Redis高级特性和应用(慢查询、Pipeline、事务、Lua)
Redis的慢查询
许多存储系统(例如 MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来,Redis也提供了类似的功能。
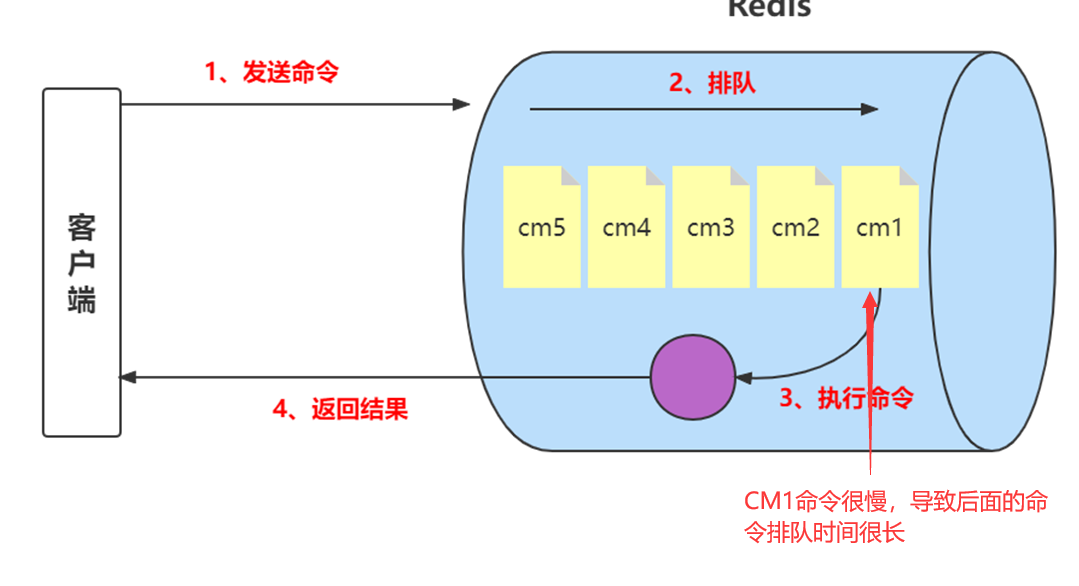
Redis客户端执行一条命令分为如下4个部分:

1、发送命令
2、命令排队
3、命令执行
4、返回结果
需要注意,慢查询只统计步骤3的时间,所以没有慢查询并不代表客户端没有超时问题。因为有可能是命令的网络问题或者是命令在Redis在排队,所以不是说命令执行很慢就说是慢查询,而有可能是网络的问题或者是Redis服务非常繁忙(队列等待长)。
慢查询配置
对于任何慢查询功能,需要明确两件事:多慢算慢,也就是预设阀值怎么设置?慢查询记录存放在哪?
Redis提供了两种方式进行慢查询的配置
1、动态设置
慢查询的阈值默认值是10毫秒
参数:slowlog-log-slower-than就是时间预设阀值,它的单位是微秒(1秒=1000毫秒=1 000 000微秒),默认值是10 000,假如执行了一条“很慢”的命令(例如keys *),如果它的执行时间超过了10 000微秒,也就是10毫秒,那么它将被记录在慢查询日志中。
我们通过动态命令修改
config set slowlog-log-slower-than 20000

使用config set完后,若想将配置持久化保存到Redis.conf,要执行config rewrite

config rewrite

注意:
如果配置slowlog-log-slower-than=0表示会记录所有的命令,slowlog-log-slower-than<0对于任何命令都不会进行记录。
2、配置文件设置(修改后需重启服务才生效)
打开Redis的配置文件redis.conf,就可以看到以下配置:

slowlog-max-len用来设置慢查询日志最多存储多少条

另外Redis还提供了slowlog-max-len配置来解决存储空间的问题。

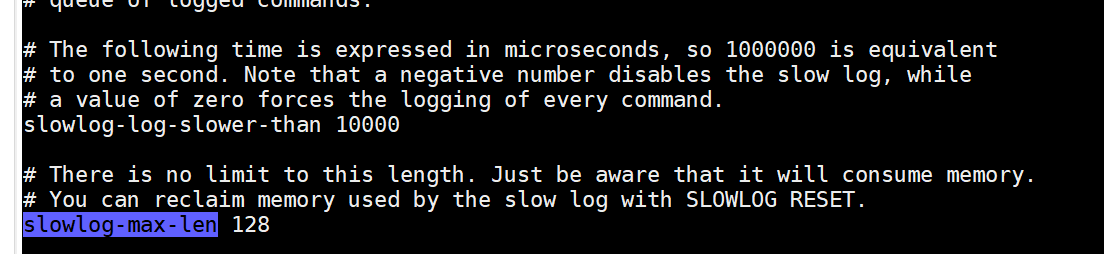
实际上Redis服务器将所有的慢查询日志保存在服务器状态的slowlog链表中(内存列表),slowlog-max-len就是列表的最大长度(默认128条)。当慢查询日志列表被填满后,新的慢查询命令则会继续入队,队列中的第一条数据机会出列。
虽然慢查询日志是存放在Redis内存列表中的,但是Redis并没有告诉我们这里列表是什么,而是通过一组命令来实现对慢查询日志的访问和管理。并没有说明存放在哪。这个怎么办呢?Redis提供了一些列的慢查询操作命令让我们可以方便的操作。
慢查询操作命令
获取慢查询日志
slowlog get [n]
参数n可以指定查询条数。
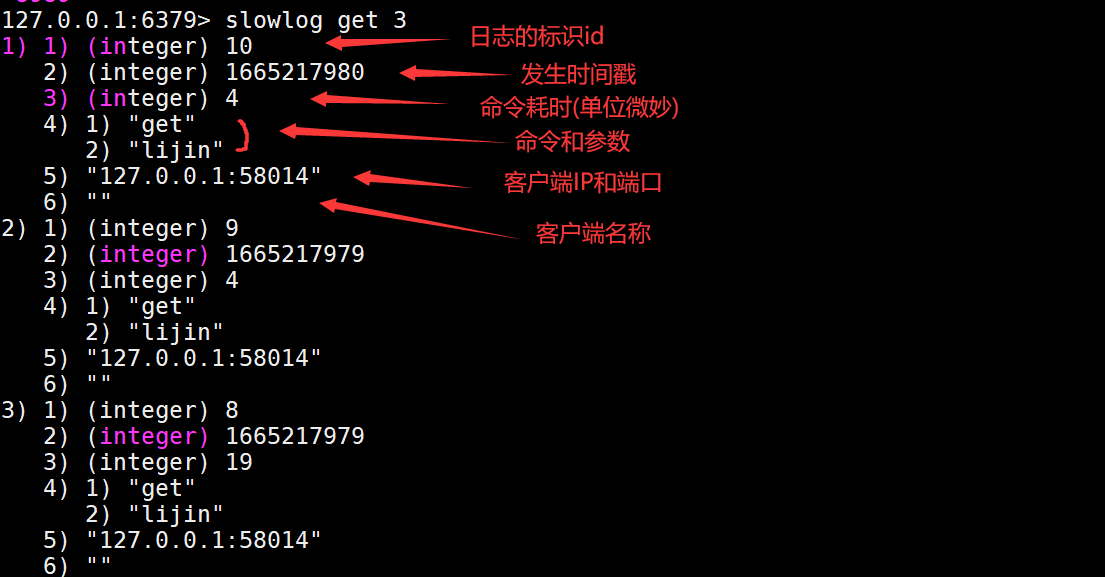
可以看到每个慢查询日志有6个属性组成,分别是慢查询日志的标识id、发生时间戳、命令耗时(单位微秒)、执行命令和参数,客户端IP+端口和客户端名称。
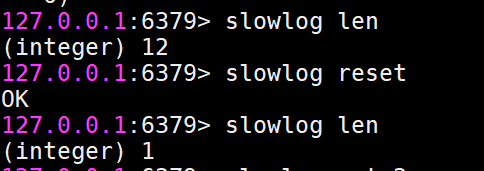
获取慢查询日志列表当前的长度
slowlog len

慢查询日志重置
slowlog reset
实际是对列表做清理操作
慢查询建议
慢查询功能可以有效地帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
slowlog-max-len配置建议:
建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔除的可能,线上生产建议设置为1000以上。
slowlog-log-slower-than配置建议:配置建议:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。
由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑OPS不到1000。因此对于高OPS场景的Redis建议设置为1毫秒或者更低比如100微秒。
慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行slow get命令将慢查询日志持久化到其他存储中。
Pipeline
前面我们已经说过,Redis客户端执行一条命令分为如下4个部分:1)发送命令2)命令排队3)命令执行4)返回结果。

其中1和4花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
但大部分命令是不支持批量操作的,例如要执行n次 hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地,Redis服务器在阿里云的广州,两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端,没有使用Pipeline执行了n条命令,整个过程需要n次RTT。
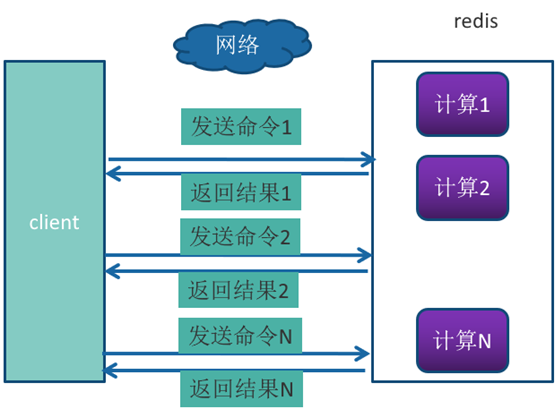
使用
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!