实现分布式锁
背景
分布式锁是一种用于协调分布式系统中多个节点之间并发访问共享资源的机制。在分布式系统中,由于存在多个节点同时访问共享资源的可能性,需要使用分布式锁来保证数据的一致性和正确性。
今天要实现的是分布式场景中的互斥类型的锁。
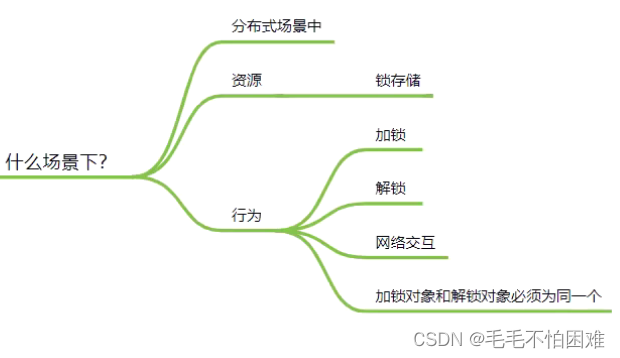
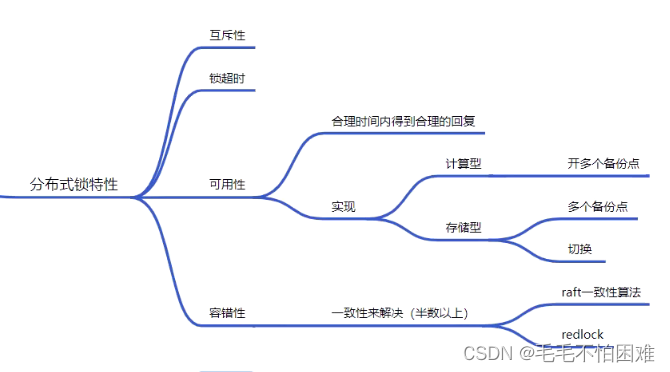
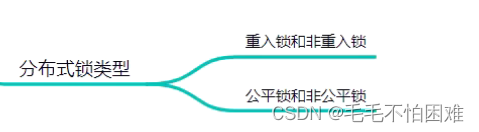
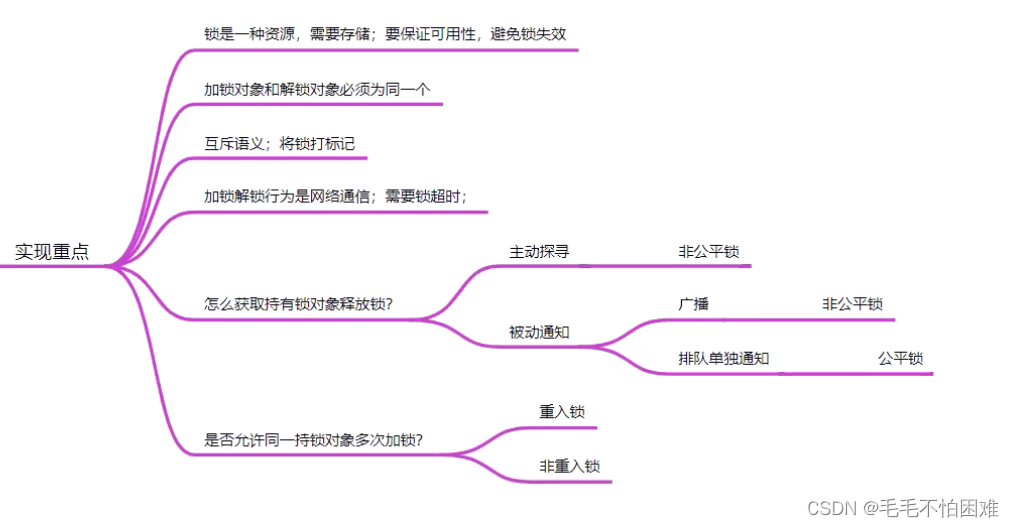
下面时分布式锁的实现重点
借助MySQL实现
主要利用MySQL唯一键和唯一性约束来实现互斥性
表结构
DROP TABLE IF EXISTS `dislock`;
CREATE TABLE `dislock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`lock_type` varchar(64) NOT NULL COMMENT '锁类型',
`owner_id` varchar(255) NOT NULL COMMENT '持锁对象',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_lock_type` (`lock_type`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='分布式锁表';
创建一个名为dislock的表,用于存储分布式锁的信息。该表包含以下字段:
id:主键,自增长的整数类型。lock_type:锁类型,字符串类型,用于标识锁的类型。owner_id:持锁对象,字符串类型,用于标识持有锁的客户端或其他相关信息。update_time:更新时间,时间戳类型,表示最后一次更新该行数据的时间。
在上面的SQL语句中,idx_lock_type是一个唯一索引,它定义在lock_type字段上,确保表中不会有两个相同的lock_type值。这样可以保证同一类型的锁在表中只有一条记录,避免了同一客户端重复获取锁的情况。
加锁和解锁
INSERT INTO dislock (`lock_type`, `owner_id`) VALUES ('act_lock', 'ad2daf3');
DELETE FROM dislock WHERE `lock_type` = 'act_lock' AND `owner_id` = 'ad2daf3'; // 要确保谁加锁谁解锁
如果要用MySQL实现的话,**还需要开一个进程(要求计算型高可用),来管理超时,**不断去查询updatetime,如果该锁超过了最长允许存在的时间,则需要删除数据库对应的该行。
如果要实现可重入的话,那么考虑再增加一个数据库字段来实现。
借助Redis实现
在Redis中,可以使用SET命令来实现分布式锁。具体实现方法如下:
-
使用
SET命令尝试在Redis中设置一个键,例如lock:resource,并将其值设置为一个唯一的标识符,例如当前进程的ID或一个随机字符串。可以使用NX选项来确保只有在该键不存在时才进行设置,从而实现加锁操作。 -
如果
SET命令返回了OK,则说明该键被成功设置,当前进程获得了锁;否则,说明该键已经被其他进程持有,当前进程没有获得锁,需要等待一段时间后重试。 -
在完成操作后,使用
DEL命令删除该键,释放锁。
需要注意的是,在使用SET命令设置键的值时,应该设置一个过期时间,以防止锁被持有进程意外终止而无法释放。可以使用EX选项来设置过期时间,例如SET lock:resource <identifier> EX 10表示将锁的过期时间设置为10秒。
另外,为了避免锁的误删除,应该使用与设置键的标识符不同的值来删除锁。可以使用Lua脚本来实现原子性的加锁和解锁操作,从而避免并发问题。例如,下面是一个简单的Lua脚本,实现了基本的加锁和解锁操作:
-- 加锁操作
if redis.call('SET', KEYS[1], ARGV[1], 'EX', ARGV[2], 'NX') then
return 1
else
return 0
end
-- 解锁操作
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
end
我们今天主要考虑下面的方法
当使用 Redis 的 Redlock 算法时,需要考虑以下关键步骤和注意事项:
-
选择 N 个 Redis 实例:
- 选择的 Redis 实例应该分布在不同的物理服务器或者逻辑节点上,以确保它们不会受到单点故障的影响。
- 这些实例可以是独立的 Redis 节点,也可以是 Redis 集群中的节点。
-
获取当前时间:
- 在进行锁操作之前,首先需要获取一个精确的当前时间戳。这可以通过系统时间或者某种网络时间协议(如NTP)来获得。
-
尝试在每个实例上获取锁:
- 对于每个选定的 Redis 实例,使用相同的锁键和唯一的随机值(例如 UUID)执行 SET 操作,并设置适当的超时时间和标识符,以确保只有持有锁的客户端才能释放锁。
- 设置锁的超时时间是为了避免锁被永久性地持有,即使持有锁的客户端出现故障。
-
计算获取锁所需的时间:
- 计算获取锁所需的时间,主要包括获取锁的时间、网络延迟以及时钟漂移等。这些因素都会影响锁的有效性。
-
判断是否成功获取锁:
- 如果大多数实例(至少超过半数)成功获取了锁,并且用于获取锁的时间没有超过超时时间,则认为获取锁成功。
- 如果无法获得大多数实例的支持,可能需要重试或者放弃锁操作。
-
释放锁:
- 在完成任务后,需要在所有实例上执行删除操作来释放锁。
注意事项
- 网络分区:在面对网络分区时,需要考虑如何处理部分 Redis 实例无法通信的情况。这可能需要引入额外的逻辑来检测并处理这种情况。
- 时钟漂移:由于不同的服务器上的时钟可能存在不同程度的漂移,需要谨慎处理时钟同步问题,以确保锁的超时时间计算准确。
- Redis 实例故障:需要考虑 Redis 实例的故障处理,包括如何发现故障实例并采取适当的措施。
总之,实现 Redlock 算法需要综合考虑各种因素,并根据具体情况进行调整,以确保系统在分布式环境下能够正确、高效地运行。
代码实现参考:
链接: https://github.com/jacket-code/redlock-cpp
其他的方法未完待续,后续补充
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【IntelliJ IDEA】打开项目Git突然无法识别解决方案
- 关于git
- 经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现
- win桌面图标间距变大如何调整
- 层次聚类与密度聚类代码实现
- 防御课程—华为USG6000V1的配置实验(一)
- [学习笔记]刘知远团队大模型技术与交叉应用L1-NLP&Big Model Basics
- uni-app 前后端调用实例 基于Springboot 详情页实现
- C_6练习题答案
- 【Java SE】基础知识回顾——【12.异常 | 线程】