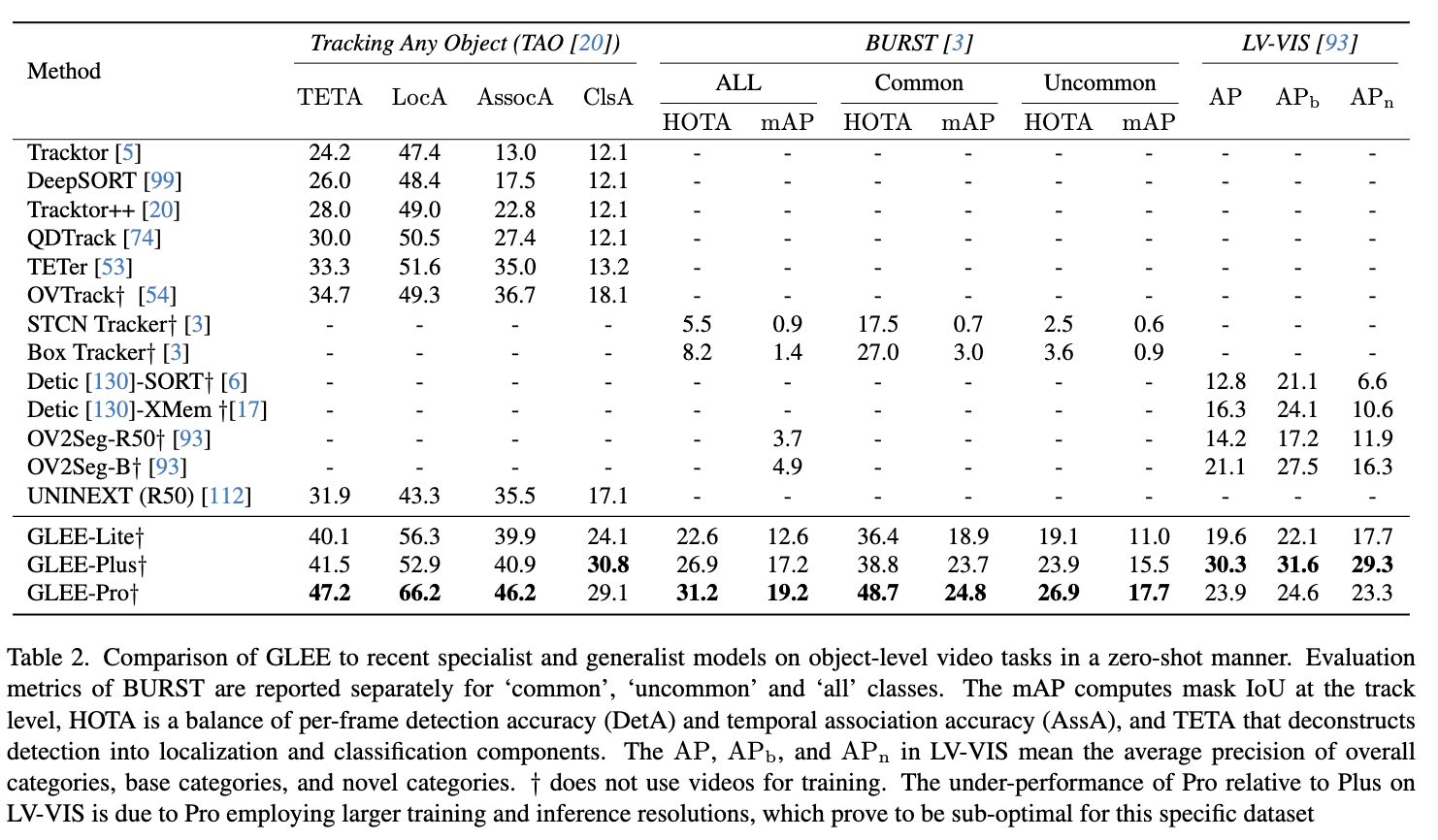
值得注意的是,这里的 GLEE 来自第二个训练阶段,它没有接触过这三个数据集的图像,也没有在视频级别的数据上进行训练。尽管有这些限制,GLEE 实现了显著超越现有方法的最先进性能。具体而言,GLEE 在 TAO 上超过了先前最佳方法 OVTrack 36.0%,在 BURST 中几乎将最佳基线的性能提高了三倍,并在 LV-VIS 中超过了 OV2Seg 43.6%。这一卓越的表现充分验证了 GLEE 在处理跨越一系列基准和任务的目标级任务中的出色泛化和zero-shot能力。
还在经典视频分割任务上进行了性能比较,包括 VIS、VOS 和 RVOS。如下表4所示,在 YTVIS2019基准上,GLEE模型在各种模型规模下都取得了 SOTA 的结果,超过了所有具有复杂设计以增强时间能力和视频统一模型 UNINEXT的专业模型。
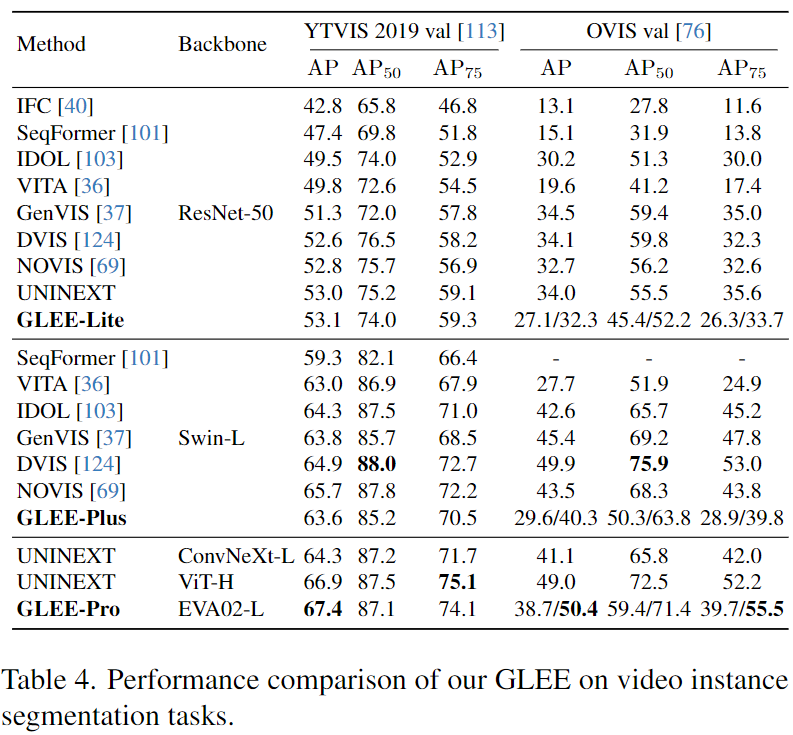
在 OVIS基准上,该基准具有大量目标遮挡的漫长视频,其中目标特征的时间能力特别关键,的模型没有直接达到 SOTA。然而,在简单微调几个小时后,它仍然实现了 SOTA 的性能。这进一步验证了GLEE模型的多才多艺和泛化能力。有关视频任务zero-shot评估和交互分割和跟踪演示的更多详细信息,请参见补充材料的第7节。
「zero-shot迁移至现实世界的下游任务」。为了衡量在不同的现实世界任务上的泛化性能,我们在 OmniLabel上评估了zero-shot性能,这是一个用于评估基于语言的目标检测器的基准,并鼓励目标的复杂和多样的自由形式文本描述。如下表5所示,与在大规模字幕数据上训练的基于语言的检测器相比,GLEE在 P-categ 中明显优于先前的模型。
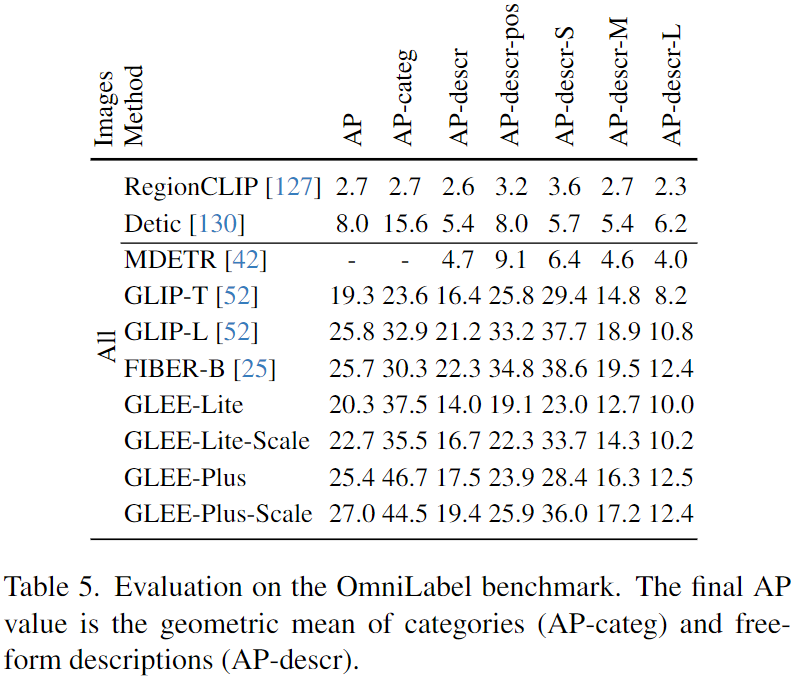
然而,由于训练数据集中字幕有限,在 AP-descr 中得分较低。通过引入来自 GRIT的更多样的盒子字幕数据来扩大训练集,AP-descr 可以提升到与现有模型相当的水平。在“Object Detection in the Wild” (ODinW) 基准上进行了额外的实验,该基准是一个涵盖了各种领域的数据集套件。我们报告了 [52] 中引入的 13 个 ODinW 检测数据集的平均 mAP,并报告了zero-shot方式下每个数据集的性能,如下表3所示。
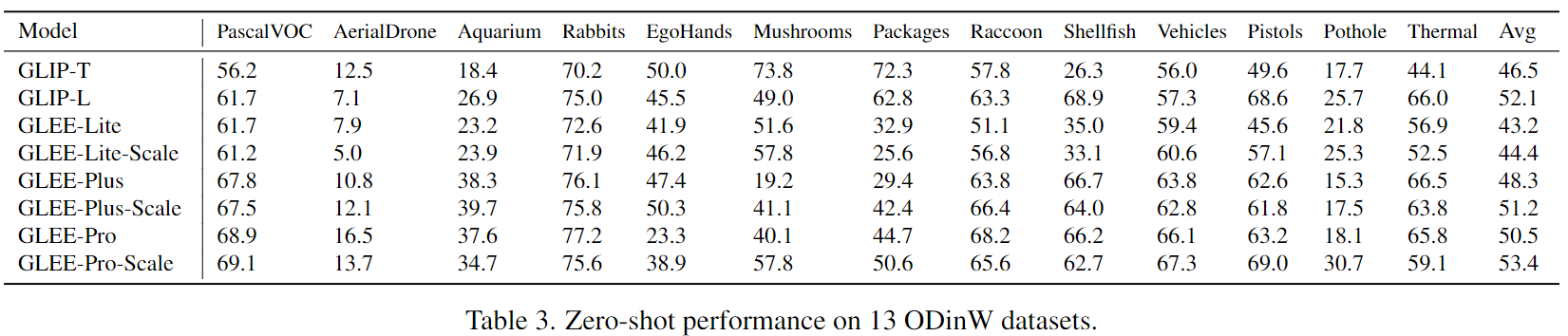
GLEE在 13个公共数据集的平均上表现优于 GLIP,展示了其强大的泛化能力。此外,通过以低成本引入自动标注的数据来扩大训练数据,zero-shot能力可以进一步增强,这表明 GLEE 通过规模化具有更大的潜力。关于在 ODinW 上每个数据集的 few-shot 性能的更全面报告可在补充材料中找到,以评估 GLEE 对其他数据集的适应能力。
作为基础模型
为了探讨 GLEE 是否可以作为其他体系结构的基础模型,选择了 LISA进行分析,这是一个将 LLAVA与 SAM 结合起来进行分割推理的 mVLLM。用预训练的 GLEE-Plus 替换了它的视觉主干,将 GLEE 的目标query输入到 LLAVA 中,并删除了 LISA 的解码器。直接将输出的 SEG tokens与 GLEE 特征图进行点积,以生成mask。如下图 4 所示,在相同步骤数的训练后,修改后的 LISA-GLEE 实现了与原始版本相当的结果,证明了 GLEE 表示的多功能性以及其在为其他模型提供服务方面的有效性。

消融实验
实验以研究在各种任务中zero-shot性能上训练数据规模的影响。为此,使用 10%、20%、50%、100% 的训练数据对 GLEE-Pro 进行了训练,评估了zero-shot迁移任务的性能,包括 TAO、BURST、OVIS 和 YTVIS,如下图 5 所示。
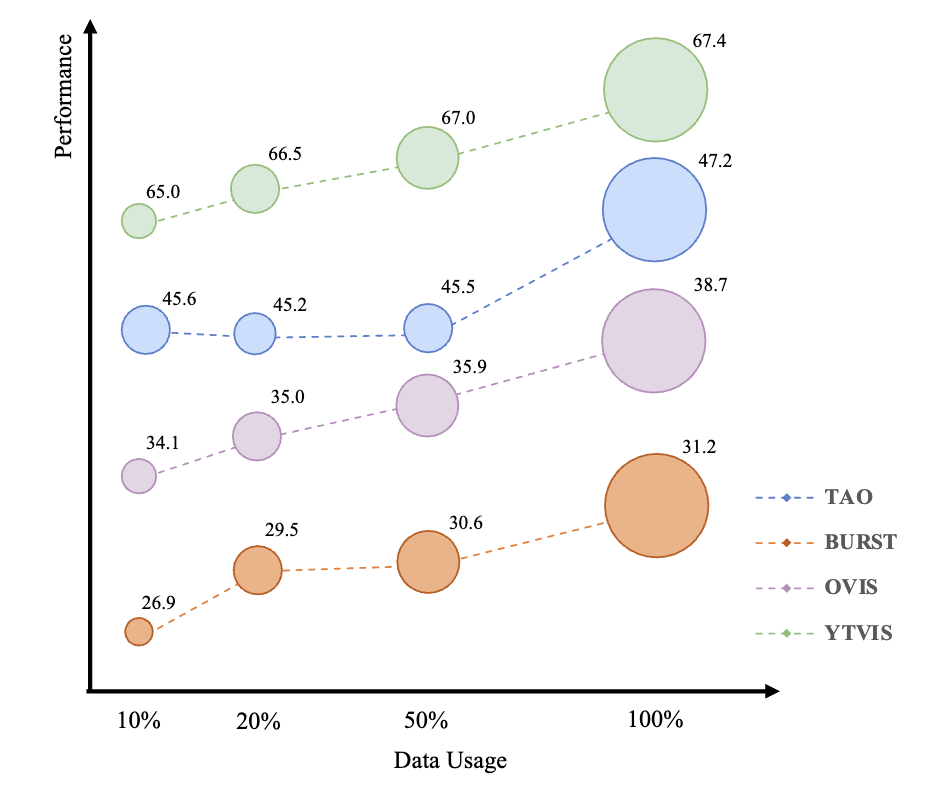
数据规模实验证明,训练数据集的增加可以提高在不同下游任务中的zero-shot性能。这一结果意味着更大的预训练数据集是一项有价值的投资,为广泛的下游任务提供了更有效和可适应的基础。由于 GLEE 的统一训练方法,可以高效地将任何手动或自动标注的数据纳入训练过程,以实现增强的泛化能力。
结论
本文引入了GLEE,这是一种先进的目标级基础模型,专为直接应用于各种目标级图像和视频任务而设计。通过采用统一的学习范式,GLEE从具有不同监督级别的各种数据源中学习。GLEE在许多目标级任务上取得了最先进的性能,并在zero-shot迁移到新数据和任务时表现出色,显示出其卓越的多功能性和泛化能力。此外,GLEE提供了通用的视觉目标级信息,这是现代LLM中目前缺失的,为面向目标的多模态语言模型(mLLMs)奠定了坚实的基础。
参考文献
[1] General Object Foundation Model for Images and Videos at Scale
论文链接:https://arxiv.org/pdf/2312.09158
?多精彩内容,请关注公众号:AI生成未来

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 开箱即用的企业级前后端分离【.NET Core6.0 Api + Vue 2.x + RBAC】权限框架-Blog.Core
- 【ARM Trace32(劳特巴赫) 使用介绍 14 -- Go.direct 介绍】
- Kylin: 多维度数据分析引擎
- PCL+CGAL进行2D delaunay重建
- 百度旋转验证码识别(最新)
- 【黑马程序员】day01-Java入门-作业
- Redis 中的哨兵选举算法是如何实现的?
- Java序列化篇----第二篇
- 【教程】cocos2dx资源加密混淆方案详解
- 智能助手的巅峰对决:ChatGPT对阵文心一言