接口测试 03 -- 接口自动化思维 & Requests库应用
1. 接口自动化思维梳理
1.1接口自动化的优点
接口测试自动化,简单来讲就是功能测试用例脚本化然后执行脚本,产生一份可视化测试报告。不管什么样的测试方式,都是为了验证功能与发现 BUG。那为什么要做接口测试自动化呢?一句话概括就是为了节省人力成本。具体来说,包括以下几点:● 减轻自己工作量,把测试从枯燥的重复劳动的人工测试中解放出来;● 协助手工测试完成很难模拟或无法模拟的的工作;● 提高工作效率,比如测试环境的自动化编译、打包、部署、持续集成甚至持续交付等。● 协助定位问题,比如接口层发现问题了,可以通过添加的 traceID 定位到日志错误或错误代码行。● ?尽早发现 Bug,自动通知测试人员。 一旦发现问题,立即通知测试人员,快速高效。
1.2 事前准备的主要两个核心
?文档的准备
磨刀不误砍柴工,准备好分详细的接口相关文档能够帮助后续接口自动化测试工作的高效展开。相关文档包括但不限于一下内容:①《需求文档》明确定义了:接口背后的业务场景,该接口是干什么用的,用到哪里,每次调用会发生什么等;②《接口文档》明确定义了:接口名,各个入参值,各个返回值,和其他相关信息;③《UI 交互图》明确定义了:各单页面需展示的数据;页面之间的交互等;④《数据表设计文档》,明确定义了:表字段规则、表 N 多 N 关系(一对一、一对多、多对多)等;======================================================================务必和相关需求方确认好文档中的信息是可靠且最新的,只有依赖可靠的文档才能设计出正确详尽的接口用例,才能得到最正确的结果。
明确接口测试自动化所需功能
测试断言是自动化测试中的测试通过条件,用于判断测试用例是否符合预期。所以支持对返回值校验是一 个必须的功能。
数据隔离是指:具体的请求接口、参数、校验等数据做到与代码相隔离,便于维护,一旦需要调整接口用 例、新增接口用例时可很快速的找到位置。隔离的另一个好处就是可复用,框架可以推广给其他团队,使 用者可以使用相同的代码,只需要根据要求填写各自用例即可测试起来。
做到数据隔离可维护后,数据传递是另外一个更重要的需求。接口测试时,首先我们会实现单接口解耦, 后续按照业务场景组合多个接口。而数据传递是则是组合多个接口的必要条件,它让接口用例之间可以做 到向下传参。举个例子:我们通过设备信息查询接口查询到当前天猫精灵音箱的设备信息,该接口会返回 一个 UUID,接下来我们要通过用户信息查询接口去查询当前设备绑定的用户信息,此时第二个接口的请 求数据是需要从第一个接口用例中的返回中提取的
实际的业务场景测试会需要各种辅助功能的支持,比如随机生成时间戳,请求 ID,随机的手机号码或位 置信息等等,此时我们就需要代码可以支持做到识别对应关键字时可以执行对应的功能函数进行填充。
日志包含执行的具体执行接口、请求方式、请求参数、返回值、校验接口、请求时间、耗时等关键信息, 日志的好处一来是可以便于在新增用例有问题时快速定位出哪里填写有问题,二来是发现 bug 时方便向 开发反馈提供数据,开发可以从触发时间以及参数等信息快速定位到问题所在。
目前测试环境包括但不限于日常、预发一、预发二、线上等等,因此用例不单单只能在一个环境上执行, 需要同一份接口用例可以在日常、预发、线上等多个环境都可以执行。所以框架需要做到可配置,便于切 换,调用不同的配置文件可以在不同的环境执行。
用例执行后,就是到了向团队展示结果的时候了,一个可视化的报告可以便于团队成员了解到每次自动化 接口用例执行的成功数、失败数等数据。
对于已经有测试用例并测试完成的接口,我们希望能够形成回归用例,在下一个版本迭代或上线之前,通 过已有用例进行一个回归测试,确保新上线的功能不影响已有功能。因此,这就需要接口自动化测试是可 持续集成的而不是一次性的。
2. Requests库的基本介绍及安装
2.1?Requests库简介
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议 的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
官网介绍:https://cn.python-requests.org/zh_CN/latest/
Requests 也可用于爬虫
2.2 Requests库安装
pip install requestspip show requests3.?Requests库的实战应用
3.1 Requests库请求源码理解
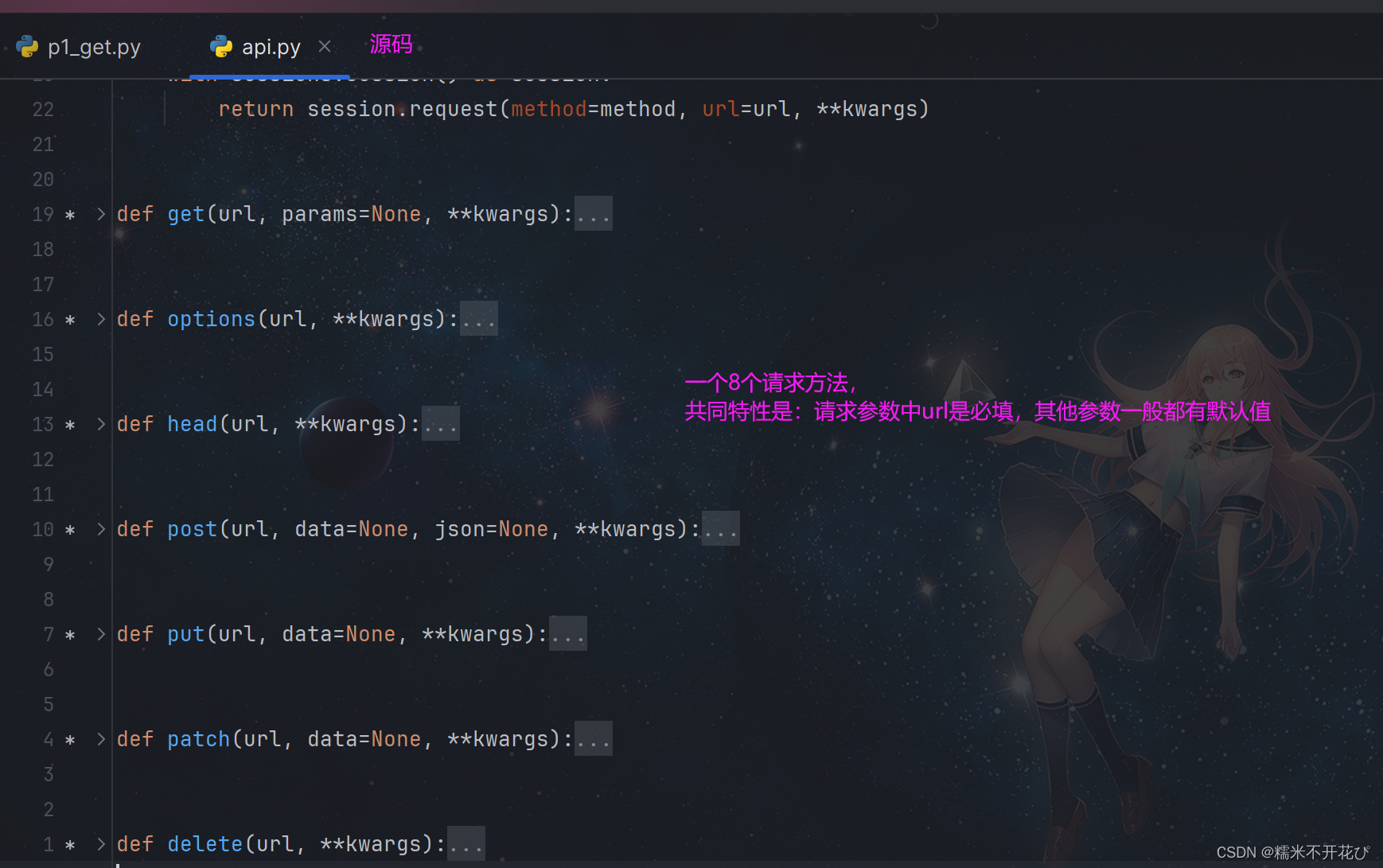
Requests库常用方法
Requests库常用的方法及对应的参考如下 :● requests.requests()● requests.get(‘https://github.com/timeline.json’) :GET请求● requests.post(“http://httpbin.org/post”) :POST请求● requests.put(“http://httpbin.org/put”) :PUT请求(提交修改全部的数 据)● requests.delete(“http://httpbin.org/delete”) :DELETE请求● requests.head(“http://httpbin.org/get”) :HEAD请求● requests.patch(“http://httpbin.org/get”) :PATCH请求(提交修改部分 数据)● requests.options(‘https://github.com/timeline.json’) :OPTIONS请 求(跨域预检请求)
requests方法的请求参数详解
requests.requests(method, url, **kwargs)● method:请求方式:GET, PUT,POST,HEAD, PATCH, delete, OPTIONS7种方式● url:网络链接● kwargs: (13个可选参数)
kwargs可选参数如下:
|
参数值
|
参数概述
|
|
params
|
字典或者字节序列,作为参数增加到url中
|
|
json
|
JSON格式的数据,作为requests的内容
|
|
headers
|
字典,HTTP定制头
|
|
data
|
是第二个控制参数,向服务器提交数据,[POST请求用的居多]
|
|
cookies
|
字典或CookieJar, Requests中的cookie
|
|
auth
|
元组,支持HTTP认证功能
|
|
files
|
字典类型,传输文件
|
|
timeout
|
设置的超时时间,秒为单位
|
|
proxies
|
字典类型,设定访问代理服务器,可以增加登录认证
|
|
allow_redirects
|
True/False,默认为True, 重定向开关
|
|
stream
|
True/False,默认为True,获取内容立即下载开关
|
|
verity
|
True/False,默认为True, 认证SSL证书
|
|
cert
| 本地SSL证书路径 |
3.2 接口测试实战
1. 导入对应的包: import requests2. 弄清楚对应的接口四要素:接口URL、请求方法、请求参数、响应数据,3. 把这些内容用代码依次实现。
GET 请求示例
# get()方法的参数
requests.get(url, params=None, **kwargs)
- url: 页面的url链接
- params: url中的额外参数,字典或字节流,非必选代码示例1:一个简单的get请求
import requests
url = "http://xxxx.com/"
res = requests.get(url)
#获取对应的响应数据:可以对数据格式进行指定
print(res.text) #text得到的是一个html信息执行后终端输出一个巨长的html
代码示例二:使用params把分开的url参数、路径拼接到url,实现正常请求
#案例二: 把url参数的环境变量和对应的参数/路径分开
url = "http://xxx.com/"
url_path = "s=api/user/login"
res = requests.get(url, params=url_path) # 执行的时候会自动把参数拼接到url中
print(res.url) # 输出的查看url是否是一个正确且完整的url
3.3 常用响应( Response)数据
|
响应参数方法
|
响应参数概述
|
|
r.status_code
|
响应状态码
|
|
r.content
|
字节方式的响应体,会自动为你解码 gzip 和 deflate 压
缩
|
|
r.headers
|
以字典对象存储服务器响应头,但是这个字典比较特殊,
字典键不区分大小写,若键不存在则返回None
|
|
r.json()
|
Requests中内置的JSON解码器,必须带上()
|
|
r.url
|
获取url
|
|
r.encoding
|
编码格式
|
|
r.cookies
|
获取cookie
|
|
r.raw
|
返回原始响应体
|
|
r.text
|
字符串方式的响应体,会自动根据响应头部的字符编码进
行解码
|
|
r.raise_for_status()
|
失败请求(非200响应)抛出异常
|
状态码
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求200 OK//客户端请求成功
400 Bad Request//客户端请求有语法错误,不能被服务器所理解
401 Unauthorized//请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden//服务器收到请求,但是拒绝提供服务
404 Not Found//请求资源不存在,eg:输入了错误的URL
500 Internal Server Error//服务器发生不可预期的错误
503 Server Unavailable//服务器当前不能处理客户端的请求,一段时间后可能恢复正常代码示例
上面提到的所有的Response响应参数方法
语法结构:定义的返回值的接收对象.方法名
部分示例如下:
import requests
url = "http://xxxx.com/"
url_path = "s=api/user/login"
res = requests.get(url, params=url_path) # 执行的时候会自动把参数拼接到url中
# print(res.text)
print("url:",res.url)
print("json串:",res.json())
print("状态码:",res.status_code)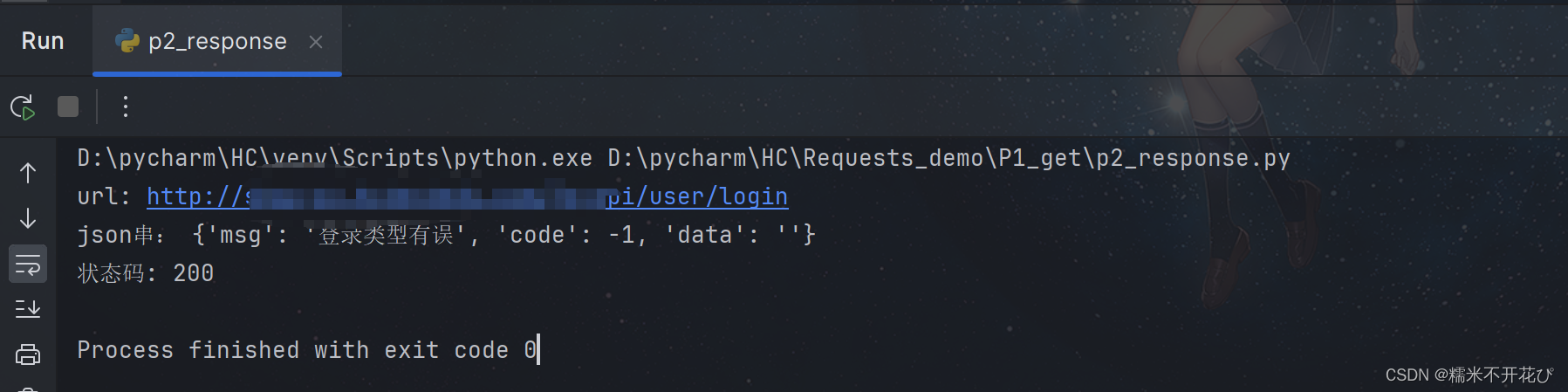
反过来说,如果发送请求之后,得到的响应数据不是我想要的呢?
解决思路: 首先把请求数据打印出来 打印请求的语法结构:接收返回值对象.request.方法名代码示例如下:
import requests
url = "http://xxxx.com/"
res = requests.get(url)
print("查看请求方法:",res.request.method)
print("查看请求url:",res.request.url)
print("查看请求body:",res.request.body)
print("查看请求头:",res.request.headers)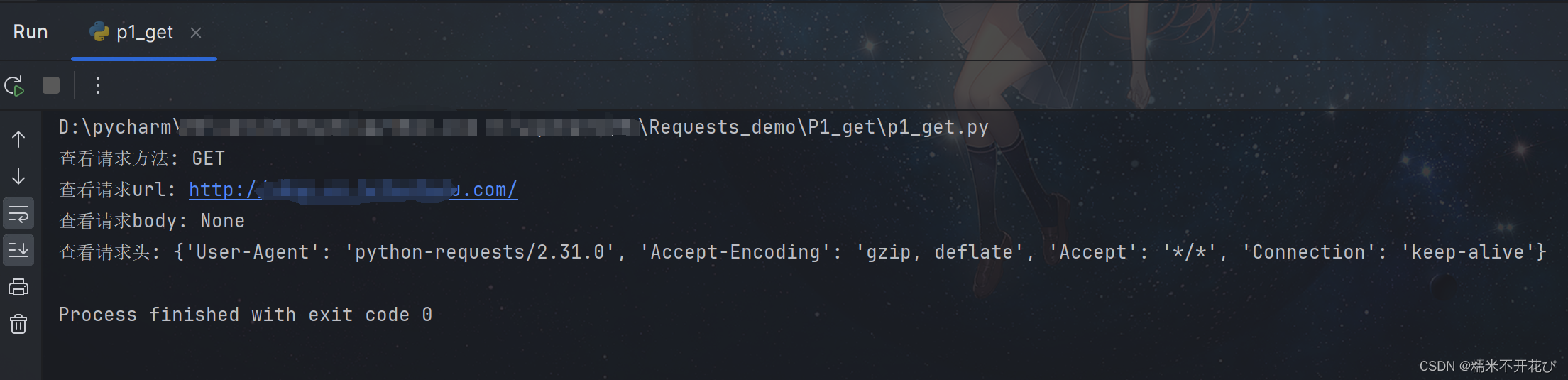
3.4 POST接口测试实战
之前我们一直也在强调,POST的请求参数的类型很多。
而控制它的就是由 请求头当中的 Content-Type 。
所以我们在开发的过程中需要注意客户端发送请求 (Request)时的Content-Type设置,如果设置的不准确,很有可能导致请求失 败,甚至也会返回415错误。
注:415 错误是 Unsupported media type,即不支持的媒体类型。
---------------->>>
一般Content-Type的使用遵守原则:
● 如果普通表单提交:Content-Type:application/x-www-form-urlencoded
● json格式: Content-Type:application/json
● 如果是文件上传:Content-Type:multipart/form-data
案例1:普通表单提交
post请求默认是以form表单提交的
encoding = "utf8"
"""
post请求:登陆接口、
请求参数数据类型x-www-form-urlencoded格式(form表单提交)
接口请求四要素:url、请求方法、请求参数、响应数据
"""
import requests
# ur完整的请求l
url = "http://域名/路径/xxx"
# 公共参数
pulic_data = {"application":"app","application_client_type":"weixin"}
# 请求参数:body
data = {"accounts":"hailey","pwd":"hailey123","type":"username"}
# ------------------发送请求------------------
res = requests.post(url,params=pulic_data,data=data)
# ------------------获取响应数据------------------
print(res.json())
print("响应头:",res.headers)
# ------------------获取请求数据------------------
print("请求头:",res.request.headers)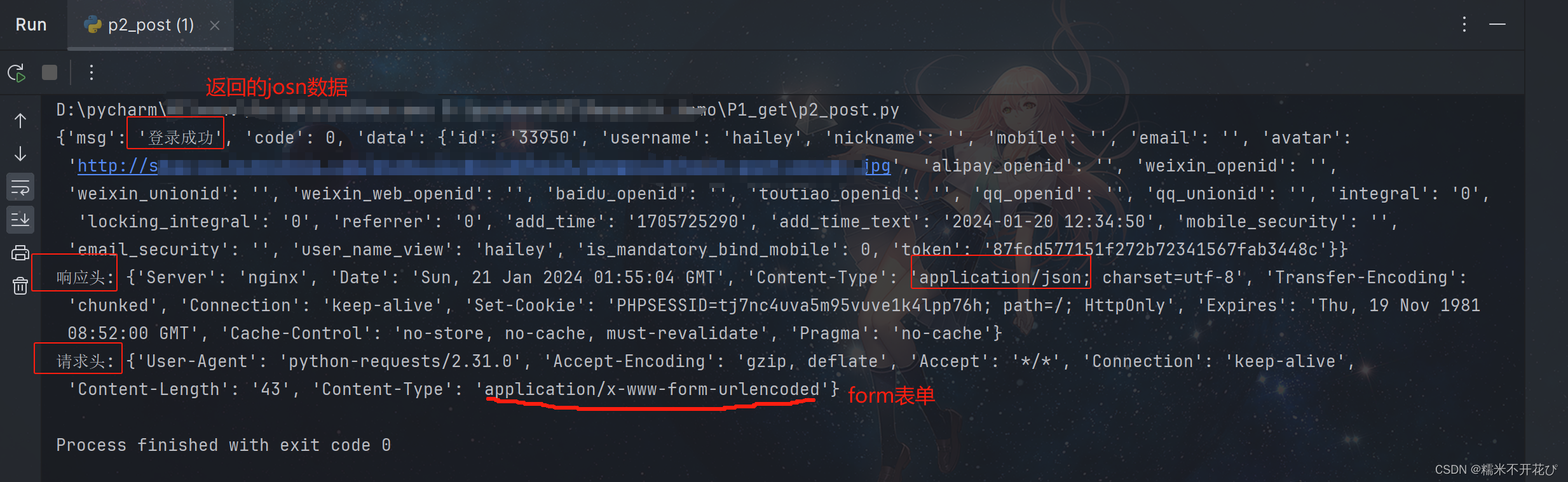
案例2:json格式
想要指定请求参数的数据类型为json:
方法1:只需要加一个json参数,把data赋给json即可
--------------->>
案例1、案例2,我这边使用的是同一个测试网址,是因为该网址做了特殊处理,只要提交的请求参数正确,不论哪种请求的数据类型都可以兼容。
实际工作中,是否能够做到这样兼容,需要看公司的代码逻辑有没有这样处理
# 指定请求数据为json格式提交:方法1
import requests
url = "http://域名/路径/xxx"
pulic_data = {"application": "app", "application_client_type": "weixin"}
data = {"accounts": "hailey", "pwd": "hailey123", "type": "username"}
# 指定请求参数的数据类型为json,只需要加一个json参数,把data赋给json即可
res = requests.post(url,params=pulic_data,json=data)
print("请求数据:",res.request.headers)
print("响应数据:",res.headers)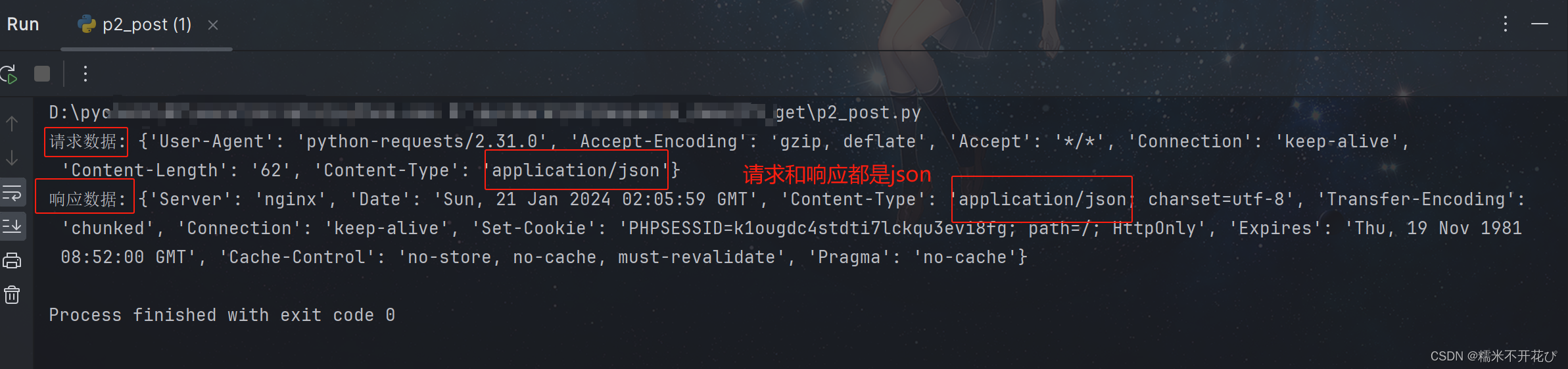
想要指定请求参数的数据类型为json:并且能不能请求参数的还是以data提交,只设置一下请求头为json呢?
方法2:
① 添加请求头设置
② data是字典类型,需要转换为json类型,不然打印响应信息会报错
------------>>
方式2处理起来稍微麻烦点,但是如果是封装的代码,就可以灵活处理,只设置请求头,可以在不同的地方使用不同的请求数据类型
具体代码如下:
import json
import requests
url = "http://xxx.com/index.php?s=/api/user/login"
pulic_data = {"application": "app", "application_client_type": "weixin"}
data = {"accounts": "hailey", "pwd": "hailey123", "type": "username"}
json_data = json.dumps(data) # 将data字典转为json
header = {'Content-Type':'application/json;charset=utf-8'} # 添加请求头设置
res = requests.post(url,params=pulic_data,headers=header,data=json_data)
print("请求数据:", res.request.headers)
print("响应数据:", res.request.headers)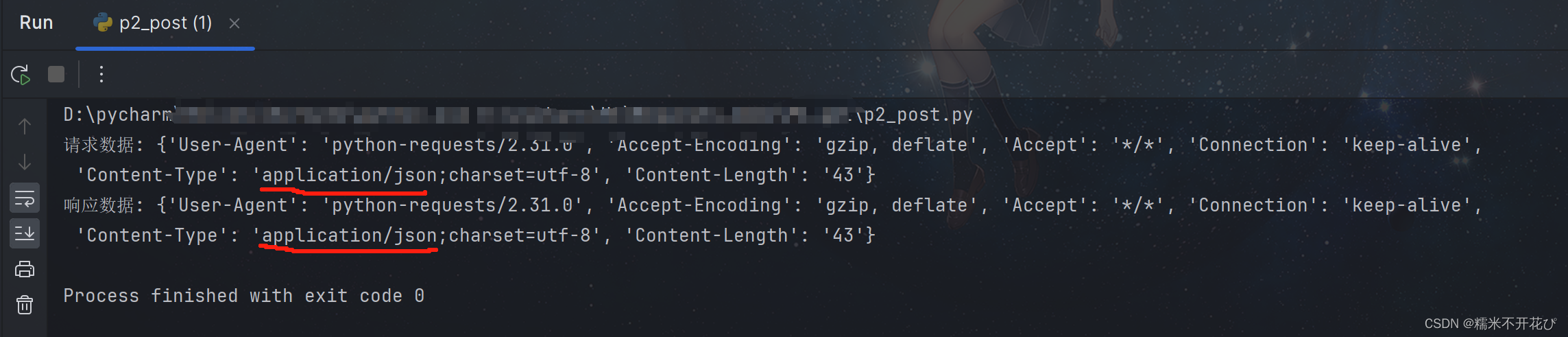
案例3:文件上传
基于flask框架实现的文件上传进行上传文件。Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架。
# Flask框架安装
pip install flask # 安装命令
pip show flask # 安装验证flask的简单应用
定义一个Flask 应用程序对象 : app = Flask ( __name__ )静态路由: @app . route ( '/upload' )指定允许的请求方法:@app.route('/login', methods=['GET', 'POST'])
上传文件接口
flask应用的完整代码(基于这段代码,才能完成下面的上传操作):
# flie name:uploadFile.py
from flask import Flask, request, jsonify
import os
# 创建了一个名为 app 的 Flask 应用程序对象。
app = Flask(__name__)
# 设置接口的路径,以及对应的请求方式
@app.route('/upload', methods=['POST'])
def upload():
# 当没有image属性提示用户
if 'image' not in request.files:
data = {
'msg': '当前未填写image参数',
'code': 400,
}
return jsonify(data)
# 获取到当前图片请求中的文件
file = request.files['image']
print(file.filename)
# 把对应的图片进行保存到当前的目录下的img目录(保存在当前服务器某个目录下)
save_path = os.path.join('img', file.filename)
file.save(save_path)
data = {
'msg': '上传成功',
'code': 200
}
return jsonify(data)
if __name__ == '__main__':
app.run()
先把代码运行,让服务启动(启动的是我们本地电脑的服务),不要手动停止
上传文件请求
# file name:p3_file.py
# 基于flask实现文件上传
import requests
# url:服务器 + 代码中定义的路径
url = "http://127.0.0.1:5000/upload"
# 请求参数:image
file_data = {"image":open("python进阶.png","rb")}
res = requests.post(url,files=file_data)
print("响应数据:",res.json())
print("响应的数据类型:",res.headers)
案例4:保持Session
如下代码,有两个接口:登录接口,查询信息接口,必须登录之后才可以查询用户信息。当接口之间有上下游关联时,就需要 保持Session,即会话机制Session也是一种鉴权,从头到尾,关闭就会失效具体项目不同,有的只有token鉴权,没有Session鉴权
保持Session接口
由于手上没有可用的具有Session鉴权的项目,这里还是使用falks实现一个本地服务器,设置Session机制来演示效果;
以下是falks代码:
file name:loginApi.py
from flask import Flask, request, jsonify, session
import os
app = Flask(__name__)
app.secret_key = os.urandom(24) # 设置一个密钥,用于加密 session 数据
# 模拟用户信息,实际项目中需要替换为真实的用户信息
data = {
"username": "hailey",
"password": "admin"}
# 登录接口
@app.route('/login', methods=['POST'])
def login():
data = request.get_json()
username = data.get('username')
password = data.get('password')
if username in users and users[username] == password:
# 登录成功,设置session
session['logged_in'] = True
return 'Login successful', 200
else:
return 'Login failed', 401
# 查询信息接口,需要登录才能访问
@app.route('/get_info')
def get_info():
if 'logged_in' in session and session['logged_in']:
# 用户已登录,返回用户信息
return 'User Info: OK' # 返回用户信息
else:
# 用户未登录,返回未授权的状态码
return 'Unauthorized', 401
if __name__ == '__main__':
app.run(debug=True)还是先把代码运行,让服务启动(启动的是我们本地电脑的服务),不要手动停止
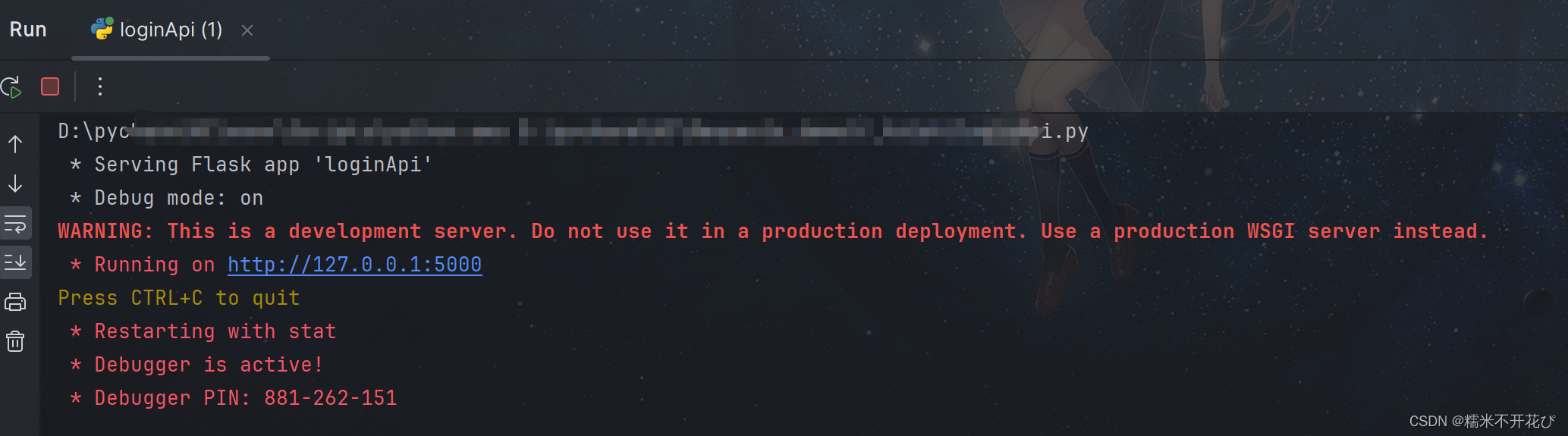
发送Session接口
错误示范:
# file name:p4_session.py
import requests
data = {
"username": "hailey",
"password": "admin"}
#方法1:显示对应的未授权
response = requests.post("http://127.0.0.1:5000/login",json=data)
print("响应内容:",response.text)
response = requests.get("http://127.0.0.1:5000/get_info")
print(":",response.text)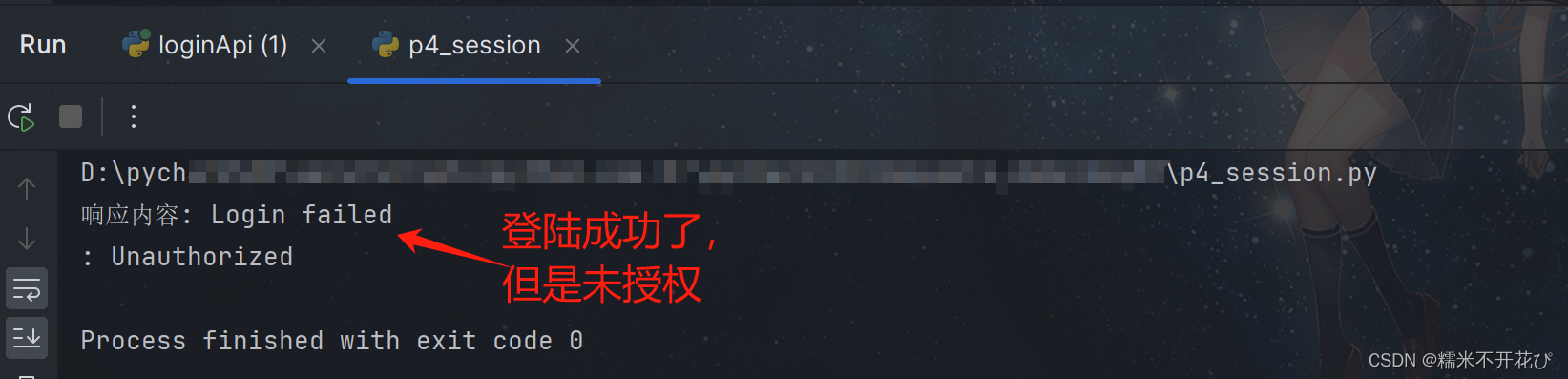
正确姿势:
在requests库中,如果需要进行session保持 1、需要实例化一个对象 2. 通过对应的对象去进行方法调用
import requests
data = {
"username": "hailey",
"password": "admin"}
session = requests.Session() #示例化对象
res = session.post("http://127.0.0.1:5000/login",json=data)
print("响应内容:",res.text)
res = session.get("http://127.0.0.1:5000/get_info")
print("get_info:",res.text)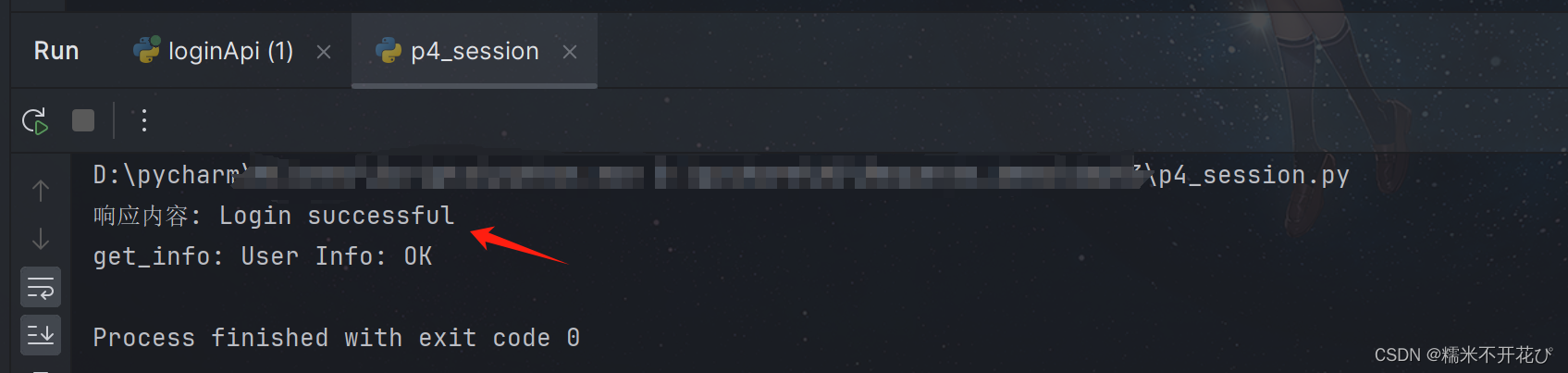
3.5 josn概述补充
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于数据的序列化和传输。它基于JavaScript的语法,但可以被多种编程语言支持和解析。
下面是一个简单的JSON示例:
{
"name": "John",
"age": 30,
"isStudent": false,
"grades": [85, 92, 78],
"address": {
"street": "123 Main St",
"city": "New York"
}
}JSON的优点
1. 简洁:相对于其他数据交换格式,JSON的语法简洁明了,易于阅读和编写。2. 可读性好:JSON使用人类可读的文本格式,便于开发人员理解和调试。3. 平台无关:JSON可以被多种编程语言支持和解析,使得不同平台之间的数据交换变得更加容易。4. 支持复杂数据结构:JSON支持嵌套的对象和数组,可以表示复杂的数据结构。在编程中,您可以使用相应编程语言提供的JSON库或工具来解析和生成JSON数据,以实现数据的序列化、传输和解析。
3.6?断言(Assert)
断言(Assertion)是一种在编程中常用的技术,用于检查代码中的条件是否满足,以确保程序的正确性。断言通常在程序中的关键位置或重要的检查点处使用,用于验证预期的条件是否为真。断言的基本概念是:在代码中插入一条断言语句,该语句会在运行时进行条件判断:????????如果条件为假(False),则会触发断言错误,并中断程序的执行。????????如果条件为真(True),则程序会继续执行。
使用断言的目的
断言通常用于以下目的:1. 调试和验证 :断言可以用于验证程序的正确性和逻辑,帮助开发人员在调试过程中发现问题和错误。通过断言,可以检查程序中的假设是否成立,并在条件不满足时提前发现问题。2. 防御性编程 :断言可以用于检查输入参数有效性或执行结果的正确性,以避免程序在非预期情况下继续行。3. 测试和验证 :断言可以用于编写单元测试或验证代码的正确性,帮助捕捉潜在的错误和异常情况。
代码示例
# assert 表达式,表达式失败之后显示的字符串
import requests
url = "http://xxxx.com/index.php?s=/api/user/login"
# 公共参数
pulic_data = {"application":"app","application_client_type":"weixin"}
# 请求参数:body
data = {"accounts":"hailey","pwd":"hailey123","type":"username"}
# ------------------发送请求------------------
res = requests.post(url,params=pulic_data,data=data)
# ------------------获取响应数据------------------
print(res.json())
response = res.json()
# ------------------获取数据,进行断言处理------------------
# 断言成功
# assert "登录成功" == response["msg"],"期望结果是:{0},实际结果是:{1}".format("登录成功",response["msg"])
# 断言失败
assert "登录失败" == response["msg"],"期望结果是:{0},实际结果是:{1}".format("登录失败",response["msg"])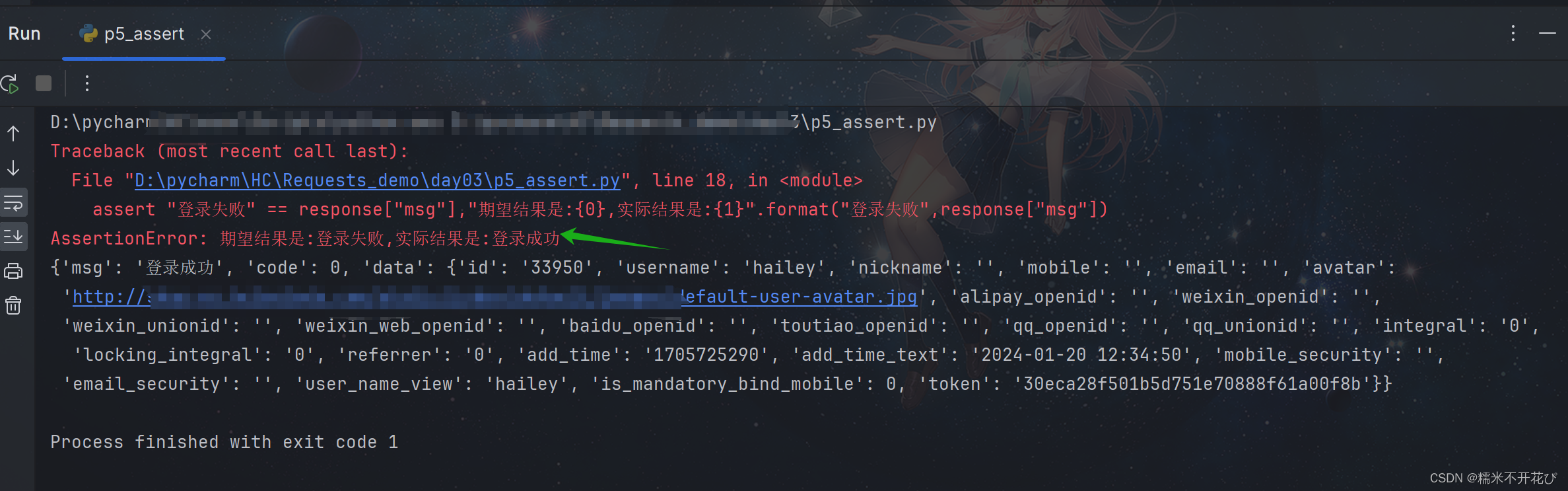
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -后端架构搭建
- 第二十章 : Spring Boot 集成RabbitMQ(四)
- Python面向对象之继承
- C/C++常见面试题(五)
- 算法训练营Day39(动态规划)
- YOLOv5改进 | SPPF | 将RT-DETR模型AIFI模块和Conv模块结合替换SPPF(全网独家改进)
- EAS WEB附件下载实现
- [C++]使用yolov5的onnx模型结合onnxruntime和bytetrack实现目标追踪
- MySQL 简介
- 让企业的招投标文件、生产工艺、流程配方、研发成果、公司计划、员工信息、客户信息等核心数据更安全。