直面Java:2.Java高级篇
?🐓Java类加载过程
1.加载 加载时类加载的第一个过程,在这个阶段,将完成一下三件事情:通过一个类的全限定名获取该类的二进制流。将该二进制流中的静态存储结构转化为方法去运行时数据结构。?在内存中生成该类的Class对象,作为该类的数据访问入口。
2.验证 验证的目的是为了确保Class文件的字节流中的信息不回危害到虚拟机.在该阶段主要完成以下四钟验证: 文件格式验证:验证字节流是否符合Class文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型. 元数据验证:对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。字节码验证:是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如:方法中的类型转换是否正确,跳转指令是否正确等。符号引用验证:这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
3.准备 准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
4.解析 该阶段主要完成符号引用到直接引用的转换动作。解析动作并不一定在初始化动作完成之前,也有可能在初始化之后。
5.初始化 初始化时类加载的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
🐓什么是类加载器,类加载器有哪些????????
类加载器就是把类文件加载到虚拟机中,也就是说通过一个类的全限定名来获取描述该类的二进制字节流?
1.主要有以下四种类加载器
启动类加载器(Bootstrap ClassLoader)用来加载java核心类库,无法被java程序直接引用。
扩展类加载器(extension class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
系统类加载器(system class loader)也叫应用类加载器:它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过 ClassLoader.getSystemClassLoader()来获取它。
用户自定义类加载器,通过继承 java.lang.ClassLoader类的方式实现。
🐓HashMap的底层源码?????????
HashMap的底层结构在jdk1.7中由数组+链表实现,在jdk1.8中由数组+链表+红黑树实现,以数组+链表的结构为例。


JDK1.8之前Put方法:
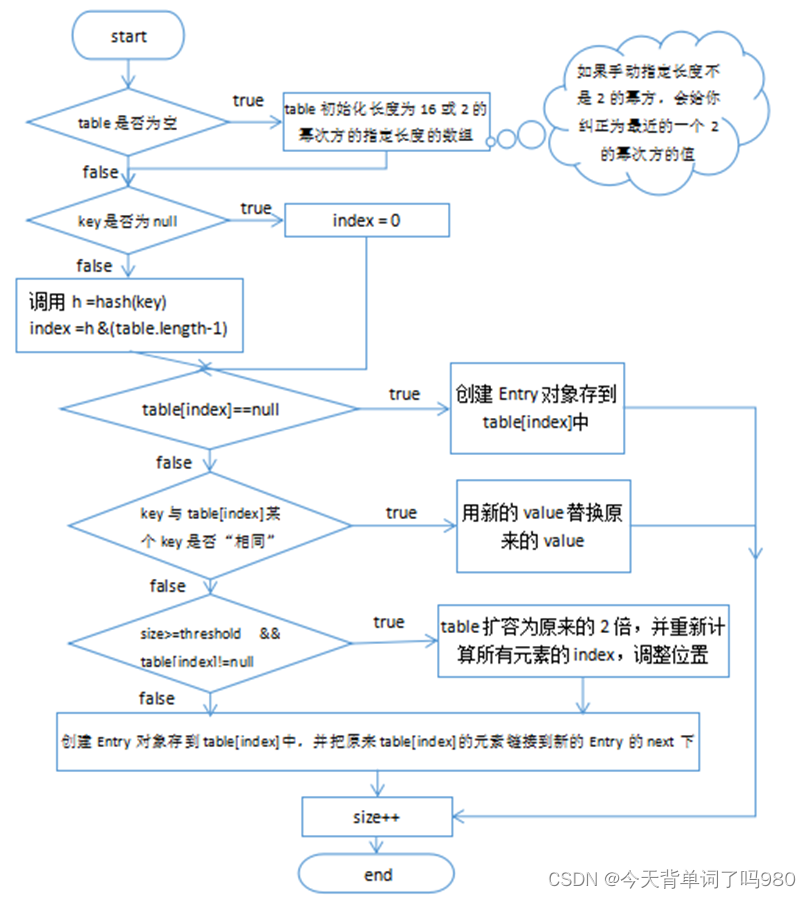
JDK1.8之后Put方法:

JDK1.8之后底层源码:
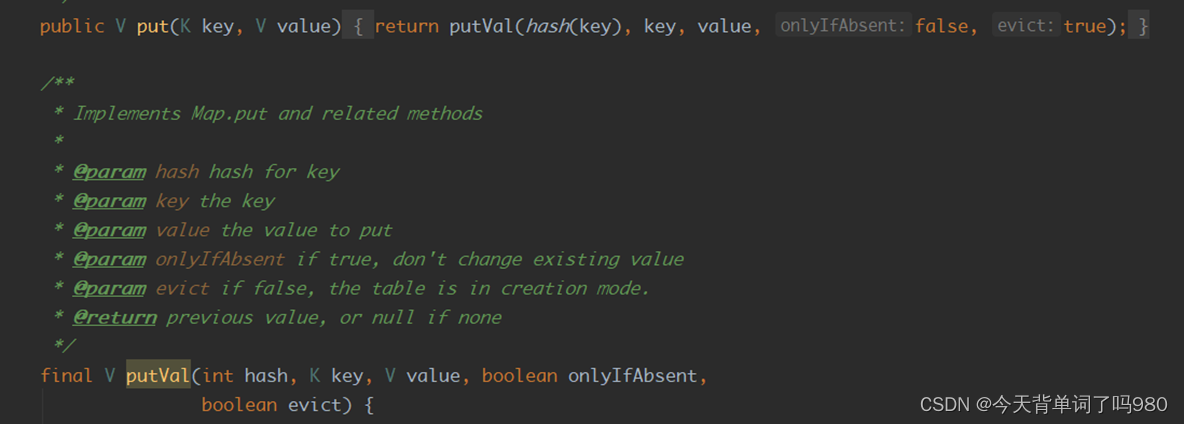

HashMap以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
补充:将链表转换成红黑树前会判断,即使阈值大于8,但是数组长度小于64,此时并不会将链表变为红黑树。而是选择进行数组扩容。
这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。具体可以参考 treeifyBin方法。
当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于8并且数组长度大于64时,链表转换为红黑树时,效率也变的更高效。
🐓Jvm的分区


🐓垃圾回收算法
1.复制算法? 年轻代中使用的是Minor GC,这种GC算法采用的是复制算法(Copying)
a.?效率高,缺点:需要内存容量大,比较耗内存
b.?使用在占空间比较小、刷新次数多的新生区
2.标记-清除? 老年代一般是由标记清除或者是标记清除与标记整理的混合实现
a.效率比较低,会差生碎片。
3.标记-整理? 老年代一般是由标记清除或者是标记清除与标记整理的混合实现
a.?效率低速度慢,需要移动对象,但不会产生碎片。
🐓GC对象的判断方法
-
引用计数法??所谓引用计数法就是给每一个对象设置一个引用计数器,每当有一个地方引用这个对象时,就将计数器加一,引用失效时,计数器就减一。当一个对象的引用计数器为零时,说明此对象没有被引用,也就是“死对象”,将会被垃圾回收. 引用计数法有一个缺陷就是无法解决循环引用问题,也就是说当对象A引用对象B,对象B又引用者对象A,那么此时A,B对象的引用计数器都不为零,也就造成无法完成垃圾回收,所以主流的虚拟机都没有采用这种算法。
- 可达性算法(引用链法) ?该算法的基本思路就是通过一些被称为引用链(GC Roots)的对象作为起点,从这些节点开始向下搜索,搜索走过的路径被称为(Reference Chain),当一个对象到GC Roots没有任何引用链相连时(即从GC Roots节点到该节点不可达),则证明该对象是不可用的。在java中可以作为GC Roots的对象有以下几种:虚拟机栈中引用的对象、方法区类静态属性引用的对象、方法区常量池引用的对象、本地方法栈JNI引用的对象。
🐓简述java内存分配与回收策略以及Minor GC和Major GC(full GC)
1.内存分配
栈区:栈分为java虚拟机栈和本地方法栈
堆区:堆被所有线程共享区域,在虚拟机启动时创建,唯一目的存放对象实例。堆区是gc的主要区域,通常情况下分为两个区块年轻代和年老代。更细一点年轻代又分为Eden区,主要放新创建对象,From survivor 和 To survivor 保存gc后幸存下的对象,默认情况下各自占比 8:1:1。
方法区:被所有线程共享区域,用于存放已被虚拟机加载的类信息,常量,静态变量等数据。被Java虚拟机描述为堆的一个逻辑部分。习惯是也叫它永久代(permanment generation)
程序计数器:当前线程所执行的行号指示器。通过改变计数器的值来确定下一条指令,比如循环,分支,跳转,异常处理,线程恢复等都是依赖计数器来完成。线程私有的。
2.回收策略以及Minor GC和Major GC
1.对象优先在堆的Eden区分配
2.大对象直接进入老年代
3.长期存活的对象将直接进入老年代
当Eden区没有足够的空间进行分配时,虚拟机会执行一次Minor GC.Minor GC通常发生在新生代的Eden区,在这个区的对象生存期短,往往发生GC的频率较高,回收速度比较快;Full Gc/Major GC 发生在老年代,一般情况下,触发老年代GC的时候不会触发Minor GC,但是通过配置,可以在Full GC之前进行一次Minor GC这样可以加快老年代的回收速度。
🐓为什么使用线程池
线程池做的工作主要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最 大数量,超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行
主要特点:线程复用;控制最大并发数:管理线程。
第一:降低资源消耗。通过重复利用己创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进 行统一的分配,调优和监控
🐓线程池底层工作原理

🐓线程池中ThreadPoolExcutor对象有哪些参数
1.corePoolSize:核心线程数,
在ThreadPoolExecutor中有一个与它相关的配置:allowCoreThreadTimeOut(默认为false),当allowCoreThreadTimeOut为false时,核心线程会一直存活,哪怕是一直空闲着。而当allowCoreThreadTimeOut为true时核心线程空闲时间超过keepAliveTime时会被回收。
2.maximumPoolSize:最大线程数
线程池能容纳的最大线程数,当线程池中的线程达到最大时,此时添加任务将会采用拒绝策略,默认的拒绝策略是抛出一个运行时错误(RejectedExecutionException)。值得一提的是,当初始化时用的工作队列为LinkedBlockingDeque时,这个值将无效。
3.keepAliveTime:存活时间,
当非核心空闲超过这个时间将被回收,同时空闲核心线程是否回收受allowCoreThreadTimeOut影响。
4.unit:keepAliveTime的单位。
5.workQueue:任务队列
常用有三种队列,即SynchronousQueue,LinkedBlockingDeque(无界队列),ArrayBlockingQueue(有界队列)。
6.threadFactory:线程工厂,
ThreadFactory是一个接口,用来创建worker。通过线程工厂可以对线程的一些属性进行定制。默认直接新建线程。
7.RejectedExecutionHandler:拒绝策略
也是一个接口,只有一个方法,当线程池中的资源已经全部使用,添加新线程被拒绝时,会调用RejectedExecutionHandler的rejectedExecution法。默认是抛出一个运行时异常。
🐓synchronized底层实现是什么 lock底层是什么 有什么区别
Synchronized原理:
方法级的同步是隐式,即无需通过字节码指令来控制的,它实现在方法调用和返回操作之中。JVM可以从方法常量池中的方法表结构(method_info Structure) 中的 ACC_SYNCHRONIZED 访问标志区分一个方法是否同步方法。当方法调用时,调用指令将会 检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有monitor(虚拟机规范中用的是管程一词),然后再执行方法,最后再方法完成(无论是正常完成还是非正常完成)时释放monitor。
代码块的同步是利用monitorenter和monitorexit这两个字节码指令。它们分别位于同步代码块的开始和结束位置。当jvm执行到monitorenter指令时,当前线程试图获取monitor对象的所有权,如果未加锁或者已经被当前线程所持有,就把锁的计数器+1;当执行monitorexit指令时,锁计数器-1;当锁计数器为0时,该锁就被释放了。如果获取monitor对象失败,该线程则会进入阻塞状态,直到其他线程释放锁。
Lock原理:
- Lock的存储结构:一个int类型状态值(用于锁的状态变更),一个双向链表(用于存储等待中的线程)
- Lock获取锁的过程:本质上是通过CAS来获取状态值修改,如果当场没获取到,会将该线程放在线程等待链表中。
- Lock释放锁的过程:修改状态值,调整等待链表。
- Lock大量使用CAS+自旋。因此根据CAS特性,lock建议使用在低锁冲突的情况下。
Lock与synchronized的区别:
- Lock的加锁和解锁都是由java代码配合native方法(调用操作系统的相关方法)实现的,而synchronize的加锁和解锁的过程是由JVM管理的
- 当一个线程使用synchronize获取锁时,若锁被其他线程占用着,那么当前只能被阻塞,直到成功获取锁。而Lock则提供超时锁和可中断等更加灵活的方式,在未能获取锁的???? 条件下提供一种退出的机制。
- 一个锁内部可以有多个Condition实例,即有多路条件队列,而synchronize只有一路条件队列;同样Condition也提供灵活的阻塞方式,在未获得通知之前可以通过中断线程以??? 及设置等待时限等方式退出条件队列。
- synchronize对线程的同步仅提供独占模式,而Lock即可以提供独占模式,也可以提供共享模式
-
synchronized
?Lock
?关键字
?类
?自动加锁和释放锁
?需要手动调用unlock方法释放锁
?jvm层面的锁
?API层面的锁
?非公平锁
?可以选择公平或者非公平锁
?锁是一个对象,并且锁的信息保存在了对象中
?代码中通过int类型的state标识
?有一个锁升级的过程
?无
?
🐓synchronized和volatile的区别
1.volatile本质是告诉JVM当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
2.volatile仅能用在变量级别,而synchronized可以使用在变量、方法、类级别。
3.volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
4.volatile不会造成线程阻塞,synchronized可能会造成线程阻塞。
5.volatile标记的变量不会被编译器优化,synchronized标记的变量可以被编译器优化。
🐓了解ConcurrentHashMap吗 ?为什么ConcurrentHashMap性能比HashTable高,说下原理
ConcurrentHashMap是线程安全的Map容器,JDK8之前,ConcurrentHashMap使用锁分段技术,将数据分成一段段存储,每个数据段配置一把锁,即segment类,这个类继承ReentrantLock来保证线程安全,JKD8的版本取消Segment这个分段锁数据结构,底层也是使用Node数组+链表+红黑树,从而实现对每一段数据就行加锁,也减少了并发冲突的概率。
hashtable类基本上所有的方法都是采用synchronized进行线程安全控制,高并发情况下效率就降低 ,ConcurrentHashMap是采用了分段锁的思想提高性能,锁粒度更细化
🐓ConcurrentHashMap的底层原理
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算
// 其实也就是把高4位与segmentMask(1111)做与运算
// this.segmentMask = ssize - 1;
//对hash值进行右移segmentShift位,计算元素对应segment中数组下表的位置
//把hash右移segmentShift,相当于只要hash值的高32-segmentShift位,右移的目的是保留了hash值的高位。然后和segmentMask与操作计算元素在segment数组中的下表
int j = (hash >>> segmentShift) & segmentMask;
//使用unsafe对象获取数组中第j个位置的值,后面加上的是偏移量
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 如果查找到的 Segment 为空,初始化
s = ensureSegment(j);
//插入segment对象
return s.put(key, hash, value, false);
}
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 判断 u 位置的 Segment 是否为null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
// 获取0号 segment 里的 HashEntry<K,V> 初始化长度
int cap = proto.table.length;
// 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的
float lf = proto.loadFactor;
// 计算扩容阀值
int threshold = (int)(cap * lf);
// 创建一个 cap 容量的 HashEntry 数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
// 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 自旋检查 u 位置的 Segment 是否为null
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 使用CAS 赋值,只会成功一次
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 计算要put的数据位置
int index = (tab.length - 1) & hash;
// CAS 获取 index 坐标的值
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 value
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// first 有值没说明 index 位置已经有值了,有冲突,链表头插法。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 容量大于扩容阀值,小于最大容量,进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目标位置元素
Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 数组桶为空,初始化数组桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加锁加入节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// 说明是链表
if (fh >= 0) {
binCount = 1;
// 循环加入新的或者覆盖节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
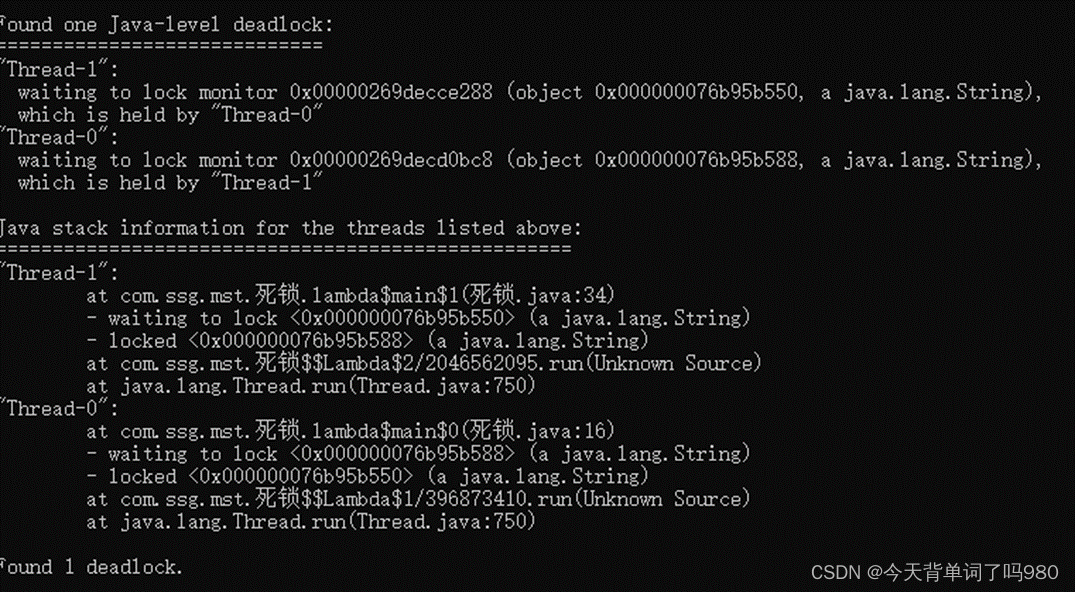
🐓如何查看Java死锁
####演示死锁
package com.ssg.mst;
public class 死锁 {
private static final String lock1 = "lock1";
private static final String lock2 = "lock2";
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
while (true) {
synchronized (lock1) {
try {
System.out.println(Thread.currentThread().getName() + lock1);
Thread.sleep(1000);
synchronized (lock2){
System.out.println(Thread.currentThread().getName() + lock2);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
Thread thread2 = new Thread(() -> {
while (true) {
synchronized (lock2) {
try {
System.out.println(Thread.currentThread().getName() + lock2);
Thread.sleep(1000);
synchronized (lock1){
System.out.println(Thread.currentThread().getName() + lock1);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
thread1.start();
thread2.start();
}
}
1.程序运行,进程没有停止

2.通过jps查看java进程,找到没有停止的进程

3.通过jstack 9060 查看进程具体执行信息
🐓如何避免Java死锁
造成死锁的几个原因
1.一个资源每次只能被一个线程使用
2.一个线程在阻塞等待某个资源时,不释放已占有资源
3.一个线程已经获得的资源,在未使用完之前,不能被强行剥夺
4.若干线程形成头尾相接的循环等待资源关系
这是造成死锁必须要达到的4个条件,如果要避免死锁,只需要不满足其中某一个条件即可。而其中前3个条件是作为锁要符合的条件,所以要避免死锁就需要打破第4个条件,不出现循环等待锁的关系。
在开发过程中
1.要注意加锁顺序,保证每个线程按同样的顺序进行加锁
2.要注意加锁时限,可以针对锁设置一个超时时间
3.要注意死锁检查,这是一种预防机制,确保在第一时间发现死锁并进行解决
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 红包封面免费送1000个,你设计,我出额度
- OSG三维渲染引擎编程学习之一百:“第十一章:OSG粒子” 之 “11.1 粒子的主要模块”
- Qt6入门教程 2:Qt6下载与安装
- GB28181/GB35114平台LiveGBS何如添加白名单,使指定海康、大华、华为等GB28181摄像头或录像机设备可以免密接入
- java并发编程十三 线程池
- uni-app封装表格组件
- Android studio ViewPager2应用设计
- AI日报:扎克伯格瞄准AGI通用人工智能
- Wasmer运行.wasm文件的流程
- 取消paypal免密支付绑定平台