线性回归的简洁实现
发布时间:2024年01月19日
1、生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)2、读取数据集
def load_array(data_arrays, batch_size, is_train=True):
# 布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
next(iter(data_iter))结果:

3、定义模型
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))4、初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
#均值为 0,标准差为 0.015、定义损失函数
loss = nn.MSELoss()6、定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03)7、训练
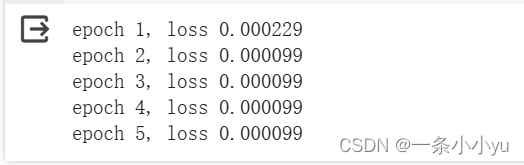
num_epochs = 5
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')结果:
来源李沐老师,仅供学习
文章来源:https://blog.csdn.net/m0_61949623/article/details/135695600
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!