hpa自动伸缩
1、定义:hpa全称horizontal pod autoscaling(pod的水平自动伸缩),这是k8s自带的模块。pod占用CPU的比率到达一定阀值会触发伸缩机制(根据CPU使用率自动伸缩)
replication controller副本控制器,控制pod的副本数
deployment controller节点控制器,部署pod
hpa控制副本的数量以及控制部署pod
(1)hpa基于kube-controll-manager服务,周期性的检测pod的CPU使用率,默认30秒检测一次
(2)hpa和replication controller、deployment controller都属于k8s的资源对象,通过跟踪分析副本控制器和deployment的pod的负载变化,针对性的调整目标pod的副本数(针对性:有一个阀值,正常情况下,pod的副本数,以及达到阀值后pod的扩容最大数量)
(3)metrics-server部署到集群中去,对外提供度量的数据
2、hpa规则【面试】
(1)定义pod时必须要有资源限制,否则hpa无法进行监控
(2)扩容是即时的,只要超过阀值会立刻扩容,但不是立刻扩容到最大副本数,会在最小值和最大值之间波动。若扩容数量满足需求,不会再扩容
(3)缩容是缓慢的,若业务峰值较高,回收策略太积极可能对业务产生崩溃。周期行的获取数据,缩容的机制问题
3、pod的副本数扩缩容有两种方式
(1)手动方式,修改控制器的副本数
方式1:命令行通过kubectl scale deployment nginx --replicas=3
![]()
方式2:edit修改控制器
![]()

方式3:修改yaml文件,使用apply -f部署更新
![]()
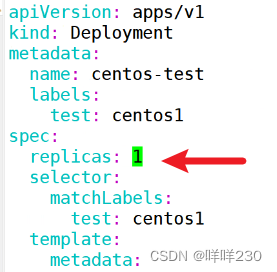
(2)hpa自动扩缩容
监控指标是cpu
hpa自动扩缩容实验
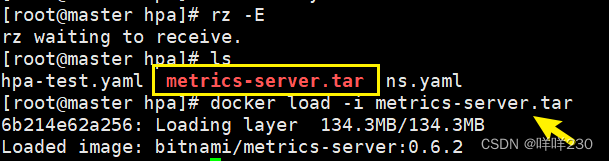
1、安装镜像包(每个节点)
docker load -i metrics-server.tar


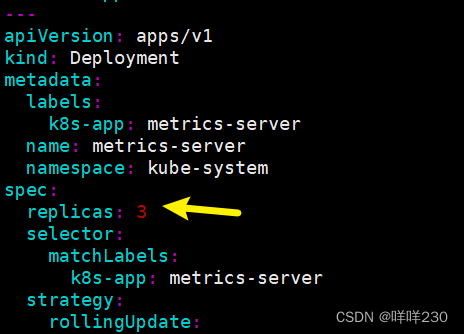
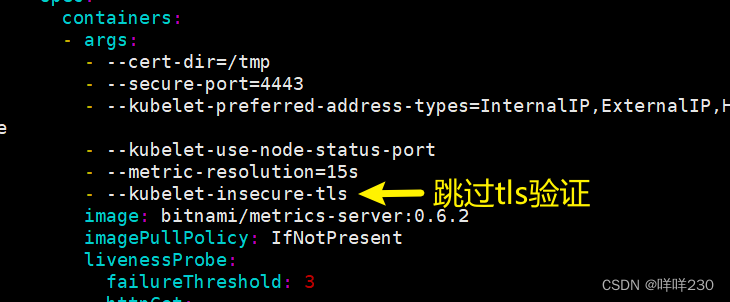
2、安装yaml文件(master节点)
 查看pod以及node节点占用cpu情况
查看pod以及node节点占用cpu情况
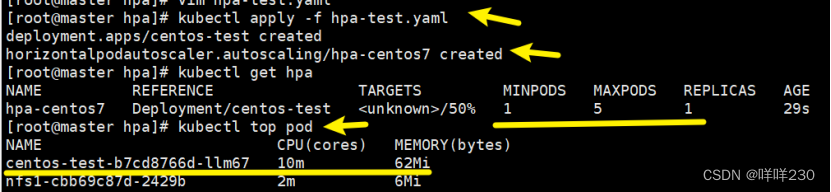
3、实现hpa
![]()


 4、模拟cpu负载,压力测试
4、模拟cpu负载,压力测试





下降原因:每个pod部署在不同节点上
5、再做压力测试
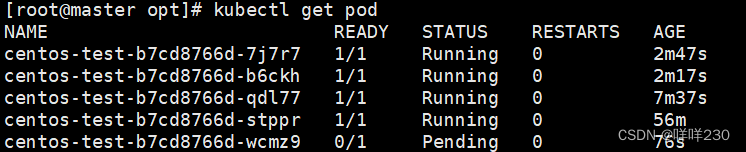 观察数据
观察数据

结论:一旦超过阀值,立刻扩容
6、缩容:关闭压力测试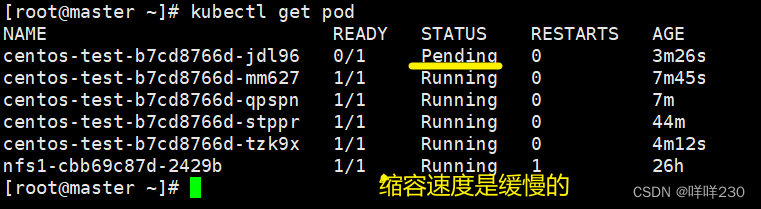


4、资源限制
(1)pod的资源限制limit
(2)命名空间资源限制★★★
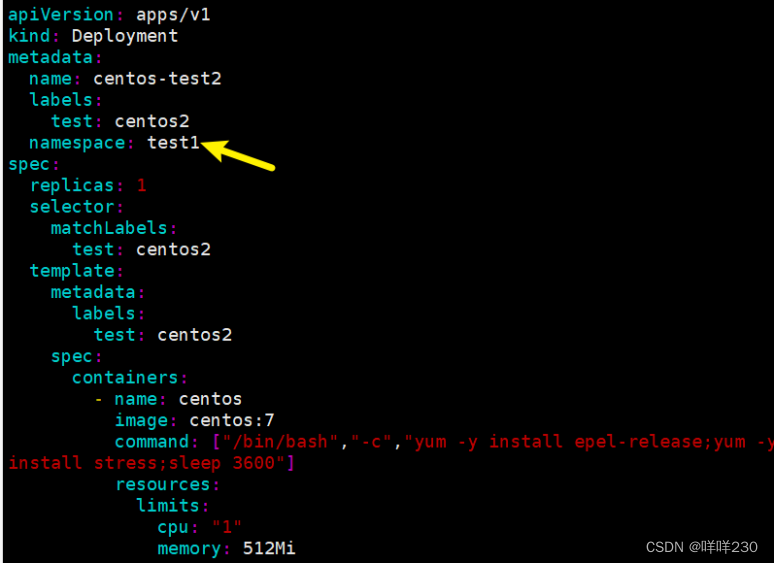
lucky-cloud项目部署在test1的命名空间,若pod不做限制,或命名空间不做限制,依然会占满所有集群资源
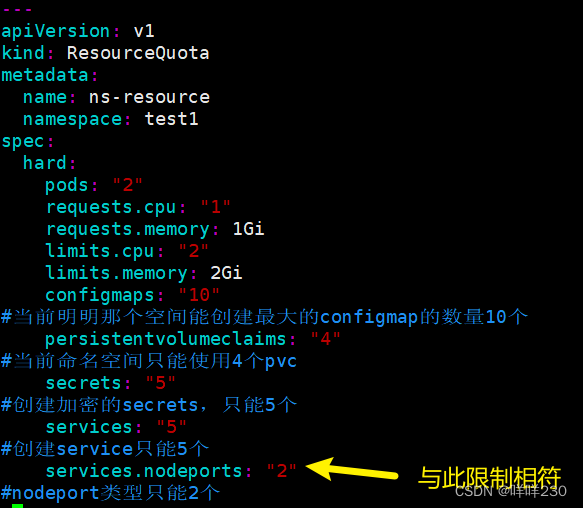
①ResourceQuata可以对命名空间进行资源限制
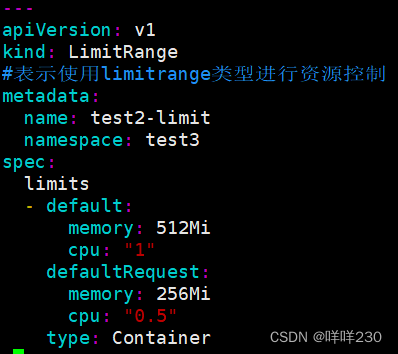
②LimitRange直接声明在命名空间中创建的pod或容器的资源限制(这是一个统一限制,所有在这个命名空间中的pod都受这个条件的限制)
??ResourceQuata
创建命名空间test1
![]()
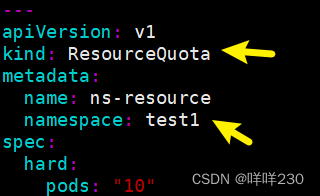
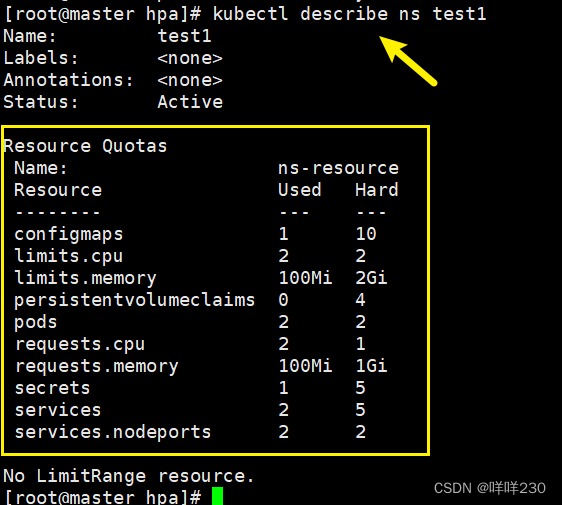
对命名空间进行资源限制
![]()


测试
①调整pod副本数



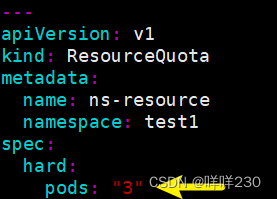
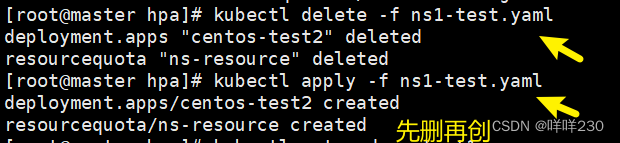

结论:在此命名空间只能创建3个有效的pod
②缩容
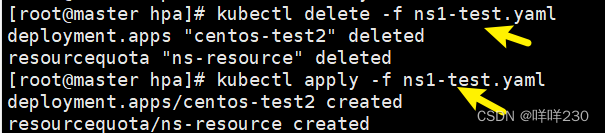

③命名空间其他限制条件
![]()

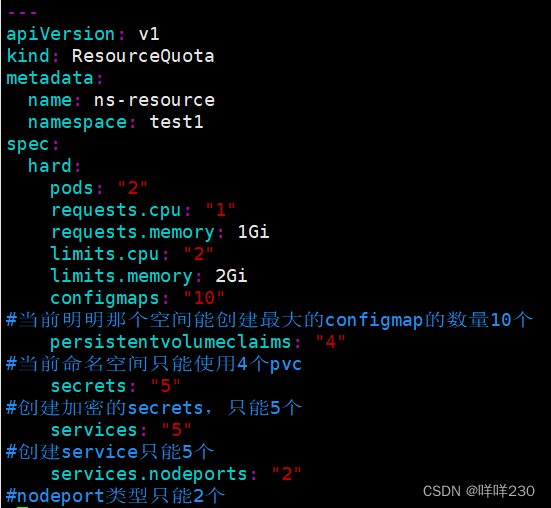
| configmaps: "10" | 在当前名命名空间创建最大的configmap的数量10个 |
| persistentvolumeclaims: "4" | 在当前命名空间只能使用4个pvc |
| secrets: "5" | 创建加密的secret只能5个 |
| services: "5" | 创建service的个数只能5个 |
| services.nodeports: "2" | 创建service的nodeport类型的svc只能2个 |

测试
①创建svc1
![]()

![]()

结论:第1个svc创建成功
②创建svc2
![]()

![]()

结论:第2个svc创建成功
③创建svc3
![]()


结论:在test1这个命名空间中限制只能创建2个service.nodeport
查看命名空间的限制
??LimitRange

创建命名空间
![]()


![]()

压力测试


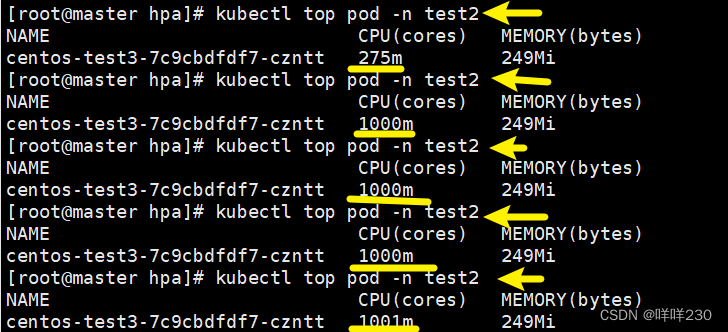
结论:最多只能占1个cpu(1000m代表1个cpu)
| type类型 |
| container(常用) |
| pod |
| pvc |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- leetcode
- 翻译: 为什么需要微调大模型 Why Fine-tuning LLM
- 2024版 - Mac安装pod (测试环境为M3,其他架构应该类似)
- 使用PJL 开发一个文档打印多份copies的打印顺序参数是啥?
- ES-mapping
- 104. 二叉树的最大深度
- Nestjs使用log4j打印日志
- QML —— ProgressBar示例(附完整源码)
- 每日一题——LeetCode961
- 浪花 - 更新队伍信息