Redis相关命令详解及其原理
Redis概念
Redis,英文全称是remote dictionary service,也就是远程字典服务。这是kv存储数据库。Redis,包括所有的数据库,都是请求-回应模式,通俗来说就是数据库不会主动地要给前台推送数据,只有前台发送了申请才能数据才能响应从而相应并且发送出数据。
为什么会有redis?在分布式场景中,不同的节点可能之间经常会共享某些数据,因此我们可以把这些共享数据存放在redis当中,哪些节点需要就可以去redis当中提取数据。
Redis的特点
- kv-存储。所有的数据都是以键值对的方式存在的,当然这个“值”也有可能是键值对。
- 内存数据库。redis所有的数据都存储在内存中,可以快速地响应请求。关系型数据库的数据一般大部分都是放在磁盘中,其中一部分放在内存中可以提升取数据的速度。Redis不是关系型数据库。
- 数据结构数据库。体现在redis的kv存储,v支持丰富的数据类型,最常用的有五种数据结构:stirng字节串(能存储二进制数据和字符串),list链表,hash,zset有序集合(能有序尽量有序),set无序集合,以及stream消息队列(很少使用,用的话一般用kafka),hyperloglog(很少使用)。
不同的数据结构会对应不同的命令。Value的类型由第一次涉及到它的命令的类型决定。
图解redis
Redis的kv关系直观图
如图,value为list的时候是双向循环链表,value为hash 的时候是个kv形式的hash表。value为zset的时候,给每个m元素都搭配一个c(score),通过对score的排序实现有序。
所有的key都是string(字节串),因为支持存储二进制数据。

Redis的安装与启动教程
安装
进入redis官网下载redis
本文中选择下载6.2版本的redis
下载好了之后解压缩成一个文件夹。
cd redis-6.2
su
make
make test
make install
安装好了之后,/usr/local/bin下会看到redis-server和redis-cli,分别对应了redis的服务器和客户端。
启动
创建一个新文件夹:mkdir redis-data
将redis-6.2文件夹下的redis.conf文件移动到redis-data下,
修改redis.conf文件,吧requirepass和daemonize属性,修改如下的白字部分:


修改好了之后,redis服务器启动命令如下:

查询redis服务器是否启动成功:

用redis-cli连接到redis-server:

之后的redis命令都在redis-cli上操作。
redis-cli案例
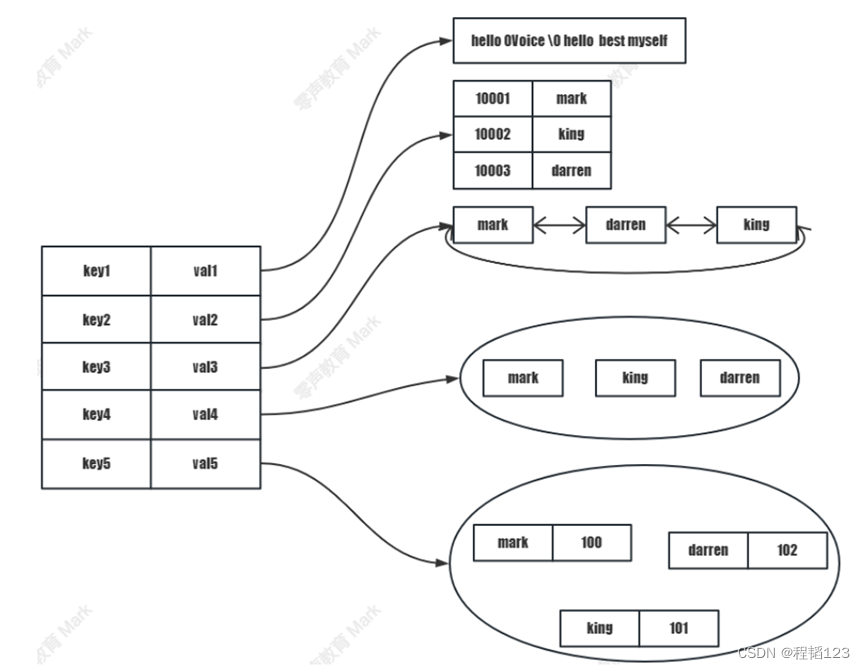
设置并获取string的kv存储

设置并获取list的kv存储
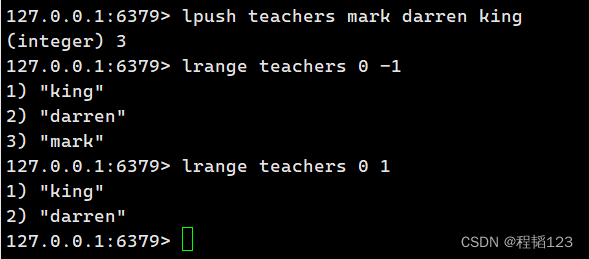
设置并获取hash的kv存储。

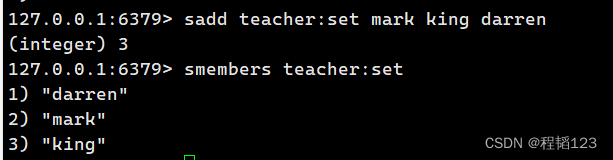
设置并获取set的kv存储
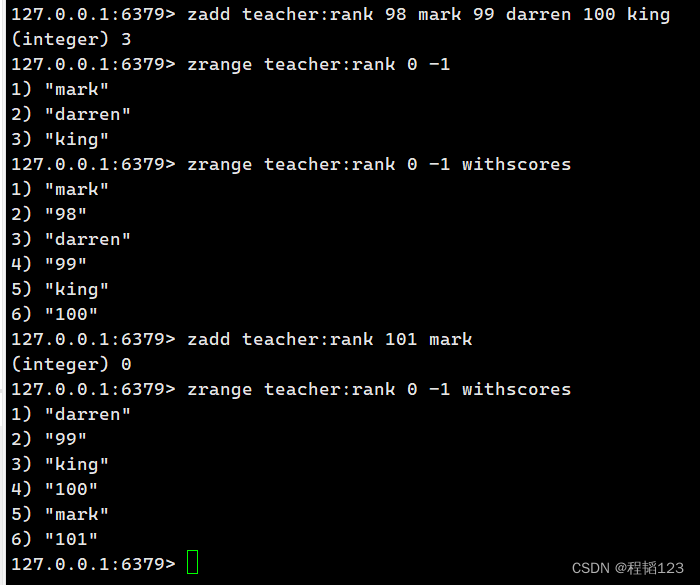
设置并获取zset的kv存储
Redis存储结构
Redis的底层数据结构是散列表。什么是散列表?简单来说散列表是一系列的链表,redis的这些链表的一个节点一对kv键值对,同时这些链表的头节点指针分别放在了同一个数组的不同位置,被串起来了。
当有一个新的键值对产生需要存储进入redis的时候,redis先先对这个key做一个hash和取余,看看要把这个键值对放在散列表的第几个链表中,然后顺着数组找到这个链表的头节点,把它插入到这个链表中。
下图中是一个redis存储结构的概念图,部分value用了一些冷门数据结构,不必太在意。跳表是用来实现zset存储的,整型数组是用来实现set存储的,动态字符串是用来实现string存储的,当然,只能说大多数情况下是如此,并不绝对。

以下是redis的不同数据结构类型的value在不同的情况下会用到的存储结构,一般是面试的时候会问,日常开发不必太深究。第一层是数据结构(数据对象类型),第二层是数据结构可能会调用的存储结构(底层存储类型)。
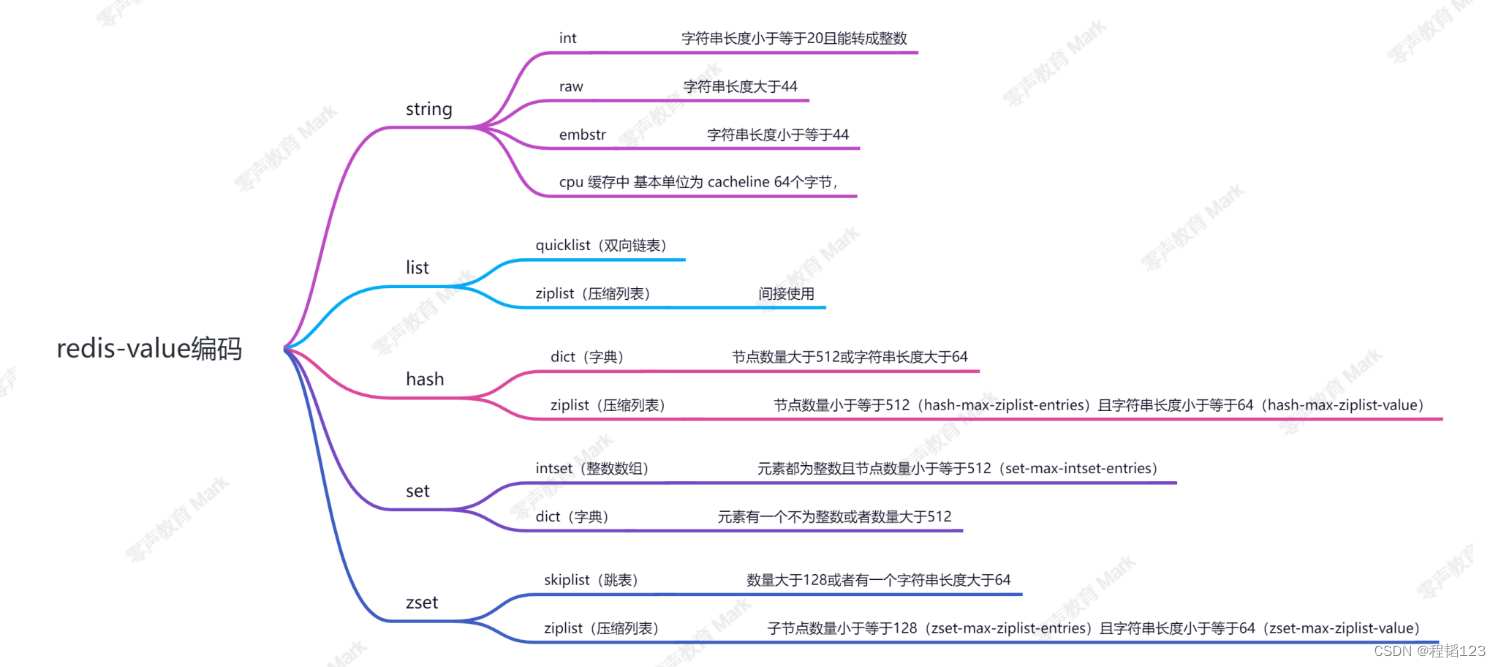
Redis各种数据的特点:
string 是一个安全的二进制字符串;
双端队列 (链表)list:有序(插入有序);
散列表 hash:对顺序不关注,field 是唯一的;
无序集合 set:对顺序不关注,里面的值都是唯一的;
有序集合 zset:对顺序是关注的,里面的值是唯一的;根据
member 来确定唯一;根据 score 来确定有序。
redis常用的数据类型
redis常用命令一般在官方文档里查询。
string
string存储结构介绍
当value为string类型的时候,字符串长度小于等于 20 且能转成整数,则使用 int 存储;
字符串长度小于等于 44,则使用 embstr 存储;
字符串长度大于 44,则使用 raw 存储。
为什么会有embstr和raw存储的区别?主要是为了字节对齐。
redis的string数据类型小于44字节的时候在底层的存储结构如下:
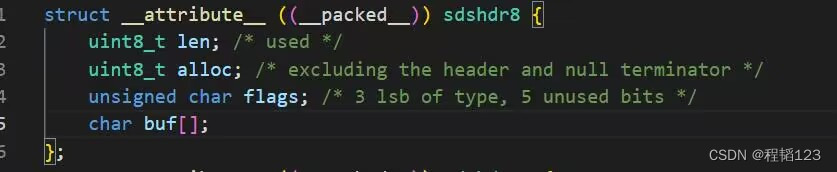
在没有存储string之前,这个结构体实例包括了前三个属性的大小(16字节),头部信息(3个字节),buf数组\0结尾(1个字节),总共20个字节。
cache line缓存存储的最小单位,用户数据部分大小为64个字节,减去20个字节后还剩44个字节给可以用于string存储。当string小于44个字节,会连同整个结构体一同存储在cache line中,也就是embstr存储。当string大于44个字节,redis会申请一块内存给string,也就是raw存储。
string 与key
redis的key一般也是string类型的。但是key的取名有个点需要注意,比如:如果有多个teacher,可能取名就是就是,不同的teacher对应的key可能就是teacher:10001,teacher:10002。为什么要用冒号分隔,一般是因为redis-cli的可视化工具可以根据冒号更好地进行可视化展开。
string的应用举例
#累加器
# 统计阅读数 累计加1
incr reads
# 累计加100
incrby reads 100
#分布式锁
# 加锁 ? 加锁 和 解析 redis 实现是 非公平锁 ? ? ectd
zk 用来实现公平锁
# 阻塞等待 ? 阻塞连接的方式
# 介绍简单的原理: 事务
setnx lock 1 ? # 不存在才能设置 定义加锁行为 占用锁 ?
setnx lock uuid ?# expire 30 过期
set lock uuid nx ex 30
# 释放锁
del lock
if (get(lock) == uuid)
del(lock);
#位运算
# 猜测一下 string 是用的 int 类型 还是 string 类型
# 月签到功能 10001 用户id 202106 2021年6月份的签到 6月
份的第1天
setbit sign:10001:202106 1 1
# 计算 2021年6月份 的签到情况
bitcount sign:10001:202106
# 获取 2021年6月份 第二天的签到情况 1 已签到 0 没有签到
getbit sign:10001:202106 2
list
list存储结构介绍
双向链表实现,列表首尾操作(删除和增加)时间复杂度O(1);查找中间元素时间复杂度为O(n);
列表中数据是否压缩的依据:1. 元素长度小于 48,不压缩;2. 元素压缩前后长度差不超过 8,不压缩。
list的应用举例
注意,如果要实现阻塞队列,需要至少需要两个进程起redis-cli,一个负责取数据阻塞,一个负责push数据。
#栈
LPUSH + LPOP
# 或者
RPUSH + RPOP
#队列
LPUSH + RPOP
# 或者
RPUSH + LPOP
#阻塞队列
LPUSH + BRPOP
# 或者
RPUSH + BLPOP
#操作与队列一样,但是在不同系统间;生成者和消费者;hash
hash存储结构介绍
散列表,在很多高级语言当中包含这种数据结构;
c++unordered_map 通过 key 快速索引 value;
hash常用命令
# 获取 key 对应 hash 中的 field 对应的值
HGET key field
# 设置 key 对应 hash 中的 field 对应的值
HSET key field value
# 设置多个hash键值对
HMSET key field1 value1 field2 value2 ... fieldn
valuen
# 获取多个field的值
HMGET key field1 field2 ... fieldn
# 给 key 对应 hash 中的 field 对应的值加一个整数值
HINCRBY key field increment
# 获取 key 对应的 hash 有多少个键值对
HLEN key
# 删除 key 对应的 hash 的键值对,该键为field
HDEL key field
set
set存储结构介绍
集合;用来存储唯一性字段,不要求有序;存储不需要有序,操作(交并差集的时候排序)
set常用命令
# 添加一个或多个指定的member元素到集合的 key中
SADD key member [member ...]
# 计算集合元素个数
SCARD key
# SMEMBERS key
SMEMBERS key
# 返回成员 member 是否是存储的集合 key的成员
SISMEMBER key member
# 随机返回key集合中的一个或者多个元素,不删除这些元素
SRANDMEMBER key [count]
# 从存储在key的集合中移除并返回一个或多个随机元素
SPOP key [count]
# 返回一个集合与给定集合的差集的元素
SDIFF key [key ...]
# 返回指定所有的集合的成员的交集
SINTER key [key ...]
# 返回给定的多个集合的并集中的所有成员
SUNION key [key ...]
#并集
sadd follow:A mark king darren mole vico
sadd follow:C mark king darren
# C可能认识的人:
sdiff follow:A follow:C
#交集
sadd follow:A mark king darren mole vico
sadd follow:C mark king darren
sinter follow:A follow:C
zset
hset存储结构介绍
有序集合实现;用来实现排行榜;它是一个有序唯一;
zst常用命令
# 添加到键为key有序集合(sorted set)里面
ZADD key [NX|XX] [CH] [INCR] score member [score
member ...]
# 从键为key有序集合中删除 member 的键值对
ZREM key member [member ...]
# 返回有序集key中,成员member的score值
ZSCORE key member
# 为有序集key的成员member的score值加上增量increment
ZINCRBY key increment member
# 返回key的有序集元素个数
ZCARD key
# 返回有序集key中成员member的排名
ZRANK key member
# 返回存储在有序集合key中的指定范围的元素 ? order by id
limit 1,100
ZRANGE key start stop [WITHSCORES]
# 返回有序集key中,指定区间内的成员(逆序)
ZREVRANGE key start stop [WITHSCORES]
zset应用举例
延时队列:将消息序列化成一个字符串作为 zset 的 member;这个消息的到期处理时间作为 score,然后用多个线程轮询 zset 获取到期的任务进行处理。
def delay(msg):
? ?msg.id = str(uuid.uuid4()) #保证 member 唯一
? ?value = json.dumps(msg)
? ?retry_ts = time.time() + 5 # 5s后重试
? ?redis.zadd("delay-queue", retry_ts, value)
# 使用连接池
def loop():
? ?while True:
? ? ? ?values = redis.zrangebyscore("delayqueue", 0, time.time(), start=0, num=1)
? ? ? ?if not values:
? ? ? ? ? ?time.sleep(1)
? ? ? ? ? ?continue
? ? ? ?value = values[0]
? ? ? ?success = redis.zrem("delay-queue",
value)
? ? ? ?if success:
? ? ? ? ? ?msg = json.loads(value)
? ? ? ? ? ?handle_msg(msg)
loop 是多线程竞争,两个线程都从zrangebyscore获取到数据,但是zrem一个成功一个失败。
时间窗口限流:系统限定用户的某个行为在指定的时间范围内(动态)只能发
生 N 次;
# 指定用户 user_id 的某个行为 action 在特定时间内
period 只允许发生该行为做大次数 max_count
local function is_action_allowed(red, userid,
action, period, max_count)
? ?local key = tab_concat({"hist", userid,
action}, ":")
? ?local now = zv.time()
? ?red:init_pipeline()
? ?-- 记录行为
? ?red:zadd(key, now, now)
-- 移除时间窗口之前的行为记录,剩下的都是时间窗口内的记录
? ?red:zremrangebyscore(key, 0, now - period*100)
? ?-- 获取时间窗口内的行为数量
? ?red:zcard(key)
? ?-- 设置过期时间,避免冷用户持续占用内存 时间窗口的长度+1秒
? ?red:expire(key, period + 1)
#commit_pipeline用于执行 Redis 流水线中的所有命令。
#返回的列表中的每个元素对应一个命令的执行结果
? ?local res = red:commit_pipeline()
#res[3] 表示时间窗口内的行为数量(即 red:zcard(key) 命令的返回值)
? ?return res[3] <= max_count
end
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JavaScript(ES6进阶部分)
- RT-Thread入门笔记5-线程的时间片轮询调度
- 使用FreeBASIC设计8051单片机汇编编译器
- 克魔助手工具详解、数据包抓取分析、使用教程
- 如果能用盗版省下钱好好对待员工也行
- 冬天夺去的清爽,可爱,春天都会还给你
- 数字化与鲜食热食,便利店2023两大关键词
- 解析为什么Go语言要使用[]rune而不是string来表示中文字符
- Springboot整合MQ学习记录
- 性能小课堂:Jmeter录制手机app脚本