Redis分布式缓存主从同步原理解析
目录
Redis主从同步的方式
????????1.全量同步

上图就是全量同步的一个流程图
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
????????首先在slave(从节点)连接master(主节点)时,从节点会给主节点发送两个参数(replid,offset),主节点会拿着自己的replid来与从节点发送过来的replid进行是否一致的判断,如果是不一致就认为是第一次进行连接,然后master把自己的replid和offset返回给slave,slave(从节点)接收到master(主节点)的replid和offset之后会在slave(从节点)进行一个保存。
????????之后master会执行bgsave来生成RDB文件,bgsave是开启一个子线程在后台进行将数据写入到磁盘中。在生成RDB文件期间,为了防止数据不同步,所有master会将期间执行的命令在repl_baklog中进行记录。master生成RDB文件后会发送给slave中,slave会先将自己的本地数据全部清空之后再加载从master分支发送来的RDB文件。
????????第三阶段就是master把repl_baklog中记录的命令发送给slave来让slave执行,这样来完成主从数据的同步
????????2.增量同步

????????假设slave分支重启了,重启成功后会拿着自己的replid和offset发送给master分支来判断replid是否一致,因为我们现在是第二次连接,所有replid是一致的,如果一致,master会认为不是第一次连接并返回给slave一句continue
????????master会拿着slave发送过来offset的值去repl_baklog来找到对应的位置,然后获取在offset值之后的数据并将这些命令发送给slave来执行,这就是增量实现主从同步
注意
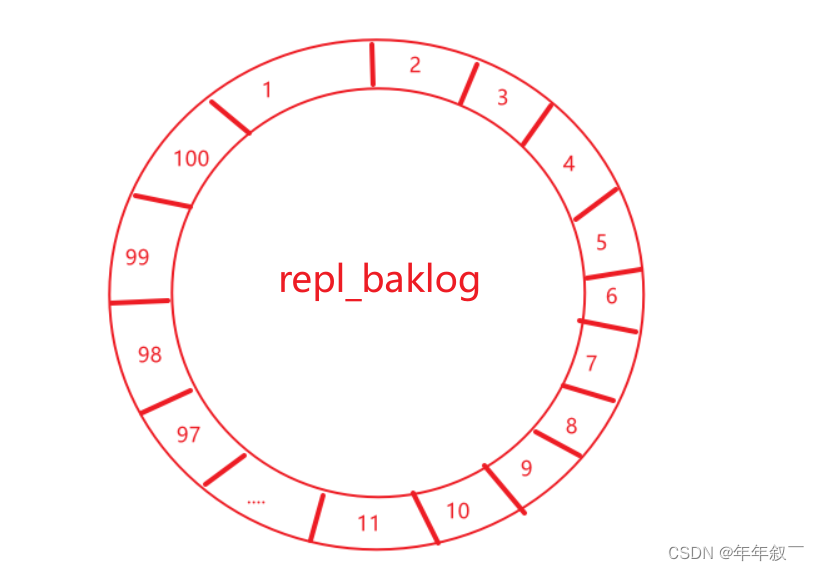
????????假设repl_baklog的长度是100(它的长度取决于设置),而slave宕机了10秒钟,slave存储的offset为“8”。在这8秒钟的时间master会将期间执行的命令记录在repl_baklog中,记录的顺序就是从8开始往下进行记录。
????????repl_baklog的形状是一个环形的,如果说在slave宕机的这段时间里,master记录的命令并没有到“8”的位置,那么slave再次连接的时候就会进行增量同步,当然还有另外一种可能,当master在repl_baklog中记录到了“100”的位置,slave还没有上线,那么master会继续往下记录并把之后的记录进行覆盖,把“1”覆盖为101,当把slave中记录的offset值也覆盖了之后,这时slave上线了,slave会发送给master两个参数replid和offset。
????????因为不是第一次连接,所以replid是一致的,master会拿着slave的offset去repl_baklog中取offset之后的命令,但是master记录的命令已经把offset的值进行了覆盖,所以master找不到对应的offset值,这时候会进行全量同步。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Keil编译STM32工程,提示__align(4)处语法错误
- 搜索引擎优化指南:SEO关键字、长尾关键字、短尾关键字以及反向链接
- .NET Framework 对应系统版本汇总
- Linux第11步_解决“挂载后的U盘出现中文乱码”
- Redis6.0 Client-Side缓存是什么
- 锁,原子操作,共享内存,CPU亲缘性总结
- 课堂纪律差如何整治
- 后视摄像头,预计2028年复合年增长率为16.2%
- 深入理解HTTP状态码
- 【Java基础】HashMap 原理