MySQL 索引优化:深入探索自适应哈希索引的奥秘
在数据库管理系统中,索引优化是提高查询性能的关键所在。MySQL 作为最流行的开源关系型数据库管理系统之一,提供了多种索引类型以满足不同查询场景的需求。其中,自适应哈希索引(Adaptive Hash Index,AHI)是 InnoDB 存储引擎提供的一种高级索引优化技术,它能够在特定情况下显著提升查询性能。本文将深入探讨自适应哈希索引的工作原理、使用场景以及如何充分利用它进行性能优化。
在 MySQL 中,索引是用来加速数据检索速度的一种数据结构。通常我们最熟悉的是 B-tree 索引,但 MySQL 的 InnoDB 存储引擎还提供了其他类型的索引,包括哈希索引和自适应哈希索引。
一、什么是自适应hash索引
先来回顾下什么是hash索引
哈希索引(Hash Index):
哈希索引基于哈希表实现,它将索引键值通过哈希函数转换为一个位置,然后在该位置存储相应的数据或数据指针。由于哈希索引可以几乎在 O(1) 时间复杂度内完成查找操作,因此在某些场景下它比 B-tree 索引更快。
然而,哈希索引有几个显著的缺点:
- 它不支持范围查询,因为哈希索引不存储数据的物理顺序信息。
- 哈希索引不支持部分键匹配查询和排序操作。
- 当哈希冲突较多时,性能会下降。
- 哈希索引的构建和维护通常需要额外的内存开销。
在 MySQL 中,InnoDB 存储引擎并不直接支持用户创建的哈希索引。但是,InnoDB 使用哈希索引作为其内部数据结构的一部分,例如用于加速某些类型的查找。
自适应哈希索引(Adaptive Hash Index,AHI):
自适应哈希索引是 InnoDB 存储引擎特有的一个功能,它是为了优化某些热点数据的查询性能而自动构建的。自适应哈希索引不同于传统的哈希索引,因为它是自动和动态的:InnoDB 会根据查询模式和数据访问频率自动决定是否构建哈希索引,并且会根据数据的变化和查询模式的变化动态地调整哈希索引。
自适应哈希索引的工作原理是,当 InnoDB 注意到某些索引值被频繁地以等值查询的方式访问时,它会在内存中为这些值建立哈希索引,从而加速后续的等值查询。这个过程是自动的,不需要用户干预。
自适应哈希索引的优点包括:
- 自动优化:自适应哈希索引会自动构建和维护,不需要用户显式创建或管理。
- 性能提升:对于某些等值查询,自适应哈希索引可以显著减少查找时间,哈希索引,查询消耗 O(1)
- 降低对二级索引树的频繁访问资源。
然而,自适应哈希索引也有一些限制和考虑因素:
- 内存消耗: 自适应哈希索引完全在内存中构建,因此需要足够的内存资源。在高负载下,它可能会消耗大量的内存。
- 不可预测性:由于是基于运行时查询模式的,所以哈希索引的存在和组成是不可预测的。
- 不适用于所有查询:自适应哈希索引主要优化等值查询,对于范围查询或排序操作没有帮助。
- hash自适应索引会占用innodb buffer pool;
总的来说,自适应哈希索引是 InnoDB 存储引擎为了提高特定类型查询性能而自动构建的一种内存中的哈希索引结构。它可以根据查询模式和数据访问频率自动调整,以优化数据库的性能。
二、自适应哈希索引的工作原理
自适应哈希索引是 InnoDB 存储引擎内部实现的一种特殊索引结构,它是基于内存中的哈希表构建的。与传统的 B-tree 索引不同,哈希索引使用哈希函数将索引键值映射到哈希表中,从而实现了 O(1) 时间复杂度的快速查找。这意味着在等值查询场景下,自适应哈希索引能够提供比 B-tree 索引更快的查找速度。
自适应散列索引(AHI)使InnoDB在系统上执行更像内存数据库,该功能由innodb_adaptive_hash_index 配置启用。
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,innodb就会使用索引键的前缀建立一个哈希索引。将索引值转换为一种指针,便于直接访问,带来速度的提升。
经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
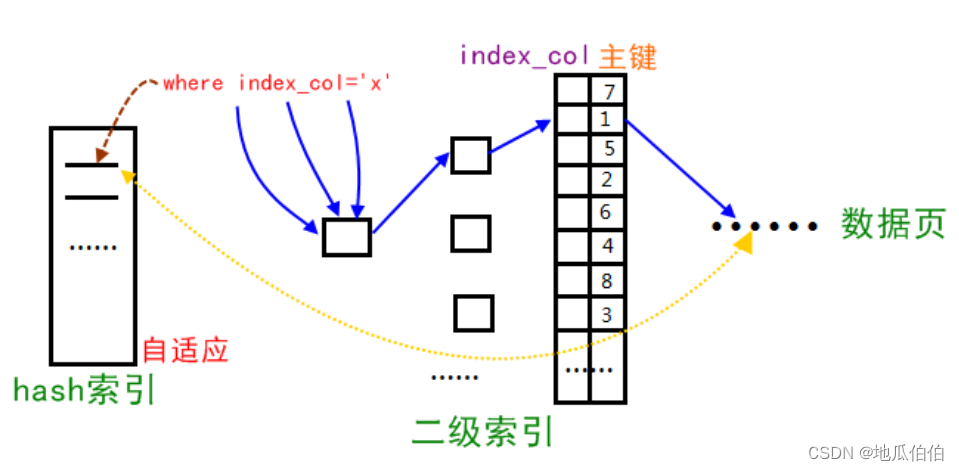
然而,哈希索引并不适用于所有查询场景。由于哈希索引不存储数据的物理顺序信息,因此它无法支持范围查询和排序操作。
此外,哈希索引的构建和维护需要额外的内存开销。为了平衡性能和资源消耗,InnoDB 存储引擎会根据查询模式和数据访问频率动态地构建和维护自适应哈希索引。
三、自适应哈希索引的使用场景
自适应哈希索引主要适用于以下场景:
-
等值查询频繁: 如果某个列的值经常被用作等值查询的条件,并且查询频率较高,那么 InnoDB 存储引擎可能会为该列的值构建自适应哈希索引。
-
热点数据访问: 对于经常被访问的热点数据,自适应哈希索引能够提供更快的查找速度,从而提高查询性能。
-
内存资源充足: 由于自适应哈希索引是基于内存构建的,因此需要足够的内存资源来支持其构建和维护。在内存资源充足的情况下,启用自适应哈希索引可以获得更好的性能提升。
在 InnoDB 存储引擎中,自适应哈希索引(Adaptive Hash Index, AHI)是一种为了提高某些查询性能而自动构建的内存中的哈希索引。但是,InnoDB 不会为每一个可能的索引值都构建哈希索引,而是基于一定的条件和阈值来决定是否构建。
以下这些条件,实际上是 InnoDB 内部用来决定是否为一个特定的索引值构建自适应哈希索引的启发式规则的一部分。可能会随着 MySQL 版本的不同而有所变化,且它们是基于 InnoDB 开发者的经验和性能测试来设定的。
-
索引使用次数: 当一个特定的索引值被查询多次时,InnoDB 会认为这个值是一个“热点”数据,值得为其构建哈希索引。通常,这个次数会有一个阈值,例如17次。如果一个索引值在连续的查询中被访问的次数超过了这个阈值,InnoDB 就可能会考虑为其构建自适应哈希索引。
-
hash info使用次数: 这个条件可能涉及到自适应哈希索引内部数据结构的维护和使用情况。当一个索引值被加入到哈希索引中后,其相关的“hash info”结构会被更新以反映这个索引值的使用情况。如果这个“hash info”结构被多次使用(例如,在多次查询中被访问),那么这个索引值就可能被认为是“热点”数据,并且其哈希索引会被保留。
需要注意的是,这些条件和阈值是基于 InnoDB 内部实现和性能考虑的,它们可能会随着 MySQL 版本的变化而调整。此外,InnoDB 还可能会考虑其他因素,如内存使用情况、系统负载等,来动态地构建和维护自适应哈希索引。
最后,这些条件和阈值通常对用户是透明的,因为自适应哈希索引的构建和维护是由 InnoDB 自动完成的。用户可以通过 SHOW ENGINE INNODB STATUS 命令来查看自适应哈希索引的使用情况,但通常不需要直接干预其构建和维护过程。
四、如何充分利用自适应哈希索引进行性能优化
要充分利用自适应哈希索引进行性能优化,可以从以下几个方面入手:
- 监控自适应哈希索引的使用情况:
通过执行 SHOW ENGINE INNODB STATUS 命令,可以查看自适应哈希索引的使用情况,包括索引的大小、构建速度以及查询性能等。这些信息可以帮助你了解自适应哈希索引在实际应用中的效果,并根据需要进行调整。
在输出的SEMAPHORES部分中
mysql> show engine innodb status\G
……
Hash table size 34673, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
字节为单位,占用内存空间总量,通过hash searches、non-hash searches计算自适应hash索引带来的收益以及付出,确定是否开启自适应hash索引
- 优化查询语句:
合理地设计查询语句,避免不必要的全表扫描和复杂的连接操作,可以减少对自适应哈希索引的依赖,从而提高查询性能。此外,使用索引覆盖扫描(Index Covering Scan)等技术可以进一步减少数据访问量,提升查询效率。
- 调整内存配置:
根据系统的实际情况和查询需求,合理调整 InnoDB 存储引擎的内存配置参数,如 innodb_buffer_pool_size 和 innodb_adaptive_hash_index_partitions 等。这些参数的设置将直接影响自适应哈希索引的构建和维护效果。
- 定期维护数据库:
定期对数据库进行维护操作,如优化表(OPTIMIZE TABLE)、重建索引(REBUILD INDEX)等,可以保持数据库的良好状态,提高自适应哈希索引的使用效果。
总之,自适应哈希索引是 MySQL加粗样式 中一种高效的索引优化技术,它能够在特定场景下显著提升查询性能。通过深入了解其工作原理和使用场景,并采取相应的优化措施,我们可以充分利用自适应哈希索引的优势,为数据库应用带来更好的性能体验。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- macos pip3 install pycryptodome导入from Crypto.Cipher import AES报错
- 2023 Gartner? 云数据库管理系统魔力象限发布 PingCAP 入选“荣誉提及”
- 最大输出 18W,集成 Type-C PD 输出和各种快充输出协议
- 基于萤火虫算法优化BP神经网络回归分析,基于GSO-BP的回归预测
- 【分布式技术】rsync远程同步服务
- WSL2Linux 子系统(七)
- nvidia docker安装
- ES的安装和RestClient的操作
- 【wrf-python】批量读取多个nc文件中共同的变量并保存为csv文件
- 云服务器ECS搭建个人项目