AGI时代的奠基石:Agent+算力+大模型是构建AI未来的三驾马车吗?
?★AI Agent;人工智能体,RPA;大语言模型;prompt;Copilot;AGI;ChatGPT;LLM;AIGC;CoT;Cortex;Genius;MetaGPT;大模型;人工智能;通用人工智能;数据并行;模型并行;流水线并行;混合精度训练;梯度累积;Nvidia;A100;H100;A800;H800;L40s;混合专家;910B;HGX H20;L20 PCIe;L2 PCIe
AI Agent是一种智能实体,能够感知环境、决策并执行动作,具有独立思考和执行任务的能力。与传统大模型相比,AI Agent能够独立思考目标并采取行动,而不仅仅依赖于提示。AI Agent基于大模型,具备上下文学习、推理和思考的能力,因此是通往AGI(通用人工智能)的主要研究方向。
AI Agent由大模型、规划、记忆和工具使用四个部分组成,其中大模型是核心,提供推理和规划等能力。近期在AI Agent领域涌现出多个研究成果,包括在游戏、个人任务助理和情感陪伴方面表现优异的产品。虽然目前AI Agent研究主要集中在学术和开发者领域,商业化产品较少,但在企业环境中,AI Agent建立对某一垂直领域的认知的场景更为适合。一些初创公司已经在以企业级Agent平台为核心进行产品研发,未来几年内预计将有更多以Agent为核心的产品涌现。
当然,AI Agent的训练离不开算力,服务器作为一个强大的计算中心,为AI Agent提供算力基础,支持其进行复杂计算和处理大规模数据的任务,包括模型训练、推理和处理大规模数据集。
蓝海大脑大模型训练平台基于开放加速模组高速互联的AI加速器,提供强大的算力支持。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。
?
大模型引领前行:AI Agent自主智能体在AGI之路的探索
一、AI Agent:探索 AGI 的真实形态
1、什么是 AI Agent?
AI Agent是一种智能实体,具备感知环境、决策和执行动作的能力。与传统人工智能不同,AI Agent通过独立思考和调用工具逐步完成给定目标,实现自主操作。虽然AI Agent在人工智能和计算机领域成为研究热点,但由于数据和算力限制,实现真正智能的AI Agents仍面临挑战。

?Hyperwrite 研发的 AI Agent 个人助理插件实现自动预订航班机票
AI Agent与大语言模型和RPA的区别在于,具备独立思考和行动的能力,相较于大模型需要基于明确的prompt进行交互,而RPA则仅能在预设流程下工作。AI Agent的工作仅需目标就能独立思考并采取行动,拆解任务并根据反馈自主创建prompt。与RPA相比,AI Agent能处理未知信息和复杂环境,使其成为更灵活的自主智能体。

?AI Agent 的工作流程
2、AI?Agent 的最终发展目标:通用人工智能 AGI
AI Agent并非新概念,早在多年前已有研究,如2014年AlphaGo和2017年OpenAI Five。这些AI能通过实时信息分析规划操作,满足AI Agent基本定义。当时主要应用在具有对抗性和明显输赢场景的游戏中,采用强化学习进行训练。然而,通用性在真实世界中难以实现。
近年来,大语言模型的崛起推动AI Agent相关研究的快速发展。这些模型基于庞大的训练数据集,包括丰富的人类行为数据,为模拟类人交互提供坚实基础。大模型的快速发展使其具有上下文学习、推理和思维链等类似人类思考方式的能力,成为AI Agent的核心。
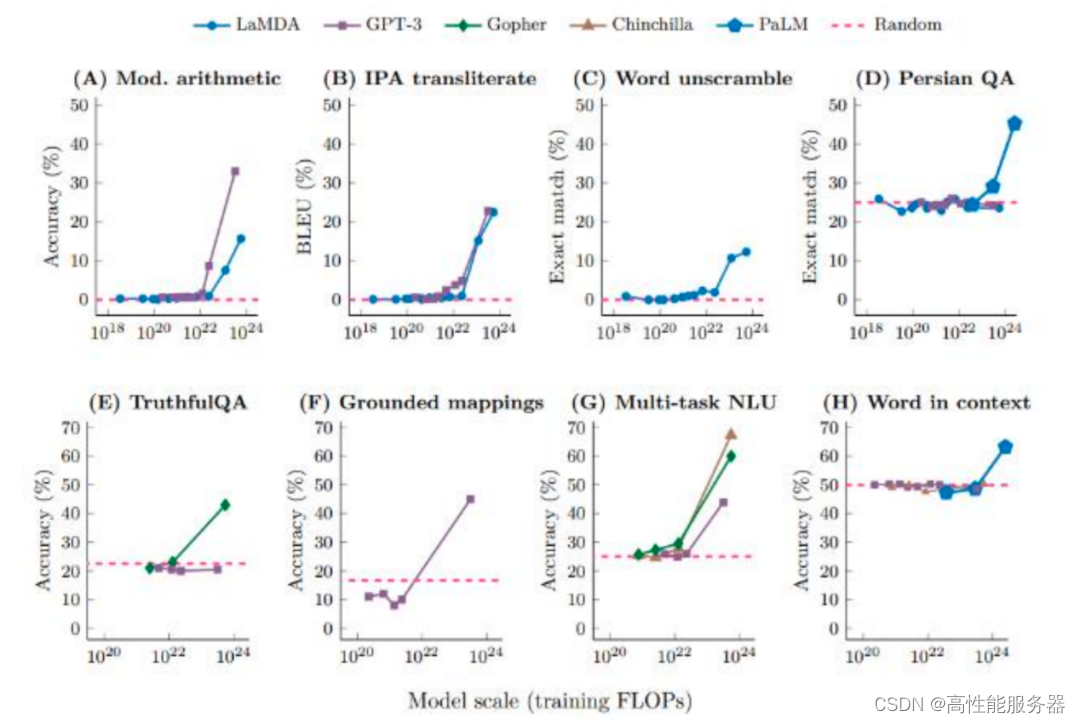
大模型的能力涌现现象
尽管大模型在全球范围内引起热潮,但随着时间推移,人们对大模型实际能力的认识更为清晰。大模型仍存在幻觉、上下文容量限制等。因此,AI Agent成为新的研究焦点。通过让大模型结合一个或多个Agent,构建具备自主思考、决策和执行能力的智能体,继续探索通往AGI之路。
研究 AI Agent 的最终目标是通向 AGI
AI Agent的发展可以类比为自动驾驶的L4阶段,尽管已取得一定进展,但距离真正的实现仍存在一定差距。据甲子光年报告,与人类的协作程度可以与自动驾驶的不同级别相媲美。对话机器人(如ChatGPT)可视为L2级别,人类向AI寻求意见,但AI不直接参与工作;副驾驶工具(如Copilot)相当于L3级别,人类和AI共同协作完成工作,AI生成初稿,人类进行修改;而AI Agent则相当于L4,人类给定目标,Agent自行完成任务规划和工具调用。然而,类似于L4级别的自动驾驶尚未真正实现,AI Agent虽易于想象和演示,但在真实应用中仍存在一定挑战,其真正的应用前景仍是未知。

?将 AI 和人类协作的程度类比自动驾驶的不同阶段
3、应用两大方向:自动化(自主智能体)、拟人化(智能体模拟)
AI Agent的发展在基于大语言模型(LLM)的应用中呈现出两大主要趋势:
1)自主智能体
这类AI Agent致力于实现复杂流程的自动化。当赋予自主智能体一个目标时,能够自主创建、执行、调整任务,并根据目标优先级不断重复这个过程,直至完成目标。由于对准确性要求较高,通常需要外部工具辅助,以减少大模型不确定性。
2)智能体模拟
这一类Agent致力于更加拟人和可信的表现。分为强调情感和情商的智能体,以及注重交互的智能体。后者通常在多智能体环境中操作,在预期之外展现出场景和能力。由于具备多样性的特点,使其能够充分利用大模型生成不确定性。
当然这两个方向并非完全独立,相反自动化和拟人化作为AI Agent的两大核心能力将同步发展。随着底层模型的不断成熟和对不同行业的深入探索,AI Agent的适用范围和实用性有望进一步扩大。

二、AI Agent 拆解:大模型、规划、记忆与工具
基于大型语言模型的AI Agent可分为四个主要组件:大型语言模型(LLM)、规划、记忆和工具使用。

由 LLM 驱动的自主智能体系统的架构
1、大模型+规划:Agent 的“大脑”,通过思维链能力实现任务分解
Agent可以有效引导和激发LLM的逻辑推理能力。当模型规模足够大时,LLM本身就具备推理能力,在简单推理问题上展现出良好的表现。然而,在处理复杂推理问题时,LLM有时可能会出现错误,导致用户无法获得理想回答。这主要是因为prompt不够合适,无法充分激发LLM的推理能力。通过追加辅助推理prompt,可以显著提高LLM在推理问题上的效果。在《Large language models are zero-shot reasoners》一文中的测试中,通过在提问时追加“Let’s think step by step”prompt,数学推理测试集GSM8K上的推理准确率从10.4%提升到40.7%。作为智能体Agent能够自主创建适当的prompt,更好地引发大型模型的推理能力。
?
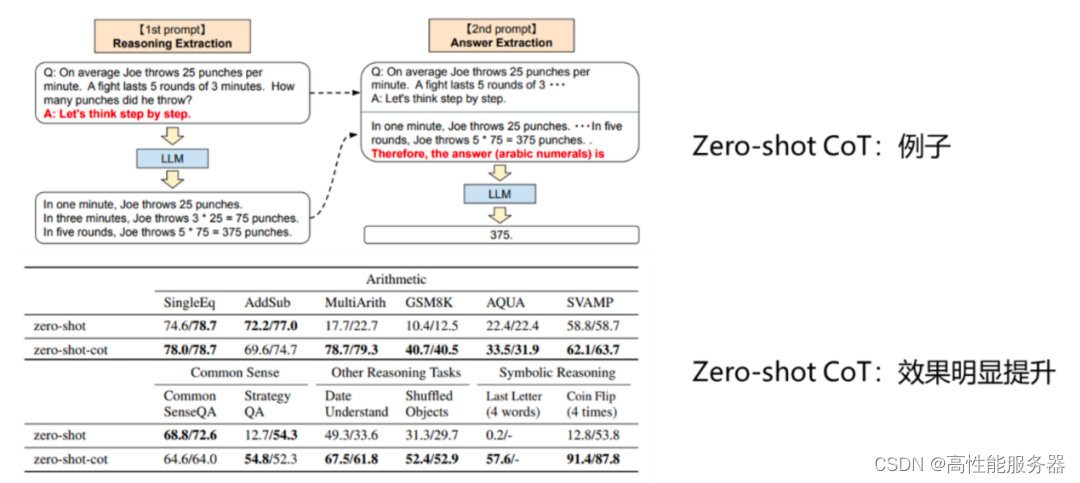
通过调整 prompt 可以提升大模型推理效果
在处理复杂任务时,Agent可以调用LLM的思维链进行任务分解和规划。在AI Agent架构中,任务分解和规划过程依赖于大模型能力。大模型具有思维链(CoT)能力,通过提示模型“逐步思考”,充分利用计算时间,将复杂任务逐步分解为更小、更简单的步骤,从而降低每个子任务难度。

AI Agent 的反思框架
通过反思与自省框架,Agent不断提升任务规划能力。其具有对过去行为的自我评估机制,从中学习并改进未来步骤,以提高最终结果质量。自省框架允许Agent修正决策和改正之前错误,实现性能不断优化。在任务执行中,尝试和错误是常态,而反思和自省在这个过程中发挥着核心作用。
2、记忆:用有限的上下文长度实现更多的记忆
AI智能体系统的输入成为系统记忆,与人类的记忆模式一一对应。记忆是获取、存储、保留和检索信息的过程,包括感觉记忆、短期记忆和长期记忆。对于AI Agent系统而言,与用户的交互生成内容被视为Agent的记忆。感觉记忆是学习嵌入表示的原始输入,包括文本、图像或其他模态;短期记忆是上下文受到有限上下文窗口长度限制;长期记忆可看作是Agent在工作中查询外部向量数据库,通过快速检索进行访问。目前,Agent主要利用外部长期记忆完成复杂任务,如阅读PDF、联网搜索实时新闻等。任务与结果存储在记忆模块中,当信息被调用时,存储在记忆中的信息将回到与用户的对话中,创造更加紧密的上下文环境。?
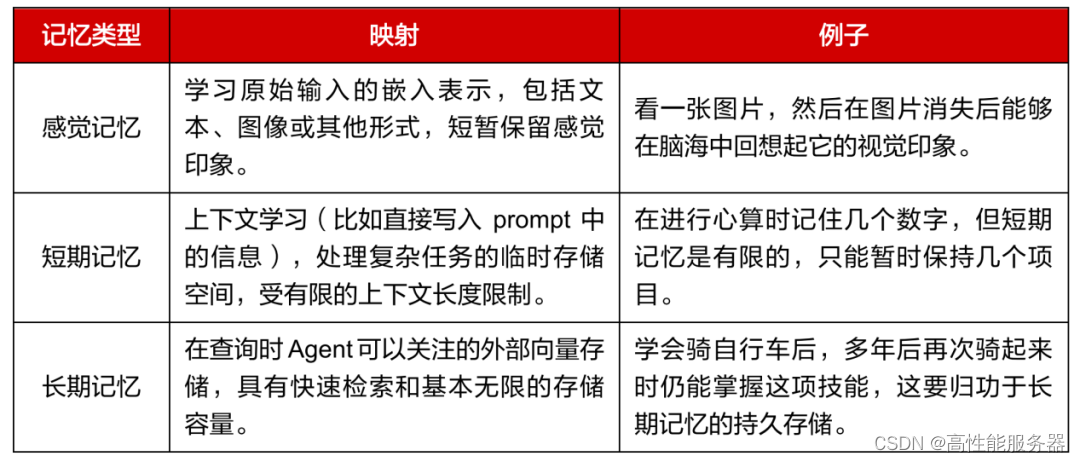
?人类记忆与 AI Agent 记忆映射
向量数据库通过将数据转化为向量形式,解决大模型海量知识存储、检索和匹配问题。向量成为AI理解世界的通用数据形式,而大模型为获取丰富语义和上下文信息需要庞大训练数据,导致数据量呈指数级增长。通过Embedding方法,向量数据库将非结构化数据如图像、音视频等抽象为多维向量,实现结构化管理,从而实现高效数据存储和检索过程,为Agent提供“长期记忆”。同时,将多模态数据映射到低维空间,大幅降低存储和计算成本,向量数据库存储成本较存储在神经网络中的成本低2到4个数量级。
Embedding技术将非结构化数据转化为计算机可识别的语言,如地图对地理信息的Embedding。通过Embedding技术,将文本等非结构化数据转化为向量后,使用数学方法计算两个向量之间的相似度,从而实现对文本的比较。向量数据库基于向量相似度计算实现强大的检索功能,通过相似性检索特性,找出近似匹配结果,为模糊匹配提供支持,适用于更广泛的应用场景。

不同文本在向量空间中的相似度计算
3、工具:懂得使用工具才会更像人类
AI Agent与大模型的一个显著区别在于,AI Agent能够利用外部工具拓展模型能力。与人类使用工具相似,为大模型配备外部工具,使其完成原本无法处理的任务。例如,ChatGPT的缺陷是其训练数据截止到2021年底,无法直接回答关于更新知识的问题。虽然OpenAI为ChatGPT添加插件功能,允许调用浏览器插件以获取最新信息,但仍需用户明确指定是否需要使用插件,不能实现完全自然回答。相比之下,AI Agent具备自主调用工具能力,对于每个子任务,Agent会判断是否需要调用外部工具来完成,并将外部工具返回信息提供给LLM,以继续下一步子任务。此外,OpenAI在6月为GPT-4和GPT-3.5引入函数调用功能,使开发者能够描述函数,并让模型智能地选择输出函数调用参数的JSON对象。

?GPT 模型函数调用功能示例
以HuggingGPT为例,将模型社区HuggingFace和ChatGPT紧密结合,构建成一个综合AI Agent。在2023年4月,浙江大学和微软联合团队推出HuggingGPT,这一系统能够连接不同的AI模型来解决用户提出的各种任务。HuggingGPT整合HuggingFace社区中的众多模型和GPT,可应对24种任务,包括文本分类、对象检测、语义分割、图像生成、问答、文本语音转换以及文本视频转换。其工作流程分为四步:
1)任务规划:通过使用ChatGPT获取用户的请求;
2)模型选择:基于HuggingFace中函数描述选择适当模型,并使用选中模型执行AI任务;
3)任务执行:执行由第2步选择模型完成的任务,将结果总结成回答返回给ChatGPT;
4)回答生成:利用ChatGPT整合所有模型推理,生成回答并返回给用户。
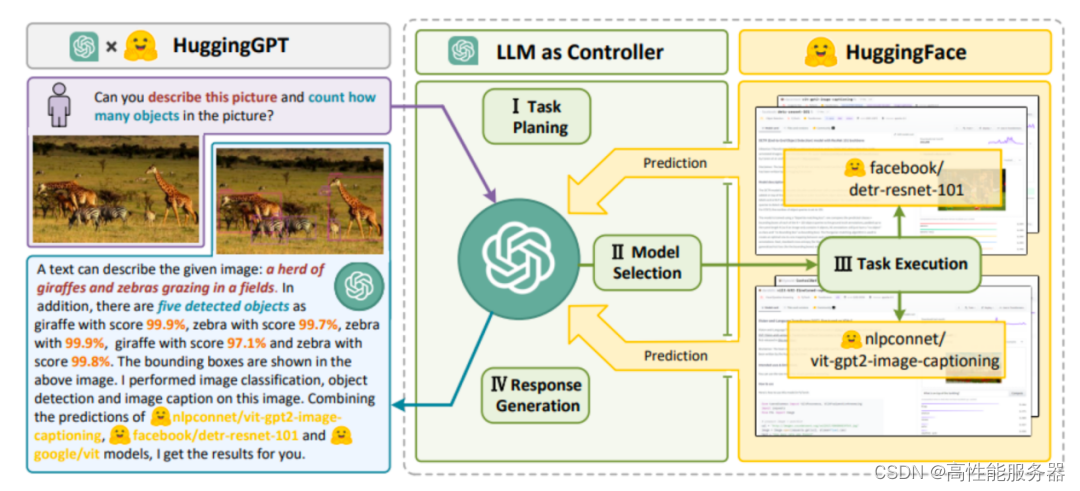
HuggingGPT 的工作步骤流程
AI Agent智探视野
应用领域深入剖析与龙头公司
一、自主智能体:自动化,新一轮生产力革命
1、软件新范式,非大模型玩家亦有机会
自主智能体力图实现复杂流程自动化,被类比为自动驾驶的L4阶段,在任务执行中不仅能够减轻人类负担,还需外部辅助和监督。这一新型智能体有望引发软件行业的交互方式和商业模式变革。交互方式方面,Agent决策、规划、执行等环节要更深刻理解用户需求,需要设计更智能架构解决问题。商业模式上,服务内容收费可能会向按token收费转变,对Agent功能实用性提出更高要求。虽然基座大模型能力重要,但在实际应用中,自主智能体架构设计、工程能力、垂类数据质量同样至关重要。在企业应用中,准确度和效率是关键指标,同时也存在对低门槛定制Agent的需求。
2、实验性 VS 实操性,单智能体 VS 多智能体
行业内对自主智能体的探索可分为实验性VS实操性、单智能体VS多智能体两大类。实验性项目如AutoGPT虽可能在运行中出错,但对开发者提供创意、思路和经验的启发。实操性应用更注重与实际场景的适配。在单智能体和多智能体之间,单智能体适用于简单任务,在C端应用上有潜力,但在B端场景中面临评估不足、任务繁重和大模型幻觉等挑战,而多智能体在解决复杂工作上具有更突出优势。

1)单智能体1?:实验性项目
-
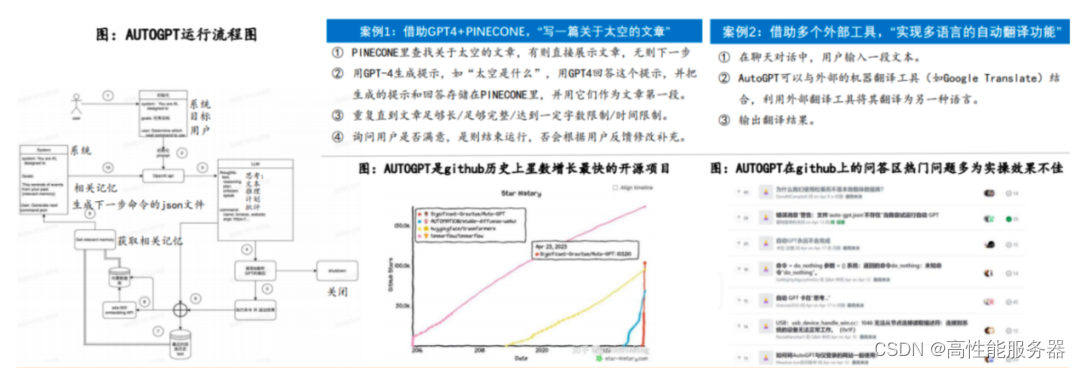
AutoGPT
AutoGPT是由游戏开发者Toran Bruce Richards于2023年3月开源的实验性AI Agent项目。该项目在GitHub上线5个月,星标数量已超过149K,成为代表性实验性项目,对后续Agent发展有启发意义。AutoGPT可以根据用户目标自动生成提示,利用GPT-4和多种工具API执行多步骤项目,无需人类干预。使用多个外部工具,包括克隆GitHub仓库、启动其他Agent、发言、发送推文和生成图片等,同时支持各种矢量数据库、LLM提供商、文本到图片模型和浏览器。该项目应用场景主要涉及办公和开发领域,包括自动化流程、市场研究、代码编写和网站/App开发等,但实际效果一般。
-
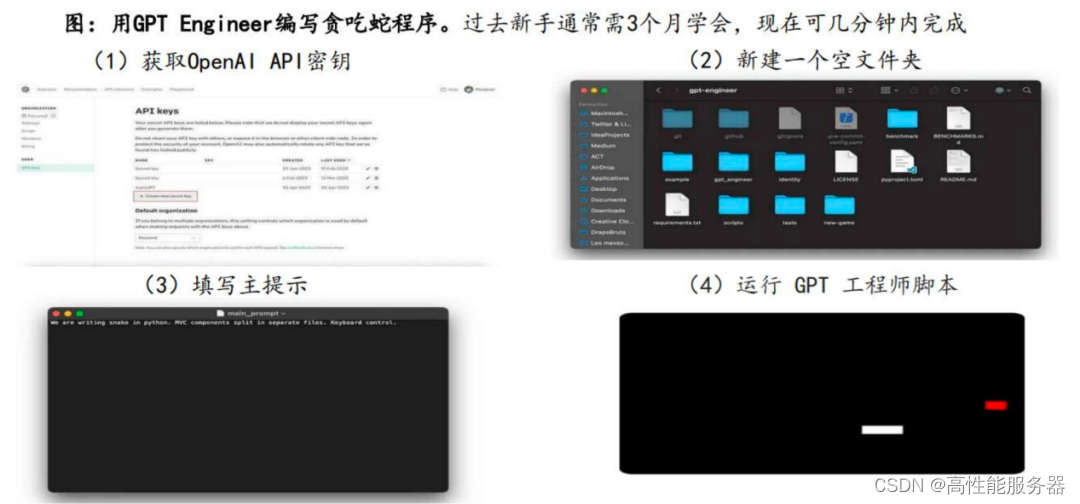
代码开发类 GPT?Engineer
GPT Engineer是由Anton Osika于6月11日推出的开源代码生成工具,基于GPT模型,根据用户的指示生成高质量代码,包括创建新函数、修复代码错误等,支持多种编程语言。截至2023年9月,其在GitHub上的星星数量接近44k。
-
科研类 GPT Researcher
GPT Researcher是哥伦比亚大学研究团队推出的网络科研任务专用的AI Agent项目,致力于生成详尽、精确和客观的研究报告。该项目已在GitHub上开源,截至2023年9月,星星数量超过4k。
GPT Researcher生成一系列研究问题,通过网络爬虫Agent从在线资源中收集与任务相关信息。每个获取资源都会被概括,并追踪其来源。当然所有资源都会被筛选、汇总,形成一份完整的研究报告。
?

-
创作类 ShortGPT
ShortGPT 可实现自动编辑框架、编辑脚本和提、创建配音/内容、生成字幕、从互联网上获取图像和视频片段等功能,并根据需要与网络和 Pexels API 连接;确保使用 TinyDB 自动编辑变量的长期持久性等功能。

2)单智能体 2:实现交互变革,中心化应用
-
功能升级后的 ChatGPT
ChatGPT在2023年经历多项功能增强:
- 增加近900个插件,覆盖多个领域,但每次最多只能启动3个插件。
- 推出高级数据分析功能,允许编写和执行Python代码,并能处理文件上传,提高处理复杂任务和数学推理准确度。
- 自定义指令功能允许用户预设身份和指令,提高ChatGPT的个性化水平。
- 9月引入多模态输入,支持语音对话和图像输入,降低使用门槛,使其更具广泛应用性。
- 企业版本提供更多功能和支持,有望推动ChatGPT在B端应用和商业领域的发展。
-
Adept AI
AI初创公司Adept于2022年9月发布大型行动模型ACT-1。ACT-1以桌面对话框形式存在,用户通过自然语言与其进行交互,改变过去鼠标/键盘的操作方式。用户可通过在文本框中输入命令,在电脑上随时调用ACT-1,一步步完成操作,并在需要时跨多个工具进行协调。用户可以即时反馈和修改错误。使用示例包括在Google Sheet中创建损益栏、更新收入总值、添加新产品和联系人,以及在交易平台上寻找适合商品。

3)单智能体 3:实现交互变革,可定制、平台化
-
Cortex
Cortex是由Kinesys AI推出产品,允许用户在其私有数据上构建AI合作伙伴,提供按使用量计费的定制AI助手服务。Cortex整合多个大型模型并通过调用向量数据、实时联网搜索和API等方式增强专业领域的实用性。在同一公司内,Cortex根据不同业务部门的需求,输出适应每个人岗位关键点信息,实现个性化服务。Cortex的客户群体主要包括个人开发者和早期初创企业,旨在减少从调试开始的工作量。已有10多家付费用户和上千个个人用户。

-
MindOS
MindOS是心识宇宙发布的多功能AI Agent引擎和平台,用户能在短短3分钟内开发独特记忆、个性和专业知识的可定制Genius。平台提供1000多个具有性格和功能的预置Genius,其准确推断意图的准确率高达97%。功能包括Marketplace(分享和发现Genius)、Workflow(通过拖放和简单配置构建Genius)、Structured Memory(从对话中提取结构化信息),未来还将增加Deep Thinking(深度思考)、Self Learning(自主学习)和Teamwork(团队协作)等板块。

4)多智能体:AGENT 团队完成复杂开发任务
-
MetaGPT
MetaGPT是深度赋智于7月开源的多智能体框架,旨在帮助用户快速搭建虚拟公司。虚拟公司中的员工都是智能体,涵盖工程师、产品经理、架构师和项目经理等角色。用户只需输入简短需求,MetaGPT能输出整个软件公司的工作流程和详细的SOP,如创作故事、竞品分析等。
该框架包括基础组件层和协作层。基础组件层构建单个Agent操作和全系统信息交换所需的核心构件,包括环境、记忆、角色和工具。协作层在基础组件层之上建立,协调单个Agent协同解决复杂问题,实现知识共享和封装工作流程。知识共享允许Agent交换信息,而封装工作流则利用SOP将任务分解为易于管理的组件,确保符合总体目标。

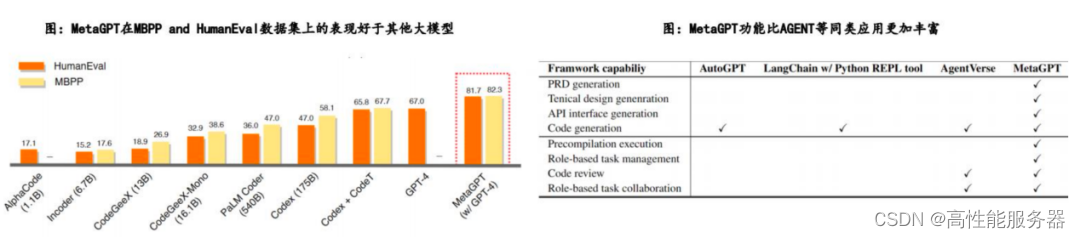
MetaGPT在横向对比中展现出较高的实操价值,在GitHub上开源两个月内获得超过24K的STAR数量。与大模型相比,MetaGPT基于GPT4-32k,利用4个Agent(工程师、产品经理、架构师、项目经理),在MBPP和HumanEval开源数据集上的单次尝试通过率明显优于其他代码生成LLM,包括GPT4和CODEX等。MetaGPT的独特之处在于其能够生成产品需求文档和技术设计,展示出在不同场景下具有更强通用性项目执行方法。实验证明,在低成本和低门槛下MetaGPT可以开发简易软件项目,平均每个项目消耗26.6k token用于prompt,完成任务后总成本为1.09美元耗时8-9分钟,远低于传统软件工程开发成本和时间。但MetaGPT偶尔会引用不存在资源文件,容易在执行复杂任务时调用未定义或未导入的类或变量,这些问题可以通过更清晰、更高效的AGENT协作工作流程来处理。
-
ChatDev
ChatDev是由清华大学NLP实验室孙茂松教授指导,与面壁智能、北京邮电大学、布朗大学研究人员联合发布全流程自动化软件开发框架。

ChatDev采用gpt3.5-turbo-16k版本ChatGPT API,从Camel指令跟随对话数据集中随机选择70个任务,作为CHATDEV软件开发分析基础。
该框架驱动智能体对话的关键机制包括:
- 角色专业化通过角色扮演确保每个智能体在专业角色下完成相应方案提议和决策讨论;
- 记忆流保存每轮对话记录以确保思路连贯性;
- 自反思当智能体未能满足要求时,生成一个“伪我”向instructor反馈问题和相关对话。

CHATDEV为软件开发提供一种高效、无需培训且具有成本效益新方法。与传统软件开发相比,CHATDEV平均生产时间不到7分钟,成本不到0.3美元,远低于传统软件开发费用和周期(通常需要数周或数月)。然而,在使用CHATDEV时提供更具体的说明可以更好地发挥其功能,尤其适用于中小型软件项目。

二、智能体模拟:拟人化,新的精神消费品
1、陪伴类,提供情绪价值
陪伴类智能体强调人类特征,包括情感情商和个性化"人格",具备记忆用户历史交流能力。随着大模型情商的不断迭代和多模态技术的发展,预计未来陪伴类智能体将更加立体拟人,能够提供更高情感价值。
当前,国内情感消费市场仍有巨大的发展空间,尤其在社会婚姻观念转变和现代工作生活紧张的情况下,人们对陪伴的需求不断增加。陪伴类智能体有望成为LLM时代的重要原生应用。从商业角度出发,预计陪伴类智能体的主要商业价值将集中在知名IP上。当前,那些拥有丰富IP储备或允许用户定制智能体的平台将在市场上有广阔前景。
具体而言,陪伴类智能体商业应用包括在线社交和秀场直播,但需要注意在线社交可能面临用户在建立情感联系后转向主流社交平台问题,而秀场直播用户价值可能更加集中在热门主播而非平台。
1)Inflection?AI:高情商个人 AI——Pi
Inflection AI推出名为Pi的个人AI产品于2023年5月正式上线。该初创公司成立于2022年估值已达40亿美元,仅次于OpenAI在人工智能领域的地位。Pi与ChatGPT有所不同,并非以专业性或替代人工方式进行宣传。Pi无法编写代码或生成原创内容,与通用聊天机器人不同,Pi专注于友好对话、提供简洁建议,甚至只是倾听。其主要特点包括富有同情心、谦虚好奇、幽默创新,具备较高的情商。Pi的定位是个人智能(Personal Intelligence),旨在提供个性化知识和陪伴,而非仅仅是辅助人工作的工具。

Inflection-1 可媲美 GPT-3.5 和 LLaMA(65B)
Pi的核心是Inflection AI开发的Inflection-1大模型其性能与GPT-3.5相当。Inflection-1在多任务语言理解和常识问题等方面表现略胜于GPT-3.5和LLaMA等常见大模型,但在代码方面稍显不足。然而,这正是公司的差异化竞争之处,因为Pi作为以情感陪伴为主的Agent,无需具备强大的代码和辅助工作能力。
与辅助工作的Agent不同,Pi更能满足情感陪伴需求。作为一个情商高的AI Agent,Pi能够使用更日常和生活化的语言与用户进行交流。Pi的回复贴近生活,语气得体,关心用户当前状态和事态发展,就像心理医生或最好的朋友一样。在回答可能涉及负面情绪问题时,Pi避免使用冒犯用户的俏皮表情或轻松口吻。甚至使用表情来增强对话人性化感觉,使用户感觉像在与真正的人类进行交流。此外,Pi还能记住与用户的对话,随着时间的推移更好地理解用户。Pi填补传统人工智能对人类情感需求忽视,类似于Pi这样提供情感陪伴的个人AI Agent在市场上具有巨大潜力。
2)平台化娱乐化,如 Character.AI、Glow 等
Character.AI成立于2021年10月,创始团队专注于深度学习、大型语言模型和对话领域,团队成员曾在Google Brain和Meta AI工作。在2022年9月推出Beta版本,采用GPT-3大模型,通过大量虚构人物数据进行训练,使聊天机器人能够根据人物的个性和特征生成对话和文本响应。据Character.AI官方透露,Beta版本推出2个月后,每天生成10亿个单词,截至2022年12月,用户已创建超过35万个机器人,涵盖信息检索、教练、教育、娱乐等多个领域。类似的产品还包括Replika、Glow等。

2、重交互,提高用户体验
交互智能体着重于强化与环境的互动能力,使智能体能够与其他智能体或虚拟世界内的事物进行实质性互动。这种能力可能导致超越设计者规划的场景和能力,尤其在开放世界游戏等领域,创造可信的智能体(主要是可信NPC)是为了赋予虚拟世界以生命的感觉。这些智能体能够做出决策并根据自己的意愿行动,从而创造出更真实的游戏体验,提升玩家的沉浸感,同时解决开放世界游戏中内容消耗过快的问题。随着可信智能体技术的成熟,可能会孕育出新的游戏品类,并在AIGC中扮演重要角色。
1)单智能体:游戏世界 AI 玩家,如 Voyager
Voyager是英伟达推出的首个大模型游戏智能体于2023年5月开源。该智能体在《我的世界》中应用,该游戏以无限可能性的虚拟世界而著称。没有预定的最终目标或故事情节。Voyager被设计成一个高效的终身学习Agent类似于人类玩家的能力,可以根据当前技能水平和世界状态发现适当的任务,并通过反馈学习和改进技能,持续探索世界。英伟达采用“无梯度”的训练方法,使基于GPT-4的Voyager在游戏中表现出色,独特物品增加3.3倍,行进距离增加2.3倍,解锁科技树里程碑的速度更是提高15.3倍。

?Voyager 玩游戏的水平相比之前的方法大幅提升
Voyager引入三个创新组件:自动课程、技能库和迭代prompt机制。自动课程设定开放性探索目标,由GPT-4生成,根据探索进度和Agent状态最大程度地实现探索。技能库存储有助于解决任务行动程序,使Voyager能够逐步建立起一个技能库,并随时间增强其能力,有效缓解“灾难性遗忘”问题。迭代prompt机制通过环境反馈、执行错误和自我验证来更新prompt,使GPT-4能够自主迭代,直到生成足够完成当前任务的prompt。
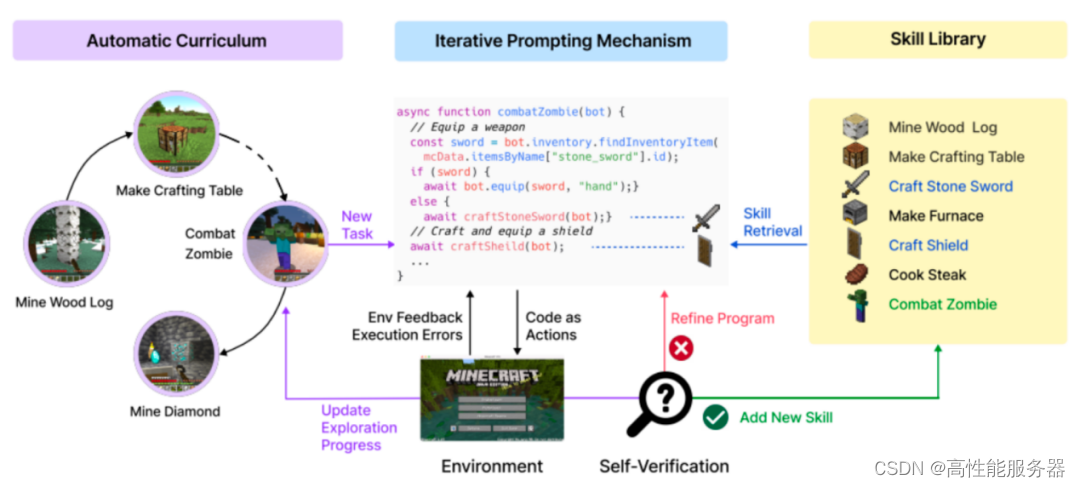
?Voyager由三大新型组件组成
Voyager在探索性能、科技树掌握速度和地图覆盖率等方面显著优于其他Agent框架,特别是在解锁科技树和拓展地图范围方面表现突出。然而,与此强大性能相比,Voyager的高昂成本成为一大制约因素。其使用GPT-4的代码生成能力导致成本居高不下。此外,存在“幻觉”问题,例如自动课程可能提出无法完成的任务。尽管如此,学界普遍认为Voyager是AI Agent领域的一项重大突破,使得实现真正的AGI更为接近。

?Voyager 的探索范围远大于其他 Agent 框架
2)多智能体:Smallville 小镇、网易《逆水寒》手游、昆仑万维《ClubKoala》虚拟世界
-
多智能体:Smallville 小镇,类西部世界的模拟社会
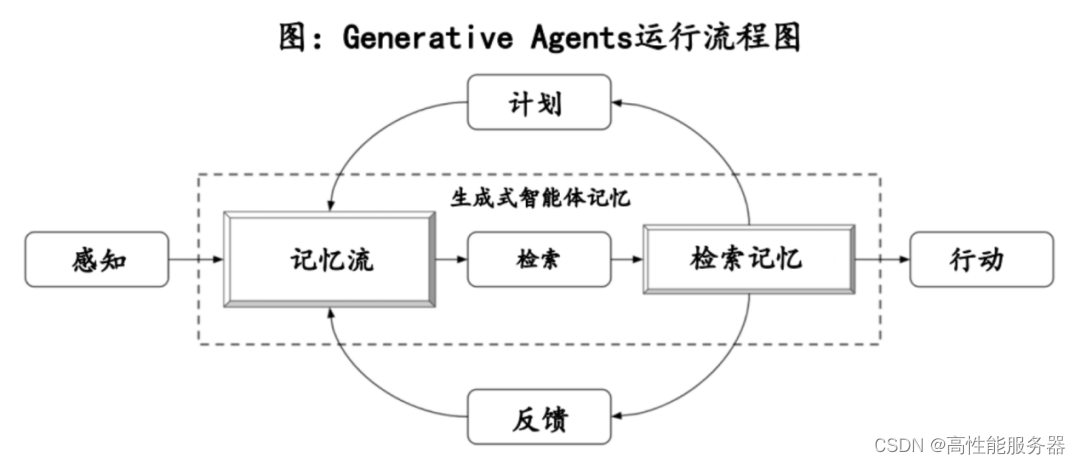
斯坦福大学研究者们在2023年4月首次创造一个虚拟的西部小镇,其中包含25个生成式AI代理,构成一个交互式沙盒环境。这些智能体展现出类似人类行为,如在公园散步、在咖啡馆喝咖啡,甚至规划举办情人节派对。这些Agent具有人类特质、独立决策和长期记忆等功能,被称为“原生AI Agent”。在这个虚拟环境中,这些Agent不仅服务于人类工具,还能够在数字世界中相互合作,建立社交关系。
在西部世界小镇的AI Agents架构中,记忆流是核心要素,包含三大基本要素:记忆、反思和规划。记忆流(MemoryStream)存储Agent的所有经历记录,每个观察包含事件描述、创建时间和最近访问的时间戳。检索过程考虑最近性、重要性和相关性三个因素,通过分数确定权重最高记忆,作为prompt传递给大模型,决定Agent下一步动作。
-
网易《逆水寒》手游,AINPC 提高玩家体验
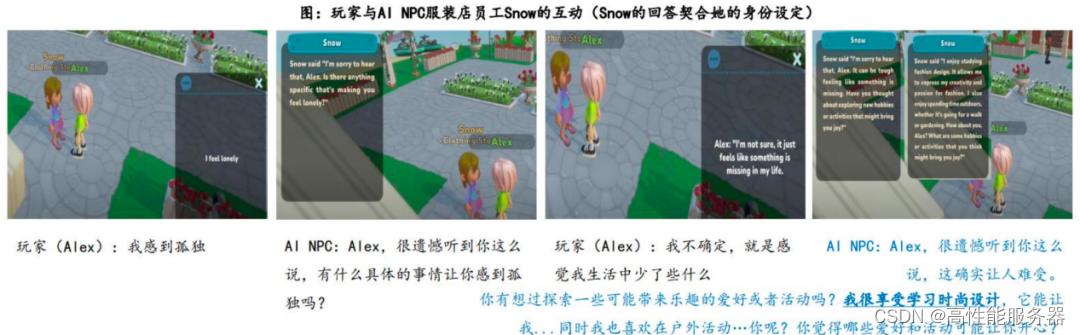
《逆水寒》手游于2023年6月30日上线,首日登顶iOS游戏免费榜,截至7月3日仍位居榜首。在iOS游戏畅销榜上,公测当天晚间跃升至第3名,次日晚上进一步升至第2名。游戏引入百位AI?NPC,这些NPC不仅与玩家互动自如,还具有记忆功能,极大增加游戏的趣味性。AI?NPC提供丰富的探索剧情,使游戏内容更加丰富多彩。通过与NPC互动,玩家可以深入了解游戏世界,获取宝贵信息,例如了解boss的弱点。此外,NPC之间的关系网还能帮助玩家巧妙解决难题。
?

-
昆仑万维《ClubKoala》虚拟世界更可信
引入AI NPC,赋予虚拟世界更真实的体验。采用Play for Fun的Atom AI系统,每个AI NPC都具备独特的性格和行为模式,自主安排日程并相互影响。加入记忆系统后,AI NPC能够记住与玩家的互动,根据玩家行为调整自身,展现出逐渐发展的“自我意识”,实现更自然、真实的动作和对话。与AI NPC的互动将被NPC牢记,分析玩家行为并在后续互动中反映,构建真正的玩家与NPC纽带。
?
三、AI Agent 应用领域?
1、AI Agent 有望多个领域实现落地应用
AI Agent是释放大型语言模型(LLM)潜能的关键,未来将与人类合作更加密切。当前的大模型如GPT-4拥有强大的能力,但其性能仍受用户prompt质量限制。AI Agent出现将用户从prompt工程中解放出来,只需提供任务目标,以大模型为核心的AI Agent即可为其提供行动能力,实现任务完成。虽然目前AI Agent主要处理简单任务,但随着研究的深入,人类与AI Agent的合作将不断增多,形成一个自动化的合作体系,推动人类社会的生产结构变革。AI Agent有望在多个领域实现实际应用,一些演示产品已经表现出色。AI Agent已初步应用于各领域,并有望成为AI应用的基础架构,涵盖toC、toB等产品领域。
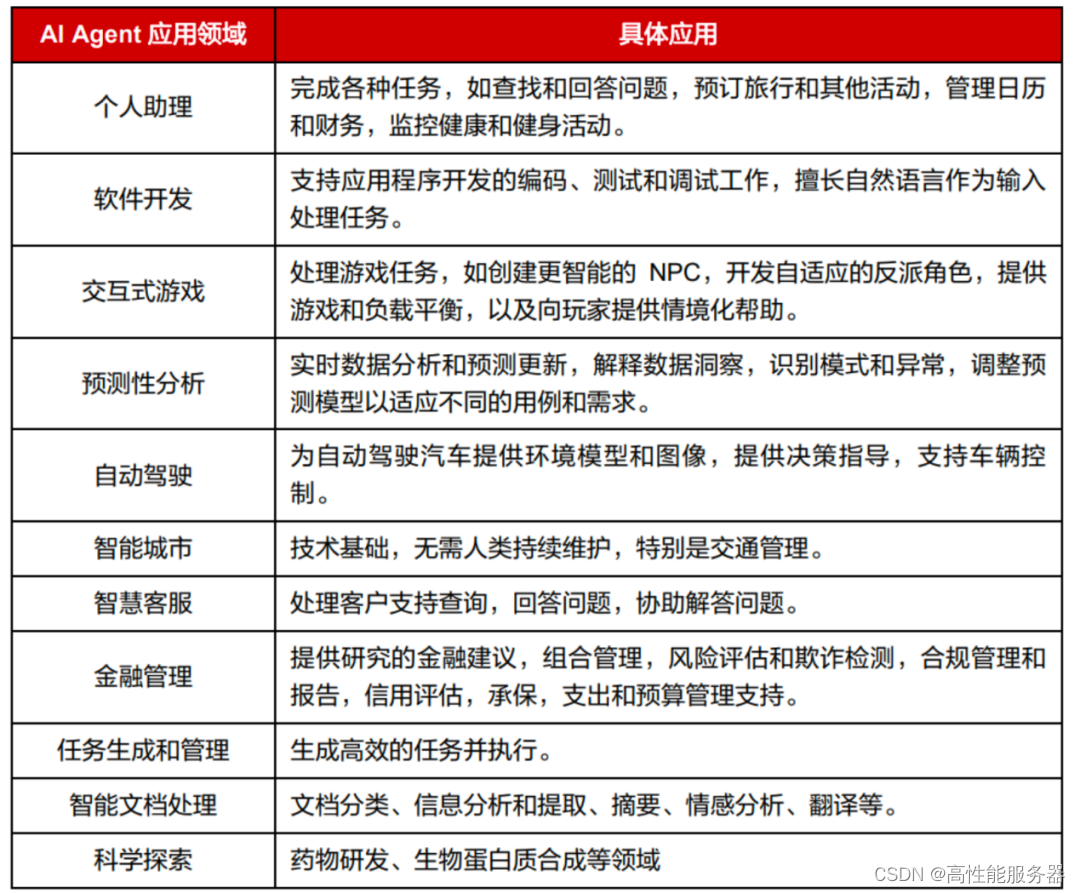
?Al Agent 可能的应用领域
2、2B+垂类 Agent 认知正在形成,有望率先落地
AI Agents在2B和垂直领域有望率先实现实际应用。由于Agent对环境反馈的依赖性,特定的企业环境更适合Agent建立对某一垂直领域认知。传统企业与AI结合应用主要集中在流程任务自动化,而Agent能够进一步提升一线员工工作质量。通过将企业在私域业务上的知识传授给Agent,使其成为领域的虚拟专家,指导并帮助一线员工。从时间角度看,经验丰富的高级员工需要长时间培养,而训练得到的垂类Agent可以低成本规模化复制。
大模型时代的到来加速AI技术平民化,未来5-10年内AI智能成本有望迅速降低,从而实现企业为每一位员工搭配Agent愿景。用户对Agent的认知逐渐形成,初创企业正在积极布局。尽管AI Agent的未来形态尚未确定,但用户对Agent的关注度正在上升,对于提升效率的认知也在形成。未来几年可能涌现出大量以Agent为核心的产品应用于各行各业。
四、龙头企业公司
大模型赋能让进一步智能化的 AI Agent 成为可能。具备底层大模型算法技术的公司以及相关的应用软件公司有望基于 AI Agent 实现应用的落地。
1、OpenAI:OpenAI GPTs 展现 AI Agent 初级形态
GPTs+Assistants API为用户提供创建自定义AI Agent的简便途径。通过自然语言构建专属GPT,整合个性化知识,并通过API调用外部功能,使每个人都有可能拥有自己的人工智能助理。
在GPTs方面,OpenAI推出自定义GPT功能,用户可添加知识、操作和说明,并选择私有、专属或公开发布。企业版用户还可为特定客户或部门创建专属ChatGPT。通过GPT Builder,用户可以以自然语言交互方式创建自定义的GPT,大幅降低开发门槛,GPT应用生态正在迅速发展。
另一方面,Assistants API是OpenAI专为开发者设计的全面API开发助手。提供代码解释器、检索和函数调用等功能,代码解释器支持在沙盒中编写和运行Python代码,检索功能增强助手的知识,而函数调用允许助手调用开发者定义的函数,并将函数响应合并到消息中。
?OpenAl发布的官方 GPTs
OpenAI即将推出GPT Store成为官方应用商店,为用户提供GPT iPhone时代可能性。在插件系统基础上升级,GPT Store将允许开发者分享和提交自定义GPTs,验证后可供用户下载使用,并由此创造收入将与OpenAI共享。插件系统已经开放70多个插件,包括网页创建、视频编辑、数据分析等功能。自ChatGPT推出以来,已有超过200万开发者使用API,92%的财富500强公司也在使用API,周活跃用户已超过1亿。
2、科大讯飞:讯飞构建星火助手生态
讯飞星火插件推出AI工具集市,将第三方生产力工具整合到讯飞星火SparkDesk和星火App中。这些插件实现对大模型的即时信息更新和互联网接入,消除数据集滞后问题有很大帮助。同时,插件扩展模型应用场景,使其适应更多场景和需求,并支持企业私有化部署,确保内部信息隐私和安全。目前,讯飞星火已接入8款插件,包括PPT生成、文档问答、简历生成、ProcessOn、智能翻译、内容运营、AI面试官、邮件生成等,覆盖18个主要应用场景,如营销、工具、旅游、购物、教育和招聘。

?星火插件为大模型赋能助力
3、昆仑万维:昆仑发布天工 SkyAgents
昆仑万维于12月1日正式发布基于“天工大模型”的全新平台“天工 SkyAgents”,旨在帮助用户构建具有自主学习和独立思考能力的AI个人助理。该平台涵盖从感知到决策再到执行的全方位智能,用户可以通过自然语言构建个性化的“私人助理”,实现协同作业,跨部门和业务流程进行信息整合与传递,为每个用户提供智能管理助手。此外,平台采用任务模块化的方式,类似操作系统的模块,覆盖问题预设、指定回复、知识库创建与检索、意图识别、文本提取、HTTP请求等多个任务方面。

?SkyAgents 六大优势
SkyAgents的使用无需编码,用户能够通过可视化设计自主定义和配置AI Agent的行为,使搭建过程变得简单高效。昆仑万维通过简化开发流程和降低技术门槛,让所有开发者都能轻松创建自己的个性化AI。平台提供多种AI能力模块组件,覆盖工作、编辑、金融、写作、助手、翻译、营销、生活等多个应用场景。用户还可以建立个人的“我的Agents”列表,方便管理和使用。
4、拓尔思:“拓天大模型”发布,AIGC 业务加速进展及落地
公司专注于NLP、知识图谱、OCR、图像视频结构化等多模态内容处理底层技术,构建全面的多模态人工智能产品体系,为客户提供文本、音视频、多模态等全栈服务。AIGC业务实现营收782.18万元同比增长206.02%,主要应用于消保报告自动生成和媒体智能辅助写稿等领域。
公司当前致力于研发拓天大模型Agent技术,侧重提升Agent的任务规划、记忆、外部工具使用、多Agent协同等能力。拓天大模型主要服务金融、媒体、政务等领域,公司建立基于各行业的主题数据库,为不同行业提供整合大模型产品,包括内容生成、多轮对话、语义理解、跨模态交互、知识型搜索、逻辑推理、安全合规、数学计算、编程能力和插件扩展等基础能力。
5、彩讯股份:国产邮箱领军者,AI、信创铸就新机遇
公司初期专注基础互联网业务,后转型为产业互联网技术及服务提供商,聚焦协助企业打造新型产品和渠道。在信创领域,公司的Richmail邮箱产品成为国内主力,其信创适配与数据安全技术领先,已被中央集采邮箱项目采用,并备受政企客户好评。
随着大模型技术发展,公司在AI技术领域布局,于2023年发布了下一代智能邮箱demo产品,具备秘书级主动服务、大模型信息整合处理及跨域信息获取与存储等核心功能,提升日常邮件办公效率超过20%。
6、金山办公:AIGC+Copilot+Insight 三箭齐发,AI 全面赋能 WPS 八大应用
金山办公是国内领先的办公软件及服务提供商,旗下产品包括WPS Office、金山文档、WPS 365和WPS AI等,具备全球竞争力,毛利率长期保持在80%以上。公司持续投入高强度研发,并在行业信创和办公软件数智化趋势下,WPS AI与WPS 365预计将迎来新的黄金发展期。
WPS AI是国内首个实现AI+办公软件的产品,拥有三层次产品结构,包括AIGC辅助文章生成、Copilot实现自动操作和Insight提供个性化知识库检索。WPS?AI已经在WPS的八大应用中实现全面赋能,涵盖文档、表格、文字和演示,通过公测展示在各个场景中的出色表现,实现工作自动化和智能化,提高用户效率和产品体验。
WPS AI整合外部和自研模型,采用混合部署策略。与百度文心一言、MiniMax、智谱 AI、科大讯飞、阿里等厂商建立合作关系,同时公司自研的7B和13B模型共同支持WPS AI功能,提高在特定场景中的推理效率和性价比,也满足具备私有化部署需求的客户。
六、AI Agent 可能面临的挑战
1、安全与隐私
智能体的安全性和隐私性直接关系到用户和社会的信任和保护。如OpenAI的GPTs在发布后出现的安全漏洞,可能导致用户数据泄露。
2、伦理与责任
智能体的核心原则包括伦理和责任,不公平、不透明或不可靠的智能体可能会引起用户和社会担忧。此外,责任的明确归属是重要的议题。
3、经济和社会影响
智能体的发展对未来工作和社会就业产生影响。例如,智能体平台可能对传统自由职业者造成冲击,而在社会工作中,雇主可能更趋向于减少人力投入,这引发对智能体技术对职业生涯的长期影响的关注。
未来3年,AI Agent能在哪些场景
为企业带来业务增长与变革
一、AI Agent在企业内的落地方式
尽管AI Agent的概念自今年五、六月份开始引起关注,并在国外涌现多个实际应用场景和案例,但从企业用户、厂商和学术界的角度来看,对AI Agent的定义存在差异。在企业用户实施AI Agent的具体方案中,大致将其分为两类。
1、与整体大模型能力建设密切相关的方案。企业用户通常认为大模型适用于多种场景,倾向于从中台或能力层次来考虑大模型的运用。例如,某股份制银行表示计划在明年在六到七个特定场景中使用大模型,强调需要构建整体大模型能力。
2、AI Agent在具体应用场景中的应用,如问答、运维管理、客服、数字人等,以及与RPA结合用于流程自动化,担任招聘助理、人力资源助理、财务助理等。
这两类方案指引企业用户在大模型部署中的不同方向,同时需要注意AI Agent是被视为一种能力建设还是一个具体的应用场景建设。

二、打造Agent中台,建设大模型能力
AI Agent架构的核心组件聚焦于四个关键因素:长短时记忆、相关配置工具、整体实现路径规划和最终执行。在底层能力方面,依赖于大模型的支持,而这些模型可以是通用、商业或专属训练的。
在能力组件层面,AI Agent包括多种通用能力组件,如多模态检索、内容生成,以及Text to SQL、Text to Chart、Text to BI等数据分析中的处理能力。记忆组件主要依赖于向量数据库和实时数据库,赋予Agent特定的记忆功能。AI Agent借鉴RPA机器人的整体构建思路,涵盖单个设计、整体执行、执行环节实现以及用户端互动。
在构建AI Agent的整体平台时,企业需考虑资源投入、底层计算能力、产品工具以及拥有深厚NLP经验的团队。不过,大多数企业在初期可能不需直接进行这样的建设,而可专注于实际应用的需求。

三、AI Agent未来应用场景规划
企业通过AI Agent在四个方向中寻求不同的价值:变革类、增收类、体验类和降本类。尽管变革和增收是更大的价值所在,当前许多公司,特别是面向消费者的企业,更倾向于体验类价值,因为对C端用户具有高比重,并通过提升用户体验收集更多交互数据。
在技术方面,Agent的能力组件包括记忆、相关配置工具、实现路径规划和执行。对于大模型的支持,特别是记忆组件的建设,仍面临挑战,但体验类场景为企业提供收集用户交互数据的机会,弥补一些企业在数据建设方面的不足。
在应用方面,办公助理和知识库问答是实际应用较好的领域,而面向整个公司层面的应用尚有提升空间。运维管理、客服领域以及数据分析被认为是未来重要的发展方向。数据分析的价值在于满足短期和长期的管理和业务需求,促使企业建立更完善的数据文化,提升决策依据。零售场景的导购赋能和销售赋能也被认为是未来带来收入增长的关键领域。

大型模型训练
GPU 内存需求与优化笔记
在处理大型模型时,必须综合考虑计算能力、内存使用以及GPU的适配情况。这不仅影响GPU在推理大型模型时的性能,还直接决定在训练集群中可用的总GPU内存,从而对能够训练的模型规模产生影响。
推理大型模型的内存计算只需考虑模型权重。而在进行大型模型训练时,内存计算则需要考虑模型权重、反向传播的梯度、优化器所需的内存以及正向传播的激活状态内存。
以ChatGLM-6B为例,其参数设置包括隐藏层神经元数量(hidden_size)为4096,层数(num_layers)为28,token长度为2048,注意力头数(attention heads)为32。下面将详细讲解如何计算推理内存和训练内存。
一、推理内存
1、模型权重
对于不同精度的模型内存计算,可以使用以下简化规则:
int8精度模型内存=参数量的1倍(6GB)
fp16和bf16精度模型内存=参数量的2倍(12GB)
fp32精度模型内存=参数量的4倍(24GB)
因为1 GB ≈ 1B字节,这种简化规则使得估算ChatGLM-6B模型在不同精度下的内存需求更为便捷。
2、推理总内存
在进行前向传播时,除了用于存储模型权重的内存之外,通常会有一些额外的开销。根据以往经验,通常被控制在总内存的20%以内。因此,可以估算推理总内存≈1.2×模型内存。
二、训练
1、模型权重
模型权重的内存需求在训练阶段涉及不同精度的训练,包括纯fp32、纯fp16以及混合精度(fp16/bf16 + fp32):
纯fp32训练模型内存=4 * 参数量(字节)
纯fp16训练模型内存=2 * 参数量(字节)
混合精度训练(fp16/bf16 + fp32)模型内存=2 * 参数量(字节)
对于ChatGLM-6B,这意味着:
纯fp32训练模型内存=4 * 6GB=24GB
纯fp16训练模型内存=2 * 6GB=12GB
混合精度训练模型内存=2 * 6GB=12GB
这样的设定允许在训练过程中选择不同的精度,权衡模型性能和内存开销。
2、优化器状态
不同优化器在内存使用上有不同的计算方式:
纯AdamW优化器内存=12 * 参数量(字节)
8位优化器(如bitsandbytes)内存=6 * 参数量(字节)
带动量的类SGD优化器内存=8 * 参数量(字节)
对于ChatGLM-6B,具体内存计算如下:
纯AdamW优化器内存=12 * 6GB=72GB
8位优化器内存=6 * 6GB=36GB
带动量的类SGD优化器内存=8 * 6GB=48GB
这些设定允许在训练过程中选择不同的优化器,权衡模型训练速度和内存开销。
3、梯度
梯度的内存需求取决于存储的数据类型,通常为fp32或fp16。对于不同的数据类型,梯度内存的计算方式如下:
fp32梯度内存=4 * 参数量(字节)
fp16梯度内存=2 * 参数量(字节)
对于ChatGLM-6B,具体梯度内存计算如下:
fp32梯度内存=4 * 6GB=24GB
fp16梯度内存=2 * 6GB=12GB
这些设定允许在混合精度训练过程中选择不同的梯度存储类型,权衡训练速度和数值稳定性。
训练总内存=模型内存+优化器内存+激活内存+梯度内存 = 12GB + 72GB + 12Gb + 7.8GB = 103GB

AI Agent对算力的需求
解析人工智能发展中的计算力挑战
随着人工智能技术的不断发展,AI Agent作为其中的关键组成部分,对算力的需求日益增加。下面将深入分析AI Agent对算力的具体需求,以及这一需求在人工智能领域中所带来的挑战和影响。
一、AI Agent与算力的密切关系
AI Agent作为自主智能体,具备学习、推理和决策的能力,其运行和发挥功能需要强大的算力支持。在训练阶段,AI Agent需要处理大量的数据和复杂的模型,而这就需要大规模的计算资源。算力的提供决定模型的规模、训练速度和推理效率,直接影响到AI Agent的性能和智能水平。
二、AI Agent的算力需求分析
大规模神经网络模型的训练需要处理庞大的数据集和复杂的模型结构。如GPT-3和BERT,其训练过程更是对算力提出极高要求。随着模型规模和复杂性的不断增加,AI Agent对算力的需求也呈现出指数级的增长。大模型在处理更多参数和更复杂的模型结构时能够获得更好的性能,但这也带来训练和推理时的计算负担。硬件供应商和云服务提供商需要不断提升计算资源的性能和规模,以满足Agent日益增加的需求。
除训练过程,AI Agent在推理和实时决策中同样对算力有着高效响应需求。在处理实时数据和作出即时决策情境下,算力的快速响应成为保证Agent高效运行关键因素。这对硬件架构和计算资源的设计提出更高的要求,需要实现低延迟和高吞吐量。
AI Agent算力需求不仅仅影响到硬件供应链,还对云服务行业和数据中心产业产生深远影响。云服务提供商需要提供弹性的计算资源,以适应用户对于AI Agent使用的不断增长。数据中心的设计和运维也需要根据算力需求的变化进行不断优化和升级。
三、大模型训练常用配置推荐
1、处理器CPU:
- Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
- Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
- AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
-AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、显卡GPU:
- NVIDIA L40S GPU 48GB
- NVIDIA NVLink-A100-SXM640GB
- NVIDIA HGX A800 80GB
- NVIDIA Tesla H800 80GB HBM2
- NVIDIA A800-80GB-400Wx8-NvlinkSW
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue小练习之随机生成数字并删除
- 题记(10)--大数加法
- QCustomplot2实战示例
- 基于docker容器化部署微服务
- 基于Java SSM框架实现实现员工工资管理系统项目【项目源码】
- Vulnhub-VULNCMS: 1渗透
- ppt流程图模板怎么绘制?手把手教你绘制PPT流程图
- 学习如何使用 Python 连接 MongoDB: PyMongo 安装和基础操作教程
- HCIA-Datacom题库(自己整理分类的)_06_园区网和网络架构判断【9道题】
- oracle数据库sqlplus登录卡顿