CPU数据按行和按列读取性能差异浅析
改了一行代码,数组遍历耗时从10.3秒降到了0.5秒!
两个简单的测试程序
定义一个同样大小的二维数组,然后循环遍历,对数组元素赋值。
array1.c 对数组按行进行访问

? array2.c 对数组按列进行访问、

编译运行,并用time命令统计一下运行时间:

array1用时0.528秒,array2用时10.310秒。array2耗时居然是array1的将近20倍!
有没有被这个结果震惊到?为什么会有如此之大的性能差异呢?
重要说明
要想真正理解这个问题,必须要先补充一些关于现代计算机存储系统相关的背景知识,这也是理解这个问题的关键所在。为方便大家理解,我会尽量以白话的形式进行讲解,尽可能避免枯燥无味的纯理论描述。
存储金字塔
相信不少人都听过“存储金字塔”这个词,或者至少见过类似下面这张图:

这张图很直观地描述了现代计算机系统的分级存储模型。
可以认为CPU就位于金字塔的顶点上,越靠近塔顶,离CPU越近,访问速度越快,但生产成本越高,相应的容量也就越小。在所有存储器中,寄存器直接内嵌在CPU中,访问速度最快,容量也最小,一般CPU上也就最多几十个通用寄存器供应用程序使用。
反之,越往下靠近塔底,访问速度越慢,生产成本越低,相应的容量也就越大。比如图中最底部的网络存储设备,相对其他存储设备而言是访问速度最慢的,但其容量却几乎可以认为是无限制的。
那么,这种金字塔式结构中,不同层级的存储设备之间究竟是如何协调工作的呢?
用一句话概括:
高一级的存储设备,往往是作为低一级存储设备的缓存来使用的。
简单来说,系统运行时,为了提升数据访问效率,把程序中最近最经常访问的数据,尽可能放到访问速度更快的高一级存储器中。这样一来,每次访问数据时,从金字塔的顶端开始,都先尝试在高一级存储器中查找,如果被访问的数据存在且有效,则直接访问,否则,就逐级到更低级的存储器中去查找。
这种金字塔式的分级存储模型之所以能够以近乎完美的方式运行,实际上都是建立在现代计算机科学中的一个非常重要的理论基础之上:程序的局部性原理。
局部性原理
一个程序的局部性,包含两个维度:时间局部性和空间局部性。
-
??时间局部性。如果一个数据在某个时间点被CPU访问了,那么在接下来很短的一段时间内,这个数据很有可能会再次被CPU访问到。
-
??空间局部性。如果一个数据在某个时间点被CPU访问了,那么与这个数据临近的其他数据,很有可能也会很快被CPU访问到。
高速缓存 - Cache
根据常识,我们知道,程序要想被CPU正常执行,必须要先被加载到内存中。
但是,内存的访问速度与CPU运行速度相比,要慢好几个数量级,可以想象一下,如果CPU每次都直接从内存中存取数据,会造成大量的计算资源浪费,程序性能严重受损,假如真是这样的话,你还能像现在这样愉快的吃鸡吗?
为了解决CPU和内存之间速度严重不匹配的问题,在CPU和内存之间设计了高速缓存,即Cache。

目前,主流CPU一般都有三级(或更多级)的Cache,依次是L1 Cache、L2 Cache、L3 Cache。其中L1 Cache速度最快,几乎可以和内嵌在CPU中的寄存器媲美,容量也最小,而L3 Cache速度最慢(但仍然比内存快很多),但容量最大。
CPU读取数据时,会在L1、L2、L3Cache中逐级查找,如果找到,就从Cache直接读取,找不到再从内存读取,并且把数据存放到Cache中,以便提高下次访问的效率。
在这个过程中,如果在Cache中找到所需数据,称为Cache命中(Cache Hit), 找不到称为Cache未命中(Cache Miss)。
不难看出,L1 Cache命中的时候,读取数据最快,性能最好,而当L1、L2、L3 Cache全部未命中时,就必须要直接从内存中读取数据,性能最差!
Cache Line
Cache Line 是 Cache和内存之间进行数据传输的最小单位。
根据上文讲解的程序的局部性原理,如果一个数据被CPU访问了,那么这个数据相邻的其他数据也很快会被访问到。因此,为了提高内存数据的读取效率,并且最大化利用CPU资源,数据在Cache和内存之间传输时,不是一个字节一个字节进行传输的,而是以缓存行(Cache Line)为单位进行传输的。
不同CPU的Cache line大小可能不同,典型的CPU Cache line大小是64个字节。
我们通过下面一个简单的例子,加深一下理解。
Cache Line 实例讲解
在一个Cache Line大小为64字节的机器上,定义个数组:
int?a[16]?=?{1,?2,?3,?4,?5,?6,?7,?8,?9,?10,?11,?12,?13,?14,?15,?16};我们假设数组a的起始地址是Cache Line对齐的,可以简单理解为a的地址能被64整除。假设,数组a还从来没有被访问过,如果此时需要访问a中的一个元素a[5],如:
int?x?=?a[5];由于在此之前数组a没有被访问过,所以理论上讲,数组a应该只存在于内存中,并未被加载到Cache中。因此,此时CPU在Cache中找不到a[5],触发Cache Miss,然后需要从内存中读取数据,并更加载到Cache中。前面提到,Cache和内存之间是以Cache Line为单位进行数据传输的,因此,这里会把一个Cache line大小(64字节)的数据从内存读取出来加载到Cache中。由于a的起始地址恰巧是Cache line对齐的,所以CPU会把整个数组(64个字节,刚好一个Cache Line)都加载到Cache中。
紧接着,如果再访问数组a的元素,如:
int?y?=?a[10];此时,整个数组都在Cache中,所以CPU在访问时,触发Cache Hit,直接从Cache读取数据即可,不需要再从内存中读取。
了解了Cache的背景知识,现在来分析下array1.c和array2.c为什么会存在这么巨大的性能差异。
按行、列访问的真正差异 - Cache
首先,必须要知道一点:C语言的数组,所有元素是存放在地址连续的内存中的,此外,C语言的多维数组,是按行进行存储的。
array1.c按行对数组进行访问,也就是从数组起始地址开始,一直连续访问到数组的最后一个元素的地址处。第一次访问一个Cache Line的首个元素时,触发Cache Miss,与该元素临近的几个元素会组成一个Cache Line,被一起加载到Cache中。如此,在访问下一个元素的时候,就会Cache Hit,直接从Cache读取数据即可。
而array2.c按列对数组进行访问,因此并不是按照连续地址进行访问的,而是每次间隔10240 * 4个字节进行访问。第一次访问一个Cache Line的首个元素时,假设地址为x,尽管该元素临近的一个Cache Line大小的元素也会被一起加载进Cache中,但是程序接下来访问的并不是临近的元素,而是地址为x + 10240 * 4处的元素,因此会再次触发Cache Miss。而当程序回过头来访问x + 4地址处的元素时,这个Cache Line可能已经被其他数据冲刷掉了。因为,尽管Cache会尽量缓存最近访问过的数据,但毕竟大小有限,当Cache被占满时,一些旧的数据就会被冲刷替换掉。
可以看出,无论是时间局部性还是空间局部性,array1.c都要比array2.c好很多!相比array1.c,array2.c会触发大量的Cache Miss,这也是为什么array2的性能会如此之差!
下面我们用perf来对比下这两个程序的性能指标。
用perf观测性能指标
perf是Linux提供的一个功能强大的实用性能调优工具,它可以用来观测几乎所有CPU相关的性能指标,但perf工具本身,不是本文重点,以后会有专门文章详细介绍perf的使用。
先获取array1.c的性能指标:

再看下array2.c的性能指标:
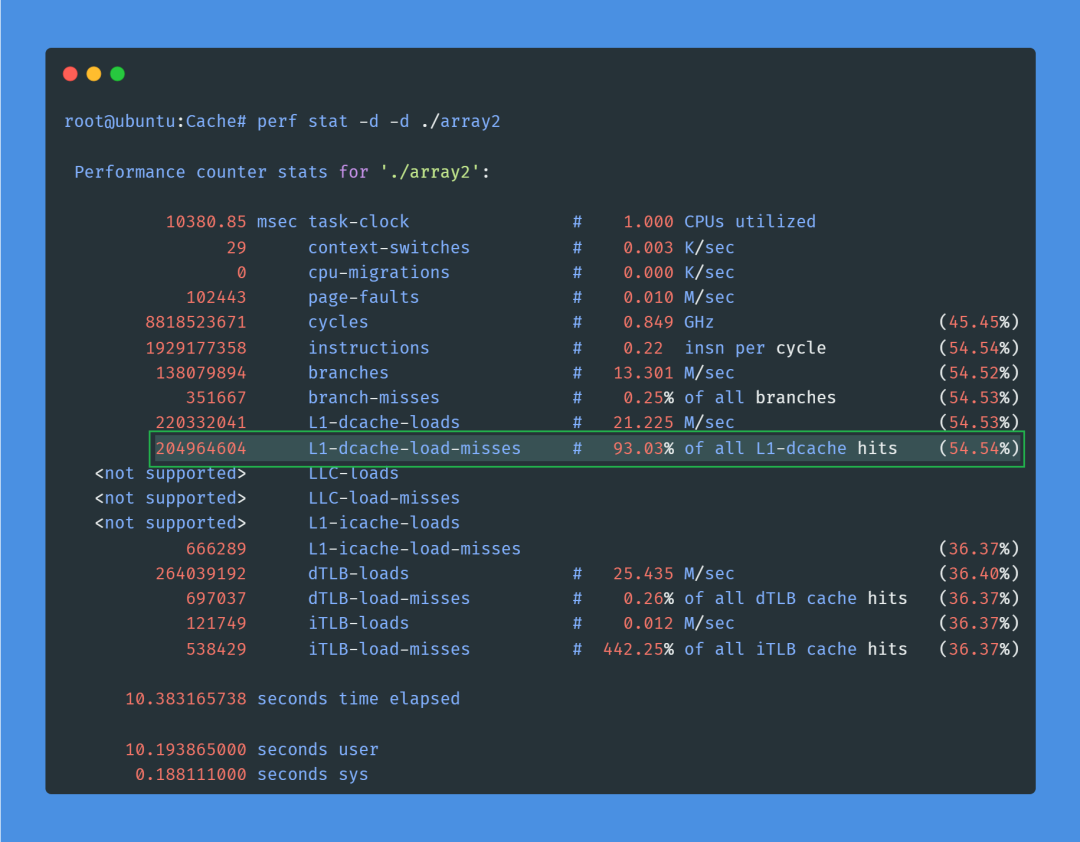
这里,我们只关注一个最重要的性能指标:L1 Data Cache的Miss率。
对比一下,array1.c的L1-dcache-load-misses率只有3.10%, 而按列访问的array2.c,则达到了惊人的93.03%!这就是两者性能差异如此巨大的真相!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【前端技术】跨标签页通信的8种方式(下)
- 2023.12.30力扣每日一题——一周中的第几天
- 外包干了3个月,技术退步明显
- 漏洞复现-海康威视 NCG 联网网关 login.php 目录遍历漏漏洞(附漏洞检测脚本)
- HTML5简介与基础骨架
- missingno——缺失数据可视化
- MySQL基础入门(一)
- 【tensorflow&flutter&web】机器学习模型怎样用到前端上(未写完)
- 怎么使用AI人工智能抠图?不妨试试这样做
- RDD键值对的应用——一个简单的例子对比用与不用键值对的差别