Hadoop——HDFS、MapReduce、Yarn期末复习版(搭配尚硅谷视频速通)
一、HDFS
1.HDFS概述
1.1 HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
1.2 HDFS优缺点
(1)优点
- 高容错性
数据自动保存多个副本。它通过增加副本的形式,提高容错性。
某一个副本丢失以后,它可以自动恢复。
- 适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
- 可构建在廉价机器上,通过多副本机制,提高可靠性。
(2)缺点
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
- 无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDF$的设计目标。
- 不支持并发写入、文件随机修改。
- 一个文件只能有一个写,不允许多个线程同时写;
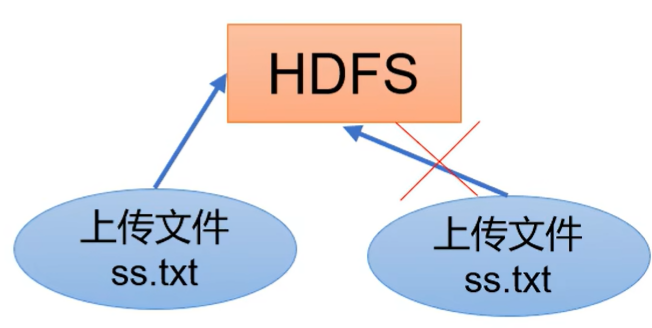
- 仅支持数据append(追加),不支持文件的随机修改。
1.3 HDFS组成架构(了解)

- NameNode:就是Master,它是一个主管、管理者。
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块(Block)映射信息;
- 处理客户端读写请求。
- DataNode:就是Slave。NameNode:下达命令,DataNode执行实际的操作。
- 存储实际的数据块;
- 执行数据块的读/写操作。
- Client:就是客户端。
- 文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block(块),然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入据:
- Client提供一些命令来管理HDFS,比如NameNode格式化;
- Client可以通过一些命令来访问DFS,比如对寸HDFS增删查改操作;
- SecondaryNameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不
能马上替换NameNode并提供服务。- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode.
1.4 HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。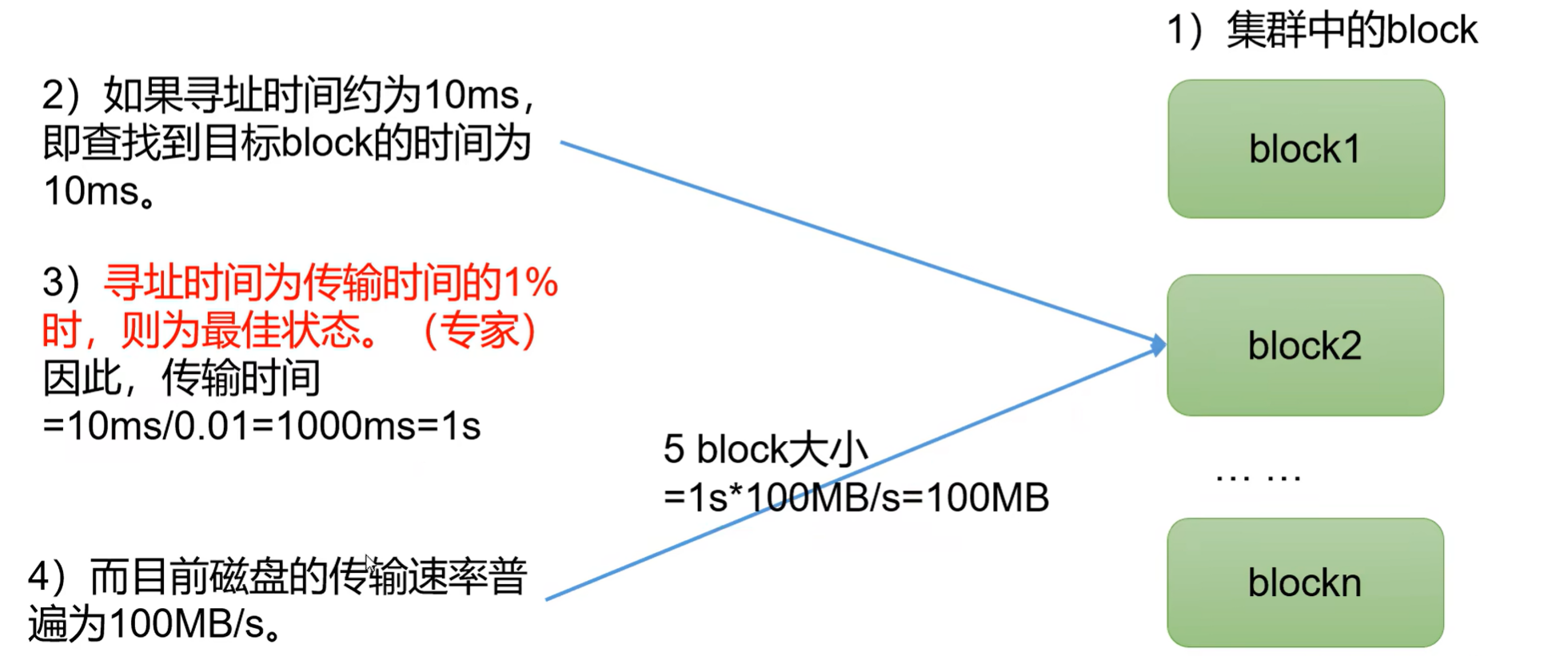
思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置,
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决丰磁盘传输速率
2.HDFS的Shell操作
2.1 基本语法
hadoop fs 具体命令 OR hdfs dfs 具体命令
两个完全一样
2.2 常用命令
①上传
- -moveFromLocal
从本地剪切到HDFS
hdfs dfs -moveFromLocal ./shuguo.txt /sanguo
- -copyFromLocal
从本地文件系统中拷贝到HDFS路径去
hdfs dfs -copyFromLocal weiguo.txt /sanguo
- -put
等同于copyFromLocal,生产环境更习惯用put
hdfs dfs -put wuguo.txt /sanguo
- -appendToFile
追加一个文件到已经存在的文件末尾
hdfs dfs -appendToFile liubei.txt /sanguo/shuguo.txt
②下载
- -copyToLocal
从HDFS拷贝到本地
hdfs dfs -copyToLocal /sanguo/shuguo.txt ./
- -get
等同于copyToLocal,生产环境更习惯用get
hdfs dfs -get /sanguo/shuguo.txt ./shuguo2.txt
③HDFS直接操作
- -ls :显示目录信息
- -cat :显示文件内容
- -chgrp、-chmod、-chown :Linux文件系统中的用法一样,修改文件所属权限
- -mkdir :创建路径
- -cp :从HDFS的一个路径拷贝到HDFS的另一个路径
- -mv :在HDFS目录中移动文件
- -tail:显示一个文件的末尾1kb的数据
- -rm:删除文件或文件夹
- -rm -r :递归删除目录及目录里面内容
- -du:统计文件夹的大小信息
- -setrep :设置HDFS中文件的副本数量
hdfs dfs -settrep 10 /jinguo/shuguo.txt
3.HDFS的API操作
public class HdfsCliient{
//全局
private FileSystem fs;
@Before
public void init() throwa URISyntaxException,IOException, InterruptedException{
// 连接的集群nn地址
URIuri new URI(str:"hdfs://hadoop102:8020");
//创建一个配置文件
Configuration configuration new Configuration();
// 用户
String user = "atguigu";
// 1 获取到了客户端对象
fs = FileSystem.get(uri,configuration,user);
}
@After
public void close() throwa IOException{
// 3 关闭资源
fs.close()
}
//创建目录
@Test
public void testmkdir()throws URISyntaxException,IOException, InterruptedException{
// 2 创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan"));
}
// 上传
/**
*参数优先级
*hdfs-default.xml => hdfs-site.xml => 子啊项目资源目录下的配置文件 => 代码里的配置优先级最高
*/
public void testPut(){
// 参数解读:参数一:表示删除数据; 参数二:是否允许覆盖; 参数三:原数据路径; 参数四:目的地路径
fs.copyFromLocalFile(delSrc:false,overwrite:false,new Path(pathString:"D://sunwukong.txt"),new Path(pathString:"hdfs://hadoop102/xiyou/huaguoshan"));
}
// 文件下载
public void testGet{
//参数解读:参数一:原文件是否删除; 参数二:原文件路径HDFS; 参数三:目标地址路径Win; 参数四:进行crc校验
fs.copyToLocalFile(delSrc:false,new Path(pathString:"hdfs://hadoop102/xiyou/huaguoshan"),new Path(pathString:"D://"),userRawLocaclFileSystem:false);
}
// 文件删除
public void testRm(){
//参数解读:参数一:要删除的路径; 参数二:是否递归删除;
//删除文件
fs.delete(new Path(pathString:".jdk-8u212-linux-x64.tar.gz"),recursive:false);
//删除空目录
fs.delete(new Path(pathString:"/xiyou"),recursive:false);
//删除非空目录
fs.delete(new Path(pathString:"/jingguo"),recursive:true);
}
//文件的更名和移动
@Test
public void testmv(){
//参数解读:参数一:原文件路径; 参数二:目标文件路径
//对文件名称的修改
fs.rename(new Path("/intput/word.txt"),new Path("/input/ss.txt"));
// 文件的移动和更名
fs.rename(new Path("/intput/ss.txt"),new Path("/cls.txt"));
//目录的更名
fs.rename(new Path(pathString:"/intput"),new Path(pathString:"/output"));
}
//获取文件详情
@Test
public viod fileDetail(){
//获取所有文件信息
RemoteIterator<LocatedFileStatus> listFiles = fs.ListFiles(new Path(pathString:"/"), recursive:true);
//遍历文件
while (listFiles.hasNext(){
LocatedFileStatus fileStatus listFiles.next();
System.out.println("=========="+fileStatus.getPath()+"=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication);
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
//获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
//判断是文件夹还是文件
public void testFile() throws IOException{
//循环遍历每一个文件
FileStatus[] listStatus = fs.ListStatus(new Path(pathString:"/"));
//判断他是不是一个文件
for(FileStatus status : ListStatus){
//如果是打印文件,不是打印目录
if(status.isFile()){
System.out.println("文件:"+status.getPath().getName());
} else{
System.oUt.println("目录:"+status.getPath().getName());
}
}
}
4.HDFS读写流程
4.1 HDFS写数据流程
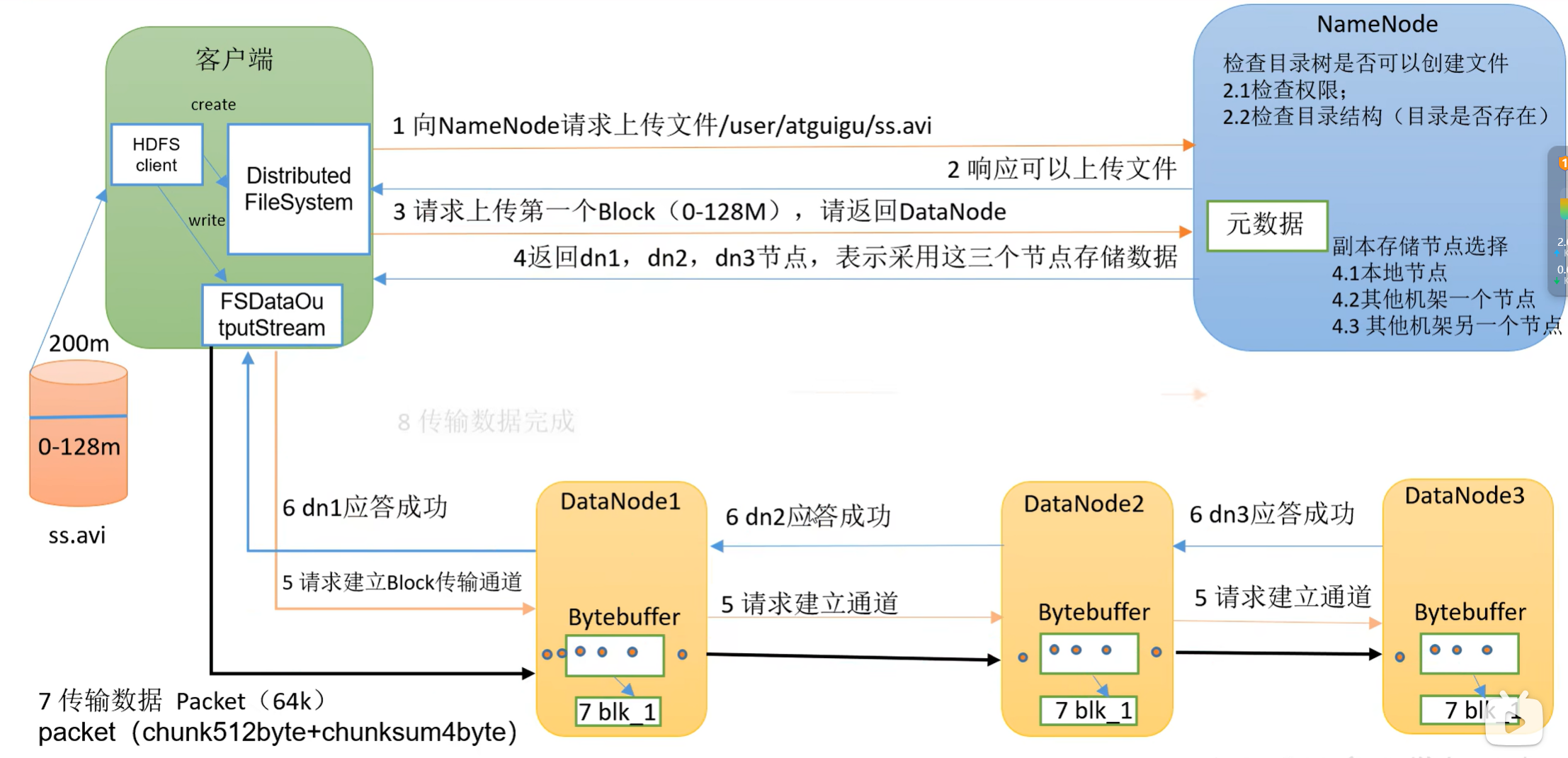
网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
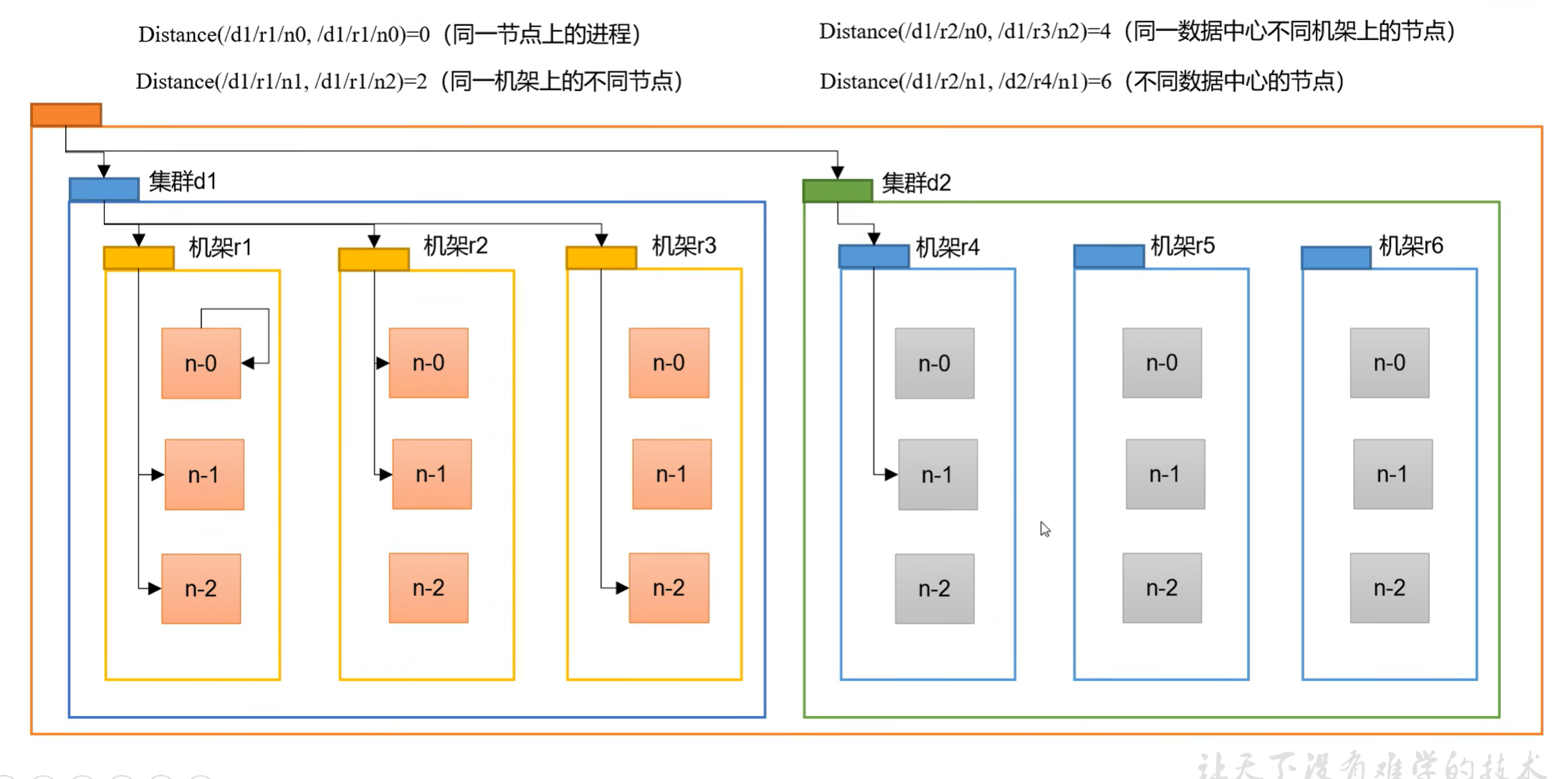
4.2 机架感知
副本节点选择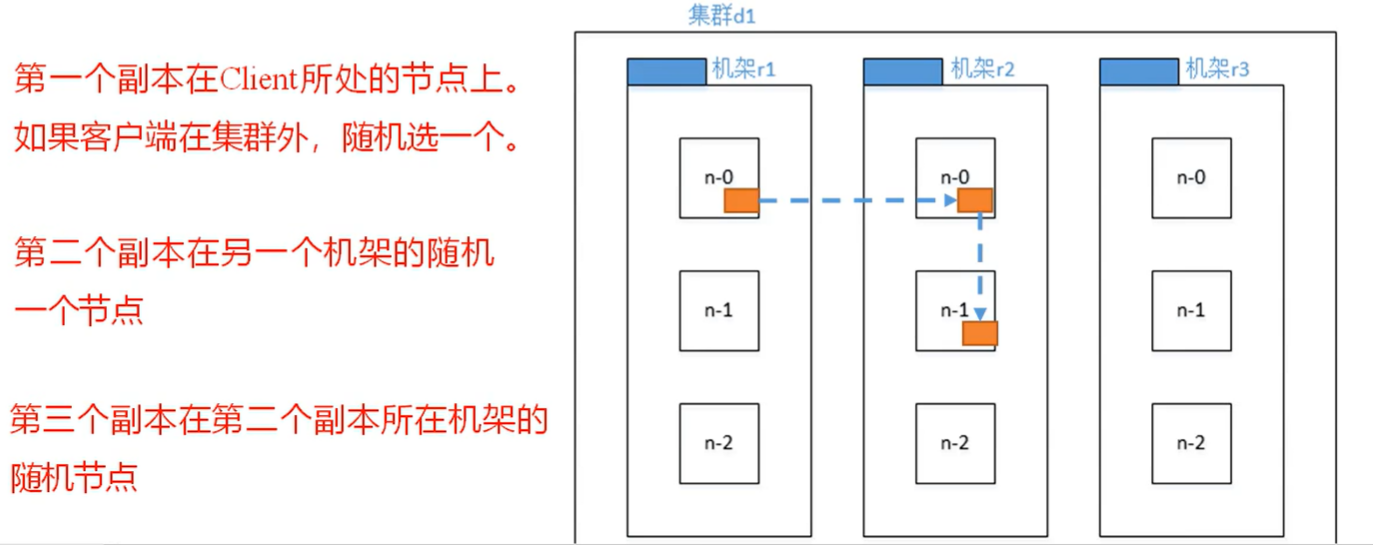
4.3 HDFS读数据流程
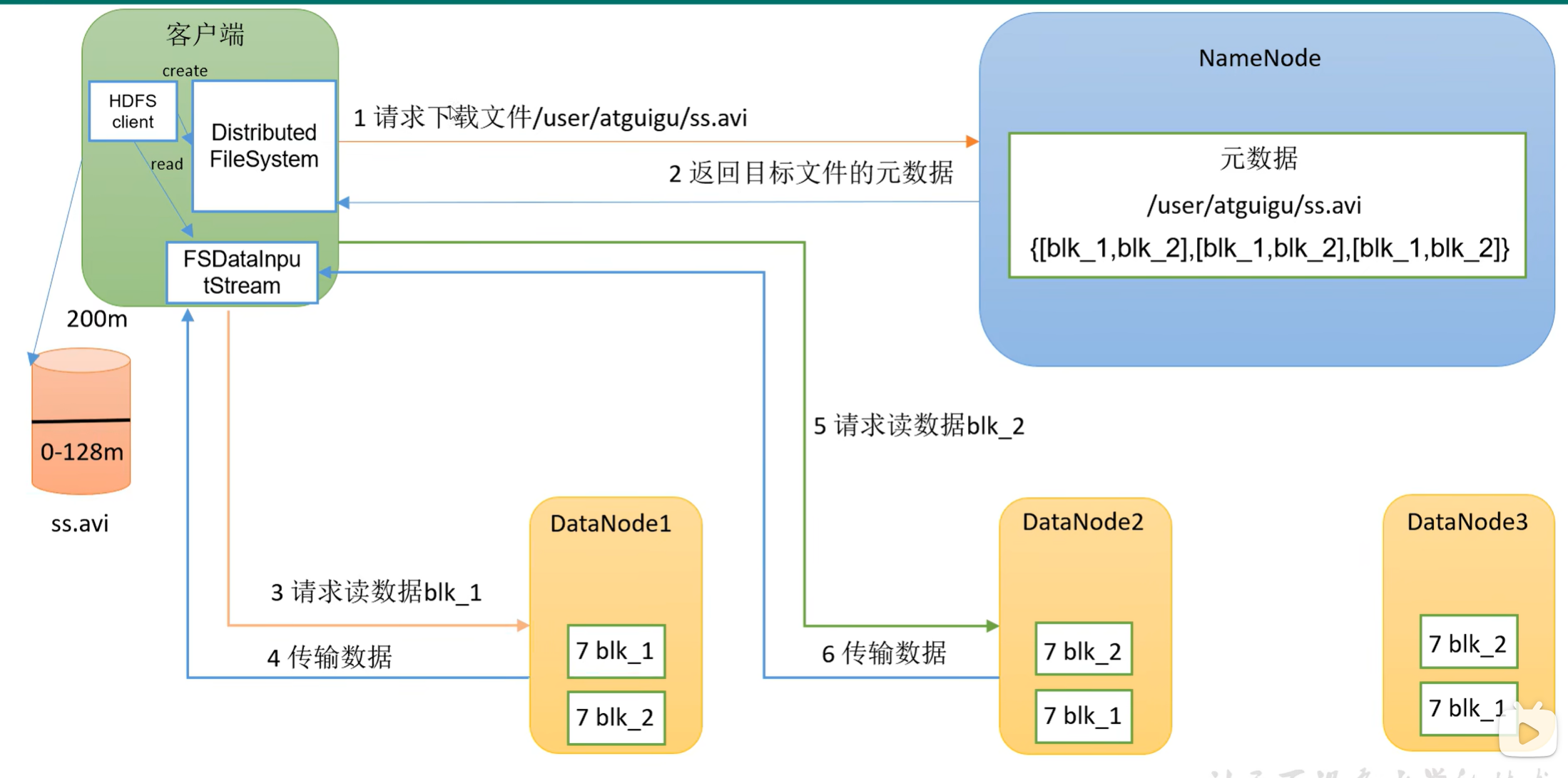
读的时候是串行,先读DataNode1的blk_1,再读DataNode2的blk_2
4.4 NN和2NN工作机制(NameNode)
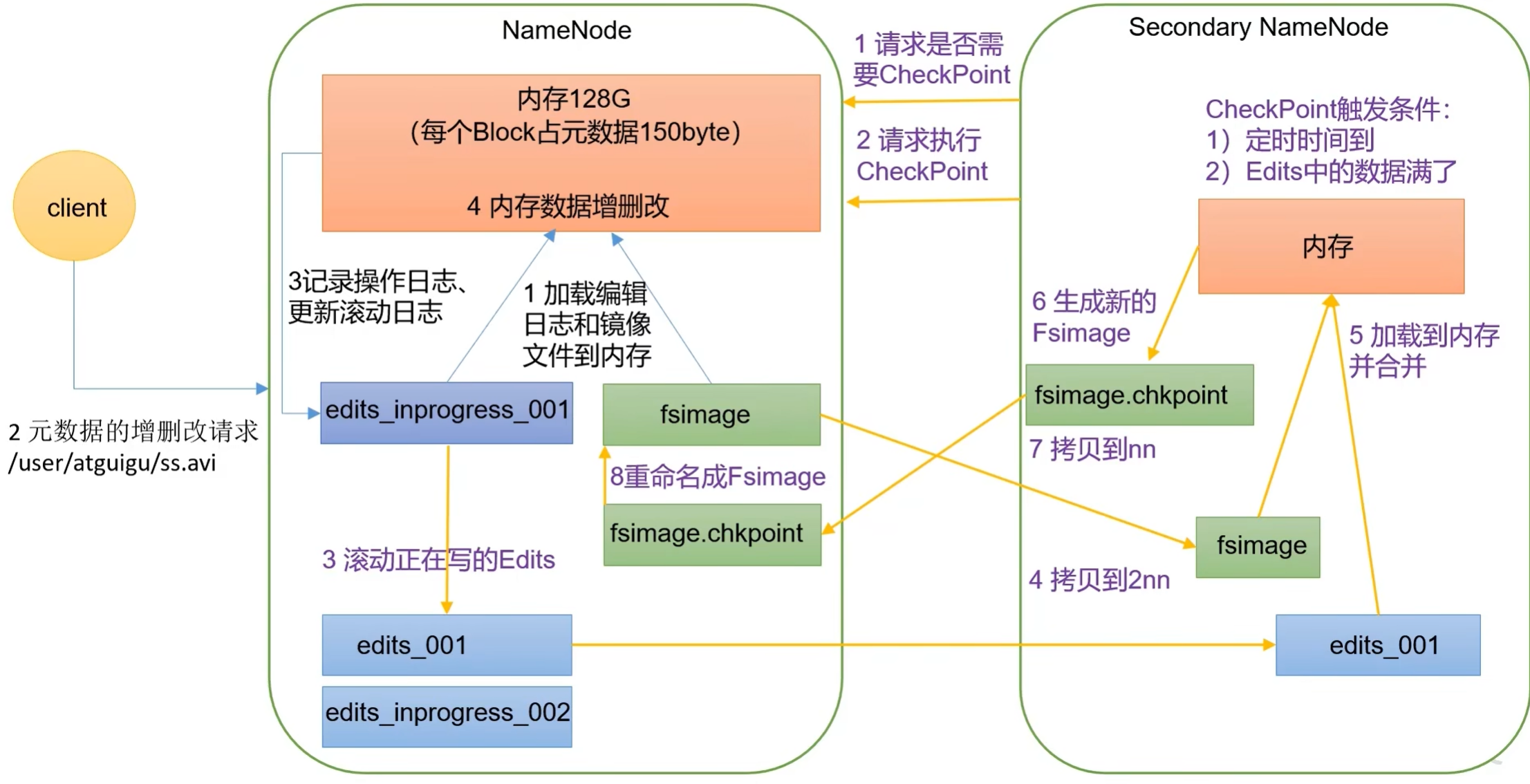
4.5 Fsimage和Edis概念
NameNode被格式化之后,将在/opt/module/hadoop-3.l.3/data/tmp/dfs/name/current目录中生如下文件
fsimage0000000000000000000
fsimage0000000000000000000.md5
seen txid
VERSION
(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inodef的序列化信息。
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
(4)每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
4.6 DataNode工作机制
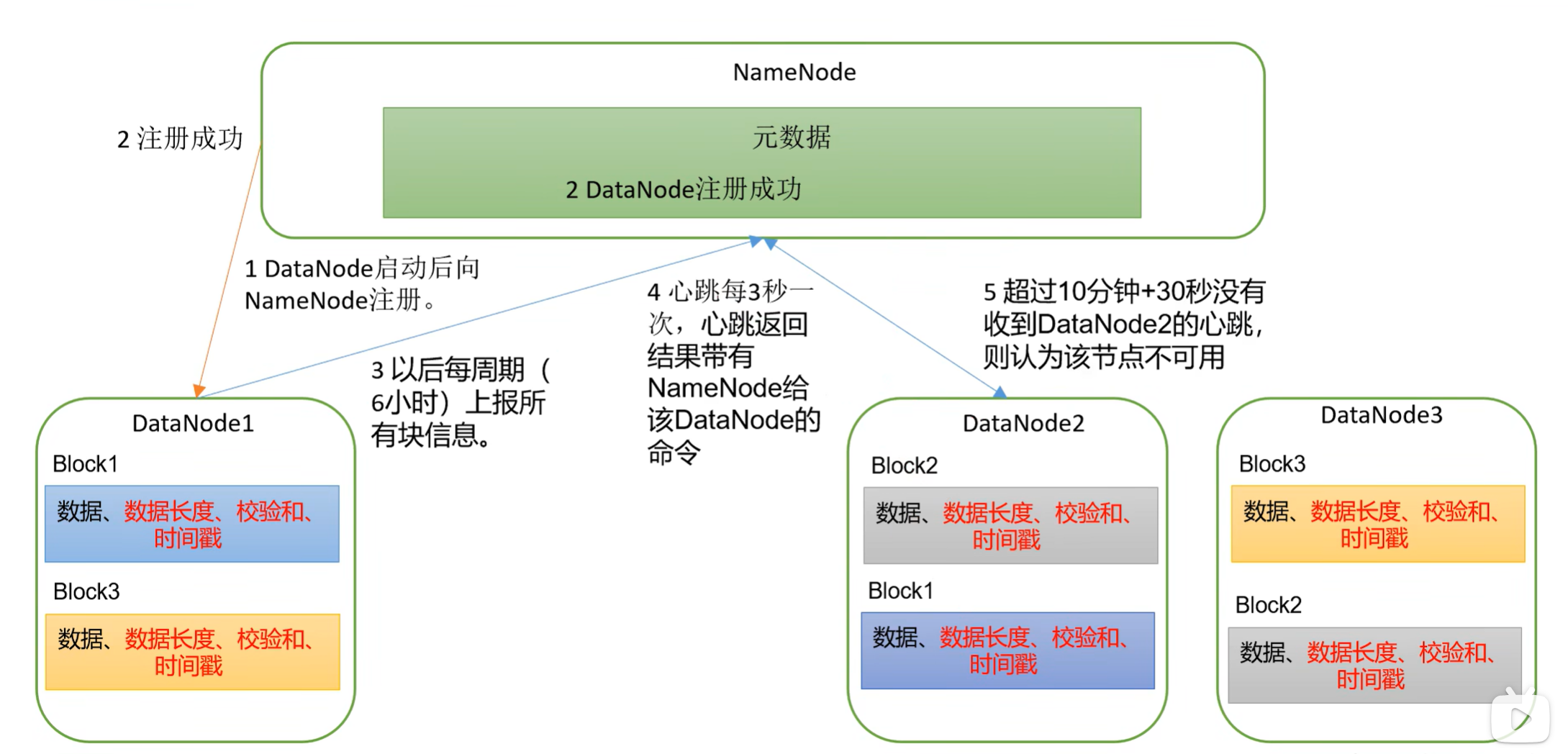
4.7 数据完整性
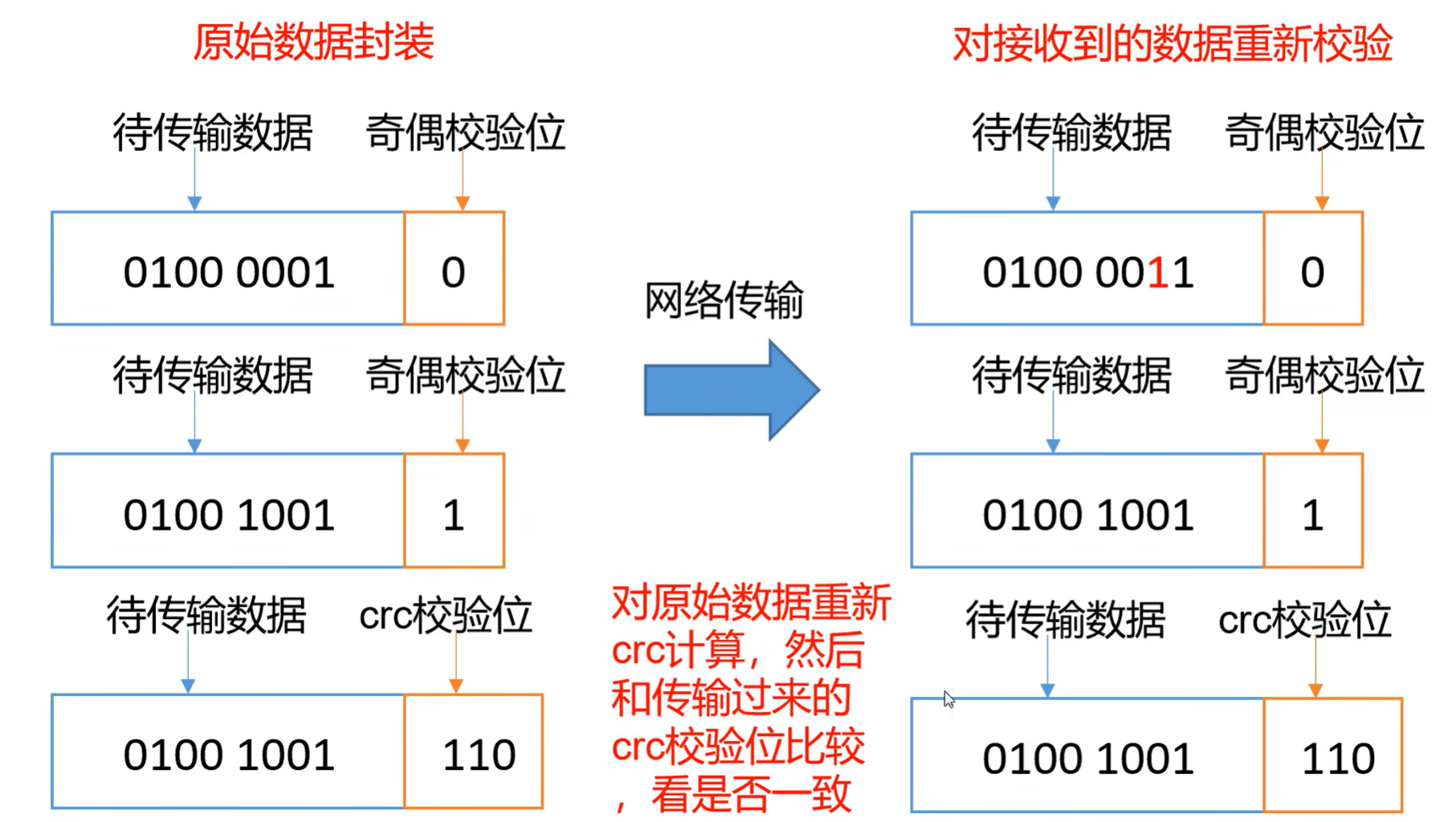
二、MapReduce
MapReduce概述
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。自己处理业务相关代码+自身的默认代码。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2 MapReduce优缺点
优点:
1、易于编程。用户只关心,业务逻辑。实现框架的接口。
2、良好扩展性:可以动态增加服务器,解决计算资源不够问题
3、高容错性。任何一台机器挂掉,可以将任务转移到其他节点。
4、适合海量数据计算(TB/PB)几千台服务器共同计算。
缺点:
1、不擅长实时计算。ysql
2、不擅长流式计算。Sparkstreaming flink
3、不擅长DAG有向无环图计算。spark
1.3 MapReduce核心编程思想
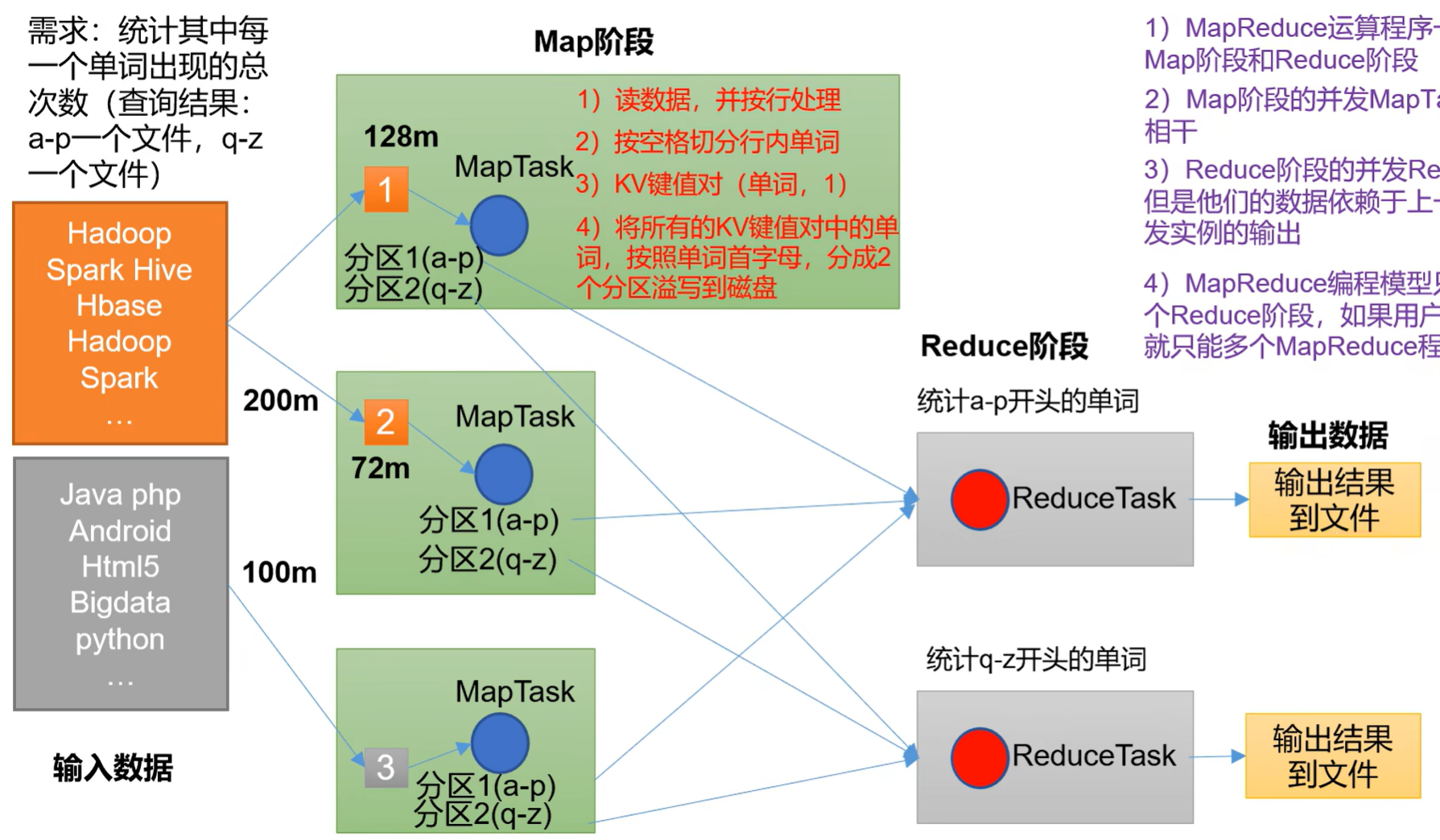
- 1)MapReduce运算程序一般需要分成2个阶段:Map阶段和Reduce阶段
- 2)Map阶段的并发MapTask,完全并行运行,互不相干
- 3)Reduce阶段的并发ReduceTask,完全互不相千,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出
- 4)MapReduce编程模型只能包含一个Map阶段和个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行
1.4 MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
1.5 MapReduce编程规范
Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map0方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map0方法(MapTaski进程)对每一个<K,V>调用一次
Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)ReduceTask进程对每一组相同k的k,v>组调用一次reduce()方法
Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
Hadoop序列化
2.1 序列化概述
什么是序列化?
序列化是指将内存中的对象转换成字节序列(或是其他数据传输协议),以便将其存储于磁盘中(持久化存储)或进行网络传输的过程
为什么不用Java序列化机制?
Java具有一套序列化机制,但是Java的学历恶化机制是一个重量级序列化框架,一个对象在被序列化后,会附带很多额外信息(各种校验信息、Header、继承体系等),不便于在网络中进行高效传输。所以,Hadoop自己开发了一套序列化机制。
Hadoop序列化机制的特点:
- 紧凑:紧凑的格式有助于高效实用存储空间,充分利用网络带宽
- 快速:序列化和反序列化的性能开销小,可以实现进程之间的快速通信
- 互操作:统一的序列化框架可以支持多语言与服务器的交互
MapReduce框架原理之InputFormat数据输入
数据切片与maptask并行度决定机制
1)一个Job的Map阶段并行度由客户端在提交Job时的切片数决定
2)每一个Split切片分配一个MapTaski并行实例处理
3)默认情况下,切片大小=BlockSize
4)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储,数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。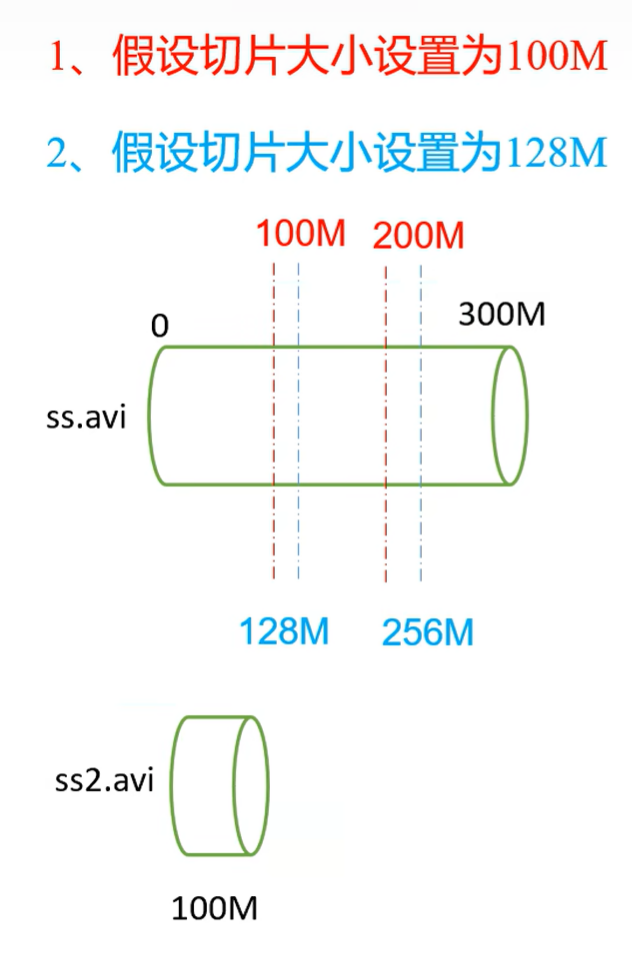
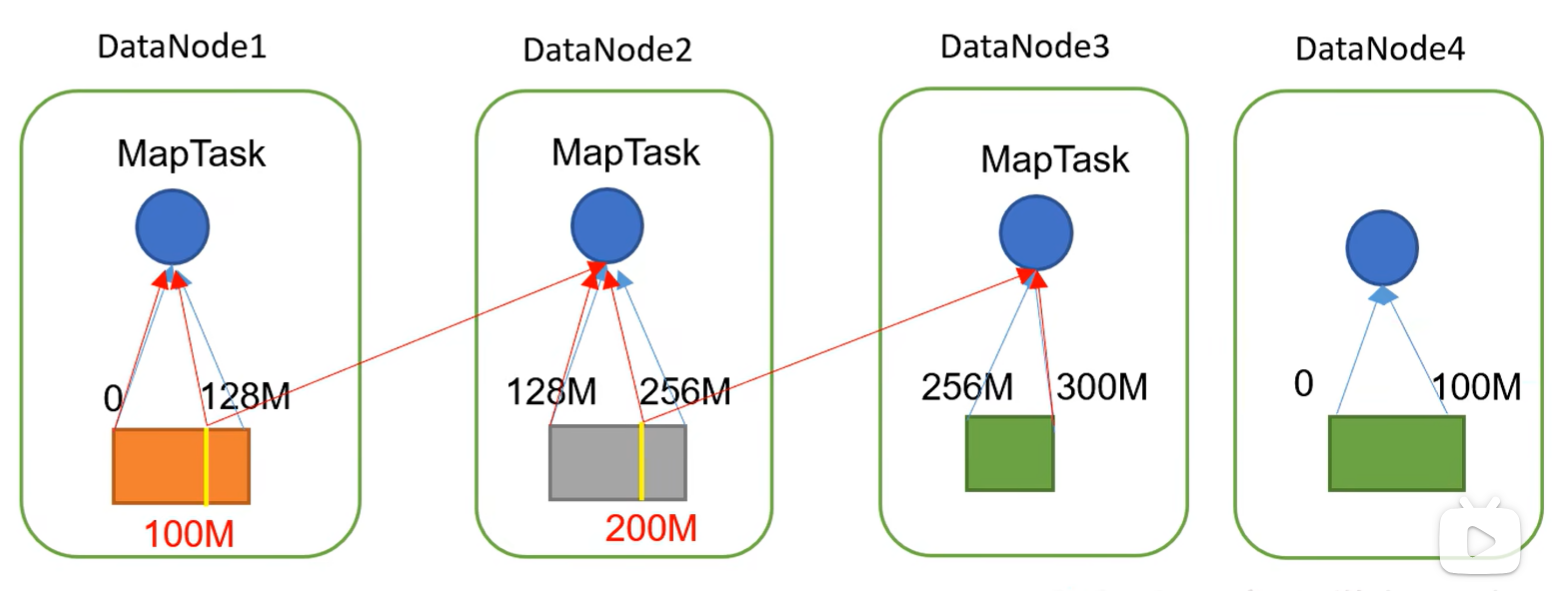
FileInputFormat切片机制
1、切片机制
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Bl1ock大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
2、案例分析
(1)输入数据有两个文件:
filel.txt 320M
file2.txt 10M
(2)经过FileInputFormat的切片机制,运算后,形成的切片信息如下:
filel.txt.splitl – 0~128
filel.txt.split2 – 128256
filel.txt.split3 – 256~320
file2.txt.splitl – 0~10M
CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1)应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置~
CombineTextInputFormat.setMaxInputSplitSize(job,4194304);//4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。
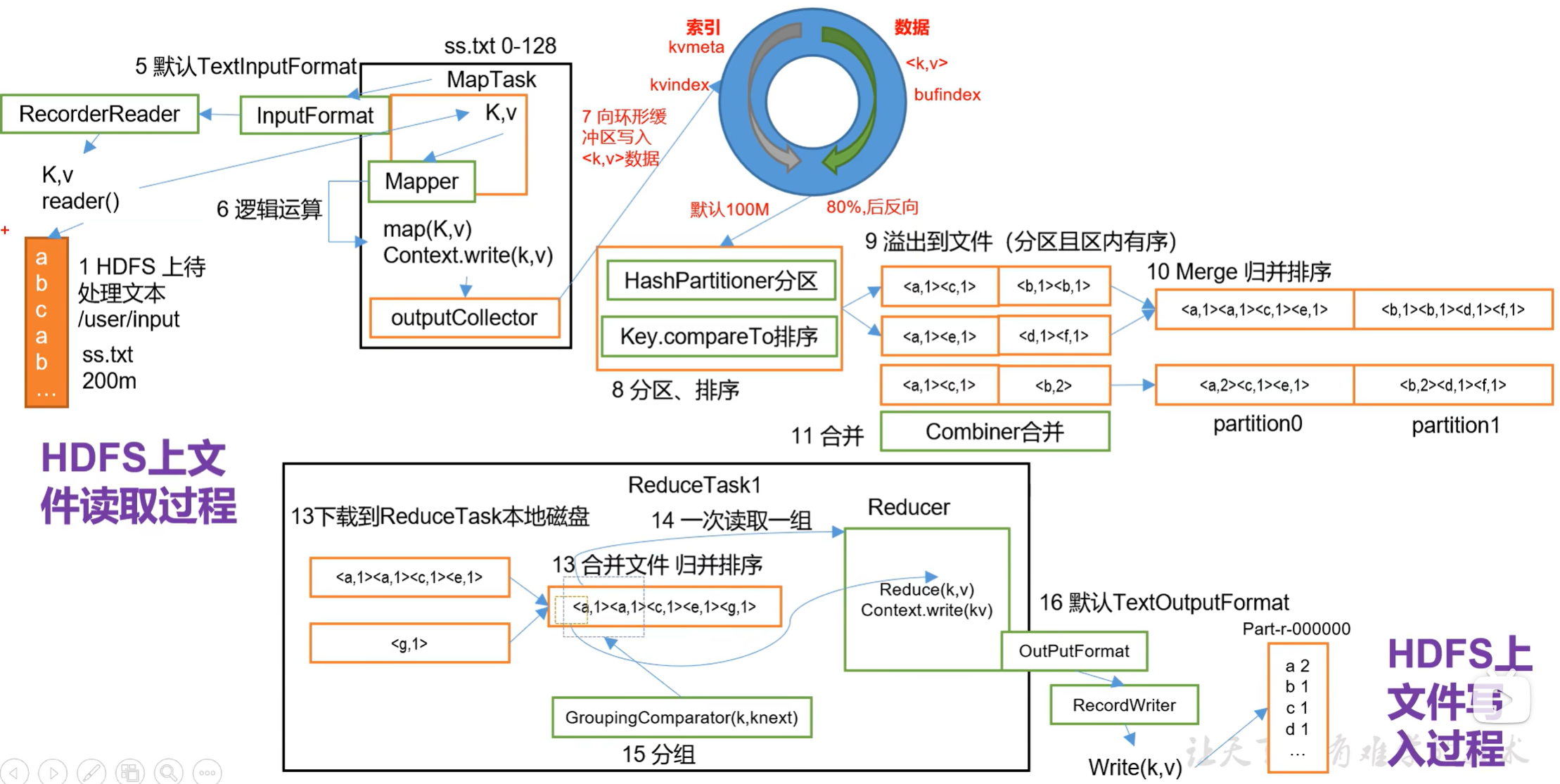
MapReduce详细工作流程
MapReduce框架原理之shuffle机制
shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。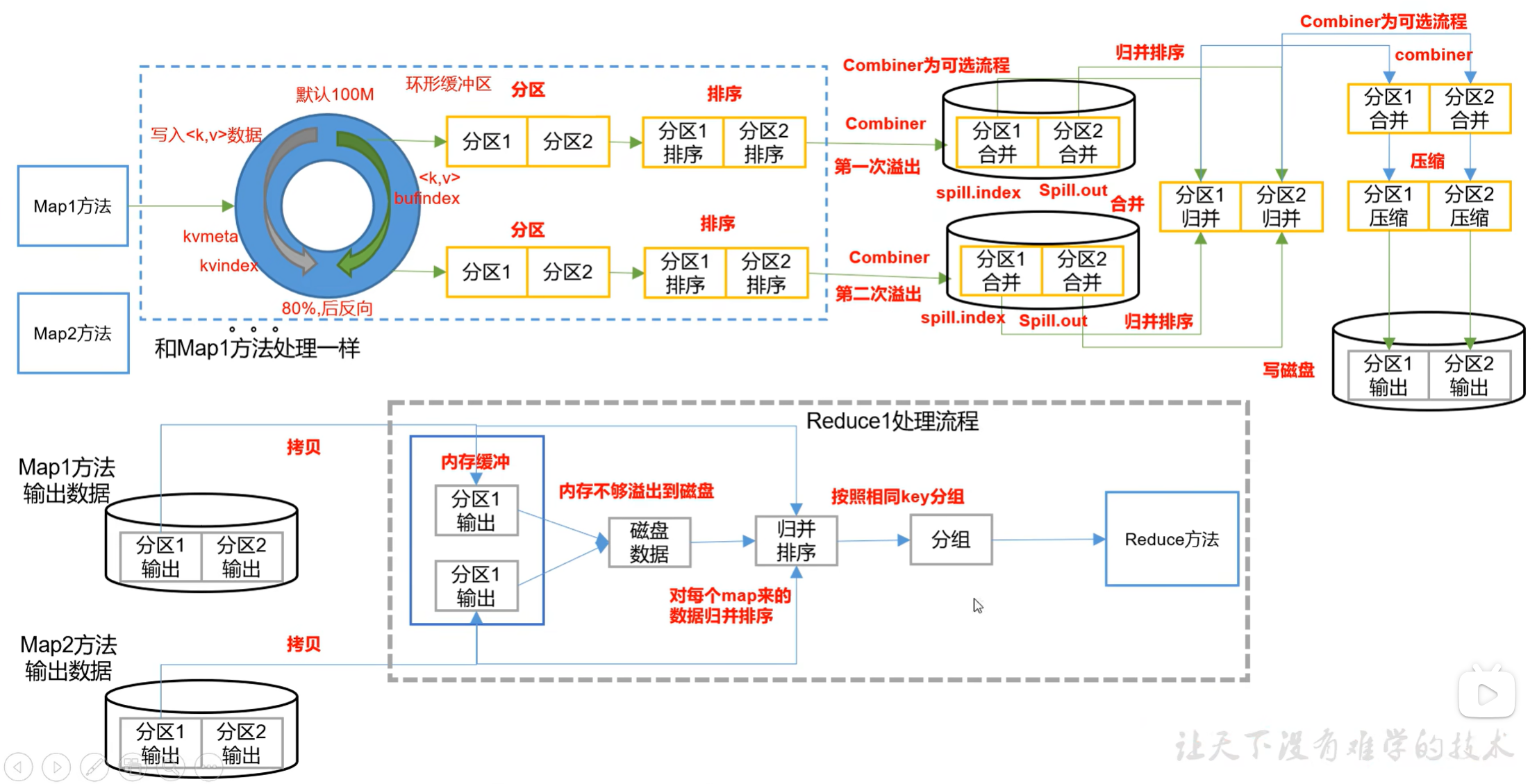
partition分区
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
默认分区HashPartitioner,默认按照key的hash值numreducetask个数
(1)如果ReduceTask的数量>getPartition的结果数,则会多产生几个空的输出文件part-r-O00xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如果ReduceTask的数量-1,则不管MapTaski端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000;
例如:假设自定义分区数为5,则
(1) job.setNumReduceTasks(1); 会正常运行,只不过会产生一个输出文件
(2) job.setNumReduceTasks(2); 会报错
(3) job.setNumReduceTasks(6); 大于5,程序会正常运行,会产生空文件
(4)分区号必须从零开始,逐一累加。例: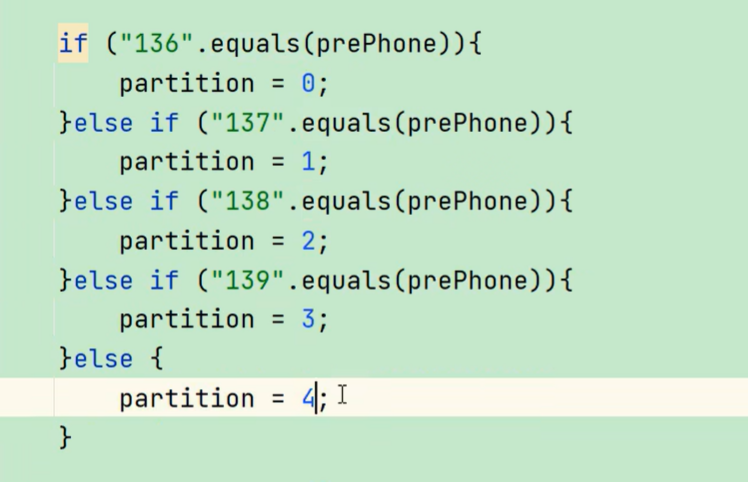
combiner合并
(I)Combiner是MR程序中Mapperz和Reducer之外的一种组件。
(2)Combiner组件的父类就是Reducer。.
(3)Combinerz和Reducer的区别在于运行的位置
Combiner是在每一个MapTask所在的节点运行;
Reducer是接收全局所有MapperE的输出结果;
(4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来。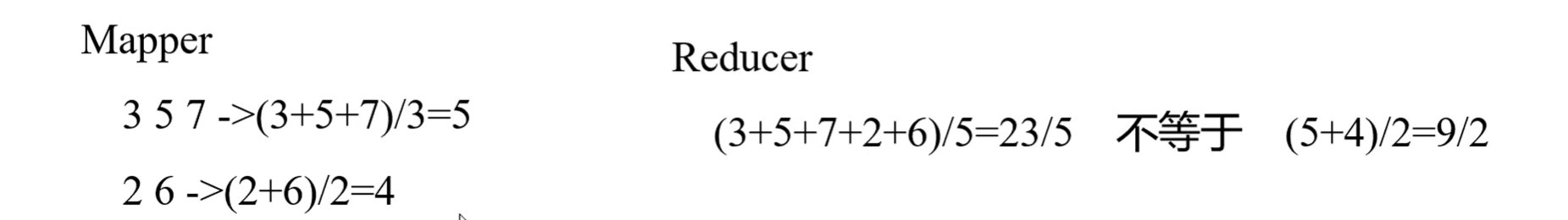
join
①reduce join
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记
录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要
在每一个分组当中将那些来源于不同文件的记录(在Mp阶段已经打标志)分开,最后进
行合并就ok了。
②map join
(1)使用场景
Map Join适用于一张表十分小、一张表很大的场景。
(2)优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数
据的压力,尽可能的减少数据倾斜。
(3)具体办法:采用DistributedCache
- 在Mapper的setup阶段,将文件读取到缓存集合中。
- 在Driver驱动类中加载缓存。
数据压缩
①压缩的好处和坏处
压缩的优点:以减少磁盘O、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
②压缩原则
(1)运算密集型的Job,少用压缩
(2)I/O密集型的Job,多用压缩
三、Yarn
1.资源调度器
3.1 Yarn基础框架
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
YARN主要由ResourceManager、.NodeManager、ApplicationMaster和Container等组件
构成。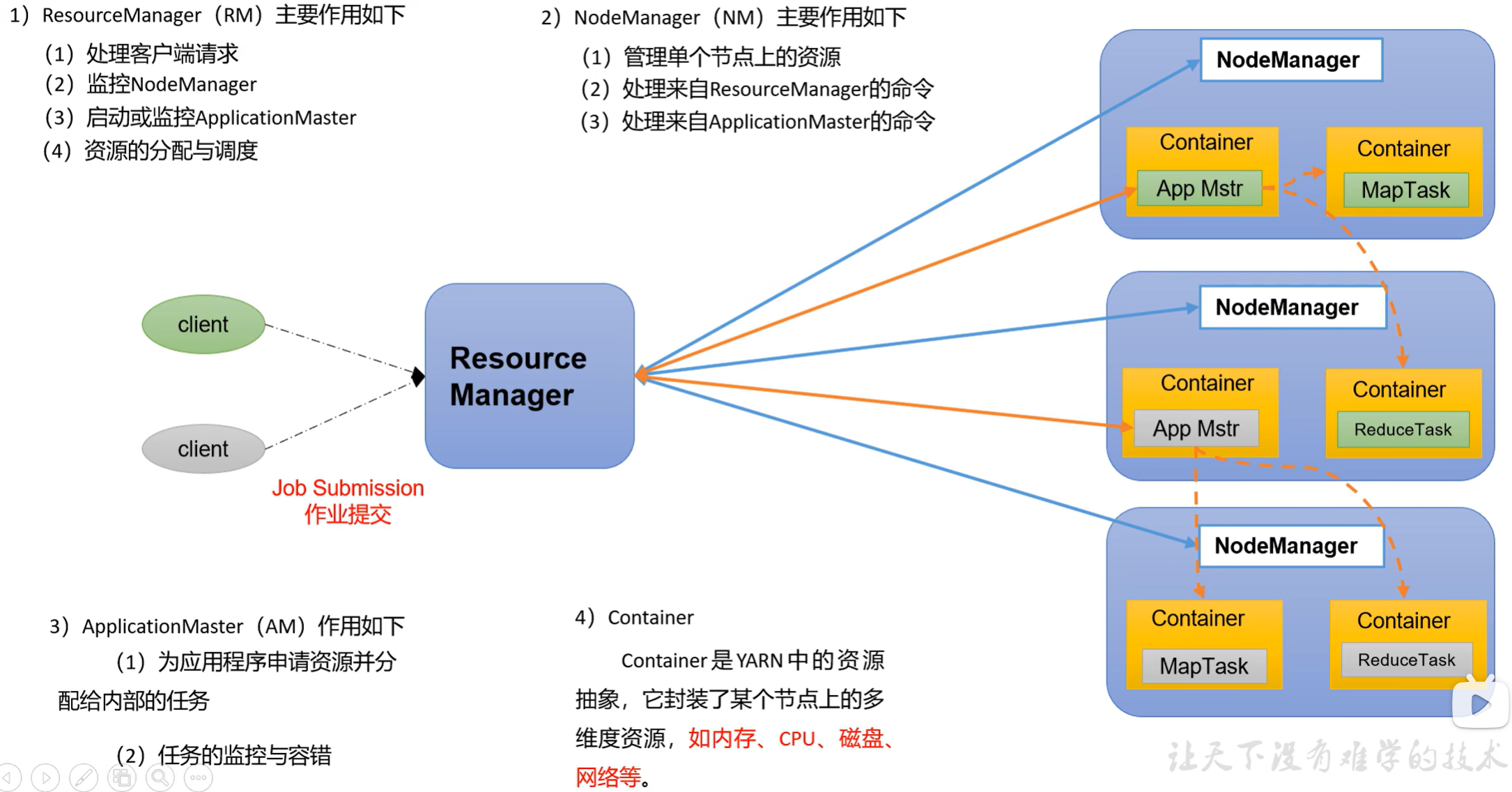
3.2 Yarn工作机制
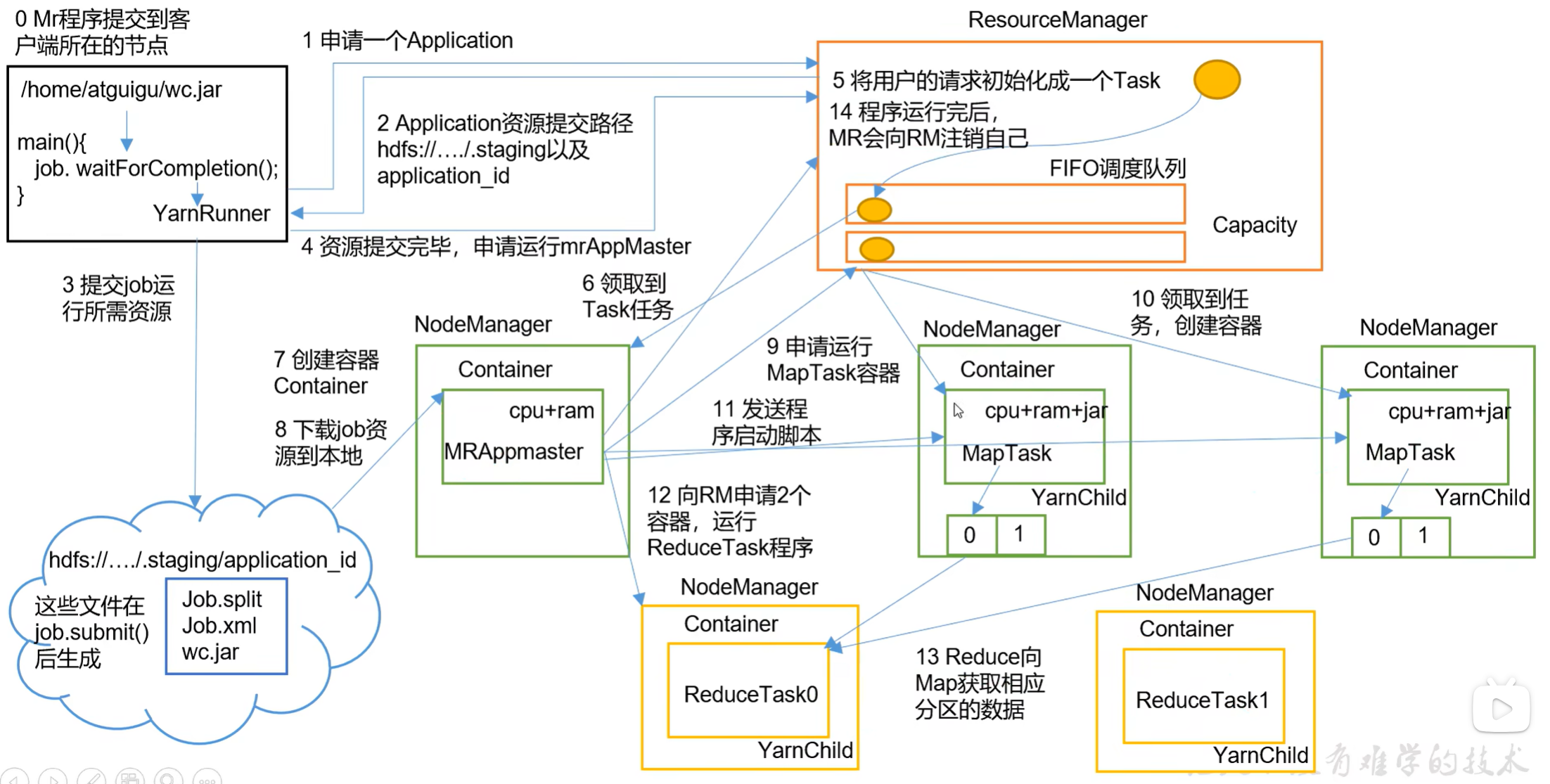
3.3作业提交过程
HDFS、YARN、MapReduce三者关系
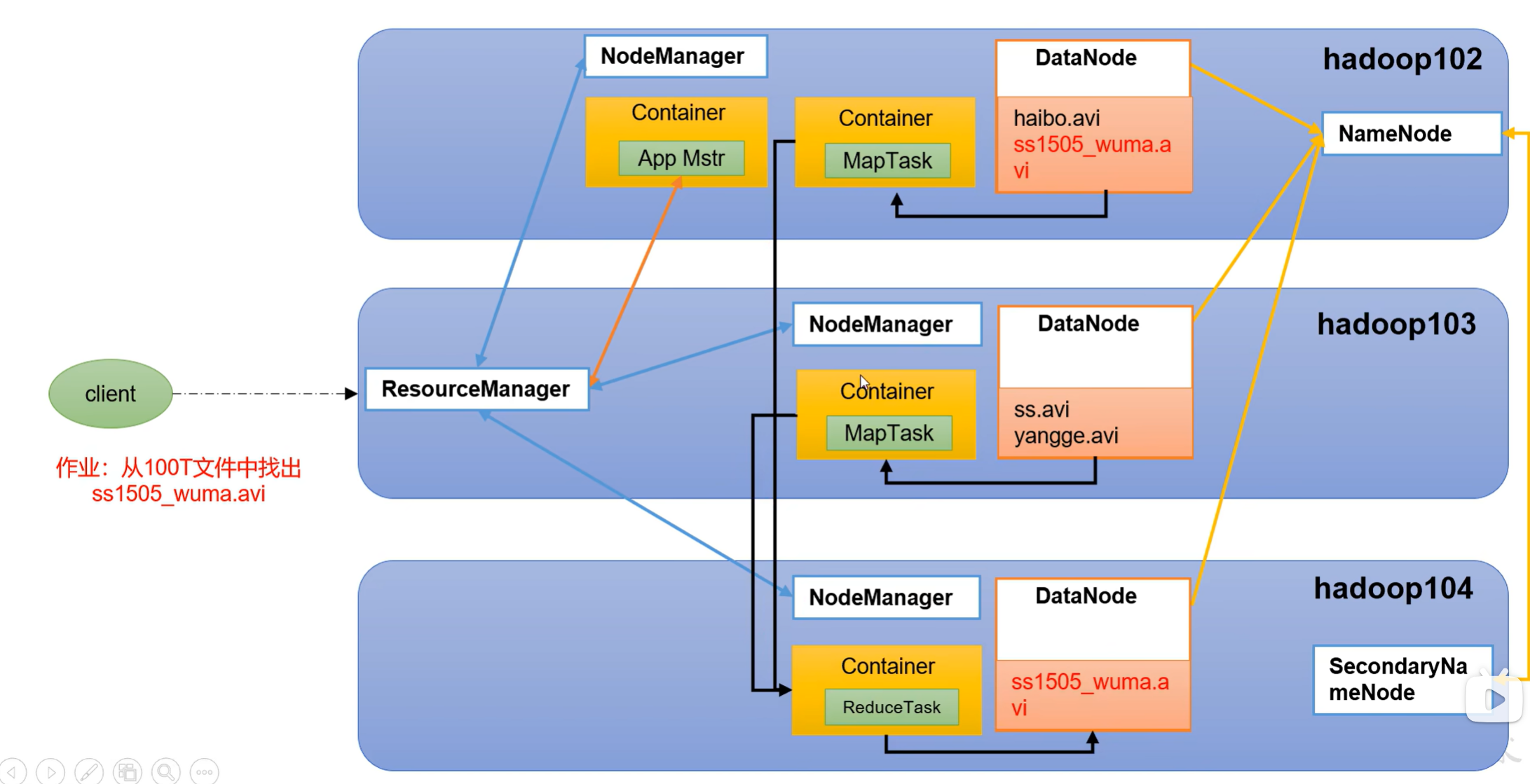
Yarn工作机制
HDFS & MapReduce
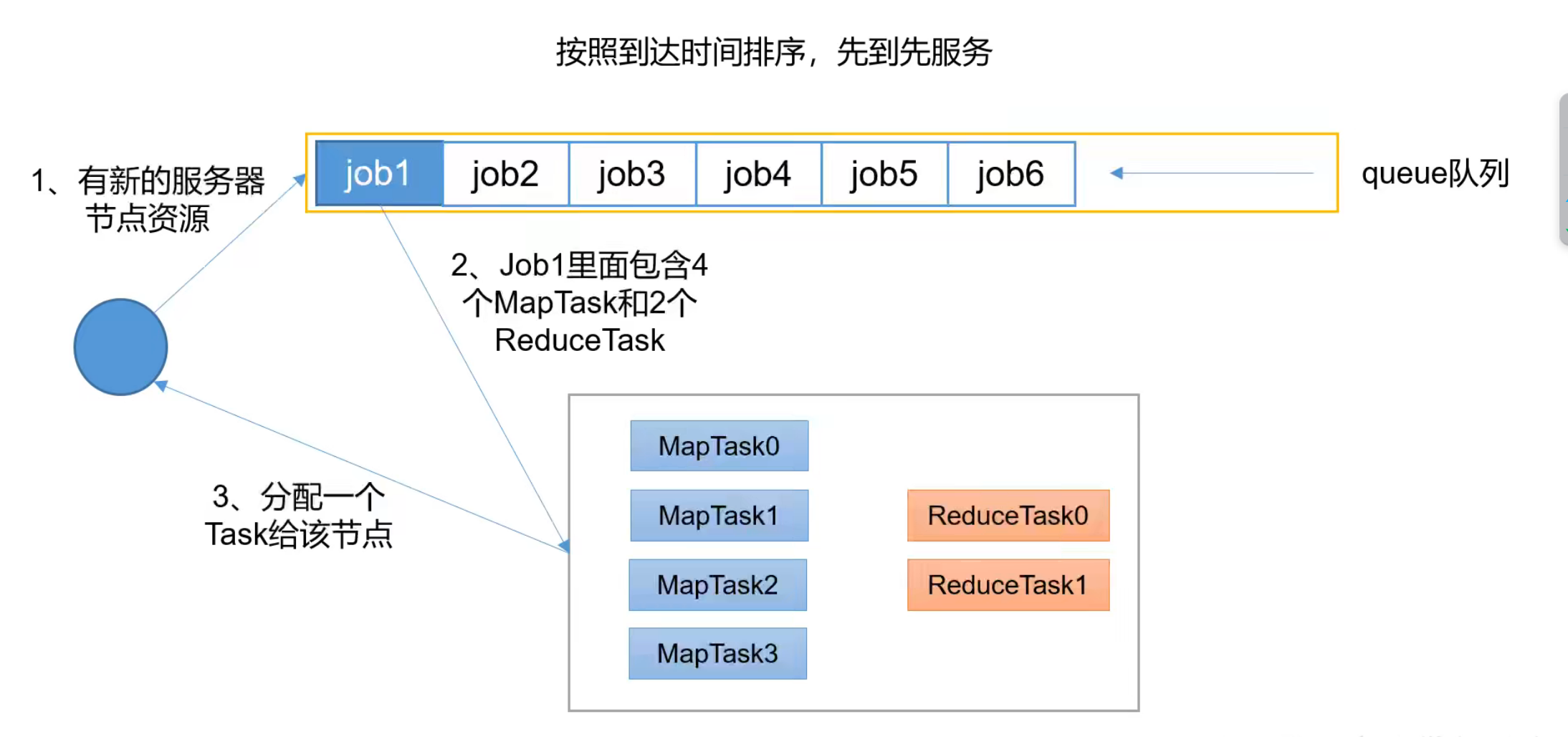
3.4 Yarn调度器和调度算法
目前,Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。Apache Hadoop3.l.3默认的资源调度器是Capacity Scheduler。.
CDH框架默认调度器是Fair Scheduler。
①先进先出调度器(FIFO)
②容量调度器
Capacity Scheduler是Yahoo(雅虎)开发的多用户调度器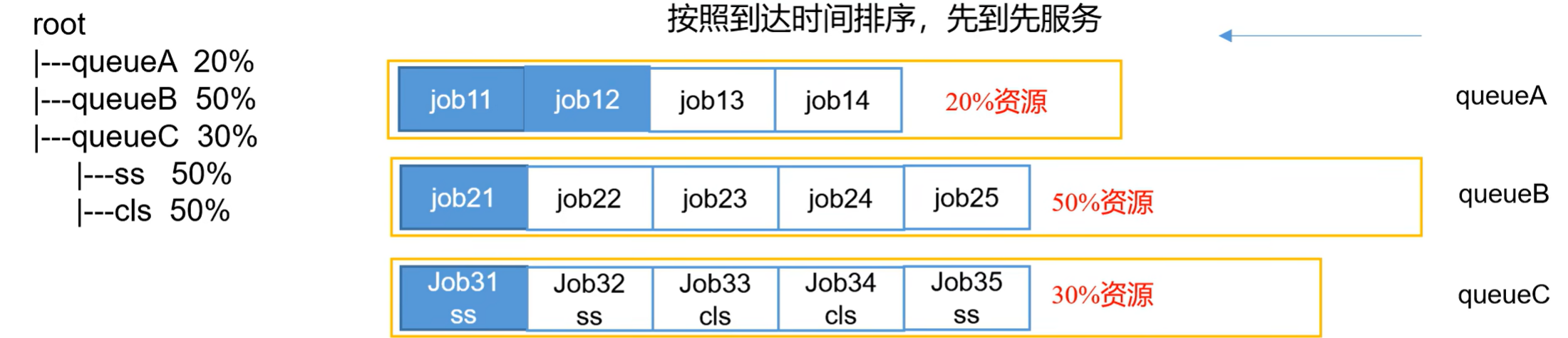
容量调度器特点:
1、多队列:每个队列可配置一定的资源量,每个队列采用FFO调度策略。
2、容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
3、灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
4、多租户:支持多用户共享集群和多应用程序同时运行。
为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。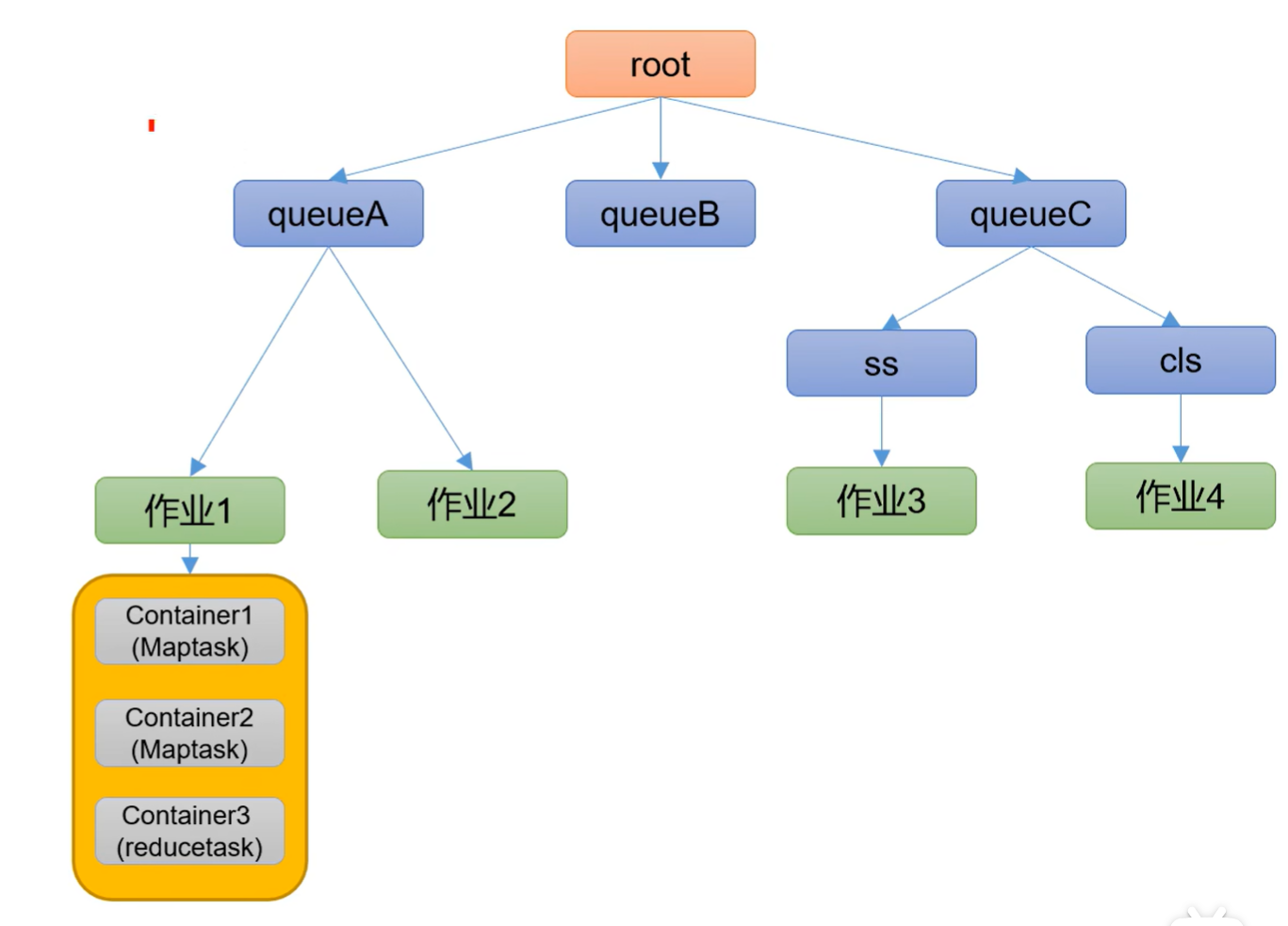
容量调度器资源分配算法:
1)队列资源分配
从root开始,使用深度优先算法,优先选择资源占用率最低的队列分配资源。
2)作业资源分配
默认按照提交作业的优先级和提交时间顺序分配资源。
3)容器资源分配
按照容器的优先级分配资源;如果优先级相同,按照数据本地性原则:
(1)任务和数据在同一节点
(2)任务和数据在同一机架
(3)任务和数据不在同一节点也不在同一机架
③公平调度器
Fair Schedulere 是Facebook开发的多用户调度器。,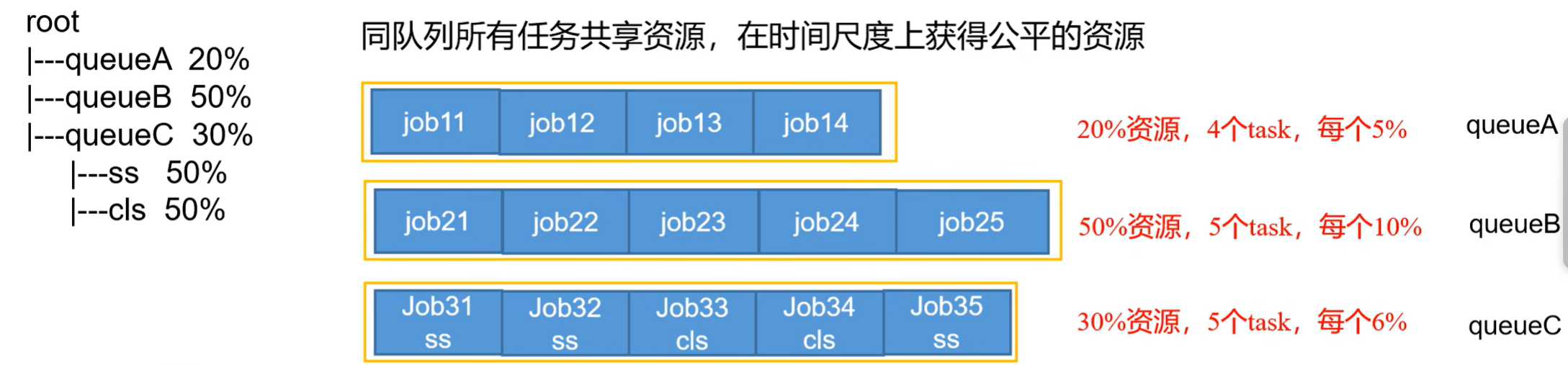
与容量调度器相同点
(1)多队列:支持多队列多作业
(2)容量保证:管理员可为每个队列设置资源最低保证和资源使用上线
(3)灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
(4)多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
与容量调度器不同点
(1)核心调度策略不同
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比例大的
(2)每个队列可以单独设置资源分配方式
容量调度器:FIFO、DRF
公平调度器:FIFO、FAIR、DRF
3.5 公平调度器——缺额
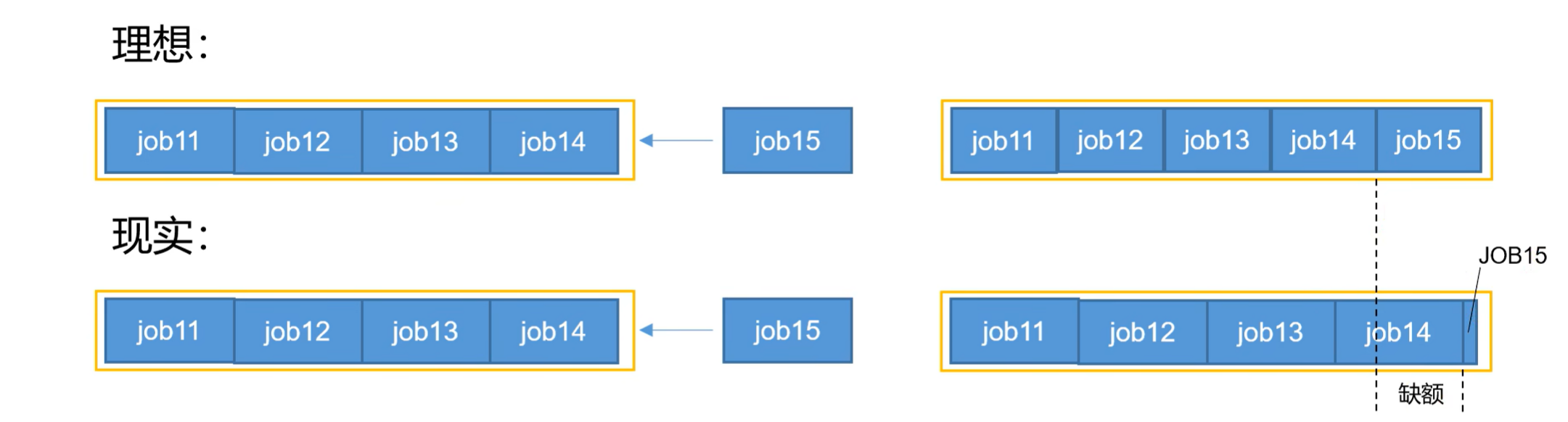
公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”
调度器会优先为缺额大的作业分配资源
3.6 公平调度器队列资源分配方式
(1)FIFO策略
公平调度器每个队列资源分配策略如果选择FFO的话,此时公平调度器相当于上面讲过的容量调度器。
(2)Fair策略
Fair策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到12的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
具体资源分配流程和容量调度器一致;
- 选择队列
- 选择作业
- 选择容器
以上三步,每一步都是按照公平策略分配资源
实际最小资源份额:mindshare=Min(资源需求量,配置的最小资源)
是否饥饿:isNeedy=资源使用量<mindshare(实际最小资源份额)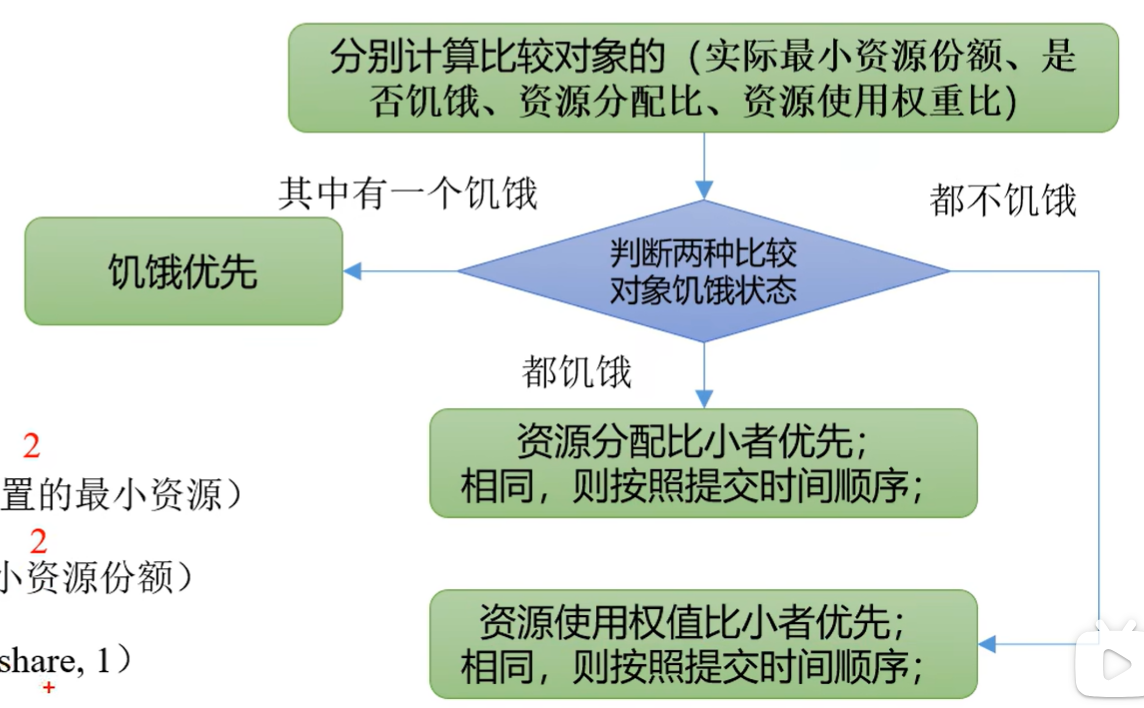
eg: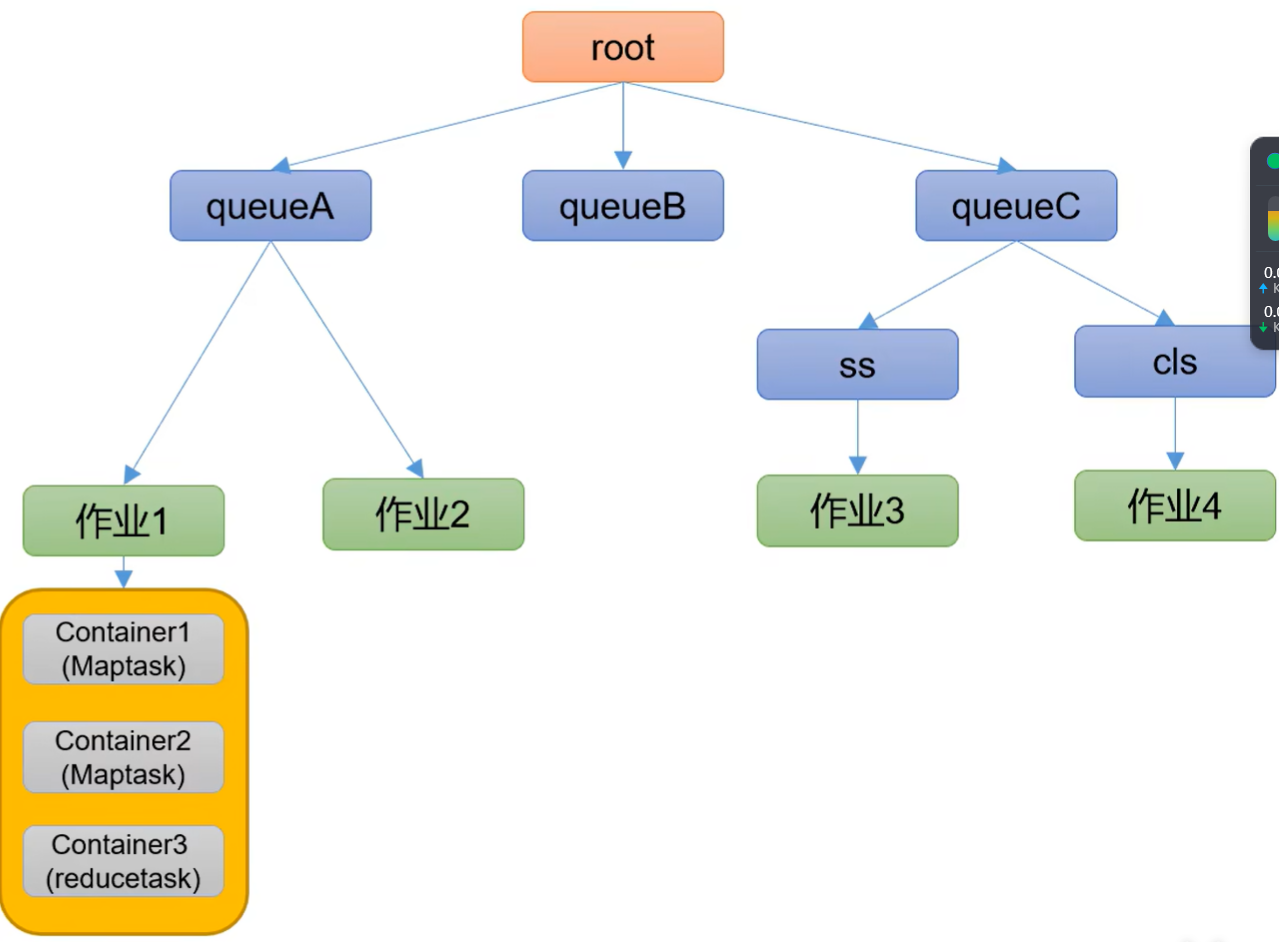
- 队列资源分配
需求:集群总资源100,有三个队列,对资源的需求分别是:
queueA->20,queueB->50,queueC -30
第一次算:100/3=33.33
queueA:分33.33→多13.33
queueB:分33.33→少16.67
queueC:分33.33→多3.33
第二次算:(13.33+3.33)/1=16.66
queueA:分20
queueB:分33.33+16.66=50
queueC:分30
- 作业资源分配

- DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:
假设集群一共有100CPU和10T内存,而应用A需要(2CPU,300GB),应用B需要(6CPU,100GB)。则两个应用分别需要A(2%CPU,3%内存)和B(6%CPU,1%内存)的资源,这就意味着A是内存主导的,B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Microsoft Office 2016 | Office2016怎么安装?
- 如何设置jeecg jeditor编辑器的高度及简洁模式
- String
- 浅谈前端工程化
- 一篇文章带你搞定CTFMice基本操作
- 只有可复制的生意才能做大,2024靠谱创业项目推荐!
- 网络安全全栈培训笔记(54-服务攻防-数据库安全&Redis&Hadoop&Mysqla&未授权访问&RCE)
- Python——面向对象
- es5和es6的区别
- 【halcon深度学习】dev_display_dl_data 移植到C# 上篇