JavaScript高级程序设计读书记录(六):定型数组,Map
1. 定型数组
定型数组(typed array)是 ECMAScript 新增的结构,目的是提升向原生库传输数据的效率。实际上,JavaScript 并没有“TypedArray”类型,它所指的其实是一种特殊的包含数值类型的数组。
1.1 历史
随着浏览器的流行,不难想象人们会满怀期待地通过它来运行复杂的 3D 应用程序。早在 2006 年,
Mozilla、Opera 等浏览器提供商就实验性地在浏览器中增加了用于渲染复杂图形应用程序的编程平台,无须安装任何插件。其目标是开发一套 JavaScript API,从而充分利用 3D 图形 API 和 GPU 加速,以便在元素上渲染复杂的图形。
1. WebGL
最后的 JavaScript API 是基于 OpenGL ES(OpenGL for Embedded Systems)2.0 规范的。OpenGL ES是 OpenGL 专注于 2D 和 3D 计算机图形的子集。这个新 API 被命名为 WebGL(Web Graphics Library),于 2011 年发布 1.0 版。有了它,开发者就能够编写涉及复杂图形的应用程序,它会被兼容 WebGL 的浏览器原生解释执行。
在 WebGL 的早期版本中,因为 JavaScript 数组与原生数组之间不匹配,所以出现了性能问题。图形
驱动程序 API 通常不需要以 JavaScript 默认双精度浮点格式传递给它们的数值,而这恰恰是JavaScript数组在内存中的格式。因此,每次 WebGL 与 JavaScript 运行时之间传递数组时,WebGL 绑定都需要在目标环境分配新数组,以其当前格式迭代数组,然后将数值转型为新数组中的适当格式,而这些要花费很多时间。
2. 定型数组
Mozilla 为解决这个问题而实现了 CanvasFloatArray。这是一个提供JavaScript 接口的、C 语言风格的浮点值数组。JavaScript 运行时使用这个类型可以分配、读取和写入数组。这个数组可以直接传给底层图形驱动程序 API,也可以直接从底层获取到。最终,CanvasFloatArray变成了 Float32Array,也就是今天定型数组中可用的第一个“类型”。
1.2 ArrayBuffer
Float32Array 实际上是一种“视图”,可以允许 JavaScript 运行时访问一块名为 ArrayBuffer 的预分配内存。ArrayBuffer 是所有定型数组及视图引用的基本单位。
注意 SharedArrayBuffer 是 ArrayBuffer 的一个变体,可以无须复制就在执行上下文间传递它。
ArrayBuffer()是一个普通的 JavaScript 构造函数,可用于在内存中分配特定数量的字节空间。
const buf = new ArrayBuffer(16); // 在内存中分配 16 字节
alert(buf.byteLength); // 16
ArrayBuffer 一经创建就不能再调整大小。不过,可以使用 slice()复制其全部或部分到一个新实例中:
const buf1 = new ArrayBuffer(16);
const buf2 = buf1.slice(4, 12);
alert(buf2.byteLength); // 8
ArrayBuffer 某种程度上类似于 C++的 malloc(),但也有几个明显的区别。
-
malloc()在分配失败时会返回一个 null 指针。ArrayBuffer 在分配失败时会抛出错误。
-
malloc()可以利用虚拟内存,因此最大可分配尺寸只受可寻址系统内存限制。ArrayBuffer分配的内存不能超过 Number.MAX_SAFE_INTEGER(2**53 - 1)字节。
-
malloc()调用成功不会初始化实际的地址。声明 ArrayBuffer 则会将所有二进制位初始化为 0。
-
通过 malloc()分配的堆内存除非调用 free()或程序退出,否则系统不能再使用。而通过声明ArrayBuffer 分配的堆内存可以被当成垃圾回收,不用手动释放。
不能仅通过对 ArrayBuffer 的引用就读取或写入其内容。要读取或写入 ArrayBuffer,就必须
通过视图。视图有不同的类型,但引用的都是 ArrayBuffer 中存储的二进制数据。
1.3 DataView
第一种允许你读写 ArrayBuffer 的视图是 DataView。这个视图专为文件 I/O 和网络 I/O 设计,其API 支持对缓冲数据的高度控制,但相比于其他类型的视图性能也差一些。DataView 对缓冲内容没有任何预设,也不能迭代。
必须在对已有的 ArrayBuffer 读取或写入时才能创建 DataView 实例。这个实例可以使用全部或部分 ArrayBuffer,且维护着对该缓冲实例的引用,以及视图在缓冲中开始的位置。
const buf = new ArrayBuffer(16);
// DataView 默认使用整个 ArrayBuffer
const fullDataView = new DataView(buf);
alert(fullDataView.byteOffset); // 0
alert(fullDataView.byteLength); // 16
alert(fullDataView.buffer === buf); // true
// 构造函数接收一个可选的字节偏移量和字节长度
// byteOffset=0 表示视图从缓冲起点开始
// byteLength=8 限制视图为前 8 个字节
const firstHalfDataView = new DataView(buf, 0, 8);
alert(firstHalfDataView.byteOffset); // 0
alert(firstHalfDataView.byteLength); // 8
alert(firstHalfDataView.buffer === buf); // true
// 如果不指定,则 DataView 会使用剩余的缓冲
// byteOffset=8 表示视图从缓冲的第 9 个字节开始
// byteLength 未指定,默认为剩余缓冲
const secondHalfDataView = new DataView(buf, 8);
alert(secondHalfDataView.byteOffset); // 8
alert(secondHalfDataView.byteLength); // 8
alert(secondHalfDataView.buffer === buf); // true
要通过 DataView 读取缓冲,还需要几个组件。
- 首先是要读或写的字节偏移量。可以看成 DataView 中的某种“地址”。
- DataView 应该使用 ElementType 来实现 JavaScript 的 Number 类型到缓冲内二进制格式的转
换。 - 最后是内存中值的字节序。默认为大端字节序。
1. ElementType
DataView 对存储在缓冲内的数据类型没有预设。它暴露的 API 强制开发者在读、写时指定一个
ElementType,然后 DataView 就会忠实地为读、写而完成相应的转换。
ECMAScript 6 支持 8 种不同的 ElementType。
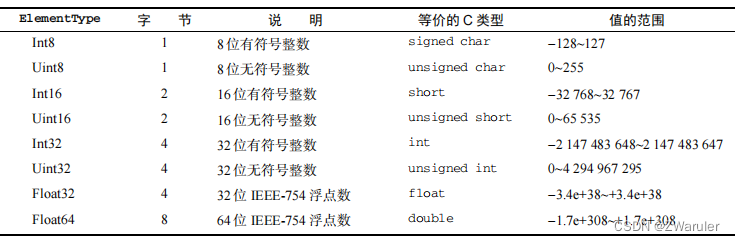
DataView 为上表中的每种类型都暴露了 get 和 set 方法,这些方法使用 byteOffset(字节偏移量)定位要读取或写入值的位置。类型是可以互换使用的,如下例所示:
// 在内存中分配两个字节并声明一个 DataView
const buf = new ArrayBuffer(2);
const view = new DataView(buf);
// 说明整个缓冲确实所有二进制位都是 0
// 检查第一个和第二个字符
alert(view.getInt8(0)); // 0
alert(view.getInt8(1)); // 0
// 检查整个缓冲
alert(view.getInt16(0)); // 0
// 将整个缓冲都设置为 1
// 255 的二进制表示是 11111111(2^8 - 1)
view.setUint8(0, 255);
// DataView 会自动将数据转换为特定的 ElementType
// 255 的十六进制表示是 0xFF
view.setUint8(1, 0xFF);
// 现在,缓冲里都是 1 了
// 如果把它当成二补数的有符号整数,则应该是-1
alert(view.getInt16(0)); // -1
2. 字节序
前面例子中的缓冲有意回避了字节序的问题。“字节序”指的是计算系统维护的一种字节顺序的约定。DataView 只支持两种约定:大端字节序和小端字节序。大端字节序也称为“网络字节序”,意思是最高有效位保存在第一个字节,而最低有效位保存在最后一个字节。小端字节序正好相反,即最低有效位保存在第一个字节,最高有效位保存在最后一个字节。
JavaScript 运行时所在系统的原生字节序决定了如何读取或写入字节,但 DataView 并不遵守这个约定。对一段内存而言,DataView 是一个中立接口,它会遵循你指定的字节序。DataView 的所有 API 方法都以大端字节序作为默认值,但接收一个可选的布尔值参数,设置为 true 即可启用小端字节序。
// 在内存中分配两个字节并声明一个 DataView
const buf = new ArrayBuffer(2);
const view = new DataView(buf);
// 填充缓冲,让第一位和最后一位都是 1
view.setUint8(0, 0x80); // 设置最左边的位等于 1
view.setUint8(1, 0x01); // 设置最右边的位等于 1
// 缓冲内容(为方便阅读,人为加了空格)
// 0x8 0x0 0x0 0x1
// 1000 0000 0000 0001
// 按大端字节序读取 Uint16
// 0x80 是高字节,0x01 是低字节
// 0x8001 = 2^15 + 2^0 = 32768 + 1 = 32769
alert(view.getUint16(0)); // 32769
// 按小端字节序读取 Uint16
// 0x01 是高字节,0x80 是低字节
// 0x0180 = 2^8 + 2^7 = 256 + 128 = 384
alert(view.getUint16(0, true)); // 384
// 按大端字节序写入 Uint16
view.setUint16(0, 0x0004);
// 缓冲内容(为方便阅读,人为加了空格)
// 0x0 0x0 0x0 0x4
// 0000 0000 0000 0100
alert(view.getUint8(0)); // 0
alert(view.getUint8(1)); // 4
// 按小端字节序写入 Uint16
view.setUint16(0, 0x0002, true);
// 缓冲内容(为方便阅读,人为加了空格)
// 0x0 0x2 0x0 0x0
// 0000 0010 0000 0000
alert(view.getUint8(0)); // 2
alert(view.getUint8(1)); // 0
3. 边界情形
DataView 完成读、写操作的前提是必须有充足的缓冲区,否则就会抛出 RangeError:
const buf = new ArrayBuffer(6);
const view = new DataView(buf);
// 尝试读取部分超出缓冲范围的值
view.getInt32(4);
// RangeError
// 尝试读取超出缓冲范围的值
view.getInt32(8);
// RangeError
// 尝试读取超出缓冲范围的值
view.getInt32(-1);
// RangeError
// 尝试写入超出缓冲范围的值
view.setInt32(4, 123);
// RangeError
DataView 在写入缓冲里会尽最大努力把一个值转换为适当的类型,后备为 0。如果无法转换,则
抛出错误:
const buf = new ArrayBuffer(1);
const view = new DataView(buf);
view.setInt8(0, 1.5);
alert(view.getInt8(0)); // 1
view.setInt8(0, [4]);
alert(view.getInt8(0)); // 4
view.setInt8(0, 'f');
alert(view.getInt8(0)); // 0
view.setInt8(0, Symbol());
// TypeError
1.4 定型数组
定型数组是另一种形式的 ArrayBuffer 视图。虽然概念上与 DataView 接近,但定型数组的区别在于,它特定于一种 ElementType 且遵循系统原生的字节序。相应地,定型数组提供了适用面更广的API 和更高的性能。设计定型数组的目的就是提高与 WebGL 等原生库交换二进制数据的效率。由于定型数组的二进制表示对操作系统而言是一种容易使用的格式,JavaScript 引擎可以重度优化算术运算、按位运算和其他对定型数组的常见操作,因此使用它们速度极快。
创建定型数组的方式包括读取已有的缓冲、使用自有缓冲、填充可迭代结构,以及填充基于任意类型的定型数组。另外,通过.from()和.of()也可以创建定型数组:
// 创建一个 12 字节的缓冲
const buf = new ArrayBuffer(12);
// 创建一个引用该缓冲的 Int32Array
const ints = new Int32Array(buf);
// 这个定型数组知道自己的每个元素需要 4 字节
// 因此长度为 3
alert(ints.length); // 3
// 创建一个长度为 6 的 Int32Array
const ints2 = new Int32Array(6);
// 每个数值使用 4 字节,因此 ArrayBuffer 是 24 字节
alert(ints2.length); // 6
// 类似 DataView,定型数组也有一个指向关联缓冲的引用
alert(ints2.buffer.byteLength); // 24
// 创建一个包含[2, 4, 6, 8]的 Int32Array
const ints3 = new Int32Array([2, 4, 6, 8]);
alert(ints3.length); // 4
alert(ints3.buffer.byteLength); // 16
alert(ints3[2]); // 6
// 通过复制 ints3 的值创建一个 Int16Array
const ints4 = new Int16Array(ints3);
// 这个新类型数组会分配自己的缓冲
// 对应索引的每个值会相应地转换为新格式
alert(ints4.length); // 4
alert(ints4.buffer.byteLength); // 8
alert(ints4[2]); // 6
// 基于普通数组来创建一个 Int16Array
const ints5 = Int16Array.from([3, 5, 7, 9]);
alert(ints5.length); // 4
alert(ints5.buffer.byteLength); // 8
alert(ints5[2]); // 7
// 基于传入的参数创建一个 Float32Array
const floats = Float32Array.of(3.14, 2.718, 1.618);
alert(floats.length); // 3
alert(floats.buffer.byteLength); // 12
alert(floats[2]); // 1.6180000305175781
定型数组的构造函数和实例都有一个 BYTES_PER_ELEMENT 属性,返回该类型数组中每个元素的大小.
如果定型数组没有用任何值初始化,则其关联的缓冲会以 0 填充.
1. 定型数组行为
从很多方面看,定型数组与普通数组都很相似。定型数组支持如下操作符、方法和属性:
- []
- copyWithin()
- entries()
- every()
- fill()
- filter()
- find()
- findIndex()
- forEach()
- indexOf()
- join()
- keys()
- lastIndexOf()
- length
- map()
- reduce()
- reduceRight()
- reverse()
- slice()
- some()
- sort()
- toLocaleString()
- toString()
- values()
其中,返回新数组的方法也会返回包含同样元素类型(element type)的新定型数组.
2. 合并、复制和修改定型数组
定型数组同样使用数组缓冲来存储数据,而数组缓冲无法调整大小。因此,下列方法不适用于定型数组:
- concat()
- pop()
- push()
- shift()
- splice()
- unshift()
不过,定型数组也提供了两个新方法,可以快速向外或向内复制数据:set()和 subarray()。
set()从提供的数组或定型数组中把值复制到当前定型数组中指定的索引位置:
// 创建长度为 8 的 int16 数组
const container = new Int16Array(8);
// 把定型数组复制为前 4 个值
// 偏移量默认为索引 0
container.set(Int8Array.of(1, 2, 3, 4));
console.log(container); // [1,2,3,4,0,0,0,0]
// 把普通数组复制为后 4 个值
// 偏移量 4 表示从索引 4 开始插入
container.set([5,6,7,8], 4);
console.log(container); // [1,2,3,4,5,6,7,8]
// 溢出会抛出错误
container.set([5,6,7,8], 7);
// RangeError
subarray()执行与 set()相反的操作,它会基于从原始定型数组中复制的值返回一个新定型数组。复制值时的开始索引和结束索引是可选的:
const source = Int16Array.of(2, 4, 6, 8);
// 把整个数组复制为一个同类型的新数组
const fullCopy = source.subarray();
console.log(fullCopy); // [2, 4, 6, 8]
// 从索引 2 开始复制数组
const halfCopy = source.subarray(2);
console.log(halfCopy); // [6, 8]
// 从索引 1 开始复制到索引 3
const partialCopy = source.subarray(1, 3);
console.log(partialCopy); // [4, 6]
定型数组没有原生的拼接能力,但使用定型数组 API 提供的很多工具可以手动构建:
// 第一个参数是应该返回的数组类型
// 其余参数是应该拼接在一起的定型数组
function typedArrayConcat(typedArrayConstructor, ...typedArrays) {
// 计算所有数组中包含的元素总数
const numElements = typedArrays.reduce((x,y) => (x.length || x) + y.length);
// 按照提供的类型创建一个数组,为所有元素留出空间
const resultArray = new typedArrayConstructor(numElements);
// 依次转移数组
let currentOffset = 0;
typedArrays.map(x => {
resultArray.set(x, currentOffset);
currentOffset += x.length;
});
return resultArray;
}
const concatArray = typedArrayConcat(Int32Array,
Int8Array.of(1, 2, 3),
Int16Array.of(4, 5, 6),
Float32Array.of(7, 8, 9));
console.log(concatArray); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
console.log(concatArray instanceof Int32Array); // true
3. 下溢和上溢
定型数组中值的下溢和上溢不会影响到其他索引,但仍然需要考虑数组的元素应该是什么类型。定型数组对于可以存储的每个索引只接受一个相关位,而不考虑它们对实际数值的影响。以下代码演示了
如何处理下溢和上溢:
// 长度为 2 的有符号整数数组
// 每个索引保存一个二补数形式的有符号整数
// 范围是-128(-1 * 2^7)~127(2^7 - 1)
const ints = new Int8Array(2);
// 长度为 2 的无符号整数数组
// 每个索引保存一个无符号整数
// 范围是 0~255(2^7 - 1)
const unsignedInts = new Uint8Array(2);
// 上溢的位不会影响相邻索引
// 索引只取最低有效位上的 8 位
unsignedInts[1] = 256; // 0x100
console.log(unsignedInts); // [0, 0]
unsignedInts[1] = 511; // 0x1FF
console.log(unsignedInts); // [0, 255]
// 下溢的位会被转换为其无符号的等价值
// 0xFF 是以二补数形式表示的-1(截取到 8 位),
// 但 255 是一个无符号整数
unsignedInts[1] = -1 // 0xFF (truncated to 8 bits)
console.log(unsignedInts); // [0, 255]
// 上溢自动变成二补数形式
// 0x80 是无符号整数的 128,是二补数形式的-128
ints[1] = 128; // 0x80
console.log(ints); // [0, -128]
// 下溢自动变成二补数形式
// 0xFF 是无符号整数的 255,是二补数形式的-1
ints[1] = 255; // 0xFF
console.log(ints); // [0, -1]
除了 8 种元素类型,还有一种“夹板”数组类型:Uint8ClampedArray,不允许任何方向溢出。超出最大值 255 的值会被向下舍入为 255,而小于最小值 0 的值会被向上舍入为 0。
按照 JavaScript 之父 Brendan Eich 的说法:“Uint8ClampedArray 完全是 HTML5canvas 元素的历史留存。除非真的做跟 canvas 相关的开发,否则不要使用它。
2. Map
ECMAScript 6 以前,在 JavaScript 中实现“键/值”式存储可以使用 Object 来方便高效地完成,也就是使用对象属性作为键,再使用属性来引用值。但这种实现并非没有问题,为此 TC39 委员会专门为“键/值”存储定义了一个规范。
作为 ECMAScript 6 的新增特性,Map 是一种新的集合类型,为这门语言带来了真正的键/值存储机制。Map 的大多数特性都可以通过 Object 类型实现,但二者之间还是存在一些细微的差异。具体实践中使用哪一个,还是值得细细甄别。
2.1 基本 API
使用 new 关键字和 Map 构造函数可以创建一个空映射:
const m = new Map();
如果想在创建的同时初始化实例,可以给 Map 构造函数传入一个可迭代对象,需要包含键/值对数组。可迭代对象中的每个键/值对都会按照迭代顺序插入到新映射实例中:
// 使用嵌套数组初始化映射
const m1 = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
alert(m1.size); // 3
// 使用自定义迭代器初始化映射
const m2 = new Map({
[Symbol.iterator]: function*() {
yield ["key1", "val1"];
yield ["key2", "val2"];
yield ["key3", "val3"];
}
});
alert(m2.size); // 3
// 映射期待的键/值对,无论是否提供
const m3 = new Map([[]]);
alert(m3.has(undefined)); // true
alert(m3.get(undefined)); // undefined
初始化之后,可以使用 set()方法再添加键/值对。另外,可以使用 get()和 has()进行查询,可以通过 size 属性获取映射中的键/值对的数量,还可以使用 delete()和 clear()删除值。
const m = new Map();
alert(m.has("firstName")); // false
alert(m.get("firstName")); // undefined
alert(m.size); // 0
m.set("firstName", "Matt")
.set("lastName", "Frisbie");
alert(m.has("firstName")); // true
alert(m.get("firstName")); // Matt
alert(m.size); // 2
m.delete("firstName"); // 只删除这一个键/值对
alert(m.has("firstName")); // false
alert(m.has("lastName")); // true
alert(m.size); // 1
m.clear(); // 清除这个映射实例中的所有键/值对
alert(m.has("firstName")); // false
alert(m.has("lastName")); // false
alert(m.size); // 0
set()方法返回映射实例,因此可以把多个操作连缀起来,包括初始化声明:
const m = new Map().set("key1", "val1");
m.set("key2", "val2")
.set("key3", "val3");
alert(m.size); // 3
与 Object 只能使用数值、字符串或符号作为键不同,Map 可以使用任何 JavaScript 数据类型作为键。Map 内部使用 SameValueZero 比较操作(ECMAScript 规范内部定义,语言中不能使用),基本上相当于使用严格对象相等的标准来检查键的匹配性。与 Object 类似,映射的值是没有限制的。
const m = new Map();
const functionKey = function() {};
const symbolKey = Symbol();
const objectKey = new Object();
m.set(functionKey, "functionValue");
m.set(symbolKey, "symbolValue");
m.set(objectKey, "objectValue");
alert(m.get(functionKey)); // functionValue
alert(m.get(symbolKey)); // symbolValue
alert(m.get(objectKey)); // objectValue
// SameValueZero 比较意味着独立实例不冲突
alert(m.get(function() {})); // undefined
与严格相等一样,在映射中用作键和值的对象及其他“集合”类型,在自己的内容或属性被修改时仍然保持不变:
const m = new Map();
const objKey = {},
objVal = {},
arrKey = [],
arrVal = [];
m.set(objKey, objVal);
m.set(arrKey, arrVal);
objKey.foo = "foo";
objVal.bar = "bar";
arrKey.push("foo");
arrVal.push("bar");
console.log(m.get(objKey)); // {bar: "bar"}
console.log(m.get(arrKey)); // ["bar"]
SameValueZero 比较也可能导致意想不到的冲突:
const m = new Map();
const a = 0/"", // NaN
b = 0/"", // NaN
pz = +0,
nz = -0;
alert(a === b); // false
alert(pz === nz); // true
m.set(a, "foo");
m.set(pz, "bar");
alert(m.get(b)); // foo
alert(m.get(nz)); // bar
2.2 顺序与迭代
与 Object 类型的一个主要差异是,Map 实例会维护键值对的插入顺序,因此可以根据插入顺序执行迭代操作。
映射实例可以提供一个迭代器(Iterator),能以插入顺序生成[key, value]形式的数组。可以通过 entries()方法(或者 Symbol.iterator 属性,它引用 entries())取得这个迭代器:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
alert(m.entries === m[Symbol.iterator]); // true
for (let pair of m.entries()) {
alert(pair);
}
// [key1,val1]
// [key2,val2]
// [key3,val3]
for (let pair of m[Symbol.iterator]()) {
alert(pair);
}
// [key1,val1]
// [key2,val2]
// [key3,val3]
因为 entries()是默认迭代器,所以可以直接对映射实例使用扩展操作,把映射转换为数组:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
console.log([...m]); // [[key1,val1],[key2,val2],[key3,val3]]
如果不使用迭代器,而是使用回调方式,则可以调用映射的 forEach(callback, opt_thisArg)方法并传入回调,依次迭代每个键/值对。传入的回调接收可选的第二个参数,这个参数用于重写回调内部 this 的值:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
m.forEach((val, key) => alert(`${key} -> ${val}`));
// key1 -> val1
// key2 -> val2
// key3 -> val3
keys()和 values()分别返回以插入顺序生成键和值的迭代器:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
]);
for (let key of m.keys()) {
alert(key);
}
// key1
// key2
// key3
for (let key of m.values()) {
alert(key);
}
// value1
// value2
// value3
键和值在迭代器遍历时是可以修改的,但映射内部的引用则无法修改。当然,这并不妨碍修改作为键或值的对象内部的属性,因为这样并不影响它们在映射实例中的身份:
const m1 = new Map([
["key1", "val1"]
]);
// 作为键的字符串原始值是不能修改的
for (let key of m1.keys()) {
key = "newKey";
alert(key); // newKey
alert(m1.get("key1")); // val1
}
const keyObj = {id: 1};
const m = new Map([
[keyObj, "val1"]
]);
// 修改了作为键的对象的属性,但对象在映射内部仍然引用相同的值
for (let key of m.keys()) {
key.id = "newKey";
alert(key); // {id: "newKey"}
alert(m.get(keyObj)); // val1
}
alert(keyObj); // {id: "newKey"}
2.3 选择 Object 还是 Map
对于多数 Web 开发任务来说,选择 Object 还是 Map 只是个人偏好问题,影响不大。不过,对于在乎内存和性能的开发者来说,对象和映射之间确实存在显著的差别。
1. 内存占用
Object 和 Map 的工程级实现在不同浏览器间存在明显差异,但存储单个键/值对所占用的内存数量都会随键的数量线性增加。批量添加或删除键/值对则取决于各浏览器对该类型内存分配的工程实现。不同浏览器的情况不同,但给定固定大小的内存,Map 大约可以比 Object 多存储 50%的键/值对。
2. 插入性能
向 Object 和 Map 中插入新键/值对的消耗大致相当,不过插入 Map 在所有浏览器中一般会稍微快一点儿。对这两个类型来说,插入速度并不会随着键/值对数量而线性增加。如果代码涉及大量插入操作,那么显然 Map 的性能更佳。
3. 查找速度
与插入不同,从大型 Object 和 Map 中查找键/值对的性能差异极小,但如果只包含少量键/值对,则 Object 有时候速度更快。在把 Object 当成数组使用的情况下(比如使用连续整数作为属性),浏览器引擎可以进行优化,在内存中使用更高效的布局。这对 Map 来说是不可能的。对这两个类型而言,
查找速度不会随着键/值对数量增加而线性增加。如果代码涉及大量查找操作,那么某些情况下可能选
择 Object 更好一些。
4. 删除性能
使用 delete 删除 Object 属性的性能一直以来饱受诟病,目前在很多浏览器中仍然如此。为此,出现了一些伪删除对象属性的操作,包括把属性值设置为 undefined 或 null。但很多时候,这都是一种讨厌的或不适宜的折中。而对大多数浏览器引擎来说,Map 的 delete()操作都比插入和查找更快。如果代码涉及大量删除操作,那么毫无疑问应该选择 Map。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 什么是数据结构?数据结构的基本概念
- .net core webapi 自定义异常过滤器
- hive聚合函数之排序
- LeetCode 279完全平方数 139单词拆分 卡码网 56携带矿石资源(多重背包) | 代码随想录25期训练营day45
- ImageIO类的使用
- 大数据毕设分享 flink大数据淘宝用户行为数据实时分析与可视化
- 深入理解AbstractQueuedSynchronizer(AQS)
- Python BPA点云重建(Ball-Pivoting Algorithm)
- 阿里云PAI部署GLM3,访问403
- 智能高效|AIRIOT智慧货运管理解决方案