强强联合!DiffusionGPT : LLM驱动的统一文本到图像生成系统
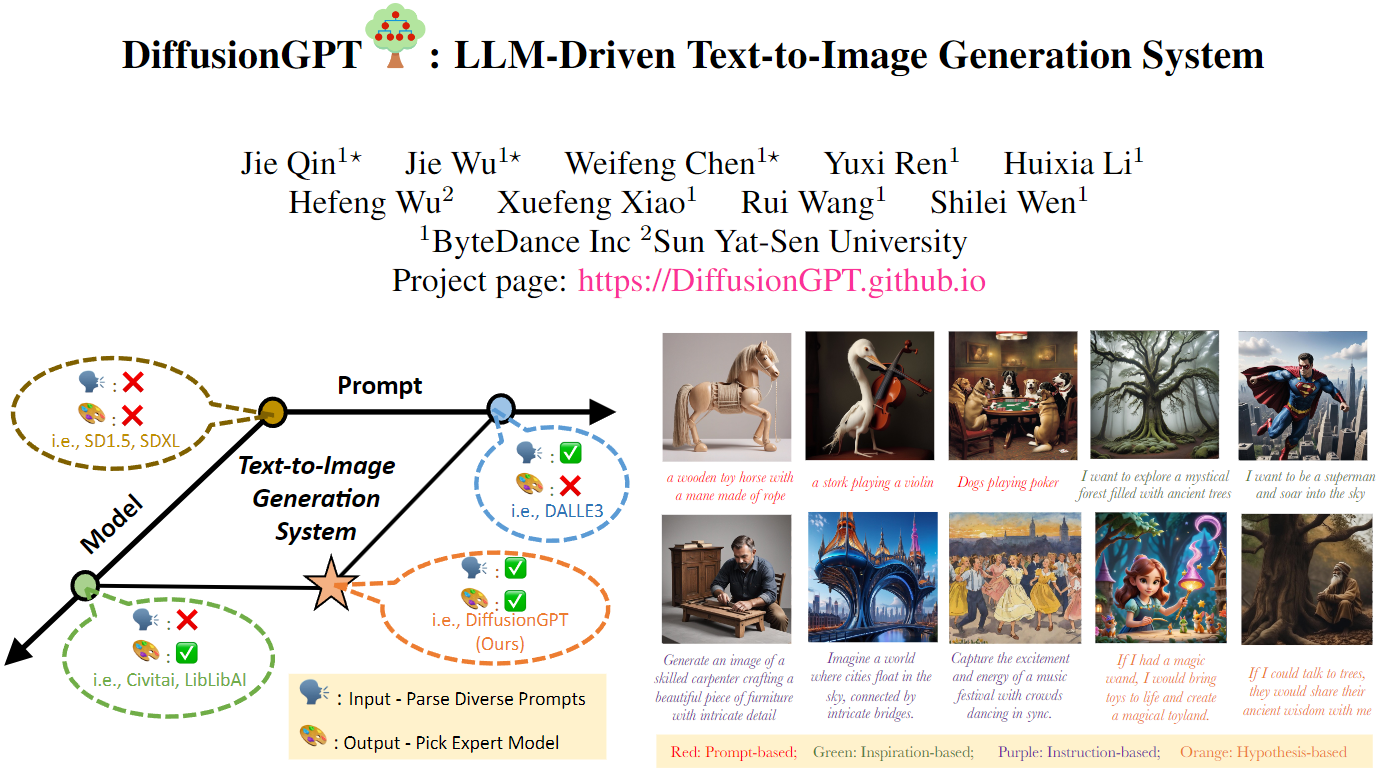
扩散模型已为图像生成领域开辟了新的途径,使得高质量模型在开源平台上得以广泛传播。然而,目前文本到图像系统面临的一个主要挑战是,它们通常无法处理多样化的输入,或者仅限于单一模型的结果。当前的统一尝试通常分为两个正交方面:
-
在输入阶段解析多样的提示;
-
激活专家模型进行输出。
为了结合两者的优势,提出了DiffusionGPT,它利用大语言模型(LLM)提供一个统一的生成系统,能够无缝地适应各种类型的提示并整合领域专家模型。DiffusionGPT根据先前的知识为各种生成模型构建领域特定的树。当提供输入时,LLM解析提示并利用思维树来指导选择合适的模型,从而放宽输入约束,确保在多样的领域中表现出色。此外引入了Advantage Databases,其中思维树通过人类反馈进行丰富,将模型选择过程与人类偏好对齐。通过广泛的实验证明了DiffusionGPT的有效性,展示了它在不同领域推动图像合成边界的潜力。
介绍
近年来,扩散模型在图像生成任务中普及,彻底改变了图像编辑、风格化和其他相关任务。DALLE-2和Imagen在从文本提示生成图像方面表现出色。然而,它们的非开源性质阻碍了广泛普及和相应的生态发展。第一个开源的文本到图像扩散模型被称为Stable Diffusion(SD),迅速赢得了广泛的关注和应用。为SD量身定制的各种技术,如Controlnet、Lora等,进一步为SD的发展铺平了道路,并促进了它在各种应用中的整合。SDXL是最新的图像生成模型,旨在提供具有复杂细节和艺术构图的卓越逼真输出。此外,SD的影响超越了技术层面。诸如Civitai、WebUI和LibLibAI等社区平台已经成为设计师和创作者之间进行讨论和合作的充满活力的中心。稳定扩散的能力演变、SD定制技术的进步以及蓬勃发展的社区平台为图像生成的进一步发展创造了激动人心和肥沃的土壤。
尽管取得了重大进展,但当前的稳定扩散模型在应用于现实场景时面临两个关键挑战:
-
模型限制:尽管稳定扩散(如SD1.5)表现出对各种提示的适应性,但在特定领域的性能较差。相反,领域特定模型(如SD1.5+Lora)在特定子领域内表现出色,但缺乏多功能性。
-
提示约束: 在进行稳定扩散的训练时,文本信息通常包括描述性语句,如字幕。然而,在利用这些模型时,我们会遇到各种提示类型,包括说明和启发。当前的生成模型难以针对这些多样的提示类型实现最佳的生成性能。
当前稳定扩散模型与实际应用之间的混合匹配通常表现为结果有限、泛化能力差,以及在实际实施中增加了难度。一系列研究工作已经探索解决这些挑战并弥合差距的方法。尽管SDXL在改善特定领域性能方面取得了显著进展,但在这方面取得最终性能仍然是困难的。其他方法涉及纳入提示工程技术或固定提示模板,以提高输入提示的质量并改善整体生成输出。尽管这些方法在缓解上述挑战方面表现出不同程度的成功,但它们并没有提供全面的解决方案。这引出了一个根本性的问题:我们是否可以创建一个统一的框架,以释放提示约束并激活相应的领域专家模型呢?
为了解决上述问题,我们提出了DiffusionGPT,它利用大语言模型(LLM)提供一种全能的生成系统,无缝集成优越的生成模型并有效解析各种提示。DiffusionGPT构建了一个“思维之树”(ToT)结构,该结构涵盖了基于先前知识和人类反馈的各种生成模型。当输入提示时,LLM首先解析提示,然后引导ToT识别最适合生成所需输出的模型。此外,引入了 Advantage Databases,其中ToT通过有价值的人类反馈进行丰富,使LLM的模型选择过程与人类偏好保持一致。
这项工作的贡献可以总结如下:
-
新洞见:DiffusionGPT利用大语言模型(LLM)驱动整个文本到图像生成系统。LLM充当认知引擎,处理各种输入并促进输出的专家选择。
-
一体化系统:DiffusionGPT通过与各种扩散模型兼容,提供了一种多功能且专业的解决方案。与现有方法只能处理描述性提示的限制不同,框架可以处理各种提示类型,扩展了其适用性。
-
效率和开创性:DiffusionGPT以无需训练的特性脱颖而出,可以作为即插即用的解决方案轻松集成。通过引入“思维之树”(ToT)和人类反馈,系统实现了更高的准确性,并开创了一个灵活的流程,可以整合更多的专家。
-
高效性:DiffusionGPT优于传统的稳定扩散模型,展示了显著的进展。通过提供一体化系统,为图像生成领域社区发展提供了更高效、更有效的路径。
相关工作
基于文本的图像生成
最初,生成对抗网络(GANs)被广泛用作基于文本的图像生成的主要方法。然而,图像生成的格局发生了变化,扩散模型作为主导框架崭露头角,尤其是当与文本编码器(如CLIP和T5)集成时,实现了精确的文本条件图像生成。例如,DAELL-2利用CLIP的图像embedding,通过先前模型从CLIP的文本embedding中导出,生成高质量的图像。同样,Stable Diffusion直接从CLIP的文本embedding生成图像。另一方面,Imagen利用像T5这样的强大语言模型对文本提示进行编码,从而实现准确的图像生成。基于变压器的架构还展示了在从文本输入生成图像方面的功效。CogView2和Muse是这类模型的显著例子。为了使文本到图像扩散模型与人类偏好保持一致,最近的方法[1, 8, 24]提出使用奖励信号训练扩散模型。这确保生成的图像不仅符合质量标准,而且与人类意图和偏好密切一致。这些前沿方法旨在提高生成图像的保真度和相关性,以更好地满足用户需求。
用于视觉语言任务的大语言模型(LLMs)
随着大语言模型(LLMs)的出现,自然语言处理(NLP)领域发生了重大变革,这些模型在通过会话界面展现出卓越的人际交往能力。为了进一步增强LLMs的能力,引入了“思维链”(CoT)框架。该框架指导LLMs逐步生成答案,旨在获得更优越的最终答案。近期的研究通过将外部工具或模型与LLMs集成,探索了创新方法。例如,Toolformer通过API标签赋予LLMs访问外部工具的能力。Visual ChatGPT 和HuggingGPT通过使LLMs能够利用其他模型处理超越语言界限的复杂任务,扩展了LLMs的能力。类似地,Visual Programming和ViperGPT通过利用编程语言解析视觉query,发挥了LLMs在处理视觉对象方面的潜力。受到这些努力的启发,我们接受了将LLMs视为多功能工具的概念,并利用这一范式 将T2I模型引导到生成高质量图像的路径。
方法
DiffusionGPT是一个专门设计用于生成多样输入提示的高质量图像的一体化系统。其主要目标是解析输入提示并确定生成模型,以产生最优结果,即高泛化、高效用和方便。 DiffusionGPT由一个大语言模型(LLM)和来自开源社区的各种领域专家生成模型(例如Hugging Face、Civitai)组成。LLM扮演核心控制器的角色,维护系统的整个工作流程,包括四个步骤:提示解析、模型构建和搜索思维树、具有人类反馈的模型选择和生成的执行。DiffusionGPT的整体流程如下图2所示。
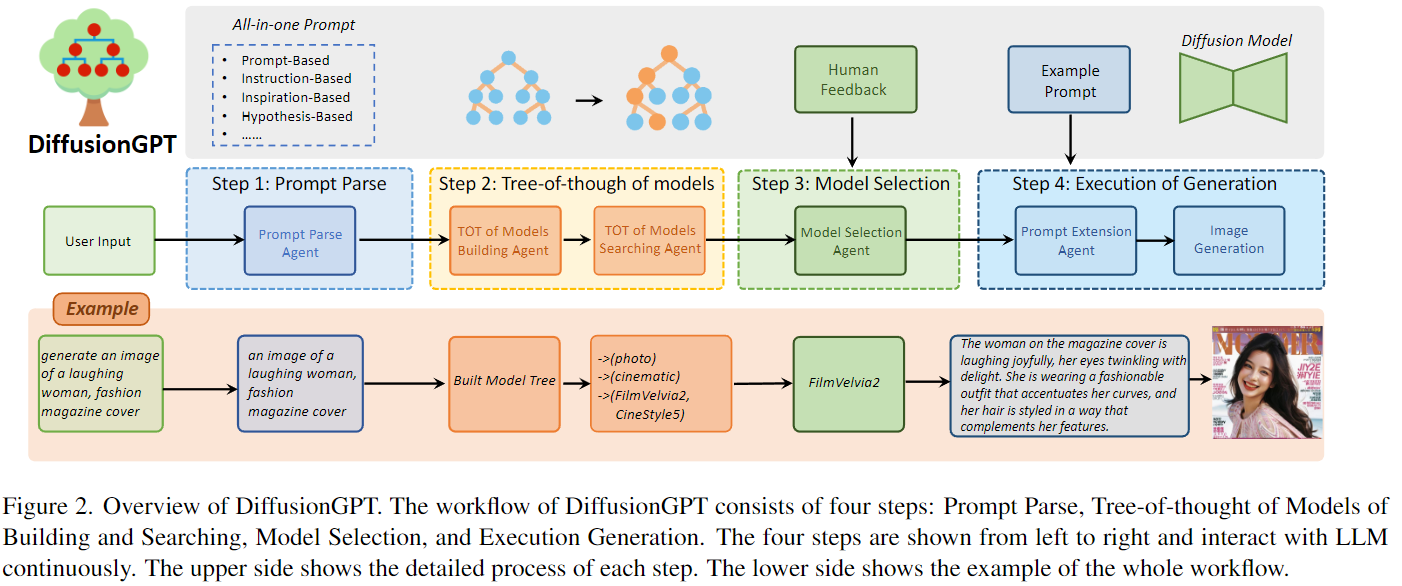
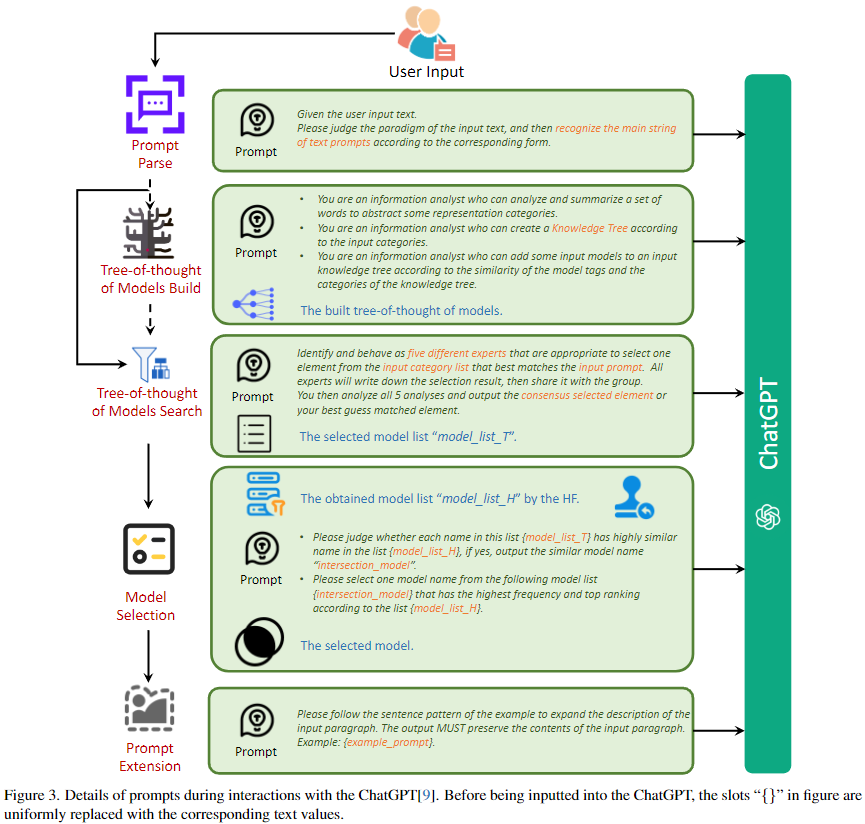
提示解析
提示解析 Agent(Prompt Parse Agent)在我们的方法中起着关键作用,因为它利用大语言模型(LLM)分析并提取输入提示中的显著文本信息。准确解析提示对于有效生成所需内容至关重要,考虑到用户输入的固有复杂性。此Agent适用于各种类型的提示,包括基于提示、基于指令、基于启发、基于假设等。 基于提示:整个输入被用作生成的提示。例如,如果输入是“一只狗”,则生成的提示将是“一只狗”。 基于指令:核心指令部分被提取为生成的提示。例如,如果输入是“生成一张狗的图片”,则识别出的提示将是“一张狗的图片”。 基于启发:欲望的目标主题被提取并用作生成的提示(例如,输入:“我想看到一个海滩”;识别出的提示:“一个海滩”)。 基于假设:涉及提取假设条件(“如果xxx,我将xxx”)和即将发生的动作的对象作为生成的提示。例如,如果输入是“如果你给我一个玩具,我会非常高兴地笑”,则识别出的提示将是“一个玩具和一个笑脸”。
通过识别这些形式的提示,Prompt Parse Agent使DiffusionGPT能够准确识别用户想要生成的核心内容,同时减轻嘈杂文本的影响。这一过程对于选择适当的生成模型并实现高质量的生成结果至关重要。
模型的思维之树
在提示解析阶段之后,接下来的步骤涉及从庞大的模型库中选择适当的生成模型以生成所需的图像。然而,考虑到可用的大量模型,同时将所有模型输入到大语言模型(LLM)进行选择是不切实际的。此外,由于不同的模型可能在其生成空间中表现出相似性,通过整个模型库进行单一模糊匹配准确识别最合适的模型变得具有挑战性。为了解决这个问题并确定最佳模型,我们提出利用基于“思维之树”(TOT)概念的模型树。通过利用模型树的搜索能力,可以缩小候选模型集合,并提高模型选择过程的准确性。
使用TOT构建模型树。Model Building Agent 使用“思维之树”(TOT)被用于根据所有模型的标签属性自动构建模型树。通过将所有模型的标签属性输入到Agent中,它分析并总结出源域和风格域的潜在类别。然后,将样式类别作为子类别纳入主题类别,建立一个两层次的层次结构。随后,根据它们的属性,将所有模型分配到适当的叶节点,从而完成全面的模型树结构。下图说明了模型树的可视化表示。 由于模型树是由Agent自动构建的,因此这种方法确保了方便地扩展性,以纳入新模型。每当添加新模型时,Agent都会根据其属性将它们无缝地放置在模型树中的适当位置。
使用TOT在模型树中进行搜索。 基于模型搜索Agent的模型树内的搜索过程旨在确定与给定提示密切匹配的一组候选模型。这种搜索方法采用广度优先的方法,系统地评估每个叶节点处的最佳子类别。在每个级别,将输入提示与类别进行比较,以确定表现最接近的类别。这个迭代过程继续为下一个叶节点导出候选集,并且搜索进行到达最终节点,其中获取候选模型的集合。这组候选模型作为后续阶段模型选择的基础。
模型选择
模型选择阶段旨在从先前阶段获得的候选集中确定最合适的模型,以生成所需的图像。这个候选集代表整个模型库的一个子集,由相对高匹配度的模型组成,与输入提示。然而,来自开源社区的有限属性信息在精确定义最佳模型同时向大语言模型(LLM)提供详细模型信息方面存在挑战。为了解决这个问题,我们提出了一个模型选择Agent,利用人类反馈并利用 Advantage Databases技术来使模型选择过程与人类偏好保持一致。
对于 Advantage Databases,采用了奖励模型来计算基于10,000个提示的语料库的所有模型生成结果的分数,并存储分数信息。在接收到输入提示后,计算输入提示与10,000个提示之间的语义相似性,识别与最高相似性的前5个提示。随后,模型选择Agent从离线数据库检索每个模型对这些提示的预计性能,并选择每个选择的提示的前5个模型。这个过程产生了一个5x5模型的候选集。
Agent然后将模型集与模型的TOT阶段获得的模型候选集相交,重点是具有更高出现概率和相对较高排名的模型。这些模型最终被选择为模型生成的最终选择。
生成的执行
一旦选择了最合适的模型,就会利用选择的生成模型来使用获取的核心提示生成所需的图像。
提示扩展。 为了增强生成过程中提示的质量,使用了一个Prompt Extension Agent来增强提示。该Agent利用所选模型的提示示例自动丰富输入提示。示例提示和输入提示都被发送到LLM,采用上下文学习范式。特别是,该Agent根据示例提示的句子模式向输入提示中添加了丰富的描述和详细的词汇。例如,如果输入提示是“一个笑着的女人的图像,时尚杂志封面”,示例提示是“女性头像的时尚摄影,穿着蓝色的丰富的外星人雨林,有花朵和鸟类,幻想,八达通渲染,hdr,杜比视觉,(复杂的细节,超详细:1.2),(自然的皮肤纹理,超现实主义,柔和的光线:1.2),蓬松的短发,锐利的焦点,夜晚,项链,中国神话,性感,中等的胸部,科幻头巾,看着观众,最高质量,完美的身体”,Prompt Extension Agent将其增强为更详细和富有表现力的形式,例如:“杂志封面上的女人正开心地笑着,她的眼睛闪烁着喜悦。她穿着一套突显曲线的时尚服装,她的头发造型使她的特征更加完美”。这种增强显著提高了生成的输出的质量。
实验
设置
在实验设置中,主要的大语言模型(LLM)控制器是ChatGPT,具体使用的是可通过OpenAI API访问的text-davinci-003版本。为了促使LLM响应的引导,采用了LangChain框架,该框架可以有效地控制和引导生成的输出。在我们实验中使用的生成模型中,选择了从Civitai和Hugging Face社区获取的各种模型。选择过程涉及选择这些平台上不同类型或风格的最受欢迎的模型。
定性结果
SD1.5版本的可视化
为了评估我们系统的有效性,通过与基准方法SD 1.5的生成性能进行比较,进行了全面的评估。SD 1.5是各种专业社区模型的基础模型。比较结果如下图4所示。对四种不同类型的提示进行了详细分析,并沿着两个关键维度进行了比较:语义对齐和图像美学。

在对结果进行仔细检查后,发现基准模型存在两个显着问题:
-
语义缺乏: 基准模型生成的图像仅对输入提示中提取的特定语义类别进行了有限的关注,导致未能完全捕捉整体语义信息。这一限制在所有类型的提示中特别明显,基准模型难以有效生成与“男人、厨师、孩子和玩具乐园”相关的对象。
-
人相关目标的表现差: 基准模型在为与人相关的对象生成准确的面部和身体细节方面面临困难,导致图像质量不佳。这一不足在比较描绘“女孩和夫妇”的图像的审美特性时变得明显。
相比之下,DiffusionGPT有效地解决了这些限制。我们系统生成的图像展现了相对完整的目标区域表示,成功捕捉了包含整个输入提示的语义信息。例如,“吹口哨弹钢琴的男人”和“一个雪花飞舞的奇妙世界,孩子们在那里堆雪人和打雪仗”的示例展示了我们系统涵盖更广泛上下文的能力。此外,我们的系统在为与人相关的对象生成更详细和准确的图像方面表现出色。这在提示“一个浪漫的情侣在星空下分享温馨时刻”中得到了体现。
SDXL版本的可视化。
随着公开可用的通用生成模型的进步,新改进的方法SD XL已经成为一种有前途的方法,展示出卓越的生成结果。为了进一步增强我们的系统,开发了一个升级版本,通过集成基于SD XL的各种开源社区模型。为了评估我们系统的性能,将其与SD XL进行了比较,如下图5所示。重要的是要注意,所有输出图像的分辨率均为1024x1024,为了进行比较,生成了四种不同类型的提示。仔细分析后,可以明显看出,SD XL在特定情况下偶尔会出现对语义信息的部分丢失。例如,在基于提示的类别中涉及“3D老虎”或在基于指令的类别中涉及“飞行汽车”的提示的生成结果可能缺乏准确的表示。相比之下,我们的系统在生成更精确和视觉上吸引人的表示方面表现出色。值得注意的例子包括生成“带有卡通猫的白色毛巾”和描绘“星空”的图像。

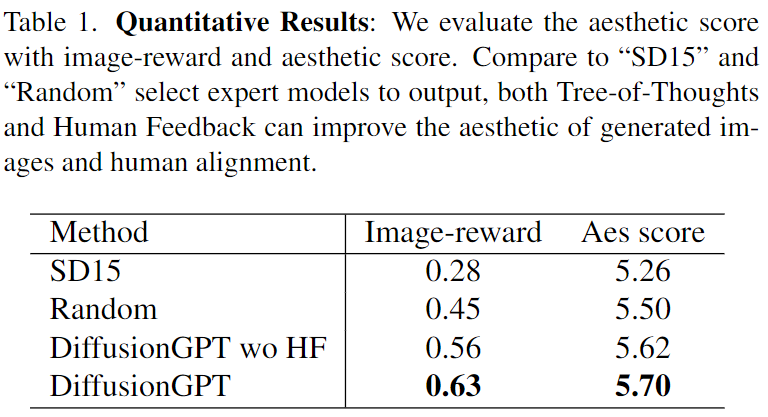
定量结果
用户偏好与下表1中呈现的定量结果之间的一致性为DiffusionGPT的健壮性和有效性提供了有力的证据。为了进一步评估不同的生成结果,使用了审美预测器和与人类反馈相关的奖励模型。通过将我们的基本版本与基准模型SD1.5的效果进行比较,表1中的结果表明我们的整体框架在图像奖励和审美评分方面优于SD1.5,分别实现了0.35%和0.44%的改进。
消融研究
思维树和人类反馈
为了验证设计的组件的有效性,对整合不同模块实现的性能进行了视觉分析,如下图8所示。图中标有“Random”的变体代表随机抽样模型。值得注意的是,随机选择模型生成了相当数量的与输入提示不符且缺乏语义一致性的图像。然而,随着逐渐将思维树(TOT)和人类反馈(HF)模块纳入系统,生成的图像质量显著提高。使用TOT和HF模块生成的图像展现了增强的真实感、与输入提示的语义对齐以及更高的审美吸引力。这种视觉分析展示了我们系统通过整合TOT和HF组件在选择卓越模型方面的优势。

提示扩展
为了评估提示扩展Agent的有效性,对使用原始提示和扩展提示生成的结果进行了比较,如下图9所示。扩展提示旨在为所需的图像提供更丰富和详细的描述。经过分析,观察到扩展提示在生成的图像的美学和细节水平上取得了显著的改善。在扩展提示中包含的额外信息允许生成更具吸引力和艺术性增强的图像。

用户研究
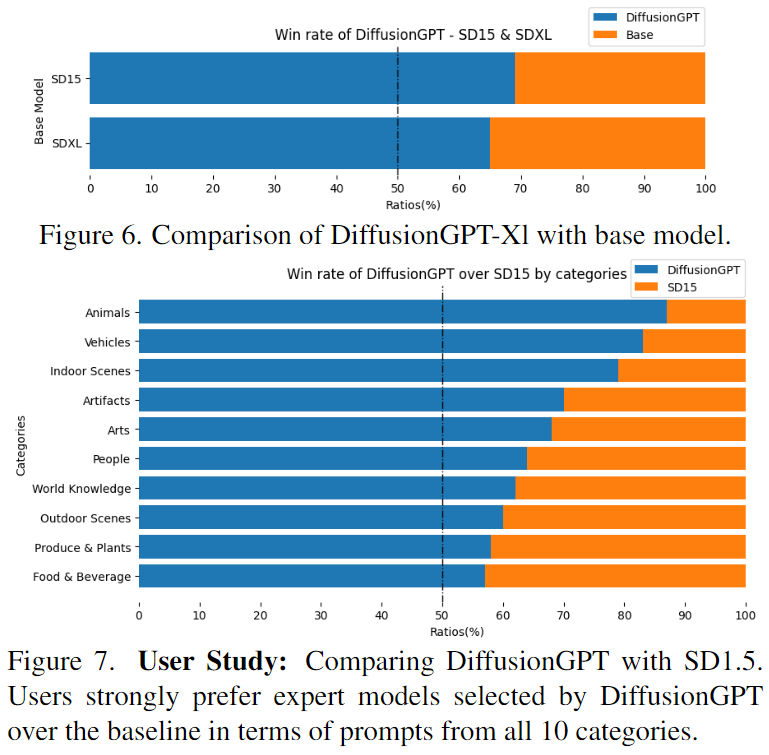
为了获取生成图像的真实人类喜好,进行了一项用户研究,将我们的模型与基准模型进行比较。使用了从PartiPrompts获取的图像标题,随机选择了100个提示,并为每个提示生成了四幅图像。随后,从20名用户那里收集了反馈,要求他们评价这些图像的优越性或相等性。这个过程为每个基准模型(SD1.5和SD XL)收集了大约400张选票。如下面的图7和图6所示,用户研究的结果一致地显示了对我们模型的明显偏好。用户一致地表达了对我们模型生成的图像的独特偏好,表明他们认为这些图像在质量或优越性方面相较于基准更高。
局限性和未来工作
尽管DiffusionGPT已经展示了生成高质量图像的能力,但仍存在一些限制,我们未来的计划如下: 反馈驱动的优化:我们旨在直接将反馈纳入LLM的优化过程中,实现更精细的提示解析和模型选择。 扩展模型候选者:为了丰富模型生成空间并取得更令人印象深刻的结果,我们将扩展可用模型的选择。 超越文本到图像任务:我们打算将我们的见解应用于更广泛的任务,包括可控生成、风格迁移、属性编辑等。
结论
Diffusion-GPT,一个全能框架,能够无缝集成优秀的生成模型并高效解析各种提示。通过利用大语言模型(LLMs),Diffusion-GPT深入了解输入提示的意图,并从思维树(ToT)结构中选择最合适的模型。该框架在不同的提示和领域中提供了多样性和卓越的性能,同时通过Advantage数据库引入了人类反馈。总的来说,Diffusion-GPT是一个无需训练,可以轻松集成为即插即用解决方案的系统,为这一领域的发展提供了一条高效而有效的途径。
参考文献
[1] DiffusionGPT : LLM-Driven Text-to-Image Generation System
代码链接:https://diffusiongpt.github.io/
更多精彩内容,请关注公众号:AI生成未来

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024程序猿面试八股文分享~
- docker部署Nacos
- tolua中table.remove怎么删除表中符合条件的数据
- 职场记7:冲破求职迷雾,踏入新的工作环境
- vue简单实现滚动条
- 司铭宇老师:家具导购销售培训:家具导购员销售技巧和话术
- 解决SQLServer访问*.mdf文件“报Unable open file Error5120“问题
- c++ map unordered_map 区别
- libbpf-tips
- QT-QML2048小游戏