【深度强化学习】确定性策略梯度算法 DDPG
前面讲到如 REINFORCE,Actor-Critic,TRPO,PPO 等算法,它们都是随机性策略梯度算法(Stochastic policy),在广泛的任务上表现良好,因为这类方法鼓励了算法探索,给出的策略是各个动作的概率分布。
实际上策略梯度方法分为两类:一类是随机性策略梯度算法,另一类是确定性策略梯度算法。
确定性策略可能更适合需要精确控制的任务,在这些任务中,任何偏离最佳操作的行为都会对结果产生重大影响(如:下棋)。而随机策略可能更适合涉及不确定性或探索的任务,因为它们允许智能体尝试不同的行动并从其结果中学习。
DDPG 深度确定性策略梯度 Deep Deterministic Policy Gradient
直觉
DQN 挺好的,但是只能离散动作,不能连续动作,关键原因在于
max
?
a
Q
(
S
,
a
)
\max_a Q(S,a)
maxa?Q(S,a),在无限多的动作下不适用。
解决方法:
max
?
a
Q
(
s
,
a
)
=
Q
(
s
,
arg
?
max
?
a
Q
(
s
,
a
)
)
→
Q
(
s
,
μ
θ
(
s
)
)
\max_a Q(s,a) = Q(s,\arg \max_a Q(s,a)) \to Q(s, \mu_{\theta}(s))
amax?Q(s,a)=Q(s,argamax?Q(s,a))→Q(s,μθ?(s))
核心思想:既然在连续的时候从众多
a
a
a 里面选一个使得
Q
Q
Q 最大的
a
a
a 这么难,那我就用一个网络直接近似给出这个
a
a
a,代替这个 max操作,这个网络就叫
μ
θ
\mu_\theta
μθ?
图示
实际上是一种 Actor-Critic 方法
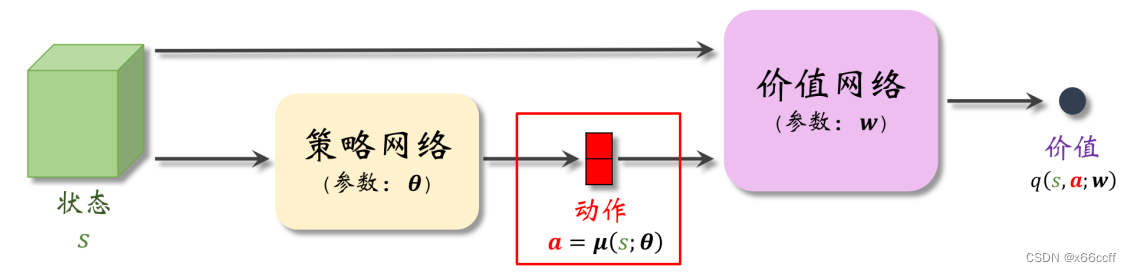
这里策略网络
μ
(
s
;
θ
)
\mu(s;\theta)
μ(s;θ)给出的动作
a
a
a 是确定的,而不是一个分布。
伪代码与解释

- 动作 Clip : 在动作选择的时候,clip,因为动作是连续的,是由神经网络给出的,防止爆nan
- (动作添加噪声 N ( 0 , σ 2 ) \mathcal{N}(0,\sigma^2) N(0,σ2)):探索 or 稳健
- (动作输入之前批标准化):平衡连续动作量纲
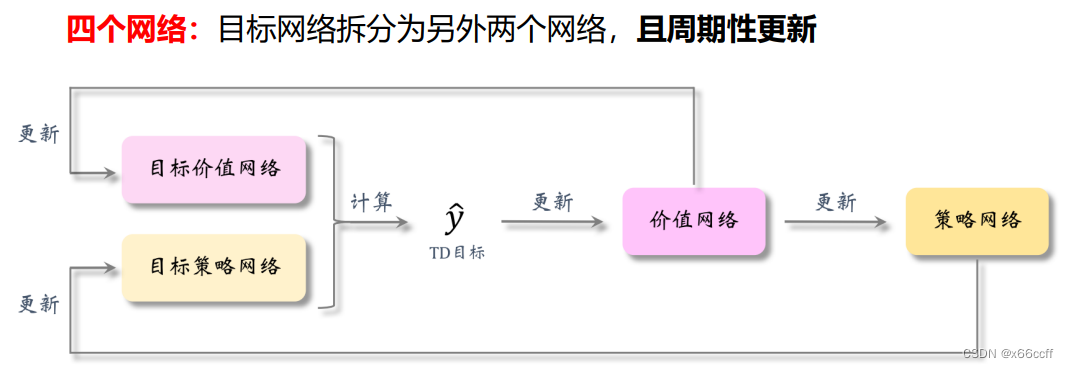
- 每得到一批数据,分别更新 Critic 、 Actor、慢 Critic、慢 Actor:
- Critic Q ? ( ? , ? ) Q_{\phi}(\cdot,\cdot) Q??(?,?) 更新:利用 ( r , s ′ ) (r,s') (r,s′) 计算 TD target,计算的时候都使用 target 参数( θ t a r g e t , ? t a r g e t \theta_{target}, \phi_{target} θtarget?,?target?) ,TD target 和 Q ( s , a ) Q(s,a) Q(s,a) 计算 TD loss, 最小化,梯度下降。
- Actor μ θ ( ? ) \mu_\theta(\cdot) μθ?(?) 更新:我们假设 Critic 已经是一个良好的估计,那么就让 θ \theta θ 往能够使得 Critic 满意的方向走(选择使得 Critic 满意的连续动作 a a a),最大化,梯度上升。
- 慢 Critic 和慢 Actor 更新:用移动平均更新即可(思想:类似于 DQN 目标网络,减少自举法带来的偏差)
DDPG 加特技
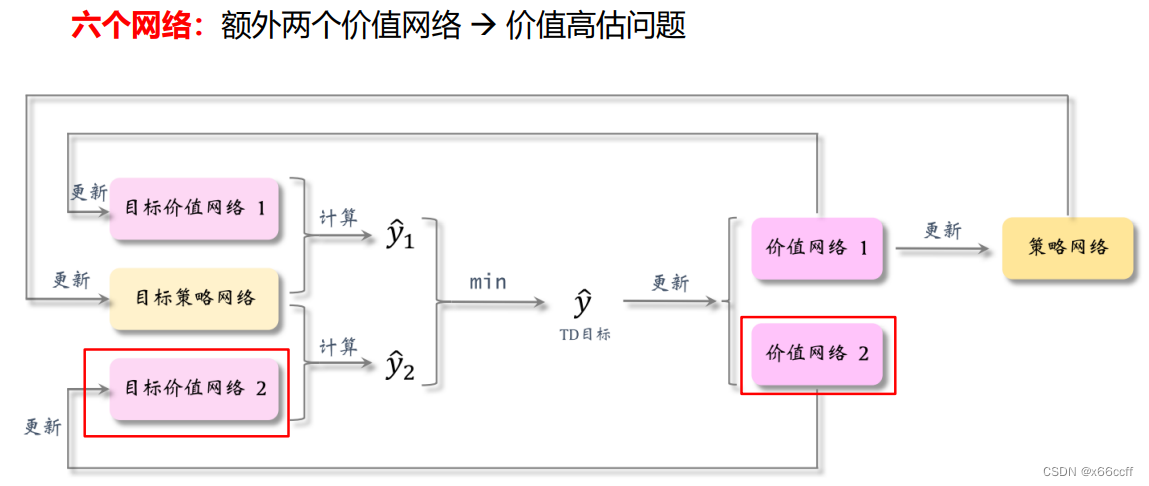
TD3:双延时 DDPG(Twin Delayed Deep Deterministic Policy Gradient)
截断双Q学习:Clipped Double Q-Learning
实验效果
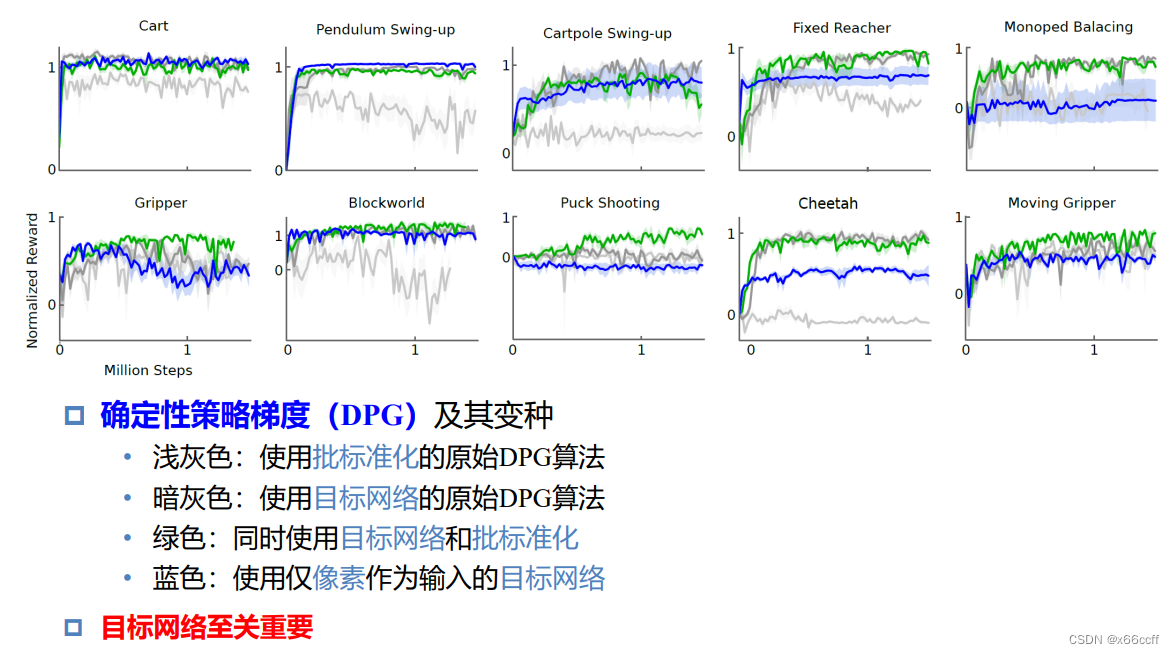
变化路线

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【i.MX6ULL】使用buildroot构建根文件系统
- CSS:元素显示模式与背景
- 二叉搜索树的简单C++类实现
- MATLAB曲线拟合
- 第十三章 Squid代理服务器 传统代理服务器
- 单片机开发从小工到专家
- QT+OSG/osgEarth编译之七十六:gltf+Qt编译(一套代码、一套框架,跨平台编译,版本:osgEarth-3.3插件库osgdb_gltf)
- 抖店商家对接带货主播建议,远离头部主播保平安,附沟通话术模板
- linux网络管理nmcli命令详解
- 德语B2 SampleAcademy