P2PNet推理和训练
发布时间:2024年01月22日
0、环境信息
Package Version
------------------------ ------------
certifi 2023.11.17
charset-normalizer 3.3.2
contourpy 1.2.0
cycler 0.12.1
easydict 1.11
filelock 3.13.1
fonttools 4.47.2
fsspec 2023.12.2
idna 3.6
importlib-resources 6.1.1
Jinja2 3.1.3
kiwisolver 1.4.5
MarkupSafe 2.1.4
matplotlib 3.8.2
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.3
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
opencv-python 4.9.0.80
packaging 23.2
pandas 2.2.0
pillow 10.2.0
pip 23.3.1
protobuf 4.25.2
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
requests 2.31.0
scipy 1.12.0
setuptools 68.2.2
six 1.16.0
sympy 1.12
tensorboardX 2.6.2.2
torch 2.1.2
torchvision 0.16.2
triton 2.1.0
typing_extensions 4.9.0
tzdata 2023.4
urllib3 2.1.0
wheel 0.41.2
zipp 3.17.0
1、测试
下载模型
根据url下载,并修改模型的相关路径

运行测试
CUDA_VISIBLE_DEVICES=0 python run_test.py --weight_path ./weights/SHTechA.pth --output_dir ./logs/报错1:
from torchvision.ops import _new_empty_tensor
connot import name '_new_empty_tensor'原因:版本问题
解决方式:将misc.py里的if语句注释到

报错2:
img_raw = img_raw.resize((new_width, new_height), Image.ANTIALIAS)
AttributeError: module 'PIL.Image' has no attribute 'ANTIALIAS'原因:原来是在pillow的10.0.0版本中,ANTIALIAS方法被删除了,使用新的方法即可
解决方式:
将Image.LANCZOS替换为Image.Resampling.LANCZOS
运行成功
此时需要你先创建logs文件,要不然看不到预测的图片。
2、训练
数据下载

生成list
分别修改dataset_path 和output_path 来生成两个对应的list
import os
# 设置数据集目录
dataset_path = '/dev_path/qiuzx/datasets/01CrowdCounting/part_A_final/test_data'
# 设置输出的train.txt文件路径
output_path = './test.list'
# 获取images文件夹下的所有.jpg文件
image_files = [f for f in os.listdir(os.path.join(dataset_path, 'images')) if f.endswith('.jpg')]
# 打开train.txt文件以写入模式
with open(output_path, 'w') as f:
# 遍历每个.jpg文件并写入train.txt
for image_file in image_files:
# 构造图片和对应txt文件的路径
image_path = os.path.join(dataset_path, 'images', image_file)
txt_path = os.path.join(dataset_path, 'txt', 'GT_' + os.path.splitext(image_file)[0] + '.txt')
# 检查txt文件和对应的jpg文件是否存在
if os.path.exists(txt_path) and os.path.exists(image_path):
# 写入train.txt文件
f.write(f"{image_path} {txt_path}\n")
else:
print(f"Skipping pair: {image_path}, {txt_path} as one or both files do not exist.")修改list的位置

运行
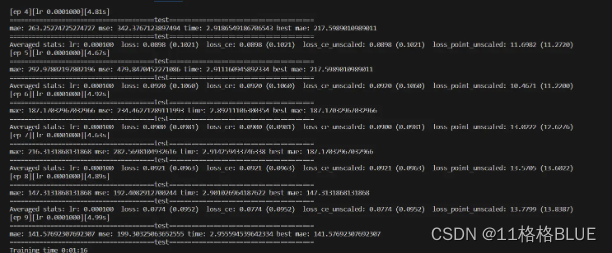
CUDA_VISIBLE_DEVICES=0 python train.py --data_root ../01CrowdCounting/part_A_final --dataset_file SHHA --epochs 3500 --lr_drop 3500 --output_dir ./logs --checkpoints_dir ./weights/train --tensorboard_dir ./logs --lr 0.0001 --lr_backbone 0.00001 --batch_size 8 --eval_freq 1 --gpu_id 0运行成功
文章来源:https://blog.csdn.net/qq_36852840/article/details/135752854
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LaTeX论文排版
- 基于YOLOv8深度学习的西红柿成熟度检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
- K8S学习指南(10)-k8s中为pod分配CPU和内存资源
- 计算机网络实验(四):交换机VLAN配置练习
- 二叉树OJ题——9.另一棵树的子树
- 音视频基本概念
- 红队基础建设与介绍
- Python常用技能手册 - 基础语法
- 【JUC进阶】13. InheritableThreadLocal
- 使用Moonbuilders Academy平台,学习DApp开发