【论文阅读】Video-to-Video Synthesis
基于条件GAN的视频到视频生成。
introduce
????总结:基于条件GAN的视频到视频生成。将视频到视频的合成问题视为一个分布匹配问题。
? 动机:GAN生成的视频很难保证前后帧的一致性,容易出现抖动。本文加入前后帧的光流信息作为约束。Vid2Vid作为pix2pix, pix2pixHD的改进版本,重点解决了视频到视频转换过程中的前后帧不一致性问题。Vid2Vid建立在pix2pixHD基础之上,加入时序约束。实现高分辨率长视频生成。接受多种输入(分割掩码,草图和姿势),能够合成长达30秒的2K分辨率街景视频。
? ?贡献:1.编辑对视频生成结果进行灵活控制。例如将视频中建筑物替换为树木。2.输入其他视频格式,如草图和姿势,输出合成视频。3.未来预测。

图:从城市景观的输入segmentation map视频生成逼真的视频。
左上:输入。右上:pix2pixHD。左下:COVST。右下:vid2vid。
链接:https://tcwang0509.github.io/vid2vid/paper_gifs/cityscapes_comparison.gif
vid2vid解决的问题是以源视频(如semantic map序列或者从人脸视频中提取的边缘序列)作为条件输入
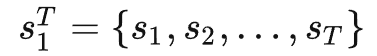
生成目标视频(真实街景图像或者人脸)
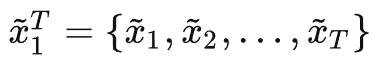
其中上标的T和下标的1代表从时间维度上的第1帧~第T帧
因此其目标是使生成视频的条件分布尽可能与真实视频的条件分布相近,即
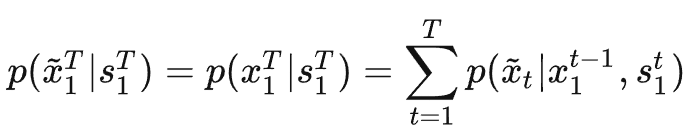
为了简化这个问题的求解难度,文章对这个过程做了马尔可夫假设,即当前帧生成的视频![]()
仅与前L帧的信息相关,而不是与整个?1~t?帧的视频序列的信息都相关,因此上式的约束条件就变成了
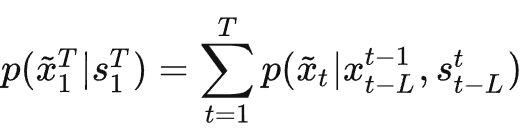
就是在生成第?t帧视频时,只需要将下边三类信息送入网络:
- 当前第t?帧的条件输入?st
- 前L帧的条件输入
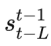
- 模型生成的前L帧图像
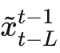
对于输入2)和3),马尔可夫假设保证只需要提供前L帧的信息,而不是前边所有帧的信息,显然就会使网络更容易优化。文章通过实验发现L一般取2就可以,L太小会损失时序信息,L太大会造成巨大的GPU开销且提升的效果也有限。
光流约束
视频在连续帧中会有大量的信息冗余,(对于相邻的两帧图像,在空间上大部分区域像素都是相同的,而只有少部分存在运动的区域的像素有较大的变化)光流(optical flow)就可以用来表示这些区域的变化大小和方向。
因此在生成第t帧视频时,相比?仅使用条件输入st信息(类似pix2pixHD那样)?或者?使用前L帧视频的完整信息,更好的方式是估算从第?t?1帧到第t帧的光流![]() ,然后作用于?t?1?帧,从而直接得到当前第t?帧的预测值(原文:wrap当前帧以预测下一帧),即加入光流约束。这种方法除了被遮挡或者移动到视频外部的区域,对于大部分区域的预测都是准确的。加入光流约束:
,然后作用于?t?1?帧,从而直接得到当前第t?帧的预测值(原文:wrap当前帧以预测下一帧),即加入光流约束。这种方法除了被遮挡或者移动到视频外部的区域,对于大部分区域的预测都是准确的。加入光流约束:
![]()
1)?

就是上文所说的,将估计的光流作用于前一帧图像,从而得到下一帧图像的预测值,其中估计的光流如图8和图9的右下角所示,是由Generator的一个单独分支生成的,其训练过程中的GroundTruth是由Flownet2生成的(所以对于vid2vid来说,其光流估计准确率的上限也就是Flownet2的准确率)
2)?![]() ?是仅使用?条件输入?和?前几帧的信息?得到?当前帧的原始图像,没有加光流约束(?
?是仅使用?条件输入?和?前几帧的信息?得到?当前帧的原始图像,没有加光流约束(?![]() ?的生成过程与pix2pixHD是完全一致的,没加入新东西)
?的生成过程与pix2pixHD是完全一致的,没加入新东西)
3)?![]() 是权重map,即对?通过1)中flow预测得到的当前帧图像?和?由2)中条件输入直接生成的当前帧原始图像?进行融合时,两部分各占的比例大小。
是权重map,即对?通过1)中flow预测得到的当前帧图像?和?由2)中条件输入直接生成的当前帧原始图像?进行融合时,两部分各占的比例大小。
理解:既然?直接生成的原始图像?没有考虑光流约束?可能造成时序不一致,而仅仅使用光流wrap得到下一帧图像在多帧图像之后容易造成累计误差,且当图像出现遮挡或者移出画面会造成预测不准确,那么直接将这两种方法生成的图像融合在一起就可以了。前一部分:![]() ;后一部分:
;后一部分:![]() 。融合的方法也很简单,就是把这两部分的结果加权平均,而这个权重就是?
。融合的方法也很简单,就是把这两部分的结果加权平均,而这个权重就是?![]() ,是一个与生成图像一样大小的map(mask),这样图像的不同区域还可以使用不同的权重。这个
,是一个与生成图像一样大小的map(mask),这样图像的不同区域还可以使用不同的权重。这个![]() 也是网络自己学出来的,在图8和图9中也是生成flow map的那个分支负责生成的。最终这个加了flow约束的Generator就如式(4)所描述的这样。
也是网络自己学出来的,在图8和图9中也是生成flow map的那个分支负责生成的。最终这个加了flow约束的Generator就如式(4)所描述的这样。
Generator网络结构

?G1低分辨率(Coarse) Generator
延续了pix2pixHD的设计,vid2vid还是使用了两阶段的Generator,第一阶段G1用来生成全局粗糙的低分辨率视频,第二阶段G2用来生成局部细化的高分辨率视频。
其中,G1的输入是下采样2倍之后,前L帧+当前帧的Semantic map序列以及之前L帧生成图像的序列,在经过下采样和提特征之后,在网络的中间将两路输提取入的feature map相加,接着在网络后部又分出两个分支,来生成未加光流约束的原始图像以及光流和权重mask;
G2的输入是原始分辨率的Semantic map序列以及生成图像,在经过2倍下采样+提特征的卷积层之后,将两个分支提取的feature map分别与G1对应的两路输出相加,然后分别送入G2后半部分的两个分支,进行局部细节的refine。
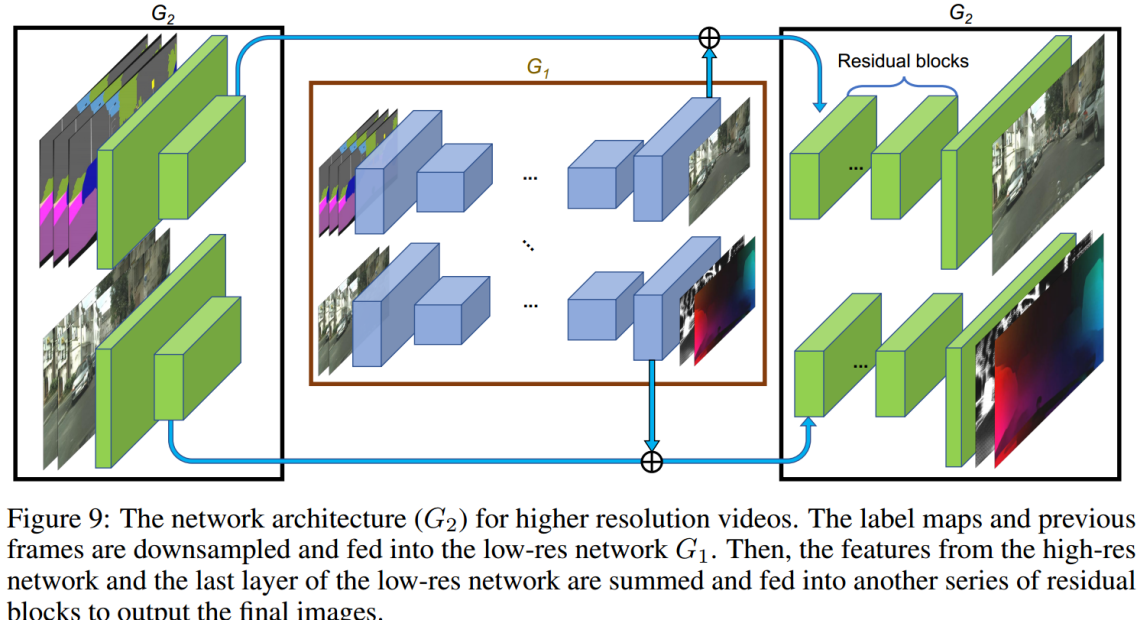
G2高分辨率(Refine) Generator
Discriminator和Loss
由于使用多个判别器可以缓解gan训练过程中的模式崩溃问题,设计了两种类型的判别器:
1.条件图像鉴别器DI。图像粒度。目的是确保生成帧与源图像相似。空间尺度。
2.条件视频鉴别器DV。视频粒度。目的是在给定光流下,确保连续的输出帧与真实视频的时间动态相似。输入为视频序列及其光流信息。DI的条件是源图像,DV的条件是流。时间尺度。
vid2vid与pix2pixHD使用的是相同的Discriminator,即PatchGAN的Discriminator,其基本结构就是由多个卷积层构成的类似Encoder的结构,输入真实或者生成的图像,得到的是判断图像每个小区域是否真实的Score map,然后对这个Score map做Avg Pool最终得到一个Score,代表判别器对这张图像的判别结果。
Discriminator结构比较简单,但在其时间和空间尺度上使用了多种DIscriminator和loss(fake代表生成图像,real代表真实图像)。总体目标函数:

LI为条件图像鉴别器DI定义的图像上的GAN损失,LV为DV定义的连续帧上的GAN损失,LW为流量估计损失。
?LI:条件图像鉴别器DI定义的图像上的GAN损失:

DI作用是判断生成的单独一帧图像在空间分布上是否真实,其和传统conditional gan的loss比较相似,但是多了光流约束的部分,需要满足以下的一致性约束:
1. 同一个condition对应的real和生成的fake,其通过VGG提取feature的一致性约束(VGG Loss);
2.real和fake经过Discriminator判别的Discriminate loss约束(即经典GAN loss约束);
3.real和fake的Feature Matching Loss(在多个尺度Discriminator上生成的多层Feature Map的一致性)约束;
4.对当前帧生成的fake的使用真实图片的flow进行wrap,从而得到的下一帧的预测值与实际生成的下一帧fake的一致性约束;
5.对未加光流约束的fake_raw同样加上述(1~3)的一致性约束;
LV:DV定义的连续帧上的GAN损失:

判断在多个时间尺度下判断生成的视频是否真实,这里多个时间尺度就是指前后帧不同的间隔。以论文代码为例,在时间尺度1上是判别前后帧间隔为1帧的若干帧连续视频;在时间尺度2上是判别前后帧间隔为3帧的跳帧视频;时间尺度3是判别间隔为9帧的视频,以此类推。
DV的设计就是把多帧的生成图像(fake)以及他们对应的真实图片(real)的flow在channel这个维度上拼接在一起,构成一个多通道的类似feature map的Volume,然后直接使用传统PatchGan的Discriminator对其进行判别,得到的结果是0或者1(真实或者不真实),再用其计算上面的loss。
LW:光流估计损失:

为了训练Generator使其能够生成连续帧之间的光流估计值,还需要在总的Loss中加入光流估计误差,其由两部分构成
1.Generator估计的flow map和Flownet2生成的flow_refrence之间的pixel-wise误差![]() ??(本文预测值和真实值)
??(本文预测值和真实值)
2.对当前帧的真实图像(real)使用估计的flow map,经过wrap得到的下一帧图像与真实的下一帧图像之间的pixel-wise误差
![]()
(wrap后的与真实图片的误差)
对前景,背景分别建模
对于语义图转换为街景图这个任务,作者还分别对前景,背景进行建模,以加快收敛速度。具体来说,可以把语义图中的“行人”,“车辆”当做前景,“树木”,“道路”当做背景。背景通常都是不动的,因此光流计算会很准,所以得到的图像也会很清晰。设置一个mask,控制前景和背景的透明度。具体公式如下:

![]() 和
和![]() 分别代表前景和背景,
分别代表前景和背景,![]() 是背景的不透明度。
是背景的不透明度。
(根据语义图分成)
评估
Fréchet Inception 距离(FID)是一种用于评估生成模型质量的指标。(它基于真实图像和生成图像之间在特征空间中的距离,通过计算两个分布之间的统计距离来衡量生成图像与真实图像之间的相似度。FID 的计算依赖于预训练的 Inception 网络,该网络用于提取图像特征。通过比较真实图像和生成图像在 Inception 网络提取的特征空间中的分布,FID 可以提供一个衡量生成图像与真实图像之间差异程度的数值。)
本文提出一种视频评估的变体,衡量视觉质量和时间一致性。具体来说,使用一个预训练的视频识别CNN(本文使用的I3D和ResNeXt)作为特征提取器,删除最后几层。这个特征提取器是“inception”网络。对于每个视频,用这个CNN提取一个时空特征图。然后,计算所有合成视频和真实视频的 特征向量的均值μ和协方差矩阵Σ。
FID = ![]()
实验结果
实现细节。以一种时空渐进的方式训练。从生成少帧的低分辨率视频开始,一直到生成30帧的全分辨率视频。由粗到细生成器由三个尺度组成:分别是512 × 256、1024 × 512和2048 × 1024分辨率。Mask预测网络M和flow预测网络W共享除输出层之外的所有权值。使用多尺度PatchGAN鉴别器架构作为图像鉴别器DI。除了空间分辨率上的多尺度外,多尺度视频鉴别器DV还会考虑视频的不同帧率,以确保短期和长期的一致性。
ADAM优化器,训练模型40个epoch,lr = 0:0002和(β1;β2) = (0:5;0:99)。NVIDIA DGX1。使用LSGAN?loss。由于图像分辨率高,即使每批只有一个短视频,也必须使用DGX1中的所有gpu(8个V100 gpu,每个具有16GB显存)进行训练。将生成器计算任务分配给4个gpu,将鉴别器任务分配给其他4个gpu。训练2K分辨率需要10天左右。(算力要求太大了)
(如果还是基于旧的方法)?
文章在Apolloscape、City Scape以及面部动作和人体姿态数据集上都进行了测试,效果



对于单帧图像,vid2vid的效果和pix2pixHD相差不大;但在连续的视频上,由于缺少光流约束,pix2pixHD生成的结果各帧之间相关性明显非常小,色块和材质的抖动很大,而vid2vid生成的视频在时域上看起来非常平滑。
另外,Generator网络还可以扩展出一个副产物,即可以进行未来若干帧视频的预测。首先对已观测到的若干帧视频进行语义分割,得到semantic map,然后训练一个generator产生未来几帧的semantic maps,最后再使用vid2vid来通过这未来几帧的map来生成视频。文章的实验结果表明vid2vid用在视频预测上也有较好的效果。
总结:提出了一种基于条件gan的通用视频到视频合成框架。通过生成器和鉴别器,可以合成高分辨率,逼真且时间一致的视频。方案:
- 生成器加入光流约束
- 判别器加入光流信息
- 对前景、背景分别建模
局限性:例如,由于标签地图中的信息不足,模型在合成转弯车辆时遇到困难。这可以通过添加额外的3D线索(如深度图)来解决。此外,模型不能保证一个物体在整个视频中具有一致的外观。偶尔,汽车会逐渐改变颜色。如果使用对象跟踪信息来强制同一对象在整个视频中共享相同的外观,则此问题可能会得到缓解。最后,执行语义操作,例如将树变成建筑物时,偶尔会出现为建筑物,并且树木具有不同的标签形状。如果我们用更粗糙的语义标签训练模型,这个问题可能会得到解决,因为训练后的模型对标签形状不那么敏感。
问题解决及新的方向:
- 模型不能保证一个物体在整个视频中具有一致的外观:参考vid2vid-zero中的跨帧建模模块,用于保证前景和后景的时态一致性;Text2Video-Zero中的跨帧注意力机制来保留整个序列中前景对象的上下文、外观和身份,以保持生成场景和背景的一致性。
??(保证帧与帧之间的一致性,尽量不要用新方法改旧方法)
2.由于信息不足,模型在合成转弯车辆时困难:添加额外的3D线索(如深度图)。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 记Android字符串资源支持的参数类型
- Kafka-Kafka基本原理与集群快速搭建
- 【一人之下】电视剧劲爆,夏禾灵玉幽会原创剧情,网友不擦边咋火
- 仅使用 Python 创建的 Web 应用程序(前端版本)第03章Streamlit-多页面
- 代码随想录算法训练营第七天 | 344.反转字符串、541. 反转字符串II、卡码网:54.替换数字、151.翻转字符串里的单词、卡码网:55.右旋转字符串
- 服务器或服务器主板中的BIOS更新详解
- 第六章---匹配系统(下)
- 玩转 Scrapy 框架 (一):Scrapy 框架介绍及使用入门
- springboot117基于SpringBoot的企业资产管理系统
- Maven依赖冲突解决