堆的应用:堆排序和TOP-K问题
发布时间:2024年01月01日
上次才讲完堆的相关问题:二叉树顺序结构与堆的概念及性质(c语言实现堆
那今天就接着来进行堆的主要两方面的应用:堆排序和TOP-K问题
1.堆排序
1.1概念、思路及代码
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
- 建立堆
- 升序:建立大堆
- 降序:建立小堆
- 利用堆删除思想来进行排序:堆顶元素是当前堆中的最大值(大堆)或最小值(小堆),将堆顶元素与堆中最后一个元素交换,然后将剩余元素重新调整成堆,再取出堆顶元素。重复上述步骤,直到所有元素都被取出,即完成了排序
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustUp(HPDataType* a, int child)
{
int father = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[father])
{
Swap(&a[child], &a[father]);
//更新下标
child = father;
father = (father - 1) / 2;
}
else
{
break;//一旦符合小堆了,就直接退出
}
}
}
void AdjustDown(HPDataType* a, int n, int father)
{
int child = father * 2 + 1;//假设左孩子大
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child++;
}
if (a[child] > a[father])
{
Swap(&a[child], &a[father]);
father = child;
child = father * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* arr, int n)//升序
{
//先建大堆
for (int i = 0; i < n; i++)
{
AdjustUp(arr, i);
}
int a = n - 1;
while (a > 0)
{
//此时最大的是堆顶,堆顶跟最后一个交换
Swap(&arr[0], &arr[a]);
//现在最大的已经在最后了,不考虑它,把新塔顶降下来,重新编程大堆
AdjustDown(arr, a, 0);
a--;
}
}
int main()
{
int arr[]= { 4,6,2,1,5,8,2,9 };
for (int i = 0; i < sizeof(arr) / sizeof(int); i++)
{
printf("%d ", arr[i]);
}
printf("\n");
HeapSort(arr, sizeof(arr) / sizeof(int));
for (int i = 0; i < sizeof(arr) / sizeof(int); i++)
{
printf("%d ", arr[i]);
}
}
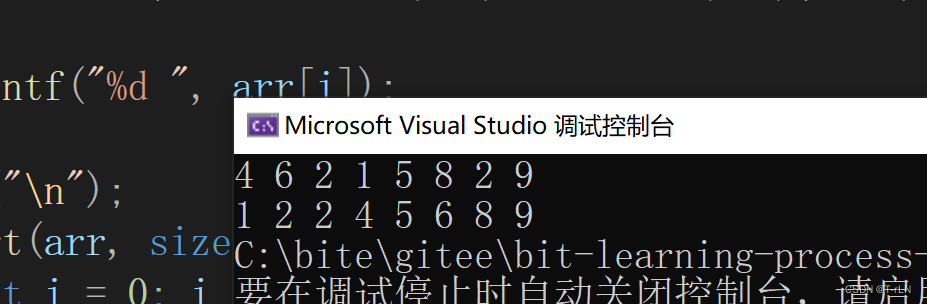
结果:
1.2改良代码(最初建立大堆用AdjustDow)
仅仅该那一部分:
void HeapSort(int* arr, int n)//升序
{
//先建大堆
//for (int i = 0; i < n; i++)
//{
// AdjustUp(arr, i);
//}
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, n, i);
}
int a = n - 1;
while (a > 0)
{
//此时最大的是堆顶,堆顶跟最后一个交换
Swap(&arr[0], &arr[a]);
//现在最大的已经在最后了,不考虑它,把新塔顶降下来,重新编程大堆
AdjustDown(arr, a, 0);
a--;
}
}
对于一个具有n个节点的完全二叉树来说,最后一个非叶子节点的下标是(n-1-1)/2,也就是说,从最后一个非叶子节点开始,依次向上调整每个节点,就可以建立一个大堆
相比于向上调整,向下调整的好处:时间复杂度低
- 向下调整的时间复杂度是O(n),而向上调整的时间复杂度是O(nlogn)
建堆的时间复杂度为 O(n),排序过程的时间复杂度为 O(n log n)(建堆的时间复杂度为 O(n),而对堆进行排序的过程中,需要进行 n-1 次堆调整操作,每次堆调整的时间复杂度为 O(log n)。因此,排序过程的时间复杂度为 O(n log n))
2. TOP-K问题
TOP-K问题:求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大
对于Top-K问题,能想到的最简单直接的方式就是排序,然后直接取。 但是:如果数据量非常大,排序就不 太可取了,最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆
- 要找前k个最大的元素,则建小堆
- 要找前k个最小的元素,则建大堆
- 用剩余的元素依次与堆顶元素来比较,不满足则替换堆顶元素:
- 要找前k个最大的元素:但凡剩余的有比小堆堆顶大的就进入到堆里面,然后向下沉;如果建立大堆有可能一个都进不来。
- 找前k个最小的也同理
void CreateData()//用来创建有随机数的文件的进行检测
{
int N = 1000;
srand(time(0));
FILE* f = fopen("data.txt", "w");
for (int i = 0; i < N; i++)
{
int a = (rand()) % 10000;
fprintf(f,"%d\n", a);
}
fclose(f);
}
void PrintTopK(int k)//前k个大的
{
//先读文件
FILE* fout = fopen("data.txt", "r");
if (fout == NULL)
{
perror("fopen file");
return -1;
}
int* a = (int*)malloc(sizeof(int) * k);
for (int i = 0; i < k; i++)//建立元素k的小堆
{
fscanf(fout, "%d", &a[i]);//把文件里的前k个数字写入数组里
AdjustUp(a, k);
}
//如果有比堆顶大的,就进来
int n = 0;
while (fscanf(fout, "%d", &n) != EOF)//读到文件读完就停止
{
if (n > a[0])
{
a[0] = n;
AdjustDown(a, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", a[i]);
}
printf("\n");
fclose(fout);
}
int main()
{
PrintTopK(5);
return 0;
}
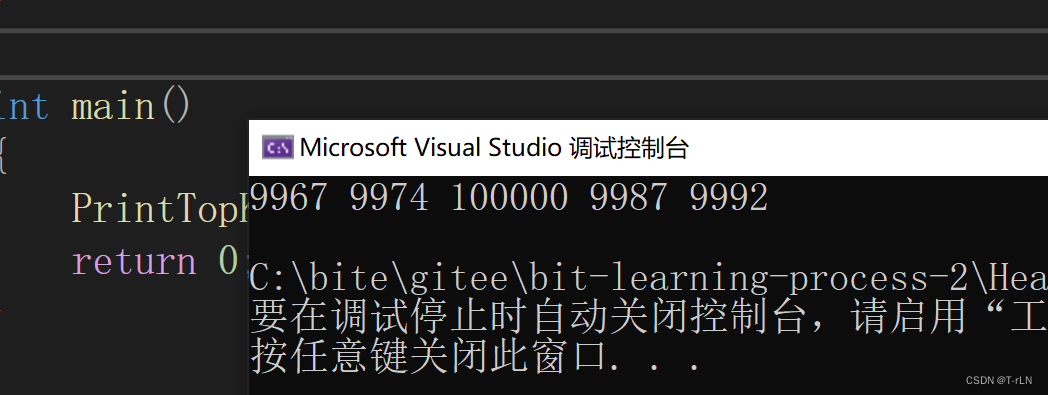
结果如下:
那这次堆的两大应用就先到这里啦,到此二叉树顺序结构部分的知识也已经分享完毕了。感谢大家的支持,希望能帮助到大家!!!
文章来源:https://blog.csdn.net/qq_74415153/article/details/135328335
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 03-搜索与图论python
- 摸底谷歌Gemini:CMU全面测评,Gemini Pro不敌GPT 3.5 Turbo
- LeeCode前端算法基础100题(21) 同构字符串
- ceph数据分布式存储
- 深入浅出:分布式、CAP 和 BASE 理论(荣耀典藏版)
- OpenStack云计算(-) 简介与部署Keystone
- jenkins error No space left on device
- git 命令
- Nacos注册中心
- Pandas实战100例 | 案例 56: 创建多重索引