【视觉SLAM十四讲学习笔记】第五讲——相机模型
专栏系列文章如下:
【视觉SLAM十四讲学习笔记】第一讲——SLAM介绍
【视觉SLAM十四讲学习笔记】第二讲——初识SLAM
【视觉SLAM十四讲学习笔记】第三讲——旋转矩阵
【视觉SLAM十四讲学习笔记】第三讲——旋转向量和欧拉角
【视觉SLAM十四讲学习笔记】第三讲——四元数
【视觉SLAM十四讲学习笔记】第三讲——Eigen库
【视觉SLAM十四讲学习笔记】第四讲——李群与李代数基础
【视觉SLAM十四讲学习笔记】第四讲——指数映射
【视觉SLAM十四讲学习笔记】第四讲——李代数求导与扰动模型
前面两讲中,我们介绍了“机器人如何表示自身位姿”的问题,部分地解释了SLAM经典模型中变量的含义和运动方程部分。本讲将讨论“机器人如何观测外部世界”,也就是观测方程部分。而在以相机为主的视觉SLAM中,观测主要是指相机成像的过程。
三维世界中的一个物体反射或发出的光线,穿过相机光心后,投影在相机的成像平面上。相机的感光器件接收到光线后,产生测量值,就得到了像素,形成了我们见到的照片。这个过程能否用数学原理来描述呢?
本讲将首先讨论相机模型,说明投影关系具体如何描述,相机的内参是什么。同时,简单介绍双目成像与RGB-D 相机的原理。然后,介绍二维照片像素的基本操作。最后,根据内外参数的含义,演示一个点云拼接的实验。
相机模型
相机将三维世界中的坐标点(单位为米)映射到二维图像平面(单位为像素)的过程能够用一个几何模型进行描述,称为针孔模型,它描述了一束光线通过针孔之后,在针孔背面投影成像的关系。 同时,由于相机镜头上的透镜的存在,使得光线投影到成像平面的过程中会产生畸变。因此,我们使用针孔和畸变两个模型来描述整个投影过程。这两个模型能够把外部的三维点投影到相机内部成像平面,构成相机的内参数(Intrinsics)。
针孔相机模型
在一个暗箱的前方放着一支点燃的蜡烛,蜡烛的光透过暗箱上的一个小孔投影在暗箱的后方平面上,并在这个平面上形成一个倒立的蜡烛图像。在这个过程中,小孔模型能够把三维世界中的蜡烛投影到一个二维成像平面。同理,可以用这个简单的模型来解释相机的成像过程。如图所示:
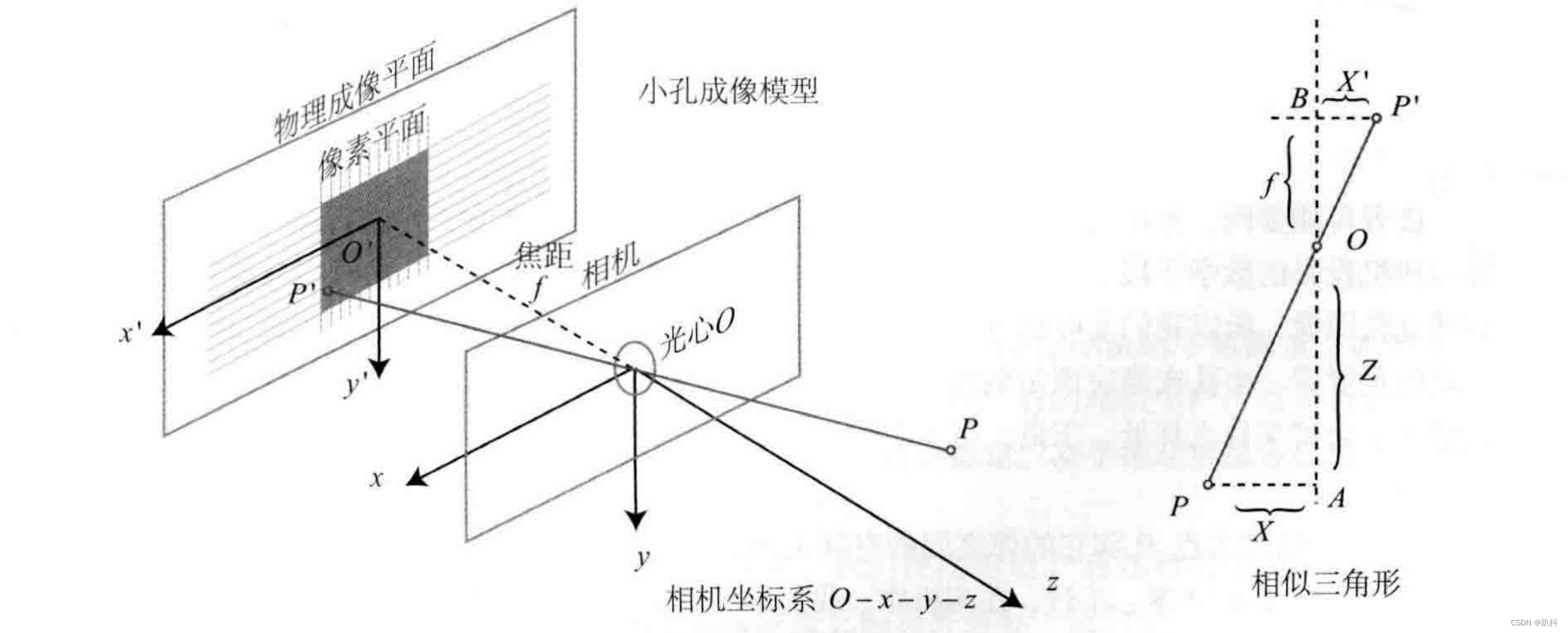
对这个简单的针孔模型进行几何建模。设 O ? x ? y ? z 为相机坐标系,z 轴指向相机前方,x 向右,y 向下。O为摄像机的光心,也是针孔模型中的针孔。现实世界的空间点P,经过小孔O投影之后,落在物理成像平面 O′ ? x′ ? y′ 上,成像点为 P′。设 P 的坐标为 [X,Y,Z]T,P′ 为 [X′,Y′,Z′]T,设物理成像平面到小孔的距离为f(焦距)。那么,根据三角形相似关系,有:
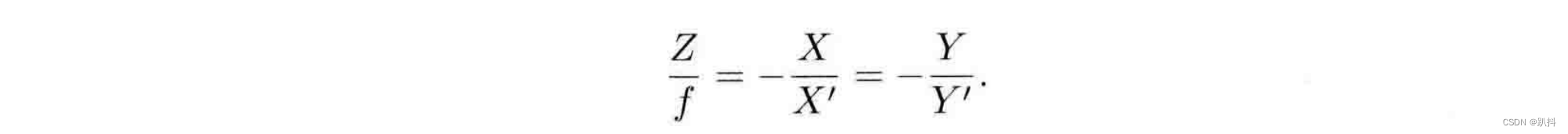
其中负号表示成的像是倒立的。不过,实际相机得到的图像并不是倒像,我们可以等价地把成像平面对称地放到相机前方,和三维空间点一起放在摄像机坐标系的同一侧,如图所示。这样做可以把公式中的负号去掉,使式子更加简洁:
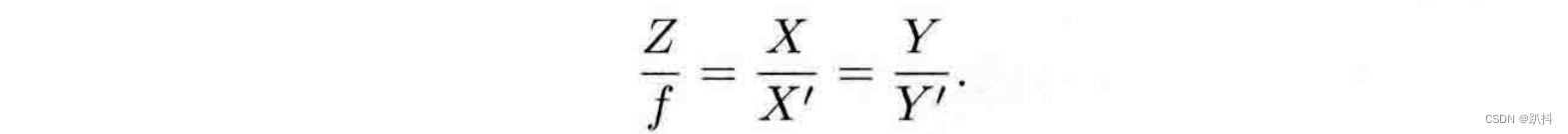
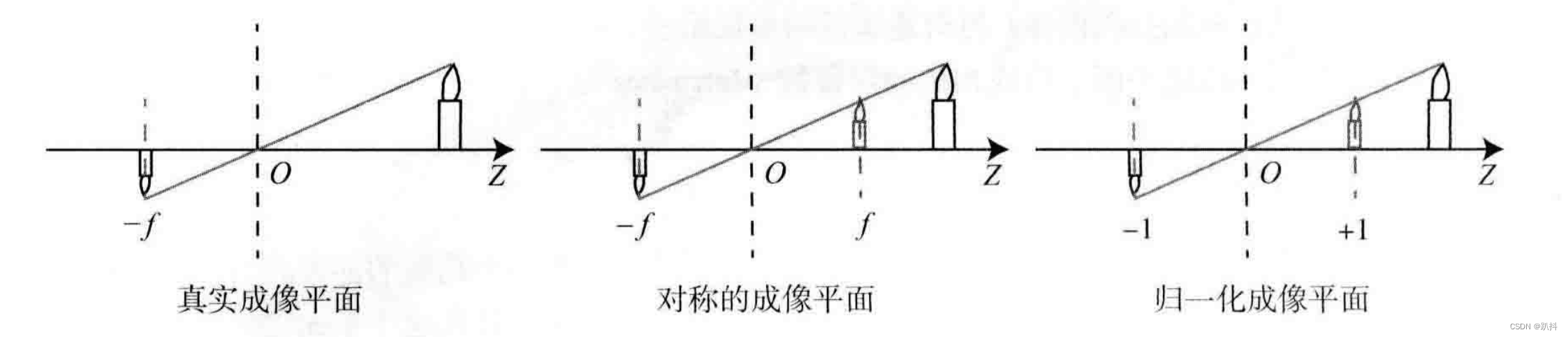
把X′,Y′ 放到等式左侧,整理得:
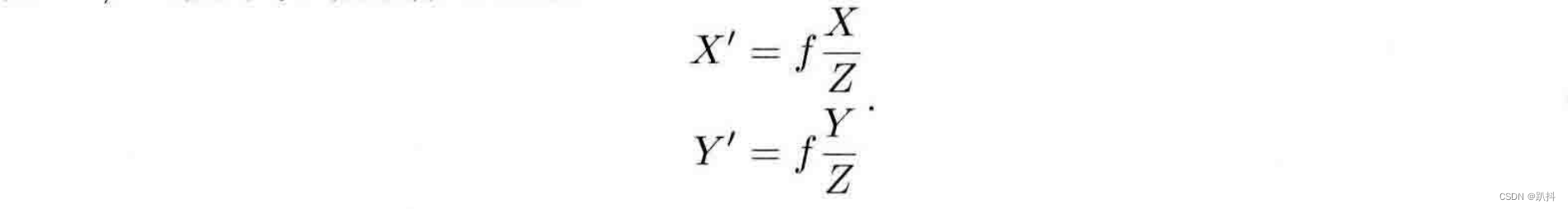
这描述了点 P和它的像之间的空间关系,这里所有点的单位都可以理解成米。不过在相机中,我们最终获得的是一个个的像素,这还需要在成像平面上对像进行采样和量化。为了描述传感器将感受到的光线转换成图像像素的过程,设在物理成像平面上固定着一个像素平面 o ? u ? v。我们在像素平面得到了P′的像素坐标:[u,v]T。
像素坐标系(或图像坐标系)通常的定义方式是:原点o′位于图像的左上角,u 轴向右与 x 轴平行,v 轴向下与 y 轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。设像素坐标在 u 轴上缩放了 α 倍,在 v 上缩放了 β 倍。同时,原点平移了 [c_x,c_y]T。那么,P′ 的坐标与像素坐标[u,v]T 的关系为:
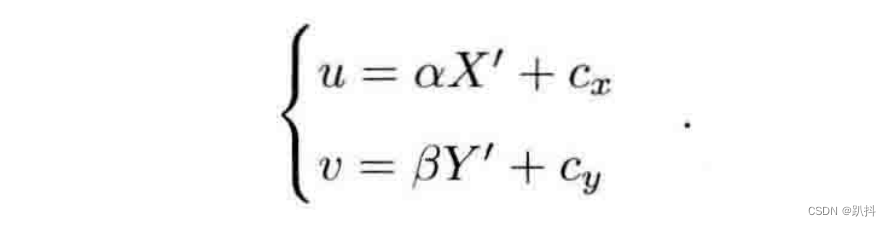
代入式
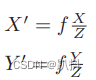
把 αf 合并成 f_x,把 βf 合并成 f_y,得:
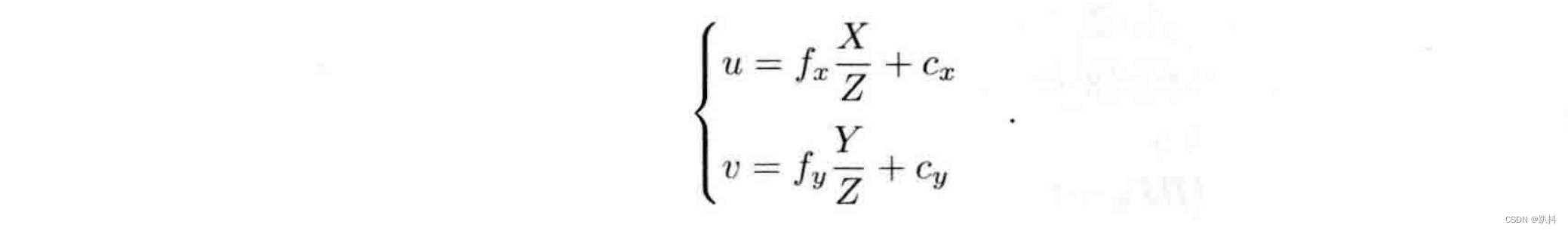
其中,f 的单位为米,α,β 的单位为像素/米,所以 f_x,f_y 和 c_x,c_y 的单位为像素。写成矩阵形式,左侧需要用到齐次坐标,右侧则是非齐次坐标:
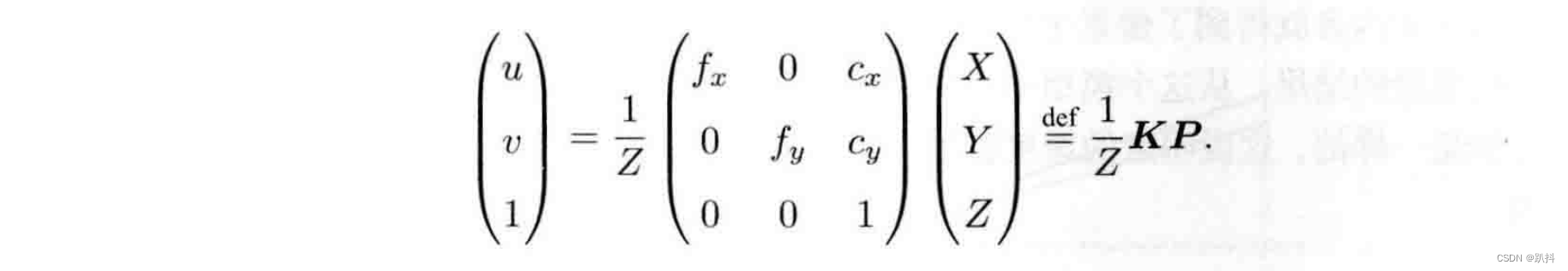
我们习惯性把Z挪到左侧:
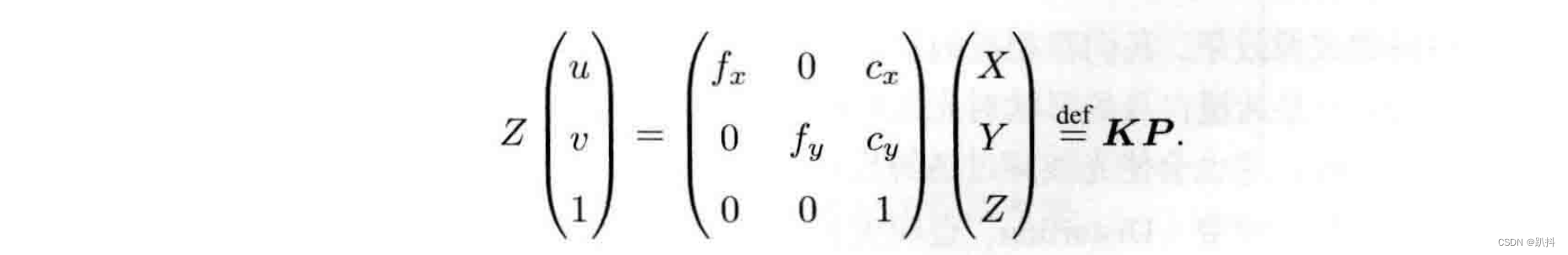
K矩阵称为相机的内参数矩阵(Camera Intrinsics)。通常相机的内参在出厂之后是固定的,不会在使用过程中发生变化。但有时需要自己确定相机的内参,也就是所谓的标定。
有内参,自然也有相对的外参。前面内参公式中的P是在相机坐标系下的坐标。由于相机在运动,所以P是相机的世界坐标(记为Pw)根据相机的当前位姿变换到相机坐标系下的结果。相机的位姿由它的旋转矩阵R和平移向量t来描述。那么有:
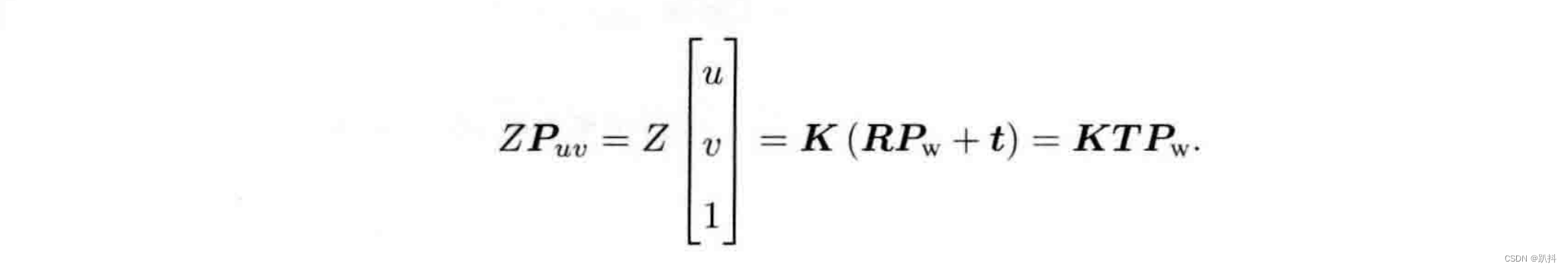
后一个式子隐含了一次齐次坐标到非齐次坐标的转换。它描述了P的世界坐标到像素坐标的投影关系。相机的位姿R,t称为相机的外参数(Camera Extrinsics) 。 相比于不变的内参,外参会随着相机运动发生改变,同时也是 SLAM 中待估计的目标,代表着机器人的轨迹。
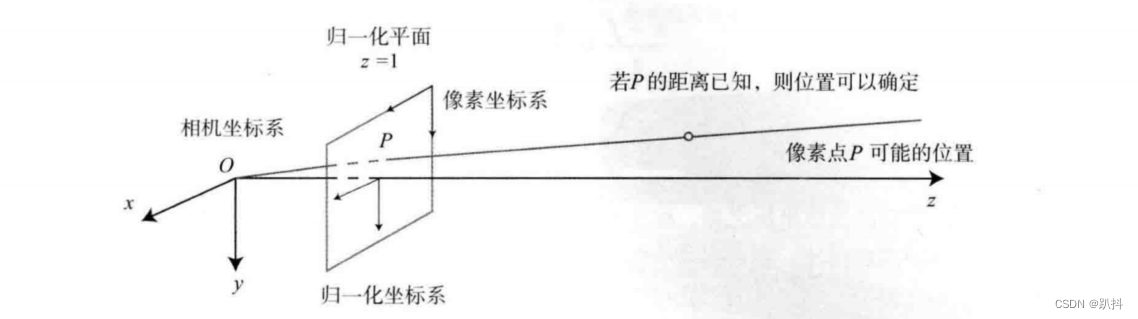
式子表明,可以把一个世界坐标点先转换到相机坐标系,再除掉它最后一维(Z)的数值(即该点距离相机成像平面的深度),这相当于把最后一维进行归一化处理,得到点 P 在相机归一化平面上的投影:

归一化坐标可看成相机前方z=1处的平面上的一个点,这个 z = 1 平面也称为归一化平面。归一化坐标再左乘内参就得到了像素坐标,所以可以把像素坐标 [u,v]T 看成对归一化平面上的点进行量化测量的结果。从这个模型中可以看出,对相机坐标同时乘以任意非零常数,归一化坐标都是一样的,这说明点的深度在投影过程中被丢失了,所以单目视觉中没法得到像素点的深度值。
畸变模型
为了获得好的成像效果,我们在相机的前方加了透镜。透镜的加入会对成像过程中光线的传播产生新的影响:一是透镜自身的形状对光线传播的影响;二是在机械组装过程中,透镜和成像平面不可能完全平行,这也会使光线穿过透镜投影到成像面时的位置发生变化。
由透镜自身形状引起的畸变(Distortion,也叫失真)称为径向畸变。在针孔模型中,一条直线投影到像素平面上还是一条直线。可是,在实际拍摄的图片中,摄像机的透镜往往使得真实环境中的一条直线在图片中变成了曲线。越靠近图像的边缘,这种现象越明显。由于实际加工制作的透镜往往是中心对称的,这使得不规则的畸变通常径向对称。它们主要分两大类:桶形畸变和枕形畸变。
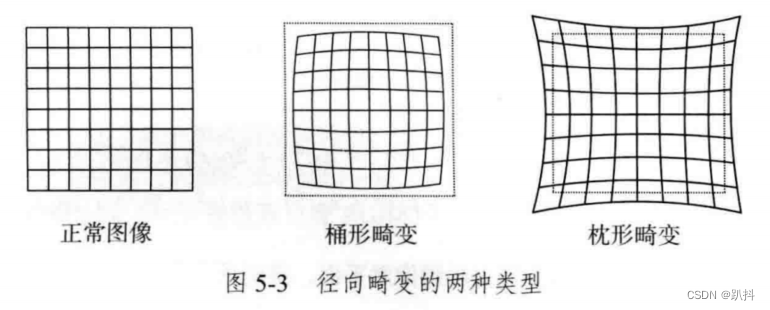
桶形畸变图像放大率随着与光轴之间的距离增加而减小,而枕形畸变则恰好相反。在这两种畸变中,穿过图像中心和光轴有交点的直线还能保持形状不变。
除了透镜的形状会引入径向畸变,由于在相机的组装过程中不能使透镜和成像面严格平行,所以也会引入切向畸变。
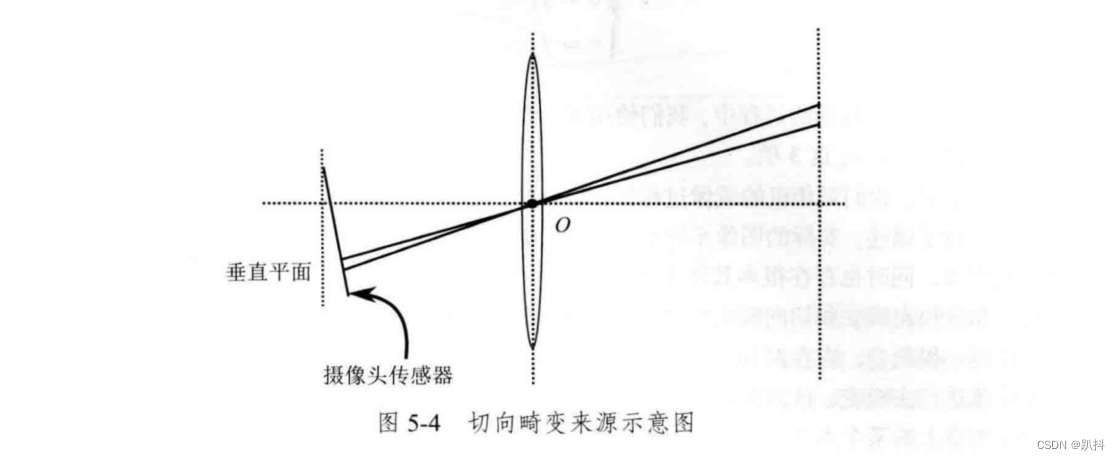
考虑归一化平面的任意一点p,它的坐标为[x,y]T ,也可写成极坐标的形式[r,θ]T ,其中r表示点p与坐标系原点之间的距离,θ表示与水平轴的夹角。
径向畸变可以看成坐标点沿着长度方向发生了变化,也就是其距离原点的长度发生了变化。通常假设这些畸变呈多项式关系,即:
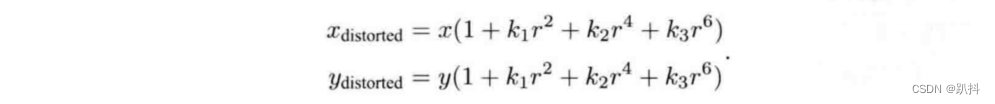
其中,[x_distorted,y_distorted]T 是畸变后点的归一化坐标。
切向畸变可以看成坐标点沿着切线方向发生了变化,也就是水平夹角发生了变化。对于切向畸变,可以使用另外两个参数p1 ,p2进行纠正:
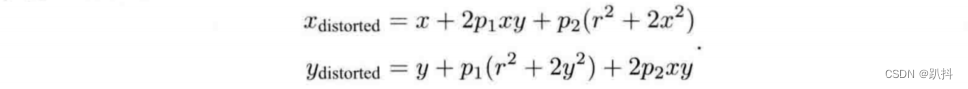
联合上面两式,对于相机坐标系中的一点P,能够通过 5 个畸变系数找到这个点在像素平面上的正确位置:
-
将三维空间点投影到归一化图像平面。设它的归一化坐标为 [x,y]T。
-
对归一化平面上的点计算径向畸变和切向畸变。
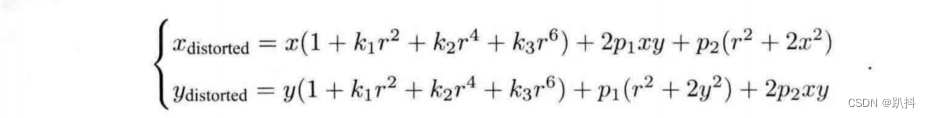
-
将畸变后的点通过内参数矩阵投影到像素平面,得到该点在图像上的正确位置。
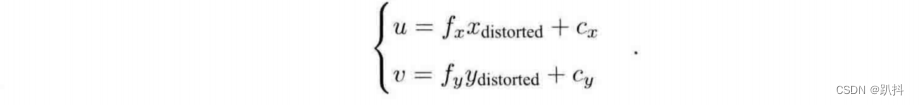
在实际应用中,可以灵活选择纠正模型,比如只选择 k1,p1,p2 这 3 项等。
实际的图像系统中,学者们提出了很多其他的模型,比如相机的仿射模型和透视模型等,同时也存在很多其他类型的畸变。视觉 SLAM 中一般都使用普通的摄像头,针孔模型及径向畸变和切向畸变模型已经足够。 当一个图像去畸变之后,我们就可以直接用针孔模型建立投影关系,不用考虑畸变了。
最后,总结一下单目相机的成像过程:
- 世界坐标系下有一个固定的点P,世界坐标为P_W。
- 由于相机在运动,它的运动由R,t或变换矩阵T∈SE(3)描述。P的相机坐标为P?c=RP_W+t
- 这时的 P?c 的分量为 X,Y,Z,把它们投影到归一化平面 Z = 1 上,得到 P 的归一化坐标:Pc = [X/Z,Y /Z,1]T 。
- 有畸变时,根据畸变参数计算P_c发生畸变之后的坐标
- P的归一化坐标经过内参后,对应到它的像素坐标:P_uv=KP_c
双目相机模型
单目相机仅根据一个像素,我们无法确定这个空间点的具体位置。这是因为,从相机光心到归一化平面连线上的所有点,都可以投影至该像素上(相当于没有了Z轴维度)。只有当P的深度确定时(比如通过双目或 RGB-D 相机),我们才能确切地知道它的空间位置。如图所示。
测量像素距离(或深度)的方式有很多种,比如人眼可以根据左右眼看到的景物差异(视差)来判断物体离我们的距离。双目相机的原理一样:通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。
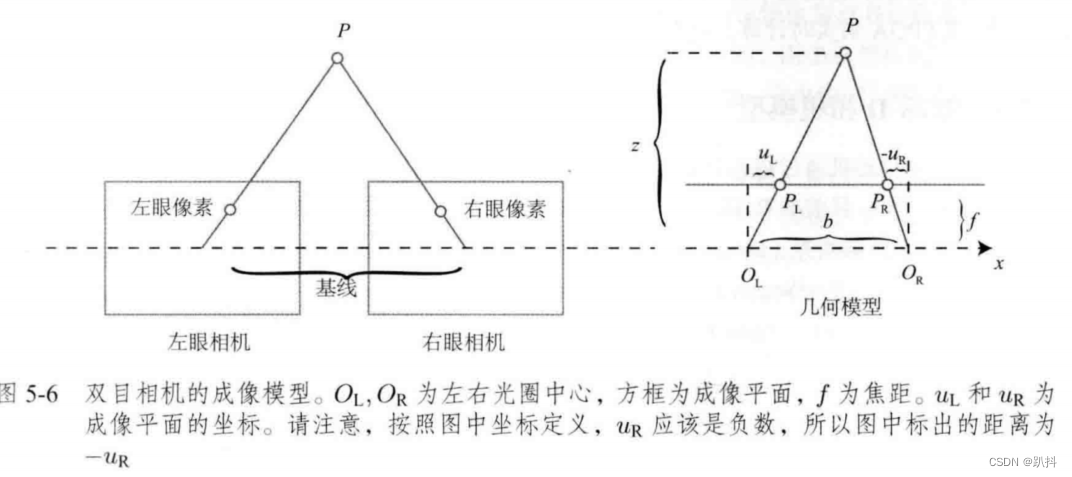
双目相机一般由左眼相机和右眼相机两个水平放置的相机组成。在左右双目相机中,我们可以把两个相机都看作针孔相机。它们是水平放置的,意味着两个相机的光圈中心都位于 x 轴上。两者之间的距离称为双目相机的基线(Baseline,记作 b),是双目相机的重要参数。
考虑一个空间点 P,它在左眼相机和右眼相机各成一像,记作 P_L,P_R。由于相机基线的存在,这两个成像位置是不同的。理想情况下,由于左右相机只在 x 轴上有位移,因此 P 的像也只在 x 轴(对应图像的u轴)上有差异。记它的左侧坐标为 u_L,右侧坐标为 u_R。根据 △PP_LP_R 和 △PO_LO_R 的相似关系,有:
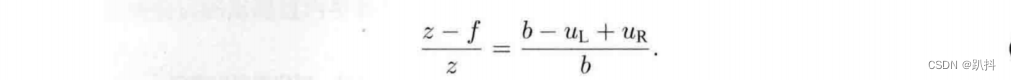
整理得:
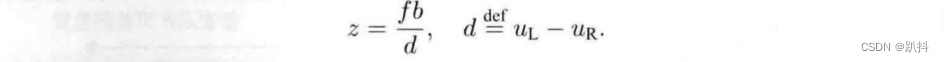
其中 d 定义为左右图的横坐标之差,称为视差。根据视差,我们可以估计一个像素与相机之间的距离。视差与距离成反比:视差越大,距离越近。同时,由于视差最小为一个像素,于是双目的深度存在一个理论上的最大值,由 fb 确定。可以看到,当基线越长时,双目能测到的最大距离就会越远。
视差 d 的计算比较困难,需要确切地知道左眼图像某个像素出现在右眼图像的哪一个位置(即对应关系)。当想计算每个像素的深度时,其计算量与精度都将成为问题,而且只有在图像纹理变化丰富的地方才能计算视差。由于计算量的原因,双目深度估计仍需要使用 GPU 或FPGA 来实时计算。
RGB_D相机模型
RGB-D 相机是主动测量每个像素的深度。目前的 RGB-D 相机按原理可分为两大类:
- 红外结构光(Structured Light)测量像素距离: Kinect 1 代、Project Tango 1 代、Intel RealSense 等。
- 飞行时间法(Time-of-flight,ToF)测量像素距离:Kinect 2 代和一些现有的 ToF 传感器等。
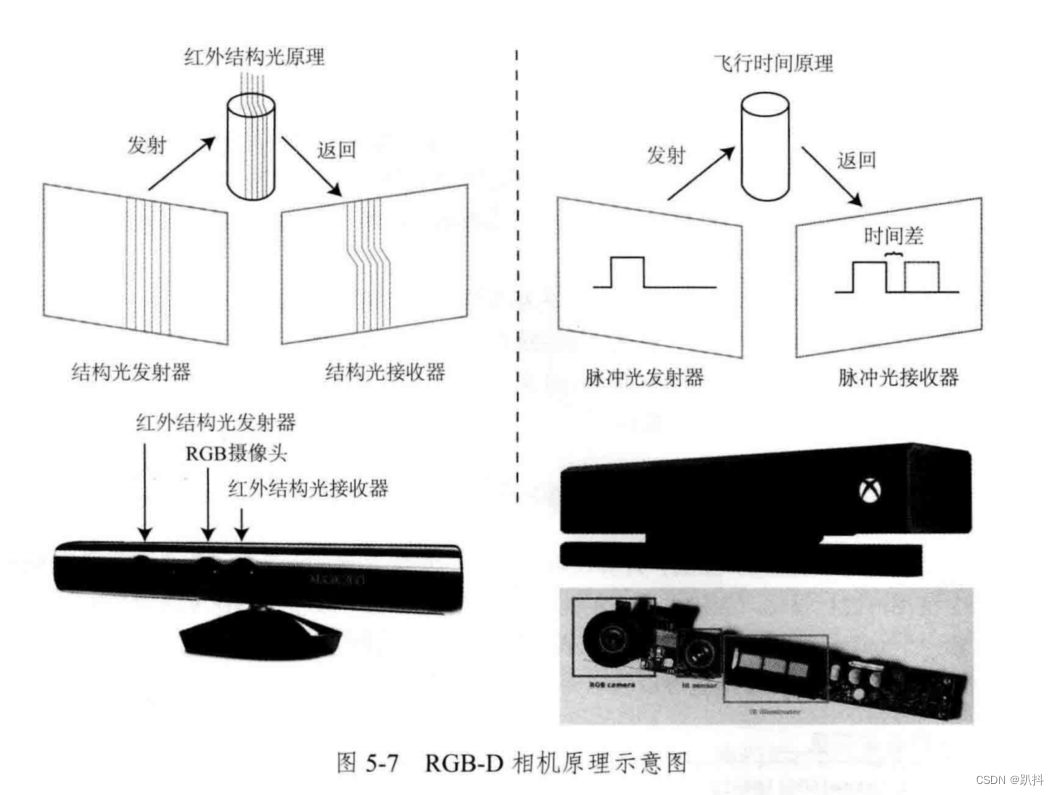
无论是哪种类型,RGB-D 相机都需要向探测目标发射一束光线(通常是红外光)。在红外结构光原理中,相机根据返回的结构光图案,计算物体与自身之间的距离。而在 ToF 原理中,相机向目标发射脉冲光,然后根据发送到返回之间的光束飞行时间,确定物体与自身之间的距离。ToF原理的相机和激光雷达十分相似,只不过激光雷达是通过逐点扫描来获取这个物体的距离,而ToF相机则可以获得整个图像的像素深度。
在测量深度之后,RGB-D 相机通常按照生产时的相机摆放位置,自己完成深度与彩色图像素之间的配对,输出一一对应的彩色图和深度图。可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云(Point Cloud)。对 RGB-D 数据,既可以在图像层面进行处理,也可在点云层面处理。
RGB-D 相机能够实时地测量每个像素点的距离。但用红外光进行深度值测量的 RGB-D 相机,容易受到日光或其他传感器发射的红外光干扰,因此不能在室外使用。在没有调制的情况下,同时使用多个 RGB-D 相机时也会相互干扰。对于透射材质的物体,因为接收不到反射光,所以无法测量这些点的位置。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 98 双指针求盛最多水的容器
- JFinal学生信息管理系统
- Spring Security 6.x 系列(15)—— Remember Me 自定义配置及源码分析
- [数据集][目标检测]白细胞检测数据集VOC+YOLO格式343张1类别
- 在自己的网站上添加在线客服功能指南:轻松实现实时沟通
- 极速整理文件!Python自动化办公新利器
- 网络编程套接字(Socket)
- Code automatic processing
- 如何在vscode当中预览html文件运行结果
- Arduino驱动重量传感器模块(重量传感器)