NLP论文阅读记录 - | 文本生成的动量校准
文章目录
前言

Momentum Calibration for Text Generation(2212)
0、论文摘要
大多数文本生成任务的输入和输出可以转换为两个标记序列,并且可以使用 Transformers 等序列到序列学习建模工具对其进行建模。这些模型通常通过最大化输出文本序列的可能性来训练,并假设在训练期间给出输入序列和所有黄金前置标记,而在推理过程中,模型会遇到暴露偏差问题(即,它只能访问其先前预测的在波束搜索期间使用代币而不是金代币)。在本文中,我们提出用于文本生成的MoCa(动量校准)。 MoCa 是一种在线方法,它使用带有波束搜索的动量移动平均生成器动态生成缓慢演变(但一致)的样本,并且 MoCa 学习将这些样本的模型分数与其实际质量对齐。对四个文本生成数据集(即 CNN/DailyMail、XSum、SAMSum 和 Gigaword)的实验表明,MoCa 使用普通微调持续改进了强大的预训练 Transformer,并且我们在 CNN/DailyMail 和SAMSum 数据集。
一、Introduction
1.1目标问题
文本生成是给定一定输入生成文本序列的任务,并且输入通常可以转换为另一个文本序列,这是典型的序列到序列(Seq2Seq)学习问题[33]。大型预训练序列到序列 Transformer 模型(例如 T5 [28]、BART [14] 和 PEGASUS [40])已成为文本生成的默认建模工具,因为它在各种生成任务上都取得了令人印象深刻的结果,例如摘要 [14, 40]、数据/关键字到文本生成 [15] 以及机器翻译 [18]。这些大型模型首先在大规模未标记数据集上进行预训练,然后针对特定任务在标记数据集上进行微调。
1.2相关的尝试
微调的主要方法是最大化黄金输出序列的可能性(MLE;最大似然估计)。通过应用链式法则,在给定所有黄金之前的令牌和输入序列的情况下,它本质上最大化了输出序列中每个令牌的概率。上面的训练损失是单词级别的。然而,在测试期间,模型需要使用波束搜索(贪婪搜索可以视为波束大小为 1 的波束搜索)从头开始(贪婪地)预测整个输出序列。与训练期间不同,模型只能访问自己的预测(而不是黄金前缀)。训练和推理之间的这种差异称为暴露偏差 [29](即模型永远不会暴露于其自身的预测误差 [38])。由于训练和推理差异而导致的另一个问题是损失评估不匹配[38],其中在训练期间采用令牌级 MLE 损失,而在推理期间通常使用序列级指标(例如 BLEU [27])。
1.3本文贡献
为了解决上述问题,在训练期间需要来自模型分布的样本,以便随着训练的进行“纠正”这些样本中的潜在错误。 [29, 7] 建议通过将生成样本的 BLEU [27] 或 ROUGE [16] 分数视为奖励,利用强化学习来指导模型训练。在计划采样[2]中,黄金目标序列中的一些标记在 MLE 训练的后期被模型预测替换。然而,我们认为上述所有这些方法仍然无法解决训练和推理之间的差异。因为[29,7,2]中模型中的样本是单独处理的,而在集束搜索中,我们在每个步骤中比较多个假设(并选择前 K 个)。换句话说,在波束搜索过程中,不同样本的相对质量比它们的绝对质量更重要。因此,我们生成的样本的概率应与其实际质量保持一致(即,我们的模型应将较高质量的样本分配给较高的概率)。其次,我们的方法应该是在线的,以确保我们模型中的样本可以在训练过程中实时表示其模型分布。同时,这些样本应该是从相似的模型生成的,以便它们的风格一致,这可能有助于使学习过程更容易。为此,我们使用动量模型来生成样本。
根据这些设计原则,我们提出了用于文本生成的 MoCa(动量校准),它通过将样本的概率与其质量对齐来校准使用 MLE 损失训练的模型。在 MoCa 中,我们有一个生成器模型和一个在线模型。生成器是在线模型的动量移动平均值,生成缓慢演变的样本。然后使用评估模型评估这些样本并估计它们的质量。我们最终使用排名损失将评估分数与在线模型分数对齐。为了进一步减少训练和推理之间的差异,我们提出了专为波束搜索定制的新在线模型评分函数。对四个文本生成数据集(即 CNN/DailyMail、XSum、SAMSum 和 Gigaword)的实验表明,MoCa 使用普通微调持续改进强大的预训练 Transformer,我们在 CNN/DailyMail 和SAMSum。
二.相关工作
Seq2Seq 模型通常通过词级 MLE 损失进行训练,而在测试期间,模型使用波束搜索根据其之前的预测来预测下一个标记。为了解决这个问题,首先在结构预测的背景下探索了在训练期间显示模型自身预测的方法[6]。在序列到序列学习中,计划采样[2]提出在训练后期用自己的模型预测替换目标序列中的一些黄金标记。 [29,7,1]在训练过程中生成整个候选目标序列,生成的序列被视为强化学习(RL)中的动作序列,使用 BLEU 或 ROUGE 作为奖励。他们的模型使用 REINFORCE 算法进行优化 [37],因为 BLEU 或 ROUGE 分数是不可微分的。 [38]引入了一种在训练期间优化波束搜索过程的方法,通过鼓励黄金前缀出现在具有边际基础损失的波束中。上述方法中的候选样本是单独查看的,并且将高模型分数分配给与其黄金样本更相似的样本。在我们的方法中,我们比较给定相同输入的多个样本,并鼓励我们的模型为质量更好的样本分配更高的分数。此外,我们的方法是可微分的,可以避免 REINFORCE 中的优化挑战。
对比学习已应用于文本生成[26,3,39,4]。他们还为每个输入生成多个候选样本,但这些样本用作硬负例,正例是黄金输出序列。对比目标旨在为正例分配较高的模型分数,为负例分配较低的分数。与我们的方法不同,负例的相对模型分数没有建模,这对于波束搜索很重要。
我们的方法还与基于两阶段重排序的文本生成方法相关[32,25,36,21,13,19],因为我们的模型尝试使用排名目标。 [19]建议使用基于 RoBERTa [17] 的重新排序器对基于 BART [14](或 PEGASUS [40])的神经文本生成模型中的候选者进行重新排序。与上述方法不同,我们的重新排序器和文本生成模型共享模型参数。 [20]和[42]使用类似的排名目标作为我们的方法,并且它们的生成模型和重新排名器的参数也被共享。然而,[20]和[42]都是离线方法,它们的候选样本在训练过程中是固定的,随着训练的进展,这些样本可能会变得过时。通过动量更新生成器,我们的方法可以生成缓慢演化的候选样本,这些样本可以代表当前模型在整个过程中的建模能力培训过程。此外,我们还发现模型评分中使用的对数概率不是最优的,并且我们提出了为波束搜索解码量身定制的新评分函数。
三.本文方法
3.1 神经文本生成
神经文本生成旨在根据其输入生成文本序列,该文本序列几乎总是可以转换为另一个文本序列。我们通常采用序列到序列(Seq2Seq)变压器[34]来建模这个任务。给定输入文本序列 X = (x1, x2, . . . , x|X|) 及其黄金输出文本序列 Y = (y1, y2, . . . , y|Y |),条件概率 p(Y | X; θ) 估计如下:
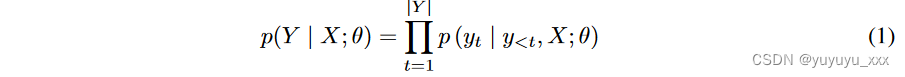
其中 θ 是模型参数,y<t 代表时间步 t 之前的所有标记。可以通过最小化输入和输出文本对的负对数似然来训练模型(相当于最大化似然):
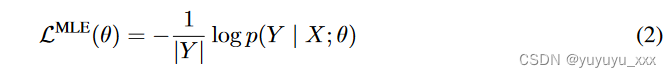
在测试期间,模型预计将使用波束搜索从头开始生成整个文本序列,这与其训练不同(即,根据先前的标记预测下一个标记)黄金代币)。因此,模型在训练过程中永远不会暴露于其自身的错误,这称为暴露偏差[29]。下面我们介绍如何解决曝光偏差。
3.2 动量校准
假设我们已经有一个使用 3.1 节中描述的 MLE 目标训练的 Seq2Seq Transformer 模型。使模型能够产生合理的输出。为了解决推理过程中使用波束搜索遇到的曝光偏差问题,如图 1 所示,我们首先从预训练的生成器模型生成输出样本,这些样本代表模型分布。然后,我们用评估模型对这些样本进行评估,并获得这些样本的排名。通常,这些排名 w.r.t.评估模型与排名不同。模型概率,这就是我们需要进行校准的原因。因此,我们使用排名损失强制模型概率与评估模型输出保持一致。最后我们更新了生成器模型,我们的方法上线了。在 MoCa 中,我们有两个 Seq2Seq Transformer 模型:参数为 θ 的在线模型 M (θ) 和参数为 xi 的生成器模型 G(xi)。它们共享相同的模型架构,但有自己的参数。在训练开始时,我们设置 ψ = θ。
样本生成 我们的方法旨在模拟训练期间的波束搜索推理。因此,给定输入序列 X,我们首先生成 K 个样本 ? Y1, ? Y2,…。 。 。 , ? YK 来自我们的生成器 G(xi),使用波束搜索 (BS) 或其变体多样化波束搜索 (DBS) [35],这些样本随后将用于修复曝光偏差。除了波束搜索中使用的归一化对数概率之外,多样化波束搜索还考虑了波束组之间的差异,并且它生成的样本在质量和多样性之间具有良好的权衡。我们没有使用抽样或核抽样[10],因为它们生成的样本质量不如BS和DBS(样本的ROUGE上限、平均值和下限都较低)。此外,我们还发现核采样生成的样本有很大一部分是重复的。
评估和校准 在此步骤中,我们使用上面生成的样本来校准我们的在线模型M(θ)。一旦我们获得这些样本 ? Y1, ? Y2,… 。 。 , ? YK,我们可以使用评估模型 E( ? Yk, Y ) 针对黄金输出序列 Y 来评估这些样本。 E 可以是非参数模型,例如 ROUGE [16] 或 BLEU [27] 和/或参数模型,例如 BERTScore [41]。然后我们对这些样本进行排序。评估模型并获得排序样本列表 ? Y′ 1, ? Y′ 2,…, ? Y′ K 使得 E( ? Y′ i ,Y ) < E( ? Y′ j , Y ) ?我 < j。
直观上,一个好的模型应该为评估分数较高的样本分配较高的概率。我们的模型 M (θ) 最初是通过 MLE 损失进行训练的(参见第 3.1 节),并不总是分配与评估分数一致的样本概率。我们使用以下基于间隔的成对排名损失[11, 43]来调整我们的模型,以便它可以将高评估分数的样本排名更高:
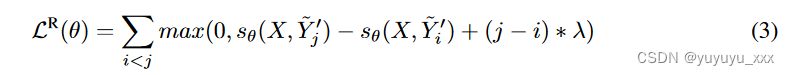
其中 sθ(X, ? Y ′) 是模型 M (θ) 为输入 X 和样本 Y ′ 之一分配的分数。 (j ? i) ? λ 是 ? Y′ i 和 ? Y′ j 分数之间的动态余量,并且 λ 是超参数。由于我们的校准过程模拟了集束搜索搜索推理,自然地 sθ(X, ? Y ′) 被定义为归一化对数概率(即集束搜索中使用的评分函数):
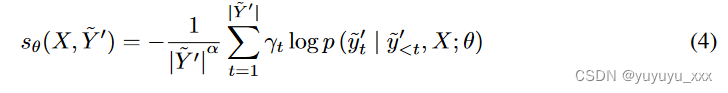
其中 ? Y ′ = ( ? y′ 1, ? y′ 2, …, ? y′ | ? Y ′|),α 是超参数(类似于波束搜索中的长度惩罚)和位置权重在普通波束搜索中,函数是常数(即 γt = 1)。给定一个由 MLE 损失训练的模型,我们观察到该模型通常在后面的位置具有较低的词级预测准确性(w.r.t. gold)。可能是因为模型需要记住更多的过程标记才能进行预测。
为了让模型专注于后面的位置(模型容易出错的位置),我们提出了针对不同位置的单调递增权重函数。

我们使用上面的函数是因为 Σ t ? γt 有一个上限,并且里面没有额外的超参数。注意 limn→∞ Σn i=1 1 i2 = π2/6。为了确保所得的 sθ(X, ? Y ′) 和普通波束搜索中使用的 sθ(X, ? Y ′) (即 γt = 1)具有相同的尺度,我们用它们的平均值和由此产生的位置加权函数为:
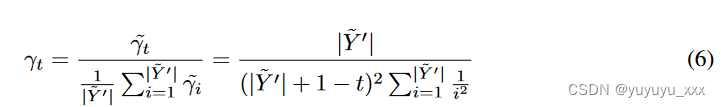
请注意,当使用 MLE 损失训练的模型的位置精度在后面的位置下降时,使用上述位置加权函数。否则,我们使用恒定的位置权重函数 γt = 1。在最终的模型损失中,我们在 MLE 目标上放置了一个小的权重(参见方程 2),我们打算提醒模型在第一阶段 MLE 中学到了什么培训(第 3.1 节):
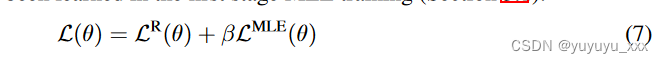
动量更新使用等式(7)中的训练损失,可以更新在线模型M(θ)的参数。但生成器模型 G(xi) 的参数保持不变,因为波束搜索过程是不可微分的。然而,保持 Ψ 不变是不合理的,因为随着训练的进行和 M(θ) 变得更强,从 G(Ψ) 预测候选样本的正确排名对于 M(θ) 来说可能太容易了。事实上,在实验中我们观察到,当保持 M (θ) 不变时,模型收敛得非常快(通常在一个时期内)。另一种方法是在每次模型更新后重置 ? = θ。在这种情况下,我们的方法就变成了完全在线的方法。也许由于生成器 G(xi) 及其生成的样本的快速变化,训练损失很高(也许是因为它太难学习),我们没有获得很好的结果。为了克服快速收敛和训练不稳定的问题,我们最终选择对生成器 G(xi) 的参数进行动量更新:

其中 m 是动量系数。请注意,反向传播中仅更新 θ。我们在实验中观察到需要相对较大的动量系数(例如,m = 0.99),这表明生成器 G(xi) 的稳定性很重要。
四 实验效果
4.1数据集
我们对跨不同领域、具有不同输入和输出长度的四个不同文本生成数据集进行了初步实验。它们是 CNN/DailyMail(CNNDM;Nallapati 等人 22)、XSum [24]、SAMSum Corpus [8] 和 Gigaword [23]。
4.2 对比模型
4.3实施细节
我们使用 PEGASUS [40](568M 参数)作为 XSum 上的主干,BART [14](400M 参数)是其他数据集上的主干。我们使用 Adam [12] 来优化我们的模型,并在验证集上调整学习率和预热步骤。我们在训练期间使用不同的波束搜索 [35] 生成 16 个候选样本。等式(3)中的余量系数λ被设置为0.001。我们使用 ROUGE 评分 [16] 作为我们的评估模型,因为它的计算速度比基于模型的方法(例如 BERTScore [41])更快。我们的在线模型评分函数中的长度归一化项 α 在 XSum 上设置为 0.6,在其他数据集上设置为 2.0。我们将 MLE 损失 β 的权重设置为 0.01(公式 7)。一般来说,我们发现需要较大的动量系数 m(例如,m ≥ 0.99),并且对于收敛速度较慢的数据集应使用较大的动量。我们在CNNDM上设置m=0.995,在其他数据集上使用m=0.99。
4.4评估指标
4.5 实验结果
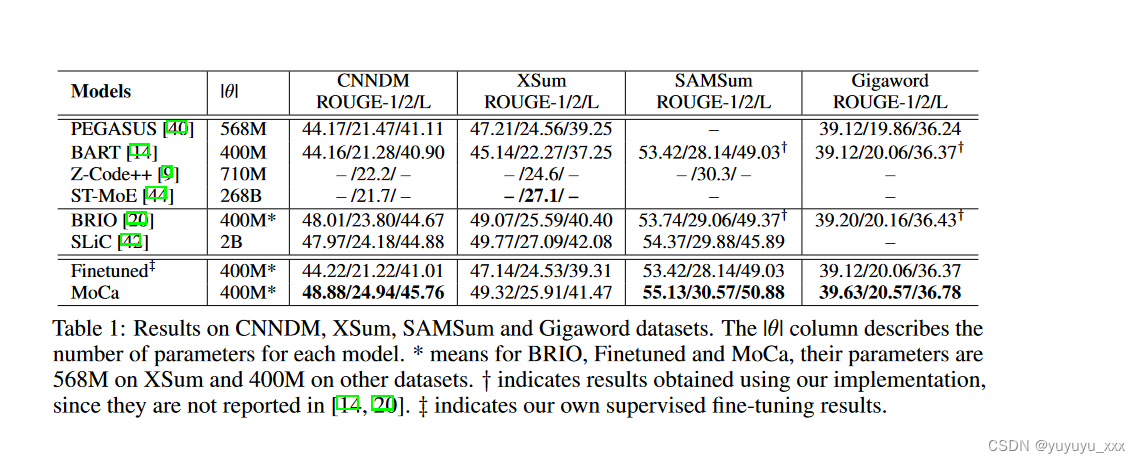
我们的主要结果如表 1 所示。在第一个块中,我们将 MoCa 与使用普通微调的大型预训练 Transformer 进行比较。 PEGASUS [40] 和 BART [14] 使用间隙句子预测和文本填充目标在无监督文本数据上进行预训练,其中分别包含 400M 和 568M 参数。 Z-Code++ [9](710M 参数)和 ST-MoE [44](268B 参数)均采用损坏的跨度预测目标 [28],而 Z-Code++ 利用附加替换的令牌检测目标 [5]。尽管只有 400M 或 568M 参数,MoCa 在 XSum 上的表现优于除 ST-MoE 之外的所有其他模型。请注意,ST-MoE 比 MoCa 大 470 倍。我们还与在第二个块中使用高级微调的模型进行比较。 BRIO(400M或568M参数)[20]和SLiC(2B参数)[42]也尝试将模型得分与评估指标对齐,就像我们的方法MoCa一样,但它们是离线方法,并且它们的模型评分函数与我们的不同。我们使用与 BRIO 相同的主干模型,并且在所有数据集上始终优于 BRIO,这表明频繁更新候选样本和使用波束搜索定制评分函数非常重要。 SLiC 比我们的模型大四倍左右,但我们在 CNNDM 和 SAMSum 上的表现仍然优于它们。与我们自己在第三个块中实现的普通微调方法(Finetuned)相比,MoCa 在所有数据集上都明显优于它,这表明 MoCa 可以很好地替代普通微调。
4.6 消融实验
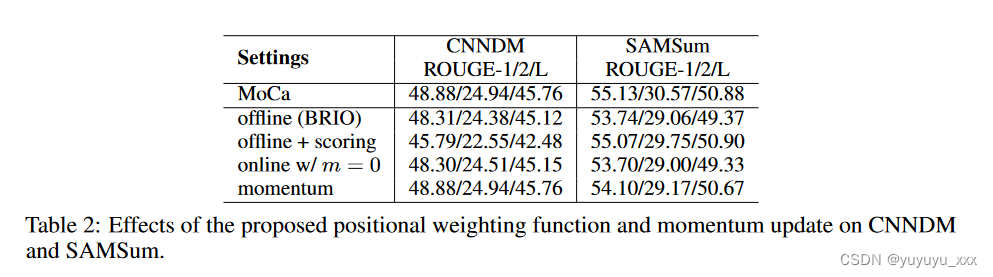
在本节中,我们评估了我们提出的在线模型评分函数以及 CNNDM 和 SAMSum 数据集上的动量更新策略的有效性。当我们使用普通在线评分函数(γt = 1)并且不使用生成器模型的在线动量更新时,我们的方法类似于 BRIO [20](参见表 2 中的离线 (BRIO) 行)。请注意,我们重新实现的 BRIO 取得了比 [20] 更好的结果(另见表 1)。如表 2 所示,利用我们提出的位置加权函数(第 3 节中的公式 6),我们在 SAMSum 上获得了更好的结果,而在 CNNDM 上获得了更差的结果(离线 + 评分)。如第 3 节所述,位置加权函数旨在解决 MLE 损失(MoCa 初始化所在)训练的模型中的位置精度下降问题。如图 2 所示,CNNDM 上的位置精度在不同位置上都很稳定,而 SAMSum 上的位置精度随着位置索引变大而下降(特别是从位置 0 到 50)。因此,我们在存在位置精度问题的数据集(例如 SAMSum)上使用等式(6)中的加权函数,在其他数据集(例如 CNNDM)上使用恒定位置加权函数(γt = 1)。当线下方式升级到线上时,我们发现动量更新很重要。没有动量的纯在线方法(在线 w/ m = 0)有时会带来伤害,而具有动量(动量)的在线方法始终优于离线方法。我们观察到,一种评分函数可能比另一种表现更好。通过适当的位置加权函数,可以进一步改进动量方法(MoCa)。
五 总结
我们提出用于文本生成的 MoCa,这是一种在线方法,旨在解决分配给候选样本的模型概率与其质量之间的差异。跨不同数据集的实验表明,MoCa 持续改进了大型预训练 Transformer 的 MLE 损失的普通微调。我们还展示了在线的重要性,并使用专为波束搜索量身定制的评分功能。 MoCa目前应用于英文文本生成任务。我们希望我们的方法可以用于多语言文本生成任务,例如机器翻译和跨语言文本摘要,以及文本之外的生成任务(例如文本到图像生成和文本到语音合成)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!