大数据从入门到精通(超详细版)之Hive的DML操作,通俗易懂,包看包会!!!
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
上一篇文章我们已经学习了Hive的DDL操作,了解到了Hive的建表语句与实际操作,接下来我们学习得深入一点,我们来学习Hive的DML操作,学习如何操作Hive当中的数据。

Hive的DML数据操作
明确学习目标
我们学习Hive的DML语句之前,我们需要先明确Hive的DML语句的使用场景:
- Hive的数据多是用于大数据场景下进行分析计算的,而不是用于存储数据的,请大家首先明确这一点。
- 真实开发环境当中的Hive中的数据一般是海量的,很少进行更新和删除的操作,因为不实用且耗费性能。
Load操作
说明
将文件数据导入到Hive的表当中。
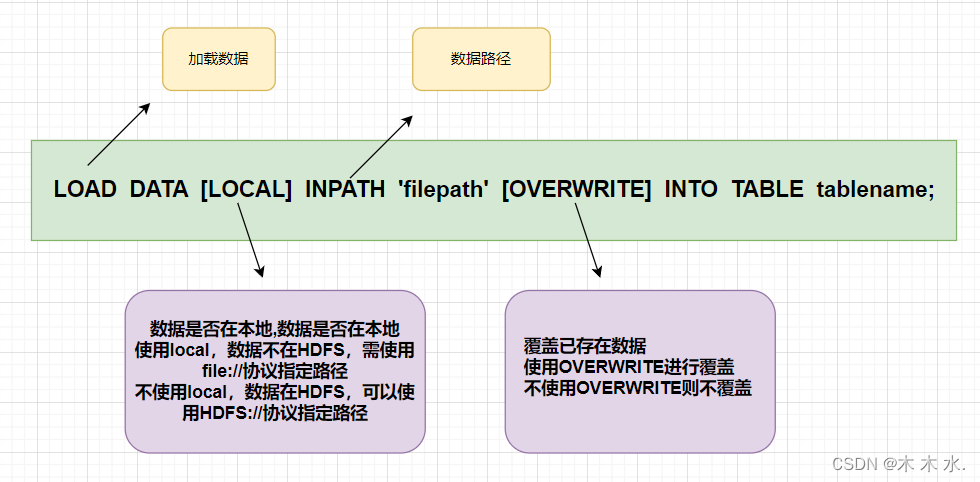
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)];
关键字说明:
-
local:表示从本地加载数据到Hive表;否则从HDFS加载数据到Hive表。注意,这里的
本地,存在两种不同的情况:一种是使用shell界面操作的情况,这里的
本地指客户端所在的本地路径另一种是使用JDBC操作的情况,这里的
本地指hiveserver2所在节点的本地路径 -
overwrite:表示覆盖表中已有数据,否则表示追加。 -
partition:表示上传到指定分区,若目标是分区表,需指定分区。分区表的概念后续后进行详细的介绍
实际操作
首先创建表:
CREATE TABLE myhive.test_load(
dt string comment '时间(时分秒)',
user_id string comment '用户ID',
word string comment '搜索词',
url string comment '用户访问网址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
接下来准备文件:
-
本地:

-
HDFS:
##从本地上传文件带HDFS hdfs dfs -put /export/test/search_log.txt /tmp/search_log.txt ##查看文件内容 hdfs dfs -cat /tmp/search_log.txt
可以看到数据都已经加载准备完毕了,接下来就使用我们的Load命令加载文件数据吧
-
首先从本地加载, 此处加了
local关键字,表示我们的数据是从本地开始加载的load data local inpath '/export/test/search_log.txt' into table myhive.test_load;
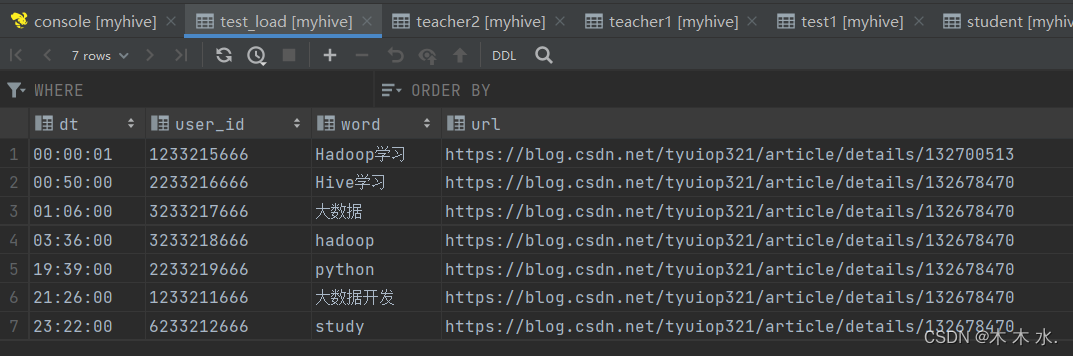
数据从本地加载成功
-
接下来再从HDFS加载,此时就不使用local关键字了
#先清空表数据 truncate table test_load; #此处使用了overwrite关键字,覆盖数据而不是追加数据 load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load;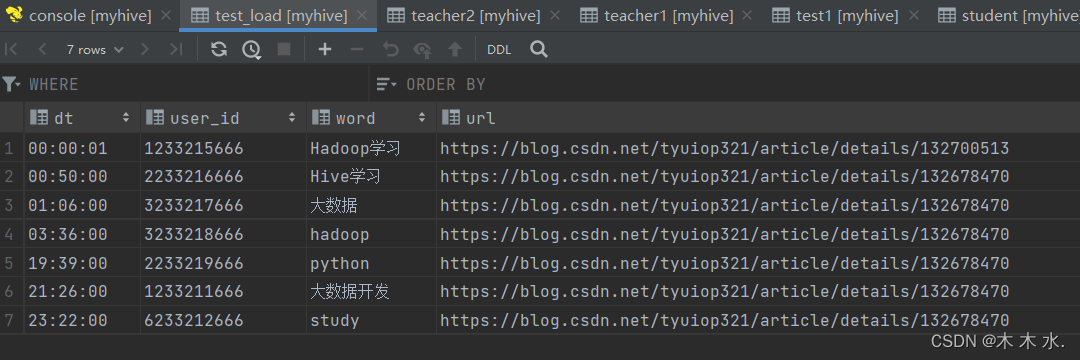
这时候需要注意:
基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)

可以看到HDFS当中的文件已经消失了,因为被移动到Hive的表当中去了
INSERT SELECT 操作
除了load加载外部数据外,我们也可以通过SQL语句,从其它表中加载数据。
语法:
INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表。
注意,这种INSERT SELECT操作不管什么情况下,都会走mapReduce程序,导致数据加载很慢,在大数据量的情况下,效率与Load操作相似,但是小数据量的情况下,效率远低于Load
Hive导出数据
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等等
语法:
insert overwrite [local] directory ‘path’ select_statement1 FROM from_statement;
-
将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/export/test/' select * from test_load ;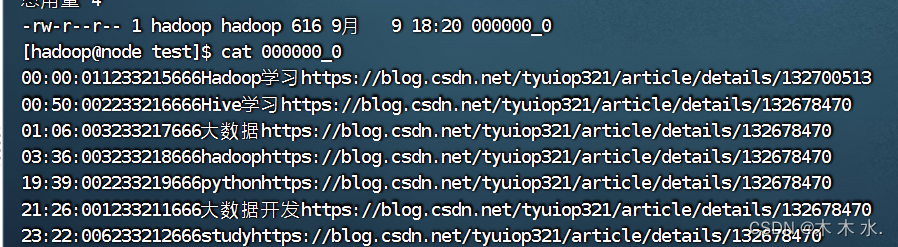
可以看到文件已经导出了,但是呢,文件的分隔符是默认的分隔符,导致不方便查看,所以要改变分隔符格式
-
将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/export/test/' row format delimited fields terminated by '\t' select * from test_load;
现在分隔符这种方式已经很方便查看了。
-
将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/export/test/' row format delimited fields terminated by '\t' select * from test_load;
hive表数据导出 - hive shell
通过hive shell的方式直接导出到linux本地
## 将sql查询语句的结果,通过重定向符,写入到/export/test/export4.txt文件当中
bin/hive -e "select * from myhive.test_load;" > /export/test/export4.txt
bin/hive -f export.sql > /home/hadoop/export4/export4.txt
结尾
恭喜小伙伴完成本篇文章的学习,相信文章的内容您已经掌握得十分清楚了,如果您对大数据的知识十分好奇,请接下来跟着学习路径完成大数据的学习哦,相信你会做到的~~~
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Arch linux 安装
- 第一次面试总结 - 迈瑞医疗 - 软件测试
- 【Linux】理解文件系统
- 说说MyBatis的优点和缺点
- draw流程图工具导入云原生(CNCF)相关控件
- Proxmox VE 安装 OpenWrt 配置旁路由教程
- 【第一节】Linux基础命令Part1
- mysql面试题:索引(B+树、聚集索引、二级索引、回表查询、覆盖索引、超大分页查询、索引创建原则)
- 物业、消防大数据平台页面,小区物业大数据监控服务平台(PS资料)
- Flink实战之运行架构