map和set
前言
map和set学了以后会非常舒服,我们今天重点讲它的使用。
map和set是什么
首先map和set是什么?
它的底层是搜索二叉树
我们依次先来学一下,set和map
注意它的底层是平衡搜索二叉树,但是我们现在就先把它看作
搜索二叉树
set

我们只需要看第一个参数,其他给了缺省参数都不用管。
那它为什么要给compare这个仿函数呢?
它可以支持你改变key的比较方式,但是一般情况不需要你给,一般用默认的
set的使用
set用起来很简单,它没有任何含量,就跟我们以前学的容器是一样的。
其实set就是我们之前搜索二叉树讲的key模型
mep就是我们讲的key/value模型
搜索我们要讲的就是解决这两个模型
它的结果是什么,无非走的是迭代器,我们看一下它的迭代器。
它的迭代器是一个双向迭代器


这其实没有什么好讲的,它的用法也是跟之前的容器一样。
但它们的底层是不一样的,我们后面的文章会讲。

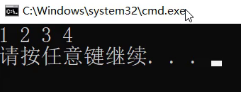
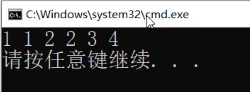
为什么这里是1234?
因为上面的一些值插入失败了,不允许冗余。
比它小往左走,比它大往右走,已经相等的值就不进了。
这块的数据结构就没右push的概念,只有线性表才是push.
C++把容器归纳成两类:
一类是序列式容器,
一类是关联式容器

序列式容器就是它的数据是挨着挨着存储的,
关联式容器就是它的数据和数据之间有非常强的关联关系。
范围for:
它只要支持迭代器就支持范围for

能不能支不支持修改?
比如每个值+=1

不可以,我们之前学了搜索树,搜索树是不能随便修改的,
或者至少不允许修改key.
搜索二叉树被修改它的结构就可能被破坏,已经不是搜索二叉树了
比如8这个位置+=10变成18,就不是搜索二叉树了。

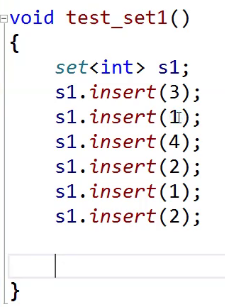
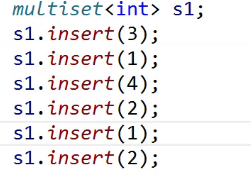
void test_set1()
{
set<int> s1;
s1.insert(3);
s1.insert(1);
s1.insert(4);
s1.insert(2);
s1.insert(1);
s1.insert(2);
set<int>::iterator it1 = s1.begin();
while (it1 != s1.end())
{
// 搜索树不允许修改key,可能会破坏搜索的规则
//*it1 += 1;
cout << *it1 << " ";
++it1;
}
cout << endl;
// 范围for
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test_set1();
return 0;
}
我们再来看一下其他的使用,其他的使用其实不学都已经会了,
这就是STL设计的优势,你会用一个容器用其他容器就能轻松搞定。
erase
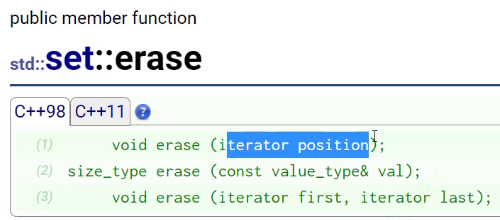
erase支持一个位置的删除,这个位置可以借助find,确定在不在
find
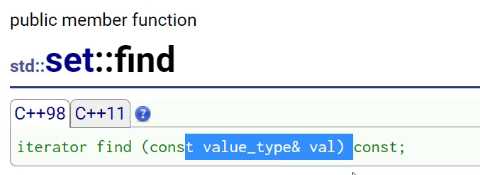
swap

set的交换,底层是两颗树,这两颗树交换头节点的指针肯定是最快的。
这里有一个比较有用的就是count,就是给个值判断这个值在不在

我们自己要判断这个值在不在可以这样:


接下来用count
count会返回它的个数
count会简化一些

虽然count让这个在不在的场景更简单了,但是好像还是有点鸡肋
这个等下我们再来看。
set完成的功能是否仅仅是排序这么简单?
set的功能严格来说是排序加去重。
如果以后要完成去重的功能也是可以用set
有些场景可能我不想做排序,或者不想做排序这么简单的功能
所以出了set还有一个multiset
它和set的最大区别就是允许建值冗余

它的操作和set也是一样的,允许建值冗余也就导致下面的问题
它不是去重,它是排序
但它还是判断在不在的问题,set的主功能还是判断在不在的模型
允许建值冗余是怎么做到的呢?
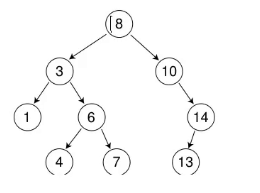
比如这颗树要再插入14
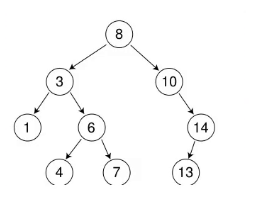
以前是比它大往右走,比它小往左走,相等就不插入。
现在再插入14是怎么样呢?就插入就可以了,插在14的左边和右边都可以
为什么插入在右边都可以?
因为以后学了平衡树知道它会旋转,就算 插入在左边,
左边如果太长它会右旋,右边多了它会左旋。
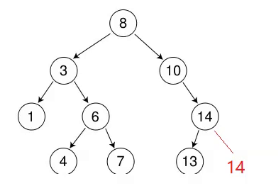
其他功能multiset和set是一样的,find是比较值得看一下的。
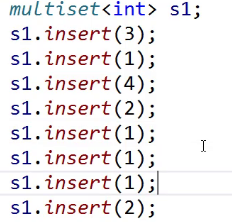
这里面有多个1,这里find找的是哪个1呢?
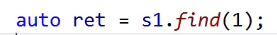
多个key,找中序的第一个,这是规定
验证一下:
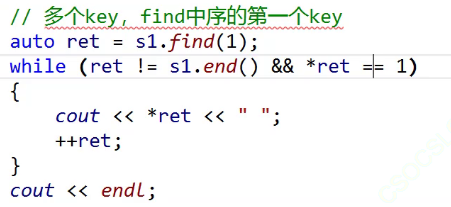

这里的count的价值就很大,它能反馈key的个数


set也就这样,以现在的水准,自己看一下文档也就会了。
平时其实很少使用mltiset,因为mltiset不那么好用,
判断在不在,有多少个,这个场景实际并不那么需要。
map
map介绍
map有什么用?
通过一个值就可以找另外一个值我们就可以用map,
经典的场景就是字典,我们中文找英文,英文找中文。
还有统计次数。
map非常非常重要。
学习map之前得先来认识一个结构。这个结构叫做pair

map是key和value的结构,它既要存一个value也要存一个key,
它是key/value的搜索树。但它里面的数据不是存key和value,
它是存value的变量。
pair是库里面自己定义的结构。
pair的结构大致是什么样子,我们看一下。
pair在STL大致就是这样子定义的
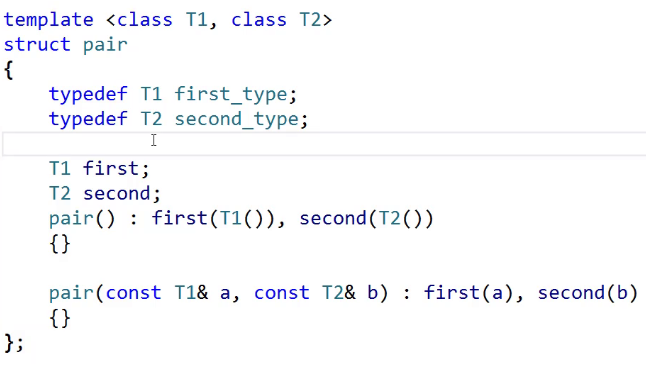
这里面有两个值,一个是first,一个是second,
一般情况下,first就是key, second就是value
还有一个构造函数。
map的使用
这里的inser和set的区别是,这里有三个版本。
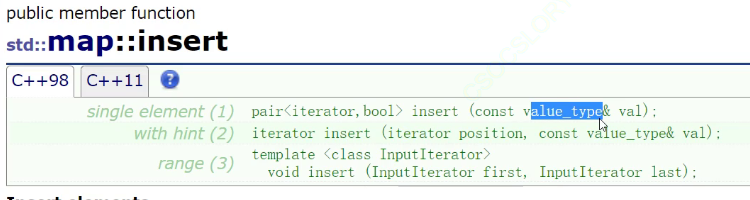
但是第二个和第三个实践当中用的非常非常少。
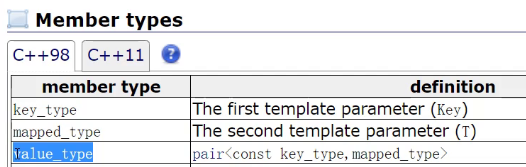
看参数,不允许修改key,但是允许修改value
不然统计次数就没办法实现了。
我们先来写代码看一下。
但是编不过,能不能结合这个报错看一下原因

如果容器是set的话,底层是树,跟链表应该一样,迭代器里面应该是结点,这里面结点的值是key.
但这里面结点的值应该是key和value,C++不支持同时两个值
只返回一个值,但里面却有两个值,key/value怎么办?
就返回一个结构,这个结构官方定义为pair
pair在这不支持流插入
所以这样就可以支持了
cout << (*dit).first << ":" << (*dit).second;
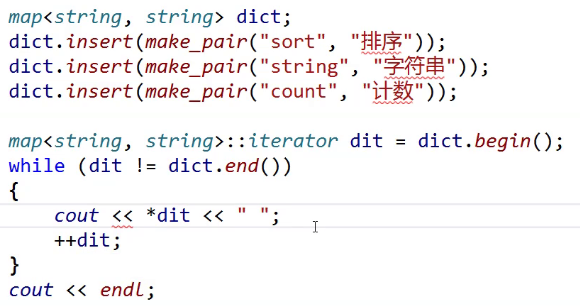
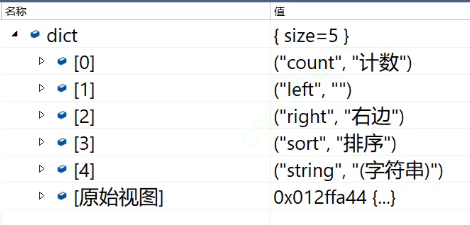
map<string, string> dict;
//dict.insert(pair<string, string>("sort", "排序"));//构造pair的匿名对象去进行插入
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("count", "计数"));
//map<string, string>::iterator dit = dict.begin();
auto dit = dict.begin();
while (dit != dict.end())
{
cout << (*dit).first << ":" << (*dit).second << endl;
++dit;
}
cout << endl;
再插入的时候我们喜欢用make_pair,make_pair是一个函数模板。

其实还是去调用匿名构造再返回。
这个make_pair还是会返回inline.
这两个写法有什么差异呢?
如果直接去写这个构造,得显示的去写这两个参数。如果这两个参数略长,写起来就略长。
make_pair的好处是可以通过传参自动推导类型,就不需要显示去自动声明类型了。
我们也更喜欢这样写。
cout << dit->first << ":" << (*dit).second << endl;
当你里面的数据是结构体里面的时候,并且是结构体的指针就喜欢用->
上面其实省略了一个->
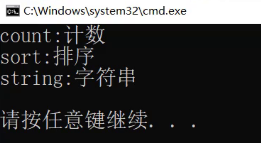
接下来看,150行插入以后会修改还是怎样。

插入失败,按照我们之前搜索树学的,value并不会参与插入规则,
value相不相同它都不管,它只管这个key
所以string插入的时候这个key已经有了,它就插入失败。
erase
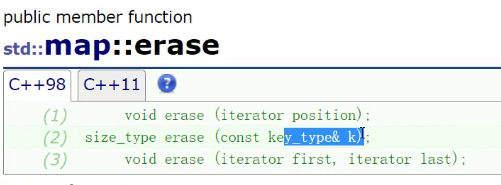
erase跟迭代器位置也是一样的,可以给个迭代器位置也可以给个key.
都是find+erase
现在我们做一件事情,统计水果出现的次数
统计次数怎么统计,还是一样,就看它在不在。
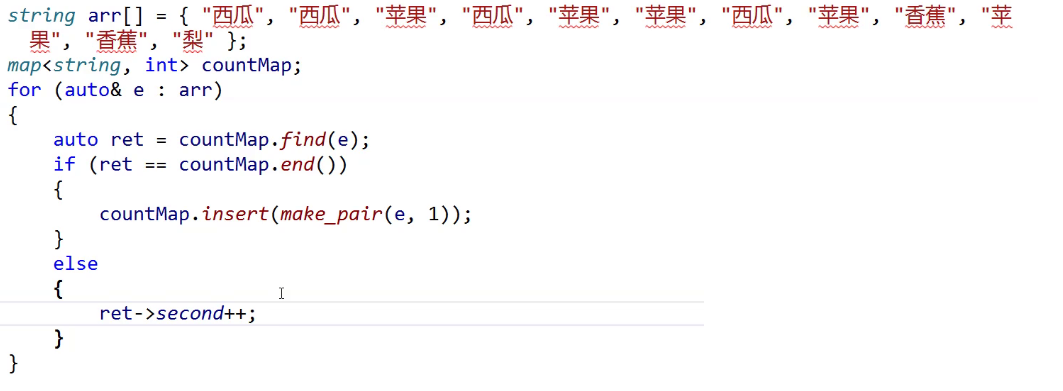
范围for验证一下
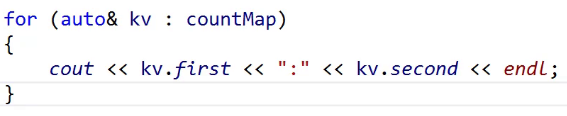
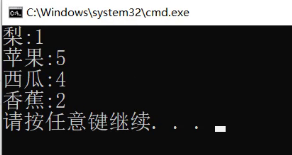
这里有一个比较特殊,值得仔细去看一下的即使【】

以前只有deque和vector才有【】
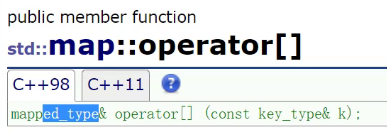
mapped_type就是第二个模板参数,第二个模板参数就是value
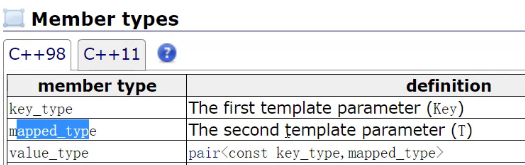
也就是意味着上面统计水果次数的代码可以这样写。
一行代码就可以统计出这里的次数。

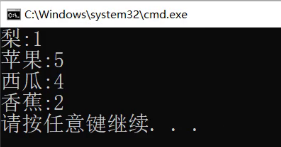
map最值得我们深入学习的就是这里的【】
operate【】是如何实现一行代码就统计出次数的呢?
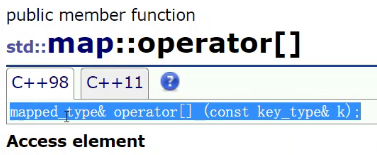
简化一下,相当于下面的代码
文档里面的,源码里应该可以简化一下

这层代码有一层insert,我们先把insert给理解清楚,再来拆解,才能尝试看懂
这里涉及一个insert的返回值的问题,这个insert的返回值不是单纯的insert的返回值的问题。

insert按照我们之前搜索二叉树的理解,插入成功是true,插入失败是false
现在是map,不允许建值冗余,如果这个key已经有了就不允许插入了。
insert返回值的描述

可以看上面的英文了解一下。
如果插入的值已经有了,它会返回跟key相等的那个结点的迭代器
如果新插入成功,他会返回新插入的那个结点的迭代器。
bool就是展示插入成功还是失败。
接着拆解一下上面的代码

这一坨就是调用insert函数,它的返回值就是pair.
pair.first就是迭代器,迭代器再解引用就是pair数据,pair再去取second就是value
返回value的引用就可以修改这个value,
看,现在就把所有连起来了。
不过上面的代码写的太挫了,现在把它改造一下。
下面这段代码本质跟上面是一样的。

这里插入有两种可能
第一种可能成功:
这里又分两种,key插入成功,key还没有
value给的次数是多少?value是int,int的类型生成的匿名对象是0
最后返回value次数的引用,来进行修改
第二种失败:
【】有这几个功能

这些后面我们会模拟实现,其实很简单。
我们更喜欢下面这样写代码。

map学了以后,很多题多会很简单
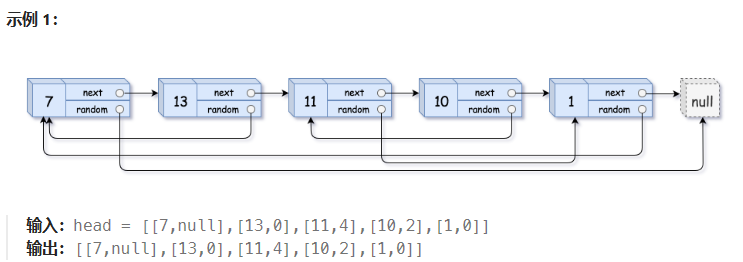
随机链表的复制
题目

分析
就尾插一个链表,对原链表进行复制

那怎么控制这个rondom呢?
我们之前的问题就是原结点和拷贝结点完全没有什么关系。
现在怎么办?
有没有办法建立一个链接来控制rondom,不用之前的方式。
我们让原结点和拷贝结点建立一个key/value关系
比如13的rondom指向7这个结点,map里面7结点的value就是下面的拷贝结点,就找到我的了。
就很轻松解决了。
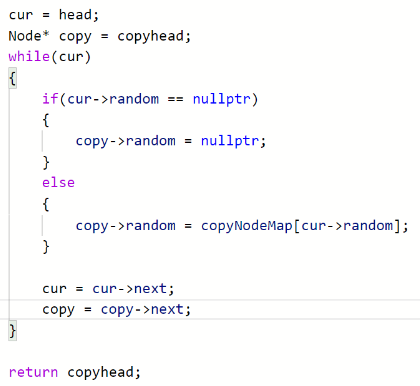
写代码

这里就懒得带哨兵卫了。
我们先复制一个链表出来。

下一步,把rondom控制一下就可以了。
每个结点和原结点都要建立映射关系
怎么建立呢?很简单

怎么控制呢?
要遍历原链表,遍历这个链表,再从头开始。
map是一个key/value型的数据结构,它的底层数据存储已经是一个pair
multimap
multimap还是跟之前一样,允许建值冗余。
演示一下


如果value相同,能不能插入呢?


可以。
搜索树根本就不在乎value,value对我们很重要,
但是对树一点也不重要,它只是顺便存在对应的结点。
它在树里面主要以key进行比较建立规则的,顺便存了个value,
也就意味着找到key就找到value.
multimap和map最核心的区别还有什么?
它没有【】,
以前key和value是一对一的关系,现在key和value是一对多的关系。
【】最核心的功能是查找对应的value,找到以后可以读这个值,还可以写。
我们不知道要修改的是哪一个对应的value.
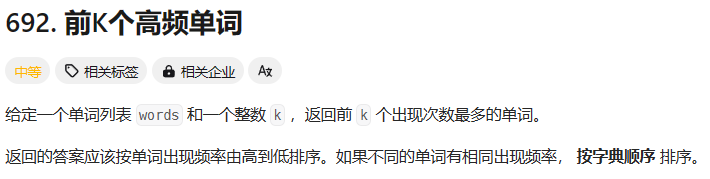
前K个高频单词
题目

分析
这相当于统计次数加Topk问题
但这道题的Topk有一点点问题

这是这道题的特殊点,稍不注意就会被坑。
也就是说两个不同的单词,出现次数相同,就按字典顺序排序。
写代码
我们先不管其他所有东西,把统计次数写出来

下一步我们要搞Topk,怎么搞呢?
map也是排序的,但是它是按单词去排序的,不是按统计次数去排序的。
现在按统计次数去排一下序。
优先级队列是一种解决方案之一
这里先不用优先级队列,
我们知道Top k数据量不大的时候,其实用堆用排序都很简单。
这里本质考察的是排序的稳定性。


map顺次去遍历的时候,这个i和love都是两次,i一定在love的前面
因为map本身是按key去排序的,按这里的string去排序的。
map已经排好了,次数相同的在前面。
如果用一个稳定的排序一定能保证i一定在love的前面
这个时候就能达到我的目的
排序的解决方式
排序能不能对map进行sort,我们现在排序按这个次数来排。
能不能作用到countMap的迭代器上?
我们之前讲过,sort的底层是快排,必须要求你的迭代器是一个随机迭代器。
map是一个双向迭代器。
只有一种方式,把它放到vector里面,再来sort.
sort这个排序稳定不稳定?
不稳定,因为sort的底层是快排,选这个key,这个key可能在中间。
那就可能相等的在左边,不相等的在右边。这个时候稳定性,就已经破坏了。
这里可以验证一下。

这里vector可以优化一下。

我们要用map去初始化vector,我们的数据解引用之后都是一个pair
我们这里就可以直接用它的迭代器区间去初始化。

topk如果数据量不大直接用sort是完全没有问题的。
但是这里sort出来还不是我想要的结果,它是按照pair去比的。
看一下pair能不能支持比较大小。
可以,但是它的比较方式比较奇葩。

看这个小于,first和second有一个小,它就小了。
这不是我们希望的比较方式,我们希望的是按照second去比。

反正这里的比较方式肯定是不符合我们的预期的,
我们能不能想办法搞成符合我们预期的比较稳定的方式
有没有什么办法?
我们先不管这些,写个仿函数。
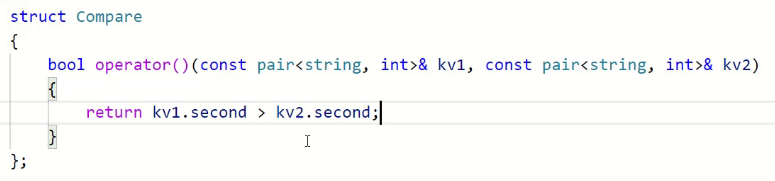
接着把sort的仿函数给进去,直接生成一个匿名对象传过去就可以了

我们想要大的在前面
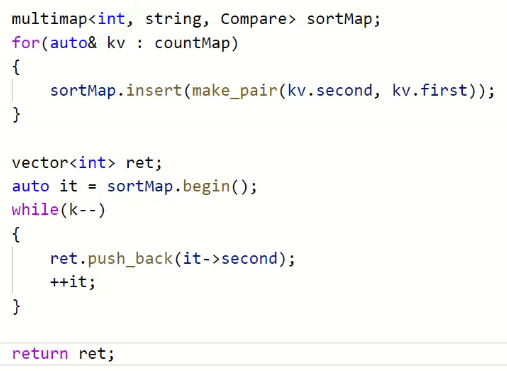
我们取它的前k个
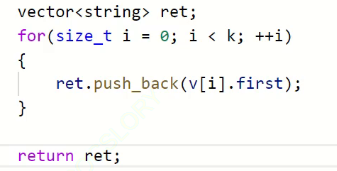
然后提交
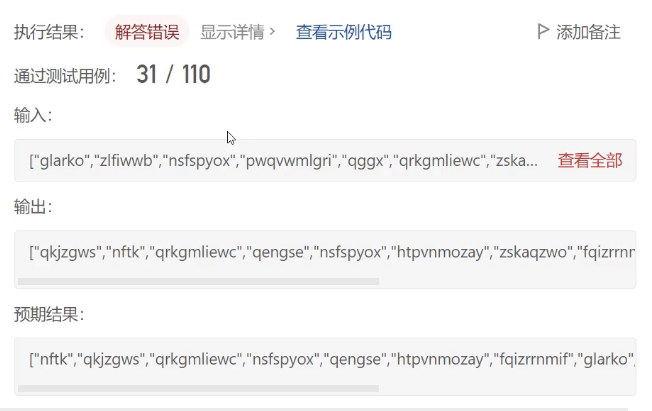
这里有些测试用例过不了的原因就是稳定性的问题。
从预期结果和实际结果是相反的就可以看出来
可以打印出来看一下
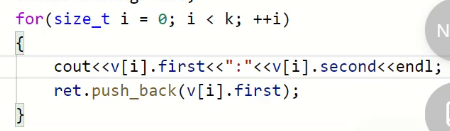
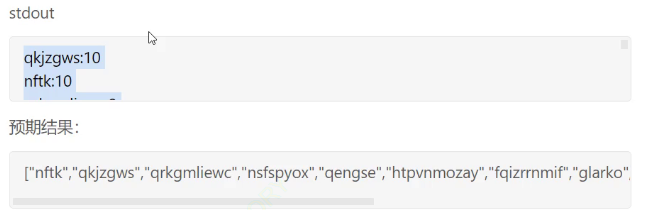
看上面的例子,在原来的vector里面“nftk”肯定在“qkjzgws”的前面,在排序之前
因为前面的map已经排过了,value都是10,
nftk肯定在前面在左边,搜索树中序出来肯定先走n再走q,
但是这里由于sort不稳定就导致了一系列的问题。
这就是经典的排序稳定性的问题
怎么解决?
归并是稳定的,但是要自己写一个。
再按字典去排一次,这种方案可以是可以

不能在这个地方,对ret这个vector再排一次,因为你的次数会受影响。
这里有两种方案可以解决:
1.找一个稳定的排序
C++的算法库里提供了一个稳定的排序

stable_sort的底层是一个什么排序,感兴趣的老铁可以去查一下
怎么实现的,怎么达到稳定的。
还有一种方式也可以解决,我们就用sort,
sort不稳定归不稳定,但是我们在这里比较的时候可以想办法控制一下的。
因为给了仿函数,仿函数就可以控制这块东西。
不是让sort稳定了,而是控制比较逻辑。
按我们以前的排序,大的肯定在前面
次数相等我们按照字典序小的在前面,也就是first小的在前面

过了
这道题不写仿函数能搞定吗?
肯定搞不定,因为给的数据是pair,不写仿函数就按照pair默认的方式去比较。
pair默认的比较方式不符合我的需求。
这道题也可以用堆,但是用堆也要控制仿函数,否则会被坑。
这道题数据量不多用map去解更好一点点。
这道题不放到另外一个vector里完成这个sort有什么方案?
map本身就能帮助我们排序,之前我们是按照key排的,现在我们要按次数去排。
但这里不能用map来做排序,我们之前说过map是排序加去重。
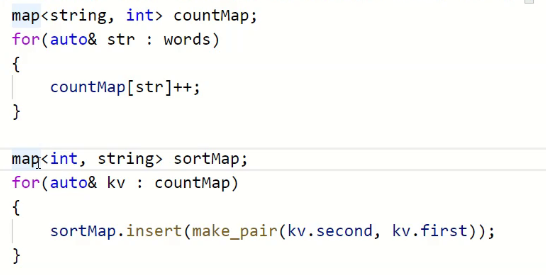
所以我们这里用multimap刚刚好。
但是我们这里用multimap也会有其他的问题。
比如key是相等的,如何保证它们value的顺序的。就比入前面的都是10次的两个。
保证不了。
这里再教大家一招
map和multimap都有一个特点,可以传仿函数去控制比较逻辑。
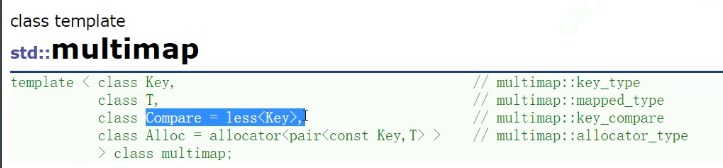
默认是用小于去控制,小的在左边大的在右边,比它大的就往右边走。
我们想要大的在左边,依次是从大到小。如果次数相同想按first去比。
这里不一样的是这是类型,因为这是类模板参数,之前的是对象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android Studio解决:Connect time out问题
- 云计算:OpenStack 分布式架构部署(单控制节点与单计算节点)
- 机器学习之K近邻(KNN)
- Java---- 静态内部类与非静态内部类的区别
- RT-Thread 线程间通信 信号
- 项目管理十大知识领域之项目干系人管理
- java体现反射的简单示例
- 回归预测 | Matlab实现SSA-BP麻雀算法优化BP神经网络多变量回归预测
- AssertionError: The environment must specify an action space. 报错 引发的惨案
- 大话前端:WebAssembly的未来与前端开发