[论文笔记] chatgpt系列 SparseMOE—GPT4的MOE结构
发布时间:2023年12月17日
SparseMOE: 稀疏激活的MOE
Swtich MOE,所有token要在K个专家网络中,选择一个专家网络。
显存增加。

Experts Choice:路由MOE:???????
由专家选择token。这样不同的专家都选择到某个token,也可以不选择该token。
由于FFN层的时间复杂度和attention层不同,FFN层的时间复杂度在O(N*d),N是输入长度,d是隐层纬度。attention层的时间复杂度在O(N^2*d)。
所以这样操作没能减小计算量。参数量也是多了几个Expert的参数量。
论文里的效果比SparseMOE更好。显存增加。
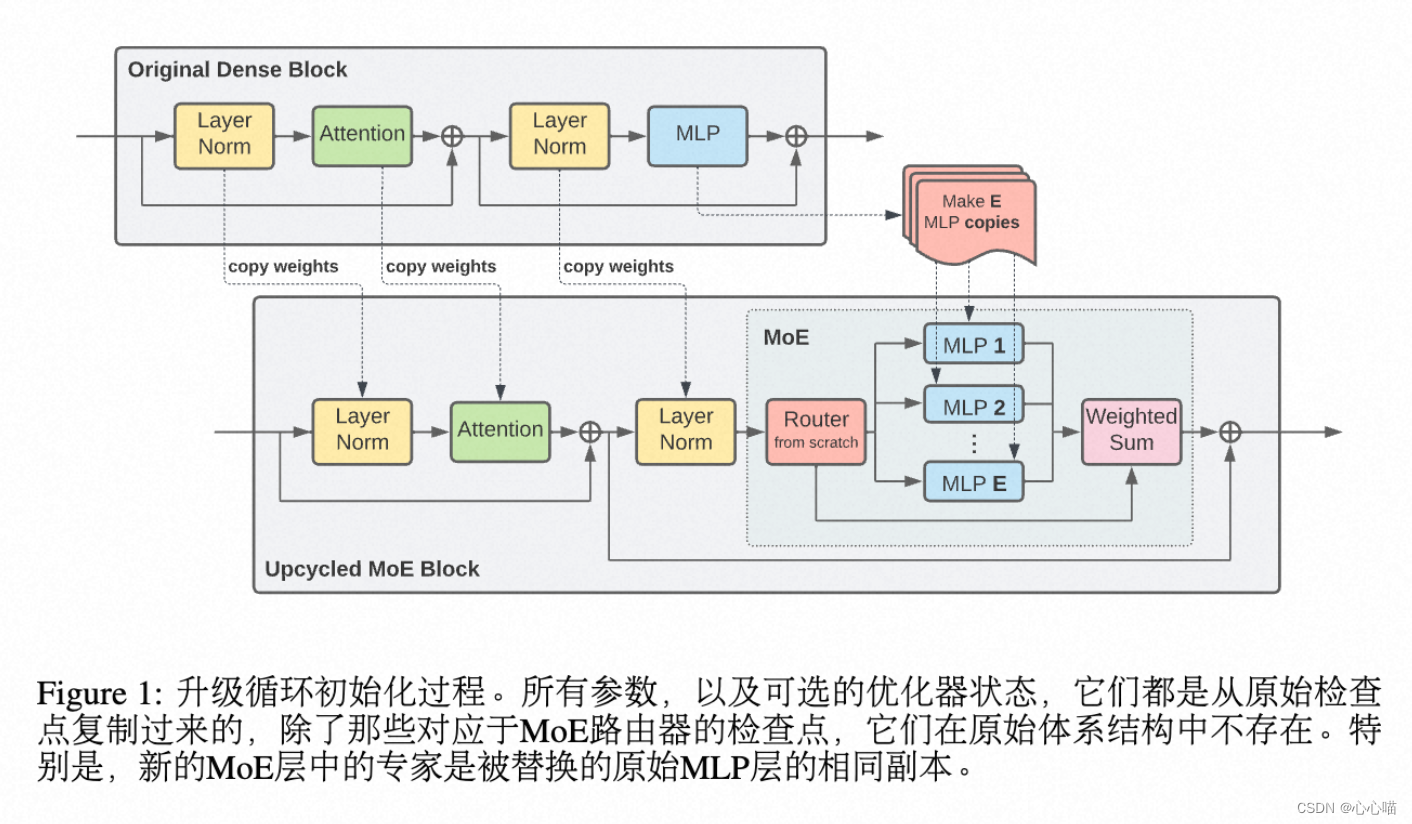
Tokens Choice:路由MOE:???????
由token选择专家。每个token只能进到一个专家里。没有t
文章来源:https://blog.csdn.net/Trance95/article/details/134998500
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Kotlin 尾递归函数
- 【Java基础篇】 try中return A,catch中return Bfinally中return C,最终返回值是什么?
- 排序算法(详解)
- 程序员超过30岁,如何做职业发展规划
- 华为OD机试 - 高效货运(Java & JS & Python & C)
- 【采药.】
- 渗透测试 | 信息收集常用方法合集
- 企业内部泄密风暴!内鬼盯上敏感信息,封堵计划全面开启!
- 缓存:系统设计中至关重要的一环
- vue自定义指令