五、模 板
1 泛型编程
以往我们想实现一个通用的交换函数,可能是通过下面的方式来实现的:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
//往下持续重载
使用函数重载虽然可以实现,但是还是有以下几个不好的地方:
- 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现,就需要用户手动增加对应的函数。
- 代码的可维护性比较低,一个出错可能所有的重载均出错。
为了解决这个痛点,在C++中,引入了模板这一概念,让编译器根据不同的类型利用该模板来生成代码。
通过编写与类型无关的通用代码,就被称为泛型编程,而模板正是泛型编程的基础。
模板可分为函数模板和类模板,下面我们依次进行介绍。
2 函数模板
2.1 函数模板的定义
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
其语法为:
template <typename T1, typename T2,......,typename TN>
返回值类型 函数名(参数列表){}
例:
template<typename T>
void Swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
说明:typename是用来定义模板参数的关键字,也可以使用class,但在这个地方不能用struct代替class。
2.2 函数模板的原理
实际上,模板本身并不是函数,它更像一张蓝图,编译器通过它来产生特定具体类型的函数。所以模板其实就是将本来应该我们做的重复的事情交给了编译器。
例:
#include <iostream>
using namespace std;
template<typename T>
void Swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
int main()
{
int i1 = 10;
int i2 = 20;
Swap(i1, i2);
double d1 = 10.0;
double d2 = 20.0;
Swap(d1, d2);
char a = '0';
char b = '9';
Swap(a, b);
return 0;
}
图解:
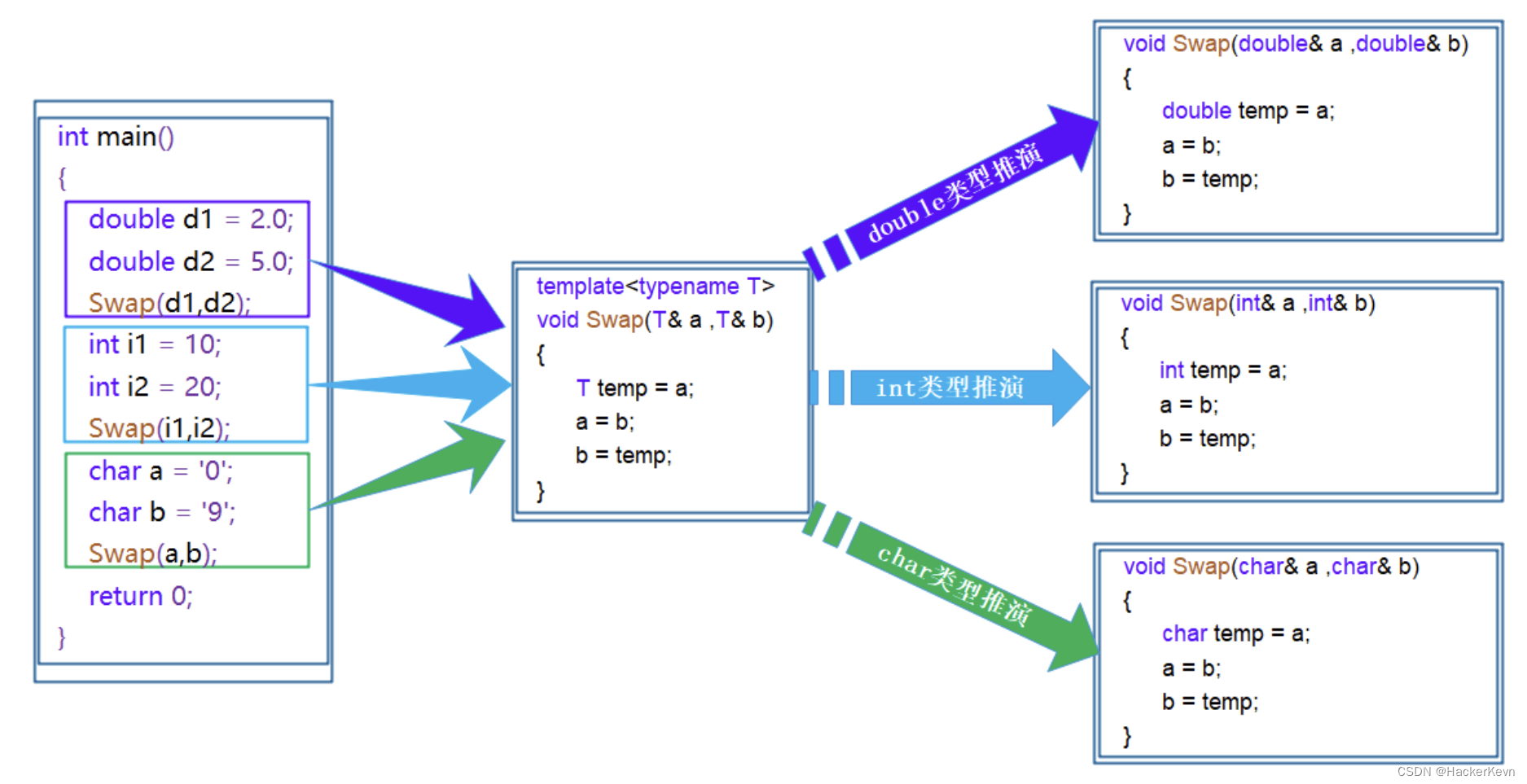
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
这一过程我们可以通过对刚才例子中的代码进行调试来观察到:
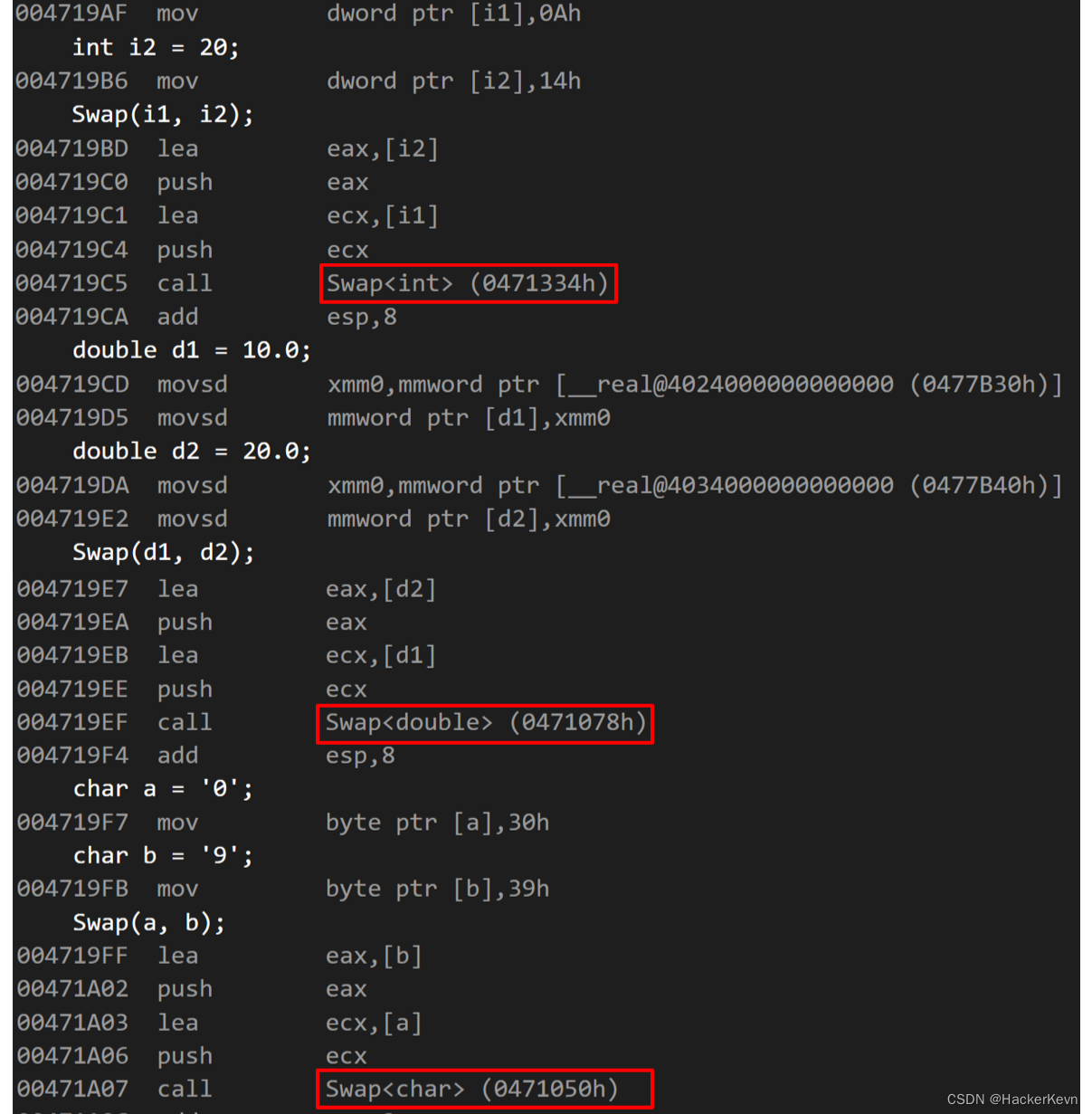
从汇编指令可以看到,对于不同的实参类型所调用的Swap函数并不相同。
2.3 函数模板的实例化
用不同类型的参数使用函数模板称为函数模板的实例化。
模板参数实例化分为:隐式实例化和显式实例化。
2.3.1 隐式实例化
隐式实例化是让编译器根据实参推演模板函数实际类型。
需要注意的是,在模板中,编译器不会进行类型转换操作,所以下面的代码运行起来是有问题的:
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10;
double d1 = 10.0;
Add(a1, d1);
return 0;
}
运行结果:

之所以编译器会报错,是因为在编译期间,当编译器看到Add(a1, d1);时,需要推演其实参类型,而由于模板参数列表中只有一个T,但是通过实参a1既可以将T推演为int,又可以通过实参d1将T推演为double,所以编译器无法确定此处到底该将T确定为int还是double从而导致报错。
此时要么将语句改为Add(a, (int)d);即让用户自己来强制转化,要么就使用显式实例化。
2.3.2 显式实例化
显式实例化是在函数名后的<>中指定模板参数的实际类型。
注意,当参数中的类型和显式实例化的类型不匹配时,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错。
例:
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10;
double d1 = 10.0;
int a2 = Add<int>(a1, d1);
cout << a2 << endl;
return 0;
}
运行结果:

2.4 函数模板的特征
- 一个非模板函数可以和一个同名的函数模板同时存在。
例:
#include <iostream>
using namespace std;
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
int main()
{
//与非模板函数匹配,编译器不需要实例化
cout << Add(1, 2) << endl;
//调用编译器实例化的Add版本
cout << Add<int>(1, 2) << endl
return 0;
}
运行结果:

- 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会将模板实例化。如果模板实例化的函数匹配程度更高,那么将选择模板。
例:
#include <iostream>
using namespace std;
//专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
//通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
int main()
{
cout << Add(1, 2) << endl; // 与非函数模板类型完全匹配,不需要函数模板实例化
cout << Add(1, 2.0) << endl; // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
return 0;
}
运行结果:

- 模板函数不允许自动类型转换,而普通函数可以进行自动类型转换。
3 类模板
类模板的引入,其实是为了解决C语言这样的一个痛点:
typedef int STDataType;
class Stack
{
private:
STDataType* _a;
size_t _top;
size_t _capacity;
};
可以看到,一旦我们这样声明一个Stack,那么它将只能存放int类型的数据,当我们想存其他类型的数据时,就还需要另写一个Stack,而如果使用类模板的话,这个问题就迎刃而解了。
3.1 类模板的定义
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
};
这样一来,刚才的Stack的类模板形式就为
template<class T>
class Stack
{
private:
T* _a;
size_t _top;
size_t _capacity;
};
3.2 类模板的特征
在C语言中,使用typedef对一个自定义类型重命名后,它的类名就是它的类型,而对于类模板,其类名和类型是区分开的,当类名加上模板参数后才是它的类型。
除此之外,类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<> 中。而且,类模板名字不是真正的类,而实例化的结果才是真正的类。
例:
Stack<int> s1;//类型为Stack<int>
Stack<double> s2;//类型为Stack<double>
关于类模板,我们还需要注意以下2点:
- 类模板的声明和定义要放在同一个文件,否则会链接错误,这和我们之前强调的声明和定义要分离得区分开。原因后续进行解释。
- 类模板中的函数放在类外进行定义时,需要加模板参数列表。
例:
//动态顺序表
//注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具,目前不需掌握
#include <iostream>
using namespace std;
template<class T>
class Vector
{
public:
Vector(size_t capacity = 10)
: _pData(new T[capacity])
, _size(0)
, _capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size() { return _size; }
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}
private:
T* _pData;
size_t _size;
size_t _capacity;
};
//类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{
if (_pData)
delete[] _pData;
_size = _capacity = 0;
}
3 非类型模板参数
以往我们定义一个静态数组模板是这样实现的:
#include <iostream>
using namespace std;
#define N 10
template<class T>
class Array
{
private:
T _a[N];
};
int main()
{
Array<int> a1;
Array<double> a2;
return 0;
}
实际上,以这样的方式实现有个缺陷,就是当我们想让a1的容量为10而a2的容量为100的话这个模板就无法实现了。
要解决这个问题,我们就需要引入非类型模板参数。
实际上,模板参数有类型形参与非类型形参,类型形参就是跟在class或者typename之类的参数类型名称,之前我们举的例子就是用的这一类型;而非类型形参就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
有了非类型形参,要实现刚才的需求我们就可以这样做:
#include <iostream>
using namespace std;
template<class T,size_t N = 10>//缺省值为10
class Array
{
private:
T _a[N];
};
int main()
{
Array<int> a1;//容量为10
Array<double, 100> a2;//容量为100
return 0;
}
注意:
- 非类型模板参数只能是整型常量,且不能更改,也就是说浮点数、类对象以及字符串等是不允许作为非类型模板参数的。
例1:
#include <iostream>
using namespace std;
template<class T, size_t N = 10>
void Func(const T& a)
{
N = 10;//非类型模板参数不能修改
}
int main()
{
Func(1);
return 0;
}
运行结果:

例2:
#include <iostream>
using namespace std;
template<class T, double N = 10>//非类型模板参数只能是整型
class Array
{
private:
T _a[N];
};
int main()
{
Array<int> a1;
Array<double, 100> a2;
return 0;
}
运行结果:

- 非类型模板参数必须在编译期就能确认结果。
在C++11中,引入了一个新的容器array,就用到了非类型模板参数。

和传统定义数组相比,使用array定义数组对越界访问的行为会更加严格,由于这里仅以array来说明非类型模板参数的应用,所以对array的更多特性不做说明。
4 模板的特化
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型时可能会得到一些错误的结果,需要特殊处理。
比如:实现一个专门用来进行小于比较的函数模板:
#include <iostream>
#include "Date.h"
using namespace std;
template<class T>
bool Less(T left, T right)
{
return left < right;
}
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
}
运行结果:

可以看到,Less绝对多数情况下都可以正常比较,但是在特殊场景下就会得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向对象的内容,而比较的是p1和p2指针的地址,这就无法达到预期的结果。
要解决这个问题,就要对模板进行特化。即:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。
模板特化中分为函数模板特化与类模板特化,下面我们分别来进行介绍。
4.1 函数模板特化
函数模板的特化步骤:
- 必须要先有一个基础的函数模板。
- 关键字
template后面接一对空的尖括号<>。 - 函数名后跟一对尖括号
<>,尖括号中指定需要特化的类型。 - 函数形参表:必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报错。
我们以刚才的代码为例进行Less函数模板的特化:
#include <iostream>
#include "Date.h"
using namespace std;
template<class T>
bool Less(T left, T right)
{
return left < right;
}
//模板的特化
template<>
bool Less<Date*>(Date* left, Date* right)
{
return *left < *right;
}
int main()
{
cout << Less(1, 2) << endl;
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl;
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl;
return 0;
}
运行结果:

当参数的类型为Date*时,编译器就会调用经过特化后的模板函数,从而得到期望的结果。
实际上,一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出:
bool Less(Date* left, Date* right)
{
return *left < *right;
}
这种实现方式简单明了,代码的可读性高也更容易书写,因为对于一些参数类型复杂的函数模板,使用特化会很麻烦,所以函数模板不建议特化。
4.2 类模板特化
4.2.1 全特化
全特化就是将模板参数列表中所有的参数都确定化。
例:
#include <iostream>
using namespace std;
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//全特化
template<>
class Data<int, char>
{
public:
Data() { cout << "Data<int, char>" << endl; }
private:
int _d1;
char _d2;
};
void Test()
{
Data<int, int> d1;
Data<int, char> d2;
}
int main()
{
Test();
return 0;
}
运行结果:

4.2.2 偏特化
任何针对模版参数进一步进行条件限制设计的特化版本就称为偏特化。比如对于以下模板类:
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
如果要进行偏特化,有以下两种方式:
1. 部分特化
将模板参数类表中的一部分参数特化。
例:
#include <iostream>
using namespace std;
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//将第二个参数特化为int
template <class T1>
class Data<T1, int>
{
public:
Data() { cout << "Data<T1, int>" << endl; }
private:
T1 _d1;
int _d2;
};
void Test()
{
Data<int, int> d1;
Data<char, int> d2;
}
int main()
{
Test();
return 0;
}
运行结果:

2. 参数更进一步的限制
采用这种方式进行特化,那么偏特化将并不仅仅是指特化部分参数,而是针对模板参数进行更进一步的条件限制所设计出来的一个特化版本。
例:
#include <iostream>
using namespace std;
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:
Data() { cout << "Data<T1*, T2*>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//两个参数偏特化为引用类型
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public:
Data(const T1& d1, const T2& d2)
: _d1(d1)
, _d2(d2)
{
cout << "Data<T1&, T2&>" << endl;
}
private:
const T1& _d1;
const T2& _d2;
};
void Test()
{
Data<double, int> d1; //调用特化的int版本
Data<int, double> d2; //调用基础的模板
Data<int*, int*> d3; //调用特化的指针版本
Data<int&, int&> d4(1, 2); //调用特化的引用版本
}
int main()
{
Test();
return 0;
}
运行结果:

4.2.3 类模板特化应用示例
下面的场景中,v1和v2哪个能正确地实现日期升序排序呢?
#include <vector>
#include "Date.h"
#include <algorithm>
template<class T>
struct Less
{
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
int main()
{
Date d1(2022, 7, 7);
Date d2(2022, 7, 6);
Date d3(2022, 7, 8);
vector<Date> v1;//v1存放Date对象
v1.push_back(d1);
v1.push_back(d2);
v1.push_back(d3);
sort(v1.begin(), v1.end(), Less<Date>());
vector<Date*> v2;//v2存放Date对象的地址
v2.push_back(&d1);
v2.push_back(&d2);
v2.push_back(&d3);
sort(v2.begin(), v2.end(), Less<Date*>());
return 0;
}
调试结果:
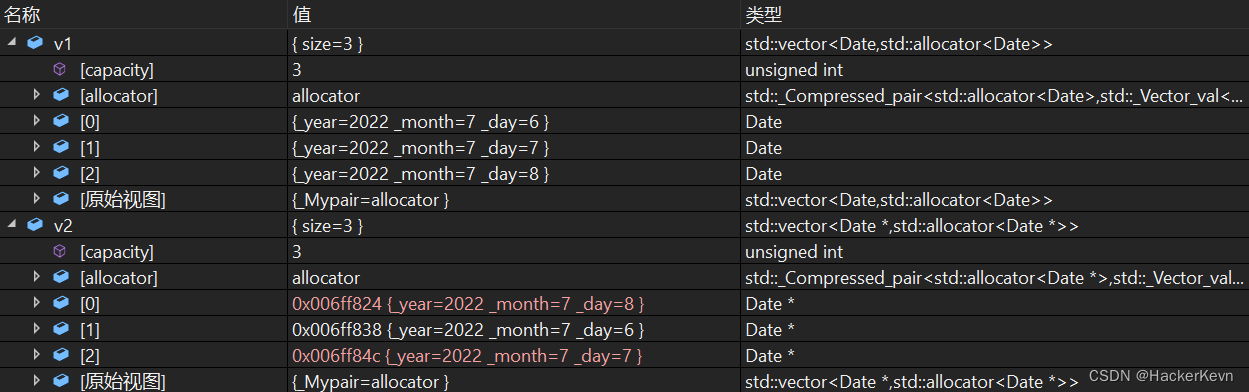
从调试结果可以看到,当我们对v1进行排序时,由于v1中存放的是Date类的对象,所以能正确排序;而对v2进行排序时,v2中存放的是Date类对象的地址,但是sort在按Less函数模板排序时实际比较的是v2中指针的地址,因此无法达到预期。
此时,我们就可以使用类模板特化来处理上述问题:
#include <vector>
#include "Date.h"
#include <algorithm>
template<class T>
struct Less
{
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
// 对Less类模板按照指针方式特化
template<>
struct Less<Date*>
{
bool operator()(Date* x, Date* y) const
{
return *x < *y;
}
};
int main()
{
Date d1(2022, 7, 7);
Date d2(2022, 7, 6);
Date d3(2022, 7, 8);
vector<Date> v1;//v1存放Date对象
v1.push_back(d1);
v1.push_back(d2);
v1.push_back(d3);
sort(v1.begin(), v1.end(), Less<Date>());
vector<Date*> v2;//v2存放Date对象的地址
v2.push_back(&d1);
v2.push_back(&d2);
v2.push_back(&d3);
sort(v2.begin(), v2.end(), Less<Date*>());
return 0;
}
调试结果:
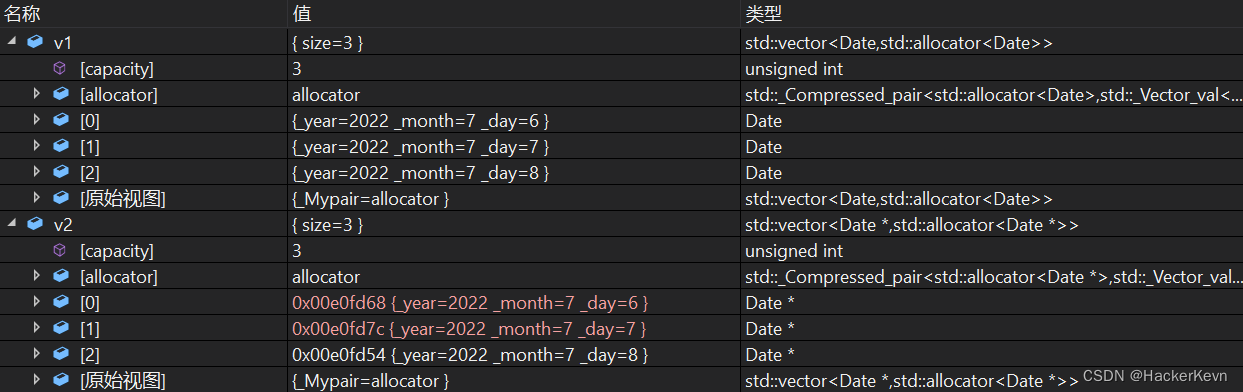
从调试结果可以看到,对Less类模板进行特化之后,就可以得到正确的结果。
5 模板的分离编译
分离编译指的是,一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程。
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
//Func.h
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
//Func.cpp
#include "Func.h"
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
//main.cpp
#include "Func.h"
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.0, 2.0) << endl;
return 0;
}
运行结果:

从运行结果可以看到,编译器报出了链接错误,是什么原因呢?
我们知道,C/C++程序要运行,一般要经历以下步骤:
-
预处理:涉及头文件的展开、宏替换、条件编译、去掉注释等。
-
编译:按照语言特性对程序进行词法、语法、语义分析,检查错误无误后生成汇编代码。
-
汇编:将汇编代码转换成二进制机器码。
-
链接:将多个obj文件合并成一个,并处理没有解决的地址问题。
那么刚才的程序按照流程应该经历下面一个过程:
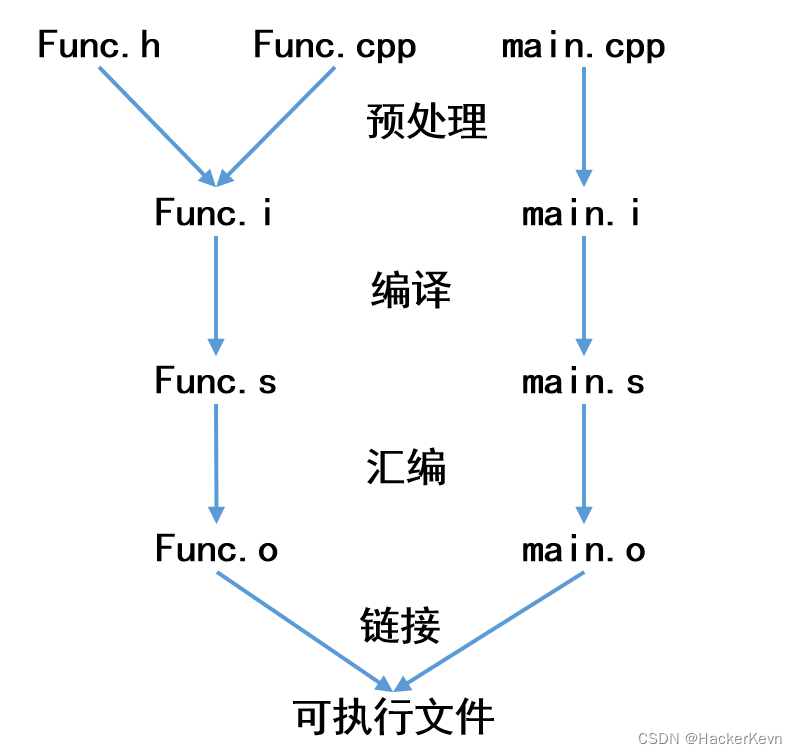
预处理阶段时,编译器还能够正常运行。而在编译阶段时,由于编译器在Func.i中没有看到Add函数的实例化,因此不会生成具体的加法函数,也就没有生成加法函数的地址。到了链接阶段,需要找到main.o中调用的Add<int>和Add<double>的地址时,由于在编译阶段没有生成地址所以在链接时报错。
这就是之前我们说类模板的声明和定义要放在同一个文件的原因。
要解决这个问题,有两种方法:
1. 在模板定义的位置进行显式实例化
例:
//Func.h
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
//Func.cpp
#include "Func.h"
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
//在模板定义的位置进行显式实例化
template
double Add<double>(const double& left, const double& right);
template
int Add<int>(const int& left, const int& right);
//main.cpp
#include "Func.h"
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.0, 2.0) << endl;
return 0;
}
运行结果:

但这种方法实际上并不实用,所以不推荐。
2. 将声明和定义放在同一个文件
按照编译的流程,在编译的时候没有找到的地址会在链接阶段去找,而将声明和定义放在同一个文件后,在编译阶段就可以将函数的地址生成,这就是将模板的声明和定义放在同一个文件所解决的本质问题。
例:
//Func.h
#include <iostream>
using namespace std;
//将声明和定义放在同一个文件
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
//main.cpp
#include "Func.h"
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.0, 2.0) << endl;
return 0;
}
运行结果:

6 总结
【优点】
- 模板复用了代码,节省资源,方便更快的迭代开发,C++的标准模板库(STL)因此而产生。
- 增强了代码的灵活性。
【缺陷】
- 模板会导致代码膨胀问题,也会导致编译时间变长。
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python读取并解析邮件
- Day51| Leetcode 309. 买卖股票的最佳时机含冷冻期 Leetcode 714. 买卖股票的最佳时机含手续费
- UM2004 一款低功耗、高性能、即插即用型 OOK 射频接收器芯片
- iOS UITextField复制、粘贴框显示为英文如何解决
- Qt学习的杂七杂八小技能
- 【uniapp】新课uniapp零基础入门到项目打包(微信小程序/H5/vue/安卓apk)全掌握
- 蓝桥杯单片机组备赛——数码管静态显示
- 为什么德国如此重视可持续性有机葡萄酒种植?
- 解决protobuf编译过程中【对‘google::protobuf:: ....... [abi:cxx11]() const’未定义的引用】的问题思路
- 互联网的程序员们下班也在学习吗?