工具系列:TensorFlow决策森林_(2)排序学习Learning to Rank
欢迎来到 TensorFlow决策森林( TF-DF)的 学习排序Learning to Rank。
在本文中,您将学习如何使用 TF-DF进行排序。
在文本中,您将会:
- 学习什么是排序模型。
- 在LETOR3数据集上训练梯度提升树模型。
- 评估该模型的质量。
安装 TensorFlow Decision Forests
通过运行以下单元格来安装 TF-DF。
# 安装tensorflow_decision_forests库
!pip install tensorflow_decision_forests
Collecting tensorflow_decision_forests
Using cached tensorflow_decision_forests-1.2.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (16.5 MB)
Collecting tensorflow~=2.11.0
Using cached tensorflow-2.11.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (588.3 MB)
Requirement already satisfied: six in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.16.0)
Requirement already satisfied: numpy in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.23.5)
Requirement already satisfied: pandas in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.5.3)
Requirement already satisfied: wheel in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (0.38.4)
Collecting wurlitzer
Using cached wurlitzer-3.0.3-py3-none-any.whl (7.3 kB)
Requirement already satisfied: absl-py in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.4.0)
Collecting tensorboard<2.12,>=2.11
Using cached tensorboard-2.11.2-py3-none-any.whl (6.0 MB)
Requirement already satisfied: typing-extensions>=3.6.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (4.5.0)
Requirement already satisfied: grpcio<2.0,>=1.24.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (1.52.0rc1)
Requirement already satisfied: gast<=0.4.0,>=0.2.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (0.4.0)
Requirement already satisfied: flatbuffers>=2.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (23.1.21)
Requirement already satisfied: h5py>=2.9.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (3.8.0)
Requirement already satisfied: setuptools in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (67.4.0)
Requirement already satisfied: libclang>=13.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (15.0.6.1)
Collecting protobuf<3.20,>=3.9.2
Using cached protobuf-3.19.6-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
Requirement already satisfied: packaging in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (23.0)
Requirement already satisfied: wrapt>=1.11.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (1.15.0)
Requirement already satisfied: termcolor>=1.1.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (2.2.0)
Requirement already satisfied: astunparse>=1.6.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (1.6.3)
Requirement already satisfied: google-pasta>=0.1.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (0.2.0)
Collecting keras<2.12,>=2.11.0
Using cached keras-2.11.0-py2.py3-none-any.whl (1.7 MB)
Requirement already satisfied: opt-einsum>=2.3.2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (3.3.0)
Collecting tensorflow-estimator<2.12,>=2.11.0
Using cached tensorflow_estimator-2.11.0-py2.py3-none-any.whl (439 kB)
Requirement already satisfied: tensorflow-io-gcs-filesystem>=0.23.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.11.0->tensorflow_decision_forests) (0.31.0)
Requirement already satisfied: python-dateutil>=2.8.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2022.7.1)
Collecting tensorboard-data-server<0.7.0,>=0.6.0
Using cached tensorboard_data_server-0.6.1-py3-none-manylinux2010_x86_64.whl (4.9 MB)
Requirement already satisfied: werkzeug>=1.0.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (2.2.3)
Requirement already satisfied: requests<3,>=2.21.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (2.28.2)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (1.8.1)
Requirement already satisfied: google-auth<3,>=1.6.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (2.16.1)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (0.4.6)
Requirement already satisfied: markdown>=2.6.8 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (3.4.1)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (0.3.0rc1)
Requirement already satisfied: cachetools<6.0,>=2.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (5.3.0)
Requirement already satisfied: rsa<5,>=3.1.4 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (4.9)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (1.3.1)
Requirement already satisfied: importlib-metadata>=4.4 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from markdown>=2.6.8->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (6.0.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (3.0.1)
Requirement already satisfied: certifi>=2017.4.17 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (2022.12.7)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (1.26.14)
Requirement already satisfied: idna<4,>=2.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (3.4)
Requirement already satisfied: MarkupSafe>=2.1.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from werkzeug>=1.0.1->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (2.1.2)
Requirement already satisfied: zipp>=0.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (3.15.0)
Requirement already satisfied: pyasn1<0.6.0,>=0.4.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (0.5.0rc2)
Requirement already satisfied: oauthlib>=3.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.12,>=2.11->tensorflow~=2.11.0->tensorflow_decision_forests) (3.2.2)
Installing collected packages: wurlitzer, tensorflow-estimator, tensorboard-data-server, protobuf, keras, tensorboard, tensorflow, tensorflow_decision_forests
Attempting uninstall: tensorflow-estimator
Found existing installation: tensorflow-estimator 2.12.0rc0
Uninstalling tensorflow-estimator-2.12.0rc0:
Successfully uninstalled tensorflow-estimator-2.12.0rc0
Attempting uninstall: tensorboard-data-server
Found existing installation: tensorboard-data-server 0.7.0
Uninstalling tensorboard-data-server-0.7.0:
Successfully uninstalled tensorboard-data-server-0.7.0
Attempting uninstall: protobuf
Found existing installation: protobuf 3.20.3
Uninstalling protobuf-3.20.3:
Successfully uninstalled protobuf-3.20.3
Attempting uninstall: keras
Found existing installation: keras 2.12.0rc1
Uninstalling keras-2.12.0rc1:
Successfully uninstalled keras-2.12.0rc1
Attempting uninstall: tensorboard
Found existing installation: tensorboard 2.12.0
Uninstalling tensorboard-2.12.0:
Successfully uninstalled tensorboard-2.12.0
Attempting uninstall: tensorflow
Found existing installation: tensorflow 2.12.0rc0
Uninstalling tensorflow-2.12.0rc0:
Successfully uninstalled tensorflow-2.12.0rc0
Successfully installed keras-2.11.0 protobuf-3.19.6 tensorboard-2.11.2 tensorboard-data-server-0.6.1 tensorflow-2.11.0 tensorflow-estimator-2.11.0 tensorflow_decision_forests-1.2.0 wurlitzer-3.0.3
Wurlitzer 是在 Colabs 中显示详细的训练日志所需的(当在模型构造函数中使用 verbose=2 时)。
# 安装wurlitzer库,用于在Jupyter Notebook中显示命令行输出
!pip install wurlitzer
Requirement already satisfied: wurlitzer in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (3.0.3)
导入库
# 导入所需的库
import tensorflow_decision_forests as tfdf # 导入决策森林库
import os # 导入操作系统库
import numpy as np # 导入数值计算库
import pandas as pd # 导入数据处理库
import tensorflow as tf # 导入深度学习库
import math # 导入数学库
2023-03-01 12:08:27.871947: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-03-01 12:08:27.872079: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-03-01 12:08:27.872090: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
隐藏的代码单元格限制了colab中的输出高度。
# 导入必要的模块
from IPython.core.magic import register_line_magic # 注册魔术命令
from IPython.display import Javascript # 显示Javascript代码
from IPython.display import display as ipy_display # 显示输出
# 由于模型训练日志可能会占据整个屏幕,因此需要将其压缩到较小的视口中。
# 这个魔术命令允许设置单元格的最大高度。
@register_line_magic
def set_cell_height(size):
# 使用Javascript代码设置单元格的最大高度
ipy_display(
Javascript("google.colab.output.setIframeHeight(0, true, {maxHeight: " +
str(size) + "})"))
# 检查 TensorFlow Decision Forests 的版本
print("Found TensorFlow Decision Forests v" + tfdf.__version__)
Found TensorFlow Decision Forests v1.2.0
什么是排序模型?
排序模型的目标是正确排序项目。例如,排序可以用于在用户查询后选择最佳的文档进行检索。
表示排序数据集的一种常见方式是使用“相关性”分数:元素的顺序由它们的相关性定义:相关性较高的项目应该在相关性较低的项目之前。错误的代价由预测项目的相关性与正确项目的相关性之间的差异定义。例如,将相关性分别为3和4的两个项目错位不如将相关性分别为1和5的两个项目错位。
TF-DF希望以“平面”格式呈现排序数据集。
查询和相应文档的数据集可能如下所示:
| 查询 | 文档ID | 特征1 | 特征2 | 相关性 |
|---|---|---|---|---|
| 猫 | 1 | 0.1 | 蓝色 | 4 |
| 猫 | 2 | 0.5 | 绿色 | 1 |
| 猫 | 3 | 0.2 | 红色 | 2 |
| 狗 | 4 | NA | 红色 | 0 |
| 狗 | 5 | 0.2 | 红色 | 0 |
| 狗 | 6 | 0.6 | 绿色 | 1 |
相关性/标签是一个介于0和5之间的浮点数值(通常在0和4之间),其中0表示“完全无关”,4表示“非常相关”,5表示“与查询相同”。
在这个例子中,文档1与查询“猫”非常相关,而文档2只与猫“相关”。没有文档真正讨论“狗”(最高相关性是文档6的1)。然而,狗的查询仍然期望返回文档6(因为这是最多关于狗的文档)。
有趣的是,决策森林通常是很好的排序器,许多最先进的排序模型都是决策森林。
让我们训练一个排序模型
在这个例子中,我们使用了一个LETOR3数据集的样本。更具体地说,我们想要从LETOR3仓库下载OHSUMED.zip。这个数据集以libsvm格式存储,所以我们需要将其转换为csv格式。
# 导入必要的库
import tensorflow as tf
import os
# 下载并解压数据集
archive_path = tf.keras.utils.get_file("letor.zip",
"https://download.microsoft.com/download/E/7/E/E7EABEF1-4C7B-4E31-ACE5-73927950ED5E/Letor.zip",
extract=True)
# 构建原始数据集的路径
raw_dataset_path = os.path.join(os.path.dirname(archive_path),"OHSUMED/Data/Fold1/trainingset.txt")
Downloading data from https://download.microsoft.com/download/E/7/E/E7EABEF1-4C7B-4E31-ACE5-73927950ED5E/Letor.zip
8192/61824018 [..............................] - ETA: 0s
81920/61824018 [..............................] - ETA: 39s
368640/61824018 [..............................] - ETA: 24s
696320/61824018 [..............................] - ETA: 18s
2105344/61824018 [>.............................] - ETA: 8s
2990080/61824018 [>.............................] - ETA: 6s
4202496/61824018 [=>............................] - ETA: 6s
5619712/61824018 [=>............................] - ETA: 4s
6299648/61824018 [==>...........................] - ETA: 4s
7503872/61824018 [==>...........................] - ETA: 4s
8396800/61824018 [===>..........................] - ETA: 4s
9773056/61824018 [===>..........................] - ETA: 3s
10493952/61824018 [====>.........................] - ETA: 3s
12181504/61824018 [====>.........................] - ETA: 3s
12820480/61824018 [=====>........................] - ETA: 3s
14688256/61824018 [======>.......................] - ETA: 3s
16941056/61824018 [=======>......................] - ETA: 2s
18882560/61824018 [========>.....................] - ETA: 2s
20979712/61824018 [=========>....................] - ETA: 2s
23076864/61824018 [==========>...................] - ETA: 2s
25174016/61824018 [===========>..................] - ETA: 1s
27271168/61824018 [============>.................] - ETA: 1s
29368320/61824018 [=============>................] - ETA: 1s
31465472/61824018 [==============>...............] - ETA: 1s
33562624/61824018 [===============>..............] - ETA: 1s
35659776/61824018 [================>.............] - ETA: 1s
37756928/61824018 [=================>............] - ETA: 1s
39854080/61824018 [==================>...........] - ETA: 0s
41951232/61824018 [===================>..........] - ETA: 0s
44105728/61824018 [====================>.........] - ETA: 0s
46170112/61824018 [=====================>........] - ETA: 0s
48496640/61824018 [======================>.......] - ETA: 0s
50610176/61824018 [=======================>......] - ETA: 0s
52436992/61824018 [========================>.....] - ETA: 0s
54591488/61824018 [=========================>....] - ETA: 0s
56631296/61824018 [==========================>...] - ETA: 0s
59432960/61824018 [===========================>..] - ETA: 0s
61333504/61824018 [============================>.] - ETA: 0s
61824018/61824018 [==============================] - 2s 0us/step
以下是数据集的前几行:
!head {raw_dataset_path}
2 qid:1 1:3.00000000 2:2.07944154 3:0.27272727 4:0.26103413 5:37.33056511 6:11.43124125 7:37.29975005 8:1.13865735 9:15.52428944 10:8.83129655 11:12.00000000 12:5.37527841 13:0.08759124 14:0.08649364 15:28.30306459 16:9.34002375 17:24.80878473 18:0.39309068 19:57.41651698 20:3.29489291 21:25.02310000 22:3.21979940 23:-3.87098000 24:-3.90273000 25:-3.87512000 #docid = 40626
0 qid:1 1:3.00000000 2:2.07944154 3:0.42857143 4:0.40059418 5:37.33056511 6:11.43124125 7:37.29975005 8:1.81447983 9:17.45499227 10:11.61793065 11:10.00000000 12:5.19295685 13:0.08547009 14:0.08453711 15:28.30306459 16:9.34002375 17:24.80878473 18:0.34920457 19:43.24062605 20:2.65472417 21:23.49030000 22:3.15658757 23:-3.96838000 24:-4.00865000 25:-3.98670000 #docid = 11852
2 qid:1 1:0.00000000 2:0.00000000 3:0.00000000 4:0.00000000 5:37.33056511 6:11.43124125 7:37.29975005 8:0.00000000 9:0.00000000 10:0.00000000 11:8.00000000 12:4.38202663 13:0.07692308 14:0.07601813 15:28.30306459 16:9.34002375 17:24.80878473 18:0.24031887 19:25.81698944 20:1.55134225 21:15.86500000 22:2.76411543 23:-4.28166000 24:-4.33313000 25:-4.44161000 #docid = 12693
2 qid:1 1:4.00000000 2:2.77258872 3:0.33333333 4:0.32017083 5:37.33056511 6:11.43124125 7:37.29975005 8:1.26080803 9:17.97524177 10:8.86378153 11:3.00000000 12:1.79175947 13:0.03409091 14:0.03377241 15:28.30306459 16:9.34002375 17:24.80878473 18:0.11149640 19:10.09242586 20:0.64975836 21:14.27780000 22:2.65870588 23:-4.77772000 24:-4.73563000 25:-4.86759000 #docid = 12694
0 qid:1 1:0.00000000 2:0.00000000 3:0.00000000 4:0.00000000 5:37.33056511 6:11.43124125 7:37.29975005 8:0.00000000 9:0.00000000 10:0.00000000 11:6.00000000 12:3.87120101 13:0.04761905 14:0.04736907 15:28.30306459 16:9.34002375 17:24.80878473 18:0.18210403 19:23.54629629 20:1.62139253 21:15.27640000 22:2.72630915 23:-4.43073000 24:-4.45985000 25:-4.57053000 #docid = 15450
1 qid:1 1:1.00000000 2:0.69314718 3:0.14285714 4:0.13353139 5:37.33056511 6:11.43124125 7:37.29975005 8:0.62835774 9:6.12170704 10:4.15689134 11:10.00000000 12:4.43081680 13:0.08333333 14:0.08191707 15:28.30306459 16:9.34002375 17:24.80878473 18:0.32796715 19:43.13226482 20:2.12249256 21:16.33990000 22:2.79360997 23:-4.75652000 24:-4.66814000 25:-4.82965000 #docid = 17665
0 qid:1 1:0.00000000 2:0.00000000 3:0.00000000 4:0.00000000 5:37.33056511 6:11.43124125 7:37.29975005 8:0.00000000 9:0.00000000 10:0.00000000 11:3.00000000 12:2.07944154 13:0.05357143 14:0.05309873 15:28.30306459 16:9.34002375 17:24.80878473 18:0.25524876 19:14.92698785 20:2.59607100 21:16.00510000 22:2.77290742 23:-4.54349000 24:-4.52334000 25:-4.69865000 #docid = 18432
0 qid:1 1:1.00000000 2:0.69314718 3:0.50000000 4:0.40546511 5:37.33056511 6:11.43124125 7:37.29975005 8:1.07964603 9:3.88727484 10:3.22375250 11:14.00000000 12:5.19295685 13:0.10000000 14:0.09779062 15:28.30306459 16:9.34002375 17:24.80878473 18:0.41939944 19:65.74099134 20:2.81316484 21:20.37810000 22:3.01446079 23:-4.25087000 24:-4.18235000 25:-4.21824000 #docid = 18540
0 qid:1 1:3.00000000 2:2.07944154 3:0.60000000 4:0.54696467 5:37.33056511 6:11.43124125 7:37.29975005 8:2.13084866 9:15.65986863 10:10.90521468 11:9.00000000 12:4.68213123 13:0.13043478 14:0.12827973 15:28.30306459 16:9.34002375 17:24.80878473 18:0.44756051 19:33.23097043 20:2.69791902 21:21.26510000 22:3.05706723 23:-4.18472000 24:-4.18399000 25:-4.03491000 #docid = 44695
0 qid:1 1:0.00000000 2:0.00000000 3:0.00000000 4:0.00000000 5:37.33056511 6:11.43124125 7:37.29975005 8:0.00000000 9:0.00000000 10:0.00000000 11:16.00000000 12:6.10479323 13:0.11510791 14:0.11289797 15:28.30306459 16:9.34002375 17:24.80878473 18:0.37130060 19:55.42216381 20:2.33077909 21:19.21490000 22:2.95568602 23:-4.09988000 24:-4.15679000 25:-4.17349000 #docid = 18541
第一步是将此数据集转换为上述提到的“平面”格式。
# 定义函数convert_libsvm_to_csv,将libsvm格式的排名数据集转换为平面的csv文件
# 参数:
# - src_path: libsvm数据集的路径
# - dst_path: 转换后的csv文件的路径
def convert_libsvm_to_csv(src_path, dst_path):
"""将libsvm格式的排名数据集转换为平面的csv文件。
注意:此代码特定于LETOR3数据集。
"""
# 打开目标csv文件
dst_handle = open(dst_path, "w")
# 标记是否为第一行
first_line = True
# 遍历源libsvm文件的每一行
for src_line in open(src_path,"r"):
# 注意:最后3个元素是注释,不需要处理
# 将每一行按空格分割,并去掉最后3个元素
items = src_line.split(" ")[:-3]
# 获取相关性值
relevance = items[0]
# 获取组别
group = items[1].split(":")[1]
# 获取特征值,将每个特征值按冒号分割
features = [item.split(":") for item in items[2:]]
if first_line:
# 写入csv文件的表头
dst_handle.write("relevance,group," + ",".join(["f_" + feature[0] for feature in features]) + "\n")
first_line = False
# 写入csv文件的每一行,格式为:相关性值,组别,特征值1,特征值2,...
dst_handle.write(relevance + ",g_" + group + "," + (",".join([feature[1] for feature in features])) + "\n")
# 关闭目标csv文件
dst_handle.close()
# 转换数据集
csv_dataset_path="/tmp/ohsumed.csv"
convert_libsvm_to_csv(raw_dataset_path, csv_dataset_path)
# 将数据集加载到Pandas Dataframe中
dataset_df = pd.read_csv(csv_dataset_path)
# 显示前3个样例
dataset_df.head(3)
| relevance | group | f_1 | f_2 | f_3 | f_4 | f_5 | f_6 | f_7 | f_8 | ... | f_16 | f_17 | f_18 | f_19 | f_20 | f_21 | f_22 | f_23 | f_24 | f_25 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | g_1 | 3.0 | 2.079442 | 0.272727 | 0.261034 | 37.330565 | 11.431241 | 37.29975 | 1.138657 | ... | 9.340024 | 24.808785 | 0.393091 | 57.416517 | 3.294893 | 25.0231 | 3.219799 | -3.87098 | -3.90273 | -3.87512 |
| 1 | 0 | g_1 | 3.0 | 2.079442 | 0.428571 | 0.400594 | 37.330565 | 11.431241 | 37.29975 | 1.814480 | ... | 9.340024 | 24.808785 | 0.349205 | 43.240626 | 2.654724 | 23.4903 | 3.156588 | -3.96838 | -4.00865 | -3.98670 |
| 2 | 2 | g_1 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 37.330565 | 11.431241 | 37.29975 | 0.000000 | ... | 9.340024 | 24.808785 | 0.240319 | 25.816989 | 1.551342 | 15.8650 | 2.764115 | -4.28166 | -4.33313 | -4.44161 |
3 rows × 27 columns
在这个数据集中,每一行代表一个查询/文档对(称为“组”)。"相关性"表示查询与文档的匹配程度。
查询和文档的特征在"f1-25"中合并在一起。特征的确切定义未知,但可能是以下内容之一:
- 查询中的单词数量
- 查询和文档之间的共同单词数量
- 查询的嵌入和文档的嵌入之间的余弦相似度
- …
让我们将Pandas Dataframe转换为TensorFlow Dataset:
# 将Pandas DataFrame转换为TensorFlow数据集
dataset_ds = tfdf.keras.pd_dataframe_to_tf_dataset(dataset_df, label="relevance", task=tfdf.keras.Task.RANKING)
# 参数说明:
# - dataset_df: 要转换的Pandas DataFrame
# - label: 数据集中用作标签的列名
# - task: 数据集的任务类型,这里是排序任务
让我们配置和训练我们的排序模型。
%set_cell_height 400
# 创建一个梯度提升树模型
model = tfdf.keras.GradientBoostedTreesModel(
task=tfdf.keras.Task.RANKING, # 设置模型任务为排序任务
ranking_group="group", # 设置排序的分组依据
num_trees=50 # 设置模型中树的数量
)
# 使用给定的数据集训练模型
model.fit(dataset_ds)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpi2w09mpt as temporary training directory
Reading training dataset...
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23.
Instructions for updating:
Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23.
Instructions for updating:
Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
Training dataset read in 0:00:03.795558. Found 9219 examples.
Training model...
2023-03-01 12:08:41.341307: W external/ydf/yggdrasil_decision_forests/learner/gradient_boosted_trees/gradient_boosted_trees.cc:1790] "goss_alpha" set but "sampling_method" not equal to "GOSS".
2023-03-01 12:08:41.341342: W external/ydf/yggdrasil_decision_forests/learner/gradient_boosted_trees/gradient_boosted_trees.cc:1800] "goss_beta" set but "sampling_method" not equal to "GOSS".
2023-03-01 12:08:41.341349: W external/ydf/yggdrasil_decision_forests/learner/gradient_boosted_trees/gradient_boosted_trees.cc:1814] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
Model trained in 0:00:00.723886
Compiling model...
[INFO 2023-03-01T12:08:42.055289081+00:00 kernel.cc:1214] Loading model from path /tmpfs/tmp/tmpi2w09mpt/model/ with prefix 501533f696fb4e7c
[INFO 2023-03-01T12:08:42.056787691+00:00 abstract_model.cc:1311] Engine "GradientBoostedTreesQuickScorerExtended" built
[INFO 2023-03-01T12:08:42.056818335+00:00 kernel.cc:1046] Use fast generic engine
WARNING:tensorflow:AutoGraph could not transform <function simple_ml_inference_op_with_handle at 0x7fee12c7d160> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function simple_ml_inference_op_with_handle at 0x7fee12c7d160> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function simple_ml_inference_op_with_handle at 0x7fee12c7d160> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
Model compiled.
<keras.callbacks.History at 0x7fee10dc41f0>
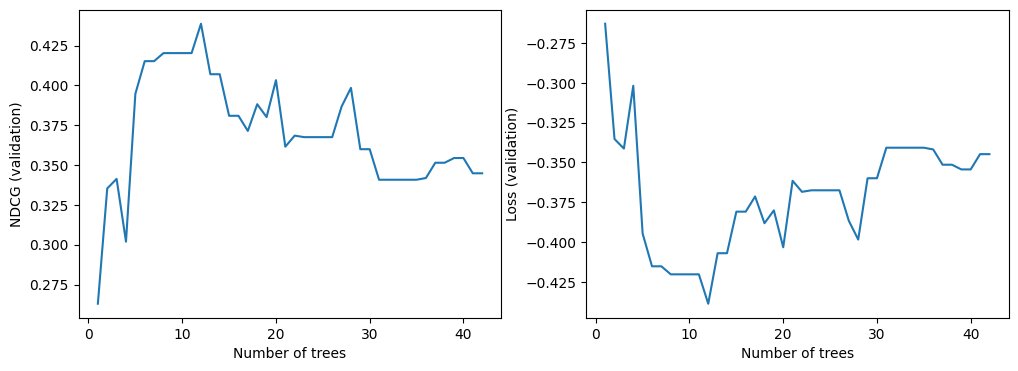
我们现在可以查看验证数据集上模型的质量。默认情况下,TF-DF训练排序模型以优化NDCG。NDCG是一个介于0和1之间的值,其中1是完美得分。因此,-NDCG是模型的损失。
# 导入matplotlib.pyplot模块,用于绘图
import matplotlib.pyplot as plt
# 获取模型的训练日志
logs = model.make_inspector().training_logs()
# 创建一个图形窗口,设置大小为12x4
plt.figure(figsize=(12, 4))
# 在图形窗口中创建一个子图,位置为1行2列的第1个位置
plt.subplot(1, 2, 1)
# 绘制折线图,x轴为每个日志的树的数量,y轴为每个日志的NDCG值
plt.plot([log.num_trees for log in logs], [log.evaluation.ndcg for log in logs])
# 设置x轴标签为"Number of trees"
plt.xlabel("Number of trees")
# 设置y轴标签为"NDCG (validation)"
plt.ylabel("NDCG (validation)")
# 在图形窗口中创建一个子图,位置为1行2列的第2个位置
plt.subplot(1, 2, 2)
# 绘制折线图,x轴为每个日志的树的数量,y轴为每个日志的损失值
plt.plot([log.num_trees for log in logs], [log.evaluation.loss for log in logs])
# 设置x轴标签为"Number of trees"
plt.xlabel("Number of trees")
# 设置y轴标签为"Loss (validation)"
plt.ylabel("Loss (validation)")
# 显示图形窗口中的图形
plt.show()
关于所有的TF-DF模型,你也可以查看模型报告(注意:模型报告中还包含训练日志):
# 设置单元格高度为400
%set_cell_height 400
# 打印模型的概要信息
model.summary()
<IPython.core.display.Javascript object>
Model: "gradient_boosted_trees_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
=================================================================
Total params: 1
Trainable params: 0
Non-trainable params: 1
_________________________________________________________________
Type: "GRADIENT_BOOSTED_TREES"
Task: RANKING
Label: "__LABEL"
Rank group: "group"
display_tree({“margin”: 10, “node_x_size”: 160, “node_y_size”: 28, “node_x_offset”: 180, “node_y_offset”: 33, “font_size”: 10, “edge_rounding”: 20, “node_padding”: 2, “show_plot_bounding_box”: false}, {“value”: {“type”: “REGRESSION”, “value”: 1.1403852084868049e-08, “num_examples”: 8365.0, “standard_deviation”: 1.0916302004218401}, “condition”: {“type”: “NUMERICAL_IS_HIGHER_THAN”, “attribute”: “f_8”, “threshold”: 3.4935169219970703}, “children”: [{“value”: {“type”: “REGRESSION”, “value”: 0.20000000298023224, “num_examples”: 5.0, “standard_deviation”: 10.890856193034367}}, {“value”: {“type”: “REGRESSION”, “value”: -0.0024064122699201107, “num_examples”: 8360.0, “standard_deviation”: 1.050017420353196}, “condition”: {“type”: “NUMERICAL_IS_HIGHER_THAN”, “attribute”: “f_8”, “threshold”: 2.7679028511047363}, “children”: [{“value”: {“type”: “REGRESSION”, “value”: 0.189948171377182, “num_examples”: 23.0, “standard_deviation”: 4.192734995883616}, “condition”: {“type”: “NUMERICAL_IS_HIGHER_THAN”, “attribute”: “f_25”, “threshold”: -4.108095169067383}, “children”: [{“value”: {“type”: “REGRESSION”, “value”: 0.156146839261055, “num_examples”: 18.0, “standard_deviation”: 0.25010476915884056}, “condition”: {“type”: “NUMERICAL_IS_HIGHER_THAN”, “attribute”: “f_19”, “threshold”: 33.230445861816406}}, {“value”: {“type”: “REGRESSION”, “value”: 0.19655971229076385, “num_examples”: 5.0, “standard_deviation”: 7.882545843900897}}]}, {“value”: {“type”: “REGRESSION”, “value”: -0.0049870857037603855, “num_examples”: 8337.0, “standard_deviation”: 1.025938917684628}, “condition”: {“type”: “NUMERICAL_IS_HIGHER_THAN”, “attribute”: “f_9”, “threshold”: 30.149837493896484}, “children”: [{“value”: {“type”: “REGRESSION”, “value”: 0.20000000298023224, “num_examples”: 6.0, “standard_deviation”: 3.859335854414536}}, {“value”: {“type”: “REGRESSION”, “value”: -0.0061759622767567635, “num_examples”: 8331.0, “standard_deviation”: 1.0193262525324194}, “condition”: {“type”: “NUMERICAL_IS_HIGHER_THAN”, “attribute”: “f_8”, “threshold”: 0.4886942207813263}}]}]}]}, “#tree_plot_ef78272ff29c4e78b6e64872f317abbb”)
使用排序模型进行预测
对于一个输入的查询,我们可以使用我们的排序模型来预测一组文档的相关性。实际上,这意味着对于每个查询,我们必须提供一组可能与查询相关或不相关的文档。我们称这些文档为候选文档。对于每个查询/候选文档对,我们可以计算训练过程中使用的相同特征。这就是我们的服务数据集。
回到本教程开头的例子,服务数据集可能如下所示:
| 查询 | 文档ID | 特征1 | 特征2 |
|---|---|---|---|
| fish | 32 | 0.3 | blue |
| fish | 33 | 1.0 | green |
| fish | 34 | 0.4 | blue |
| fish | 35 | NA | brown |
注意,相关性不是服务数据集的一部分,因为这是模型试图预测的内容。
服务数据集被输入到TF-DF模型中,并为每个文档分配一个相关性分数。
| 查询 | 文档ID | 特征1 | 特征2 | 相关性 |
|---|---|---|---|---|
| fish | 32 | 0.3 | blue | 0.325 |
| fish | 33 | 1.0 | green | 0.125 |
| fish | 34 | 0.4 | blue | 0.155 |
| fish | 35 | NA | brown | 0.593 |
这意味着文档ID为35的文档被预测为与查询"fish"最相关。
让我们尝试使用我们的真实模型来完成这个任务。
# 定义测试数据集的路径,使用libsvm格式
test_dataset_path = os.path.join(os.path.dirname(archive_path),"OHSUMED/Data/Fold1/testset.txt")
# 将数据集转换为csv格式
csv_test_dataset_path="/tmp/ohsumed_test.csv"
convert_libsvm_to_csv(raw_dataset_path, csv_test_dataset_path)
# 将csv格式的数据集加载到Pandas Dataframe中
test_dataset_df = pd.read_csv(csv_test_dataset_path)
# 显示前3个样本
test_dataset_df.head(3)
| relevance | group | f_1 | f_2 | f_3 | f_4 | f_5 | f_6 | f_7 | f_8 | ... | f_16 | f_17 | f_18 | f_19 | f_20 | f_21 | f_22 | f_23 | f_24 | f_25 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | g_1 | 3.0 | 2.079442 | 0.272727 | 0.261034 | 37.330565 | 11.431241 | 37.29975 | 1.138657 | ... | 9.340024 | 24.808785 | 0.393091 | 57.416517 | 3.294893 | 25.0231 | 3.219799 | -3.87098 | -3.90273 | -3.87512 |
| 1 | 0 | g_1 | 3.0 | 2.079442 | 0.428571 | 0.400594 | 37.330565 | 11.431241 | 37.29975 | 1.814480 | ... | 9.340024 | 24.808785 | 0.349205 | 43.240626 | 2.654724 | 23.4903 | 3.156588 | -3.96838 | -4.00865 | -3.98670 |
| 2 | 2 | g_1 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 37.330565 | 11.431241 | 37.29975 | 0.000000 | ... | 9.340024 | 24.808785 | 0.240319 | 25.816989 | 1.551342 | 15.8650 | 2.764115 | -4.28166 | -4.33313 | -4.44161 |
3 rows × 27 columns
假设我们的查询是"g_5",测试数据集已经包含了该查询的候选文档。
# 过滤 "g_5" 组别的数据
serving_dataset_df = test_dataset_df[test_dataset_df['group'] == 'g_5']
# 移除组别和相关性的列,因为在预测中不需要这些列
serving_dataset_df = serving_dataset_df.drop(['relevance', 'group'], axis=1)
# 将数据转换为 Tensorflow 数据集
serving_dataset_ds = tfdf.keras.pd_dataframe_to_tf_dataset(serving_dataset_df, task=tfdf.keras.Task.RANKING)
# 运行预测,对所有候选文档进行预测
predictions = model.predict(serving_dataset_ds)
1/1 [==============================] - ETA: 0s
1/1 [==============================] - 0s 181ms/step
我们可以将预测结果添加到数据框中,并使用它们找到得分最高的文档。
# 将预测结果添加到serving_dataset_df数据框中的'prediction_score'列中
serving_dataset_df['prediction_score'] = predictions
# 按照'prediction_score'列的值降序排列serving_dataset_df数据框
serving_dataset_df.sort_values(by=['prediction_score'], ascending=False)
| f_1 | f_2 | f_3 | f_4 | f_5 | f_6 | f_7 | f_8 | f_9 | f_10 | ... | f_17 | f_18 | f_19 | f_20 | f_21 | f_22 | f_23 | f_24 | f_25 | prediction_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 642 | 2.0 | 1.386294 | 0.666667 | 0.575364 | 29.447117 | 8.435116 | 29.448021 | 2.207135 | 12.292170 | 10.101899 | ... | 21.208715 | 0.523845 | 77.852148 | 7.659101 | 30.2660 | 3.410025 | -3.03908 | -3.19282 | -2.87112 | 0.965342 |
| 685 | 3.0 | 2.079442 | 0.750000 | 0.669431 | 29.447117 | 8.435116 | 29.448021 | 3.060164 | 21.795657 | 17.652746 | ... | 21.208715 | 0.793681 | 39.623271 | 8.513801 | 33.9830 | 3.525860 | -2.84235 | -2.81360 | -2.59920 | 0.893874 |
| 646 | 4.0 | 2.772589 | 0.285714 | 0.275971 | 29.447117 | 8.435116 | 29.448021 | 1.421063 | 24.550338 | 14.727974 | ... | 21.208715 | 0.602963 | 84.868108 | 7.767931 | 31.0268 | 3.434851 | -3.19269 | -3.31166 | -3.14901 | 0.258856 |
| 684 | 4.0 | 2.484907 | 0.333333 | 0.314236 | 29.447117 | 8.435116 | 29.448021 | 1.730304 | 29.299744 | 15.114793 | ... | 21.208715 | 0.692899 | 71.279648 | 8.148804 | 36.5645 | 3.599078 | -2.16625 | -2.43823 | -1.94658 | 0.258856 |
| 640 | 3.0 | 2.079442 | 0.428571 | 0.400594 | 29.447117 | 8.435116 | 29.448021 | 2.107361 | 21.795657 | 15.999891 | ... | 21.208715 | 0.000000 | 0.000000 | 0.000000 | 30.6422 | 3.422378 | -3.20997 | -2.59768 | -2.59768 | 0.258856 |
5 rows × 26 columns
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- IDEA启动项目遇到的异常汇总,包括插件异常,版本依赖异常,启动异常等以及对应的解决办法
- 常见的 JavaScript 调试工具详解
- Solidbi仪表板介绍
- Python组装jmx并调用JMeter执行压测
- golang开发--beego入门
- (四)Java 变量
- Ubuntu Desktop 22.04 禁用自动更新
- 异常处理与CrashRpt工具——(2)
- Flash读取数据库中的数据
- 应用在智能照明系统中的光距感-接近传感芯片