超级干货 | 从神经元到CNN、RNN、GAN…神经网络看本文绝对够了
在深度学习十分火热的今天,不时会涌现出各种新型的人工神经网络,想要实时了解这些新型神经网络的架构还真是不容易。光是知道各式各样的神经网络模型缩写(如:DCIGN、BiLSTM、DCGAN……还有哪些?),就已经让人招架不住了。
因此,这里整理出一份清单来梳理所有这些架构。其中大部分是人工神经网络,也有一些完全不同的怪物。尽管所有这些架构都各不相同、功能独特,当我在画它们的节点图时……其中潜在的关系开始逐渐清晰起来。

把这些架构做成节点图,会存在一个问题:它无法展示神经网络架构内部的工作原理。举例来说,变分自编码机(VAE:variational autoencoders )看起来跟自编码机(AE:autoencoders)差不多,但它们的训练过程却大不相同。训练后的模型在使用场景上差别更大:VAE是生成器,通过插入噪音数据来获取新样本;而AE仅仅是把他们所收到的任何信息作为输入,映射到“记忆中”最相似的训练样本上。
在介绍不同模型的神经元和神经细胞层之间的连接方式前,我们一步一步来,先来了解不同的神经元节点内部是如何工作的。
神经元
对不同类型的神经元标记不同的颜色,可以更好地在各种网络架构之间进行区分。但是,这些神经元的工作方式却是大同小异。在下图的基本神经元结构后面,你会看到详细的讲解:

基本的人工神经网络神经元(basic neural network cell)相当简单,这种简单的类型可以在常规的前馈人工神经网络架构里面找到。这种神经元与其它神经元之间的连接具有权重,也就是说,它可以和前一层神经网络层中的所有神经元有连接。
每一个连接都有各自的权重,通常情况下是一些随机值(关于如何对人工神经网络的权重进行初始化是一个非常重要的话题,这将会直接影响到之后的训练过程,以及最终整个模型的性能)。这个权重可以是负值,正值,非常小,或者非常大,也可以是零。和这个神经元连接的所有神经元的值都会乘以各自对应的权重。然后,把这些值都求和。
在这个基础上,会额外加上一个bias,它可以用来避免输出为零的情况,并且能够加速某些操作,这让解决某个问题所需要的神经元数量也有所减少。这个bias也是一个数字,有些时候是一个常量(经常是-1或者1),有些时候会有所变化。这个总和最终被输入到一个激活函数,这个激活函数的输出最终就成为这个神经元的输出。

卷积神经元(Convolutional cells)和前馈神经元非常相似,除了它们只跟前一神经细胞层的部分神经元有连接。因为它们不是和某些神经元随机连接的,而是与特定范围内的神经元相连接,通常用来保存空间信息。这让它们对于那些拥有大量局部信息,比如图像数据、语音数据(但多数情况下是图像数据),会非常实用。
解卷积神经元恰好相反:它们是通过跟下一神经细胞层的连接来解码空间信息。这两种神经元都有很多副本,它们都是独立训练的;每个副本都有自己的权重,但连接方式却完全相同。可以认为,这些副本是被放在了具备相同结构的不同的神经网络中。这两种神经元本质上都是一般意义上的神经元,但是,它们的使用方式却不同。
池化神经元和插值神经元(Pooling and interpolating cells)经常和卷积神经元结合起来使用。它们不是真正意义上的神经元,只能进行一些简单的操作。
池化神经元接受到来自其它神经元的输出过后,决定哪些值可以通过,哪些值不能通过。在图像领域,可以理解成是把一个图像缩小了(在查看图片的时候,一般软件都有一个放大、缩小的功能;这里的图像缩小,就相当于软件上的缩小图像;也就是说我们能看到图像的内容更加少了;在这个池化的过程当中,图像的大小也会相应地减少)。这样,你就再也不能看到所有的像素了,池化函数会知道什么像素该保留,什么像素该舍弃。
插值神经元恰好是相反的操作:它们获取一些信息,然后映射出更多的信息。额外的信息都是按照某种方式制造出来的,这就好像在一张小分辨率的图片上面进行放大。插值神经元不仅仅是池化神经元的反向操作,而且,它们也是很常见,因为它们运行非常快,同时,实现起来也很简单。池化神经元和插值神经元之间的关系,就像卷积神经元和解卷积神经元之间的关系。
均值神经元和标准方差神经元(Mean and standard deviation cells)(作为概率神经元它们总是成对地出现)是一类用来描述数据概率分布的神经元。均值就是所有值的平均值,而标准方差描述的是这些数据偏离(两个方向)均值有多远。比如:一个用于图像处理的概率神经元可以包含一些信息,比如:在某个特定的像素里面有多少红色。举个例来说,均值可能是0.5,同时标准方差是0.2。当要从这些概率神经元取样的时候,你可以把这些值输入到一个高斯随机数生成器,这样就会生成一些分布在0.4和0.6之间的值;值离0.5越远,对应生成的概率也就越小。它们一般和前一神经元层或者下一神经元层是全连接,而且,它们没有偏差(bias)。

循环神经元(Recurrent cells?)不仅仅在神经细胞层之间有连接,而且在时间轴上也有相应的连接。每一个神经元内部都会保存它先前的值。它们跟一般的神经元一样更新,但是,具有额外的权重:与当前神经元之前值之间的权重,还有大多数情况下,与同一神经细胞层各个神经元之间的权重。当前值和存储的先前值之间权重的工作机制,与非永久性存储器(比如RAM)的工作机制很相似,继承了两个性质:
第一,维持一个特定的状态;
第二:如果不对其持续进行更新(输入),这个状态就会消失。
由于先前的值是通过激活函数得到的,而在每一次的更新时,都会把这个值和其它权重一起输入到激活函数,因此,信息会不断地流失。实际上,信息的保存率非常的低,以至于仅仅四次或者五次迭代更新过后,几乎之前所有的信息都会流失掉。
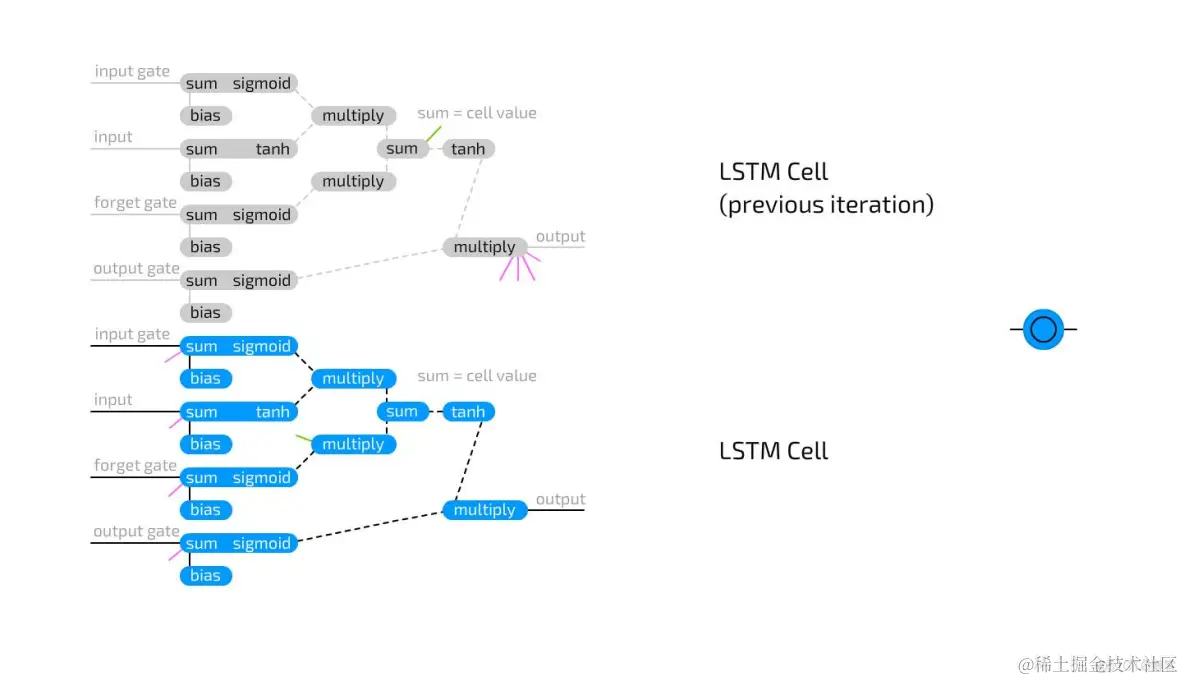
长短期记忆神经元(Long short term memory cells)用于克服循环神经元中信息快速流失的问题。
LSTM是一个逻辑回路,其设计受到了计算机内存单元设计的启发。与只存储两个状态的循环神经元相比,LSTM可以存储四个状态:输出值的当前和先前值,记忆神经元状态的当前值和先前值。它们都有三个门:输入门,输出门,遗忘门,同时,它们也还有常规的输入。
这些门它们都有各自的权重,也就是说,与这种类型的神经元细胞连接需要设置四个权重(而不是一个)。这些门的工作机制与流门(flow gates)很相似,而不是栅栏门(fence gates):它们可以让所有的信息都通过,或者只是通过部分,也可以什么都不让通过,或者通过某个区间的信息。
这种运行机制的实现是通过把输入信息和一个在0到1之间的系数相乘,这个系数存储在当前门中。这样,输入门决定输入的信息有多少可以被叠加到当前门值。输出门决定有多少输出信息是可以传递到后面的神经网络中。遗忘门并不是和输出神经元的先前值相连接,而是,和前一记忆神经元相连接。它决定了保留多少记忆神经元最新的状态信息。因为没有和输出相连接,以及没有激活函数在这个循环中,因此只会有更少的信息流失。
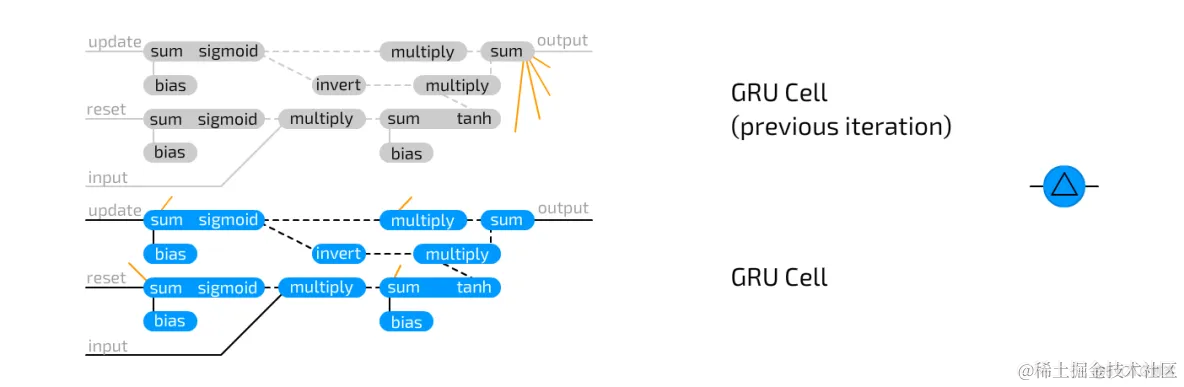
门控循环神经元(Gated recurrent units (cells))是LSTM的变体。它们同样使用门来抑制信息的流失,但是只用两个门:更新门和重置门。这使得构建它们付出的代价没有那么高,而且运行速度更加快了,因为它们在所有的地方使用了更少的连接。
从本质上来说LSTM和GRU有两个不同的地方:
第一:GRU神经元没有被输出门保护的隐神经元;
第二:GRU把输出门和遗忘门整合在了一起,形成了更新门。核心的思想就是如果你想要一些新的信息,那么你就可以遗忘掉一些陈旧的信息(反过来也可以)。
神经细胞层(Layers)
形成一个神经网络,最简单的连接神经元方式是——把所有的神经元与其它所有的神经元相连接。这就好像Hopfield神经网络和玻尔兹曼机(Boltzmann machines)的连接方式。当然,这也就意味着连接数量会随着神经元个数的增加呈指数级地增加,但是,对应的函数表达力也会越来越强。这就是所谓的全连接(completely (or fully) connected)。
经历了一段时间的发展,发现把神经网络分解成不同的神经细胞层会非常有效。神经细胞层的定义是一群彼此之间互不连接的神经元,它们仅跟其它神经细胞层有连接。这一概念在受限玻尔兹曼机(Restricted Boltzmann Machines)中有所体现。现在,使用神经网络就意味着使用神经细胞层,并且是任意数量的神经细胞层。其中一个比较令人困惑的概念是全连接(fully connected or completely connected),也就是某一层的每个神经元跟另一层的所有神经元都有连接,但真正的全连接神经网络相当罕见。
卷积连接层(Convolutionally connected layers)相对于全连接层要有更多的限制:在卷积连接层中的每一个神经元只与相邻的神经元层连接。图像和声音蕴含了大量的信息,如果一对一地输入到神经网络(比如,一个神经元对应一个像素)。卷积连接的形成,受益于保留空间信息更为重要的观察。实践证明这是一个非常好的猜测,因为现在大多数基于人工神经网络的图像和语音应用都使用了这种连接方式。然而,这种连接方式所需的代价远远低于全连接层的形式。从本质上来讲,卷积连接方式起到重要性过滤的作用,决定哪些紧紧联系在一起的信息包是重要的;卷积连接对于数据降维非常有用。
当然了,还有另外一种选择,就是随机连接神经元(randomly connected neurons)。这种形式的连接主要有两种变体:
第一,允许部分神经元进行全连接。
第二,神经元层之间只有部分连接。
随机连接方式有助于线性地降低人工神经网络的性能;当全连接层遇到性能问题的时候,在大规模人工神经网络中,使用随机连接方式非常有益。拥有更多神经元且更加稀疏的神经元层在某些情况下运行效果更好,特别是很多的信息需要被存储起来,但是,需要交换的信息并不多(这与卷积连接层的运行机制很相似,但是,它们是随机的)。非常稀疏的连接网络(1%或2%)也有被使用,比如ELMs, ESNs?和LSMs。这特别适用于脉冲网络(spiking networks),因为一个神经元拥有更多的连接,它对应的权重具有的能量也就更少,这也就意味着将会有更少的扩展和重复模式。
时间滞后连接(Time delayed connections)是指相连的神经元(通常是在同一个神经元层,甚至于一个神经元自己跟自己连接),它们不从前面的神经元层获取信息,而是从神经元层先前的状态获取信息。这使得暂时(时间上或者序列上)联系在一起的信息可以被存储起来。这些形式的连接经常被手工重新进行设置,从而可以清除神经网络的状态。和常规连接的主要区别是,这种连接会持续不断地改变,即便这个神经网络当前没有处于训练状态。
下图展示了以上所介绍的神经网络及其连接方式。当我卡在哪种神经元与哪个神经细胞层该连到一起的时候,就会拿这张图出来作为参考(尤其是在处理和分析LSTM与GRU神经元时):
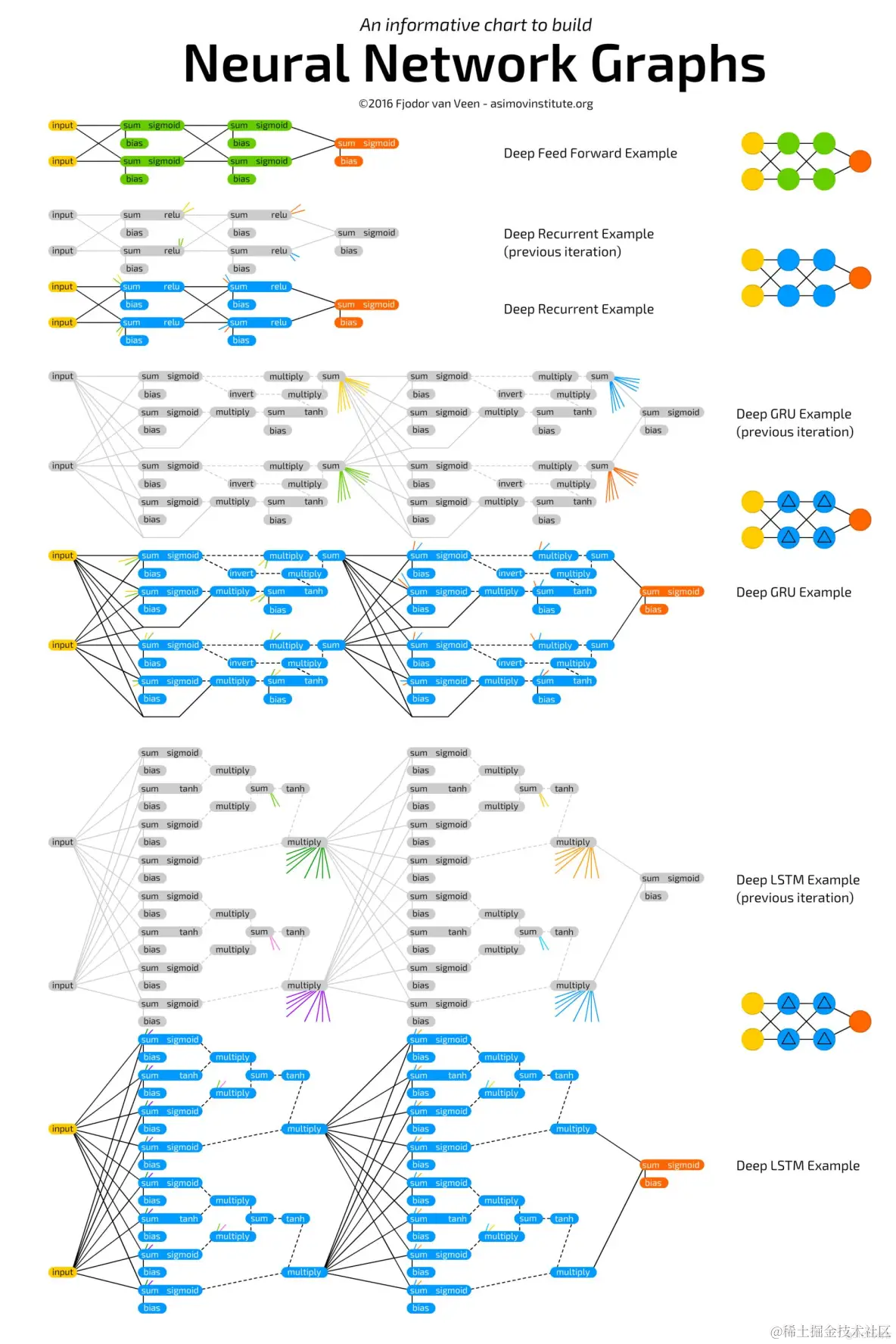
显而易见,整理一份完整的清单是不切实际的,因为新的架构正被源源不断地发明出来。所以,接下来这份清单的目的,只想带你一窥人工智能领域的基础设施。对于每一个画成节点图的架构,我都会写一个非常非常简短的描述。你会发现这些描述还是很有用的,毕竟,总还是有一些你并不是那么熟悉的架构。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 蓝鹏测控提前祝您2024元旦快乐!心想事成!
- K8S---NetworkPolicy
- 算法基础之计数问题
- [C#]winform部署openvino调用padleocr模型
- 使用flet创建todo应用
- c语言之打印素数
- 初阶:第三部分Python函数的知识框架思维导图
- LeetCode每周五题_2024/01/01~2024/01/05
- 火焰识别摄像机
- Serverless和Spring cloud结合让后端开发更专注于业务