基于YOLOv5+单目的物体距离和尺寸测量
目录
1,YOLOv5原理介绍

YOLOv5是目前应用广泛的目标检测算法之一,其主要结构分为两个部分:骨干网络和检测头。
骨干网络采用的是CSPDarknet53,这是一种基于Darknet框架的改进版卷积神经网络。CSPDarknet53通过使用残差结构和跨层连接来提高网络的表达能力,并且采用了空洞空间金字塔池化(ASPP)来实现多尺度的信息提取。这样设计的骨干网络具有较强的特征提取能力,可以有效地提取出图像中的目标信息。
检测头是YOLOv5的另一个关键组成部分,主要用于从骨干网络特征图中提取目标检测信息。它由三个子模块组成:SPP、PAN和YOLOv5输出层。
SPP模块:空洞空间金字塔池化模块,用于对特征图进行多尺度的池化和下采样操作,从而实现对不同大小的目标进行检测。
PAN模块:特征金字塔自上而下的路径,用于将不同层次的特征图融合在一起,并进行上采样操作,以便将低分辨率的特征图与高分辨率的特征图进行融合。
YOLOv5输出层:用于在特征图上进行目标检测,输出目标的类别、边界框位置和置信度等信息。其中,YOLOv5输出层采用特定的损失函数(GIoU和Focal Loss)来优化目标检测的精度和鲁棒性。
总体来说,YOLOv5的主要作用是实现对图像中的目标进行快速、准确的检测。与传统的目标检测算法相比,YOLOv5具有以下优点:
高速:YOLOv5采用了高效的网络结构和检测头,可以实现高速的目标检测。
精度:YOLOv5使用特定的损失函数和多尺度特征提取等技术,可以实现高精度的目标检测。
通用性:YOLOv5能够在不同的场景下进行目标检测,具有较强的通用性和适应性。
易用性:YOLOv5可以通过预训练模型和微调等方法进行快速部署和使用,具有良好的易用性和可扩展性。
?
2,单目测尺寸以及距离原理
2.1单目测物体距离
单目相机测距常用或者说实用的方法就是相似三角形法,为了让大家更好地理解程序,这里简单说一下相似三角形法。
相似三角形:假设我们有一个宽度为 W 的目标或者物体。然后我们将这个目标放在距离我们的相机为 D 的位置。我们用相机对物体进行拍照并且测量物体的像素宽度 P 。这样我们就得出了相机焦距的公式:
F = (P x D) / W
举个例子,假设我在离相机距离 D = 24 英寸的地方放一张标准的 8.5 x 11 英寸的 A4 纸(横着放;W = 11)并且拍下一张照片。我测量出照片中 A4 纸的像素宽度为 P = 249 像素。
因此我的焦距 F 是:
F = (248px x 24in) / 11in = 543.45
当我继续将我的相机移动靠近或者离远物体或者目标时,我可以用相似三角形来计算出物体离相机的距离:
D’ = (W x F) / P
为了更具体,我们再举个例子,假设我将相机移到距离目标 3 英尺(或者说 36 英寸)的地方并且拍下上述的 A4 纸。通过自动的图形处理我可以获得图片中 A4 纸的像素距离为 170 像素。将这个代入公式得:
D’ = (11in x 543.45) / 170 = 35 英寸
或者约 36 英寸,合 3 英尺。
从以上的解释中,我们可以看到,要想得到距离,我们就要知道摄像头的焦距和目标物体的尺寸大小,这两个已知条件根据公式:
D’ = (W x F) / P
得出目标到摄像机的距离D,其中P是指像素距离,W是A4纸的宽度,F是摄像机焦距。
?
2.2单目测物体尺寸
上述原理反推则可测物体尺寸,这里就不再赘述。
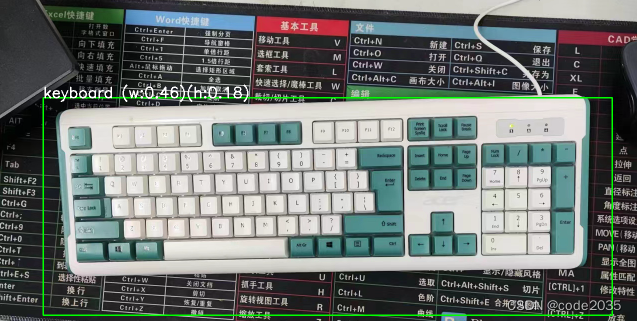
3,成果展示
3.3测距离

3.2测尺寸:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 008-关于FPGA/ZYNQ直接处理图像传感器数据输出的若干笔记(裸板采集思路)
- 【昕宝爸爸小模块】图文源码详解什么是线程池、线程池的底层到底是如何实现的
- 【Unity】Attribute meta-data#com.google.android.play.billingclient.version 多版本库冲突
- Python第四章(字符串)
- MySQL_14.数据库高速缓冲区空间管理
- AtCoder ABC周赛2023 12/10 (Sun) D题题解
- Vmware安装windowsServer2022版本
- 使用docker-compose管理docker服务
- odoo16 产品变体之体验
- Mybatis-plus动态表名配置