进程间通信
进程间通信
进程间通信介绍
进程间通信目的
-
数据传输:一个进程需要将它的数据发送给另一个进程
-
资源共享:多个进程之间共享同样的资源。
-
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止
时要通知父进程)。
-
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另
一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信发展
- 管道
- System V进程间通信
- POSIX进程间通信
进程间通信分类
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
进程间通信的本质
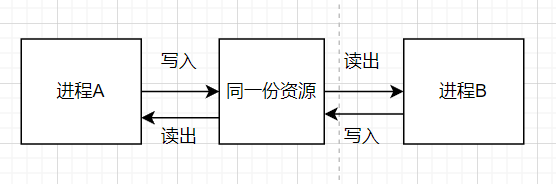
进程间通信的本质就是让不同的进程看到同一份资源(文件等等),然后进行交流(调用系统接口)
后者我们十分的熟悉,我们之前调用了很多个系统接口(fork,reak,write等等)
所以进程间通信的本质就是让不同资源看到同一份资源
管道
什么是管道
管道是Unix中最古老的进程间通信的形式。
我们把从一个进程连接到另一个进程的一个数据流称为一个“管道“
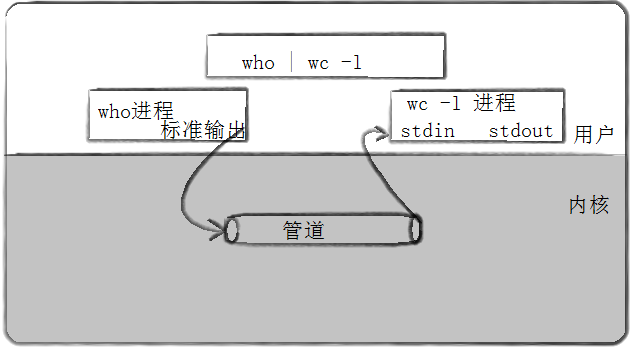
我们之前说进程间通信的本质是让不同的进程看到同一份资源,管道就是其中的一种资源
- 管道分为匿名管道和命名管道
匿名管道
进程间通信的本质就是让不同资源看到同一份资源
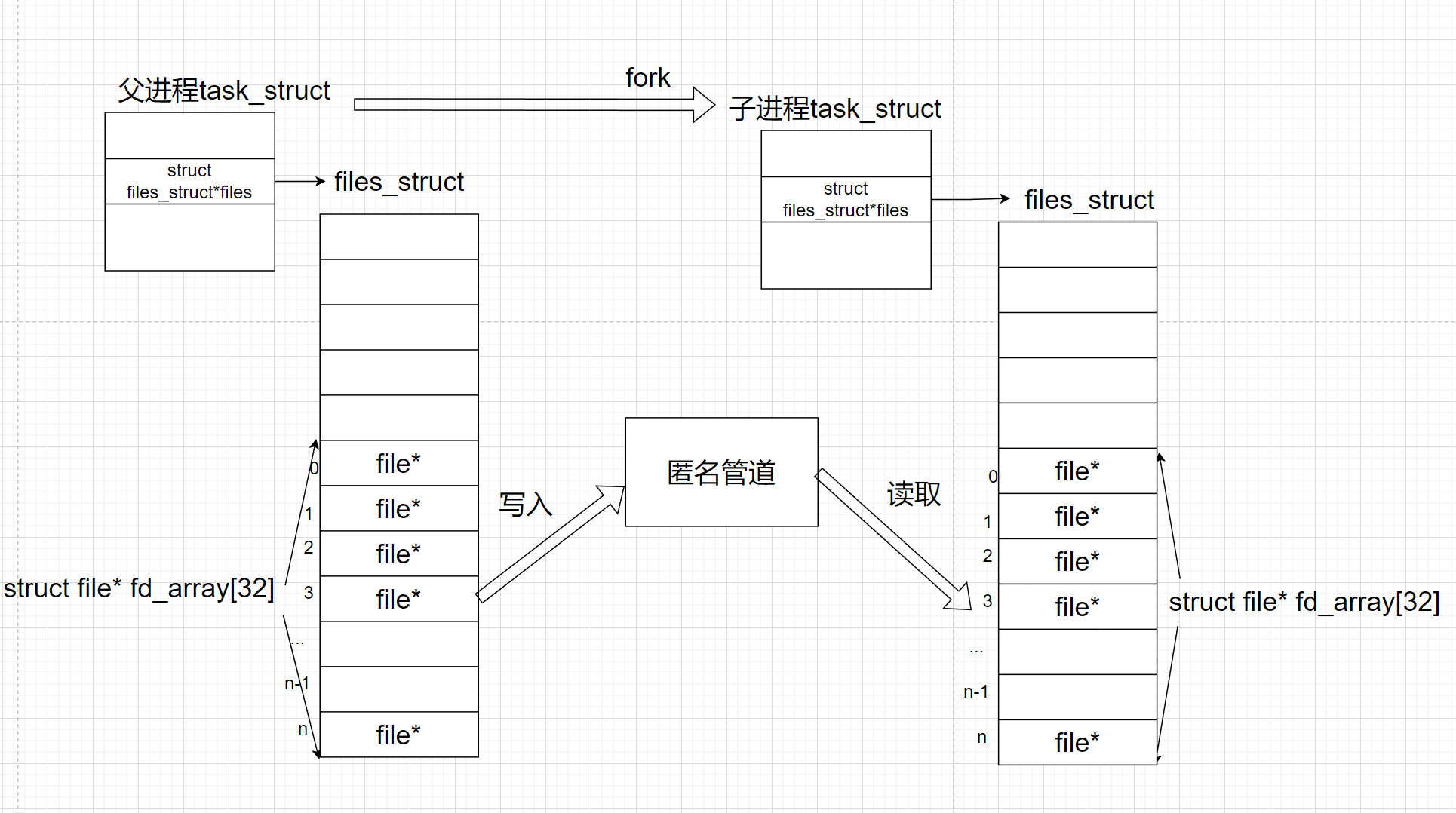
而匿名管道的本质就是让父子进程看到同一个文件(pipe),这样父进程进行写入或者读取,子进程负责读取或者写入,这样就可以完成进程间通信
我们在Linux中多次强调过,Linux下一切皆文件,因此管道也是一个文件
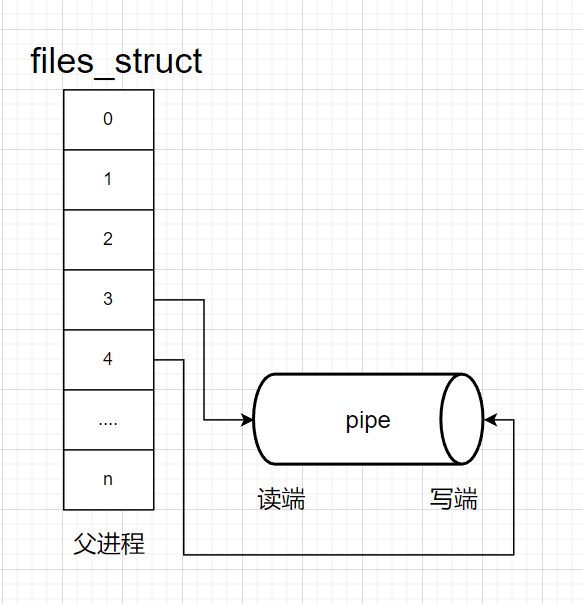
我们父进程在创建的时候,会默认打开0,1,2这三个文件描述符,会让磁盘会将信息加载到内存中struct file这个结构体里面,这里包含了操作方法和内部缓冲区
此时,我们父进程fork子进程的时候,不会拷贝匿名管道(struct file)这个文件,因为创建进程跟文件没有关系,但是files_struct会被拷贝,因为它属于进程的一部分,并拷贝了其中的文件描述符,曾经父进程打开的内容,子进程也会被映射,此时父进程打开同一份文件,就相当于看到了同一份资源,这个时候只要父进程写入,子进程读取就相当于完成了进程间通信
pipe函数
pipe函数用于创建匿名管道
#include <unistd.h>
int pipe(int pipefd[2]);
pipefd是一个输出型参数,pipefd[0]和pipefd[1]分别代表读取段和写入端
pipe成功返回0,失败返回-1
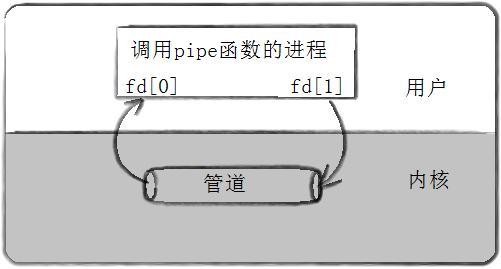
用fork共享匿名管道原理
父进程调用pipe系统接口
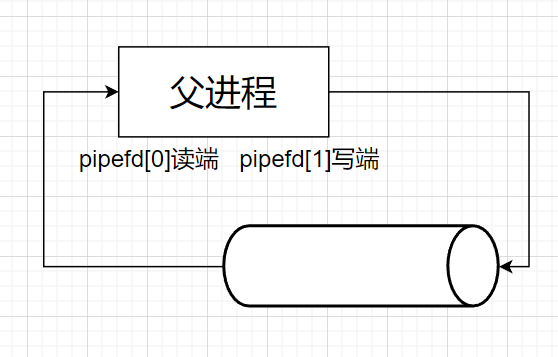
父进程fork后,也就是pipe的读端指向父子进程,pipe的写端也指向父子进程
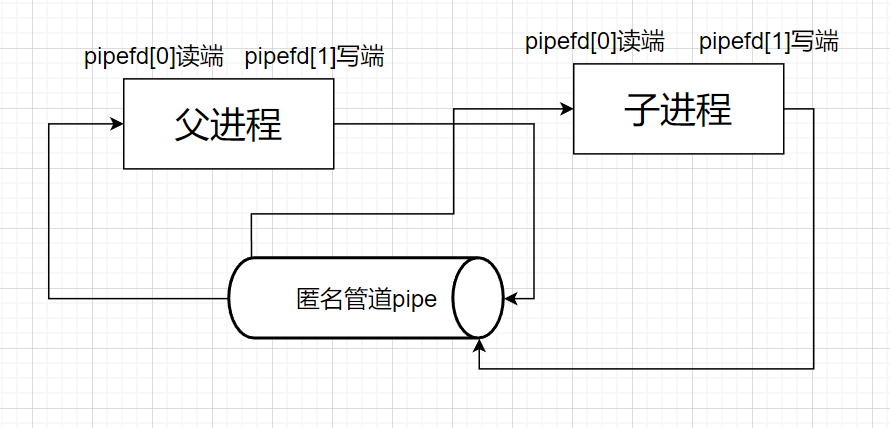
父进程关闭读端,子进程关闭写端
注意:
- 匿名管道只能用于有亲戚关系的进程,如父子进程,爷孙进程等等
- 管道只有单向性
- 从管道写端写入的数据会被内核缓冲,直到从管道的读端被读取。
站在文件描述符角度-深度理解管道
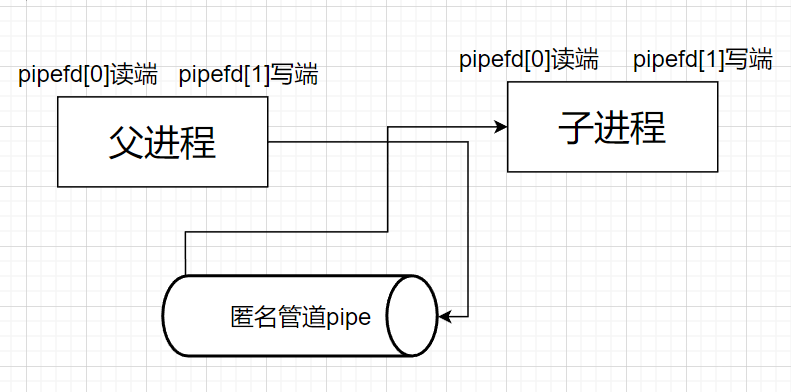
父进程调用pipe系统接口
父进程fork后,也就是pipe的读端指向父子进程,pipe的写端也指向父子进程
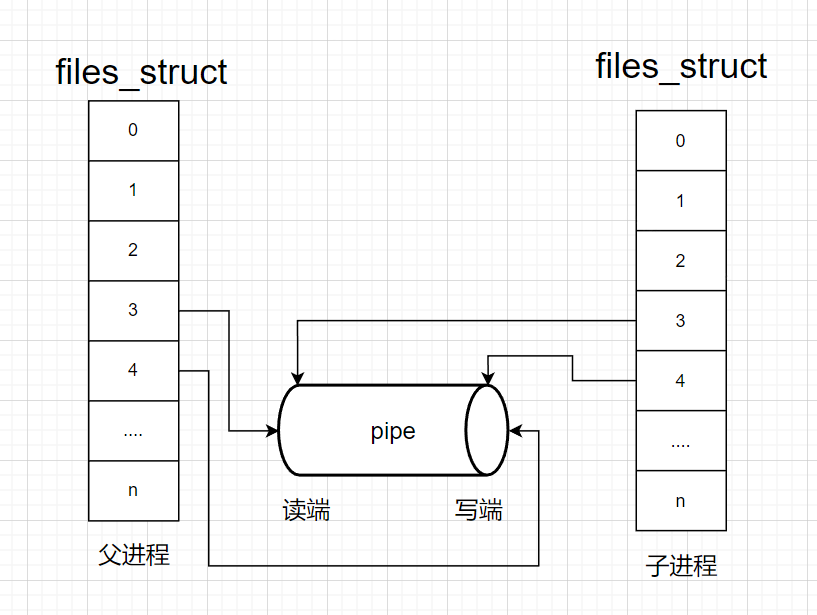
父进程关闭读端,子进程关闭写端
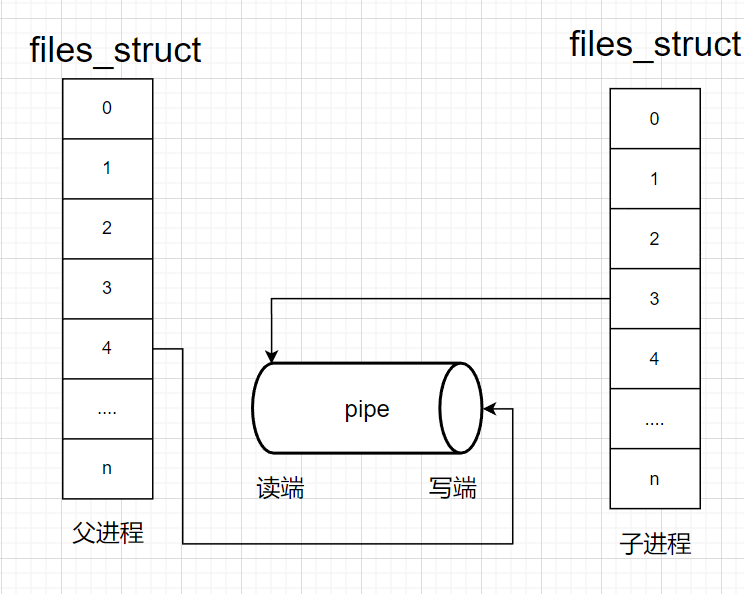
站在内核角度-管道本质
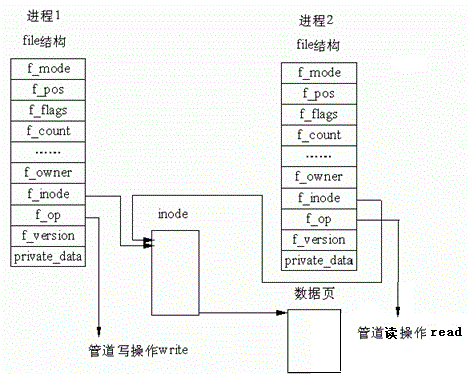
所以,看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了“Linux一切皆文件思想”。
当父进程关闭管道的写端,子进程是怎么知道父进程关了的?并且后面还把数据读完就关了呢?
- 父进程创建了子进程之后,在文件对应的属性中有引用计数,表示有多少个指针指向改进程,因此如果引用计数为1,说明该进程只要一个人在用,因此只要这个人读完就代表文件结束了。
因此,父进程和子进程在读写的时候,是有一定的顺序性的。
管道内部,没有数据的时候,reader就必须阻塞等待(将当前进程的take_struct放入等待队列中),等待管道有数据;如果数据被写满,writer就必须阻塞等待,等待管道中有空间。不过呢,在父子进程各自printf的时候(向显示器写入【显示器也是文件】),并没有什么顺序,因为缺乏访问控制。而管道内部是有顺序的,因为它自带访问控制机制,同步和互斥机制。
管道读写规则
-
O_NONBLOCK设置两个新的打开文件描述的O_NONBLOCK文件状态标志。使用为达到相同的结果,该标志省去了对fcntl(2)的额外调用。
-
在两个新的文件描述符上设置close-on-exec (FD_CLOEXEC)标志。看到open(2)中同一标志的描述,原因是这可能有用。
当管道内没有数据可读时:
- O_NONBLOCK disable:read调用一直阻塞,一直等到有数据来到为止。
- O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
当管道满的时候
- O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
- O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
如果所有管道写端对应的文件描述符被关闭,则read返回0
如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程
退出
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
我们这里解释一下原子性这个概念
原子性你可以理解为就只有两种状态要么做完了,要么没做
匿名管道特点
-
只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创
建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
-
管道提供流式服务
-
一般而言,进程退出,管道释放,所以管道的生命周期随进程
-
一般而言,内核会对管道操作进行同步与互斥
-
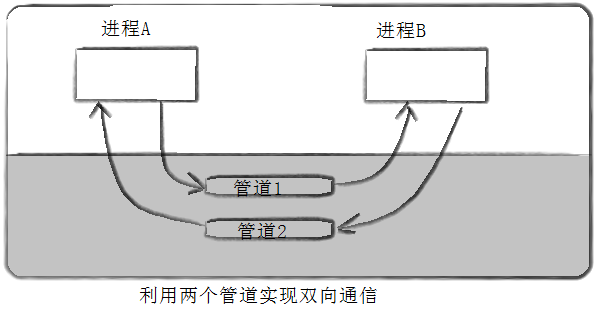
管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
在数据通信中,数据在线路上的传送方式可以分为以下三种:
- 单工通信(Simplex Communication):单工模式的数据传输是单向的。通信双方中,一方固定为发送端,另一方固定为接收端。
- 半双工通信(Half Duplex):半双工数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。
- 全双工通信(Full Duplex):全双工通信允许数据在两个方向上同时传输,它的能力相当于两个单工通信方式的结合。全双工可以同时(瞬时)进行信号的双向传输。
管道是半双工的,数据只能向一个方向流动,需要双方通信时,要建立起两个管道:
命名管道
- 匿名管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。
- 如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。
- 命名管道是一种特殊类型的文件
如何常见一个命名管道
命名管道可以从命令行上创建,命令行方法是使用下面这个命令:
$ mkfifo filename
我们发现我们的命名管道文件mypipe2是一个p类型文件
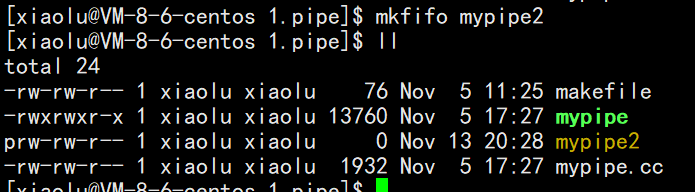
命名管道也可以从程序里创建,相关函数有:
int mkfifo(const char *pathname, mode_t mode);
mkfifo函数
函数原型:
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
mkfifo有两个参数pathname和mode
pathname参数:表示要创建的命名管道文件
- 如果pathname是一个路径的话,这个管道文件就创建在pathname这个路径下
- 如果path是文件名的话,就将这个管道文件默认创建在当前这个路径下
moded是默认权限
返回值:
- 创建成功返回0,创建失败返回-1
#include<iostream>
using namespace std;
#include<sys/types.h>
#include<sys/stat.h>
#define FILE_NAME "myfifo"
int main()
{
if (mkfifo(FILE_NAME, 0666) < 0)
{
cerr << "mkfifo error" << endl;
return 1;
}
//create success
cout << "hello world" << endl;
}
实际上创建出来文件的权限值还会受到umask(文件默认掩码)的影响,实际创建出来文件的权限为:mode&(~umask)。umask的默认值一般为0002,当我们设置mode值为0666时实际创建出来文件的权限为0664。若想创建出来命名管道文件的权限值不受umask的影响,则需要在创建文件前使用umask函数将文件默认掩码设置为0。
umask(0); //将文件默认掩码设置为0
匿名管道与命名管道的区别
-
匿名管道由pipe函数创建并打开。
-
命名管道由mkfifo函数创建,打开用open
-
FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完
成之后,它们具有相同的语义。
命名管道的打开规则
当前打开操作是读:
- O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO
- O_NONBLOCK enable:立刻返回成功
当前打开操作是写:
- O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO
- O_NONBLOCK enable:立刻返回失败,错误码为ENXIO
system V共享内存
共享内存区是最快的IPC形式。一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到
内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据
system V共享内存原理:
共享内存的底层原理跟两种管道不太一样,共享内存是通过在物理内存中申请一块空间用来充当共享内存,在通过页表的映射关系与进程的地址空间中的共享内存构建映射关系,从而完成进程间通信
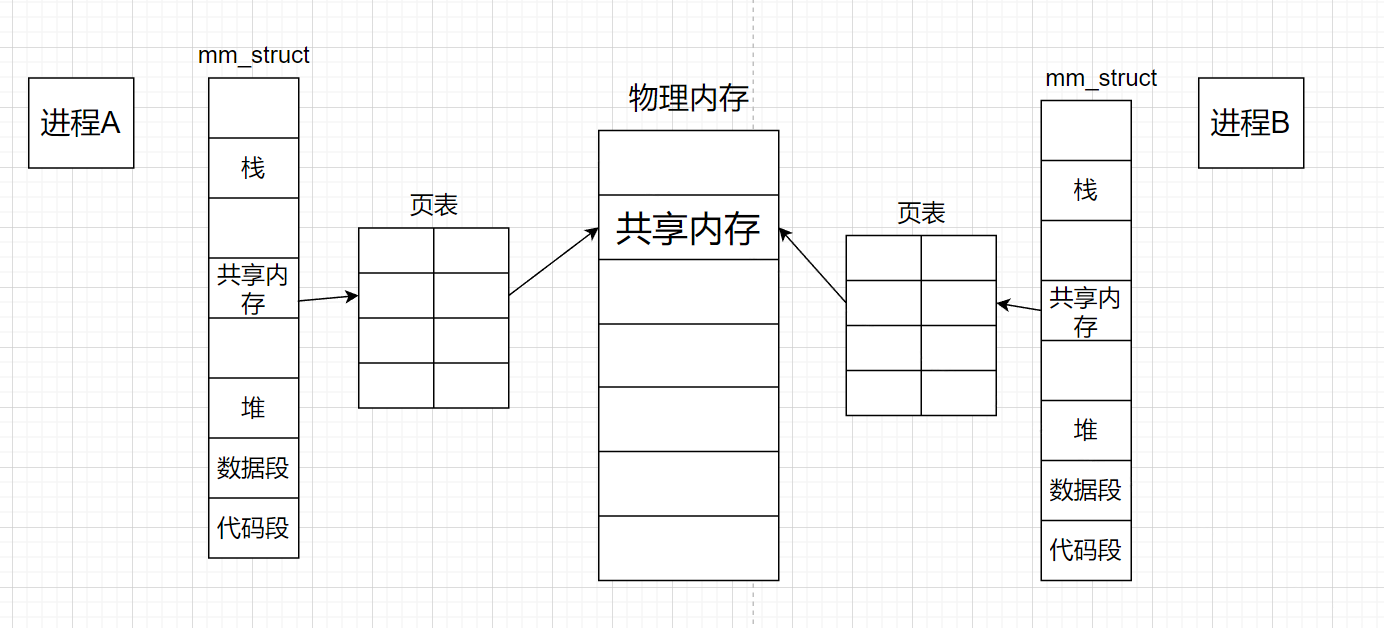
这里所说的开辟物理空间、建立映射等操作都是调用系统接口完成的,也就是说这些动作都由操作系统来完成。所以操作系统需要提供具有如下功能的接口:
- 创建共享内存 —— 删除共享内存(OS内部帮我们做)
- 关联共享内存 —— 去关联共享内存(进程做,实际也是OS做)
共享内存数据结构
在系统当中可能会有大量的进程在进行通信,因此系统当中就可能存在大量的共享内存,那么操作系统必然要对其进行管理,所以共享内存除了在内存当中真正开辟空间之外,系统一定还要为共享内存维护相关的内核数据结构。共享内存的数据结构如下:
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
共享内存函数
shmget函数创建共享内存
函数原型:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
shmget有三个参数
- key:表示共享内存在系统中的唯一标识
- size:共享内存大小(建议设置为页[4KB]的整数倍)
- shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
返回值:
- 成功:shmget()返回与参数值关联的System V共享内存段的标识符
- 失败:返回-1
?为什么要建议将size设为4KB的整数倍呢?
💡一个新的共享内存段,其size等于size的值向上取整为PAGE_SIZE(4KB)的倍数,我们假设有4GB的空间,约等于2^20次方个页,对于这么多页,操作系统需要把共享内存上的这么多页管理起来,依旧是先描述,再组织,OS内部用数组的方式将页保存了起来(struct page mem[2^20])。
shmflg
shmflg常见有两个标识符:IPC_CREAT和IPC_EXCL
- IPC_CREAT:当内存中有与key值相等的共享内存的话,就返回key值,如果没有的话就创建一个共享内存,并将其的标识符设为key值
- IPC_CREAT:IPC_CREAT不能单独使用,必须和IPC_CREAT配合,如果存在标识符为key值的共享内存的话,就报错返回,如果没有就创建一个标识符为key值的共享内存
换句话说:
使用组合IPC_CREAT,一定会获得一个共享内存的句柄,但无法确认该共享内存是否是新建的共享内存。
使用组合IPC_CREAT | IPC_EXCL,只有shmget函数调用成功时才会获得共享内存的句柄,并且该共享内存一定是新建的共享内存。
key
共享内存是存放在内核中的,内核会为我们维护共享内存的结构,那如何管理呢?依旧是先描述再管理
我们再来看看内核中共享内存的结构体:
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
我们发现第一个变量是一个ipc_perm结构体类型的变量,而我们的key值就存放在这个结构体中
struct ipc_perm {
key_t __key; /* Key supplied to shmget(2) */
uid_t uid; /* Effective UID of owner */
gid_t gid; /* Effective GID of owner */
uid_t cuid; /* Effective UID of creator */
gid_t cgid; /* Effective GID of creator */
unsigned short mode; /* Permissions + SHM_DEST and SHM_LOCKED flags */
unsigned short __seq; /* Sequence number */
};
ipc_perm结构体的第一个变量是key,而这个key是标识共享内存的唯一标识符
一个key代表一个共享内存,因此我们如何获取跟之前不同的key值呢?
ftok函数获取key值
我们上文说到了我们需要不同的key值,因此就出现ftok函数,我们可以通过 ftok函数来获取不同的key值
#include <sys/types.h>
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
我先来介绍这两个参数:
- pathname为一个已存在的路径名
- proj_id:为一个整数标识符
ftok函数会通过pathname和proj_id的最低八位(必须非0)这两个参数生成一个key值,而这个key值被称IPC键值
如果ftok函数调用成功的话,就会返回这个key值,如果失败就会返回-1
而这个key值也是就IPC键值在shmget函数调用的时候会被填充到ipc_perm这个结构体内
如果我们想要通过共享内存进行进程间通信的话:
我们可以传入相同的pathname和proj_id的值,这样就会生成相同的key值从而看到同一块共享内存
shmctl函数释放共享内存
此时我们若是要将创建的共享内存释放,有两个方法,一就是使用命令释放共享内存,二就是在进程通信完毕后调用释放共享内存的函数进行释放。
我们可以通过ipcs命令来查看共享内存的信息:
$ ipcs
如果我们单独用ipcs命令他会自动跳出消息队列,共享内存以及信号量的信息,ipcs命令可以带很多选项:
- -q:列出消息队列相关信息。
- -m:列出共享内存相关信息。
- -s:列出信号量相关信息。
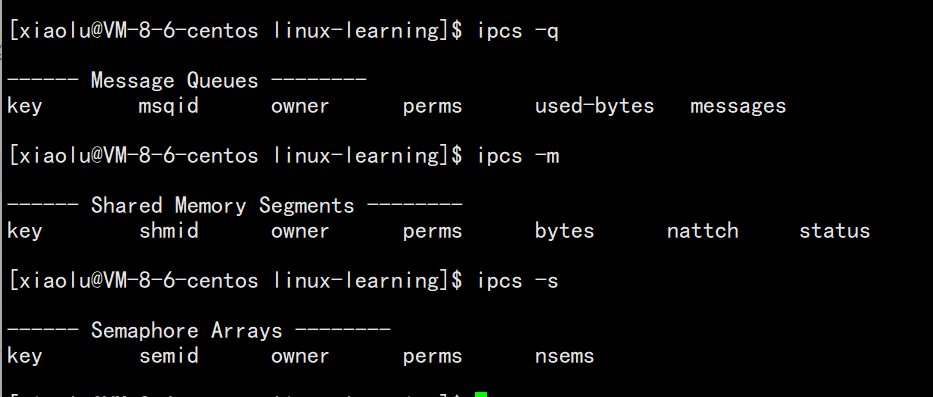
我们看到共享内存中有很多变量,我们来了解一下他们的含义:
| 变量 | 含义 |
|---|---|
| key | 系统层面的标识符 |
| shmid | 用户层面的唯一标识符 |
| owner | 所有者 |
| perms | 权限 |
| bytes | 共享内存的大小 |
| nattch | 关联共享内存的进程数量 |
| status | 共享内存的状态 |
在共享内存列表中的perms代表的是该共享内存的权限,这个是可以修改的:
int shmid = shmget(key, MEM_SIZE, flags | 0666);
注意: 、
key是在内核层面上保证共享内存唯一性的方式,而shmid是在用户层面上保证共享内存的唯一性,key和shmid之间的关系类似于fd和FILE*之间的的关系。
如果我们想要显示的删除,就使用ipcrm -m shmid:
$ ipcrm -m shmid
我们可以通过系统接口去释放共享内存
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
- shmid:由shmget返回的共享内存标识码
- cmd:将要采取的动作(有三个可取值)
- buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1
关于cmd的三个可取值:
| 选项 | 含义 |
|---|---|
| IPC_STAT | 获取当前的共享内存的关联值,且buf为输出型参数 |
| IPC_SET | 在进程有足够权限的前提下,将共享内存的当前关联值设置为buf所指的数据结构中的值 |
| IPC_RMID | 删除共享内存 |
shmat函数关联共享内存:
#include <sys/types.h>
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);
我们来认识shmat的三个参数:
- shmid:用户层面的唯一标识符
- shmaddr:要连接的地址,通常为NULL,OS会自动给你找一个合适的地址
- shmflg:标识符,他有3个可能取值SHM_RND和SHM_RDONLY还有个0
返回值:成功返回一个指针,指向共享内存第一个节;失败返回-1
shmflg有三个可能取值我们来了解一下:
| 选项 | 含义 |
|---|---|
| SHM_RDONLY | 关联共享内存后只能进行读取操作 |
| SHM_RND | 若shmaddr不为NULL,则关联地址自动向下调整为SHMLBA的整数倍。公式:shmaddr-(shmaddr%SHMLBA) |
| 0 | 读写权限 |
说明:
shmaddr为NULL,核心自动选择一个地址
shmaddr不为NULL且shmflg无SHM_RND标记,则以shmaddr为连接地址。
shmaddr不为NULL且shmflg设置了SHM_RND标记,则连接的地址会自动向下调整为SHMLBA的整数倍。公式:shmaddr -(shmaddr % SHMLBA)
shmflg=SHM_RDONLY,表示连接操作用来只读共享内存
shmdt函数去关联共享内存
有关联共享内存的函数,肯定也有去关联的函数啊!
#include <sys/types.h>
#include <sys/shm.h>
int shmdt(const void *shmaddr);
参数
shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段
共享内存与管道进行对比
从上文的描述中,我们可以清晰的得知,当共享内存建立完后,我们不需要再进行系统的调用,而管道建立后还需进行read和write等系统接口的调用,因此从访问速度上讲的话,共享内存的速度肯定是最快的
我们先来看看管道通信:
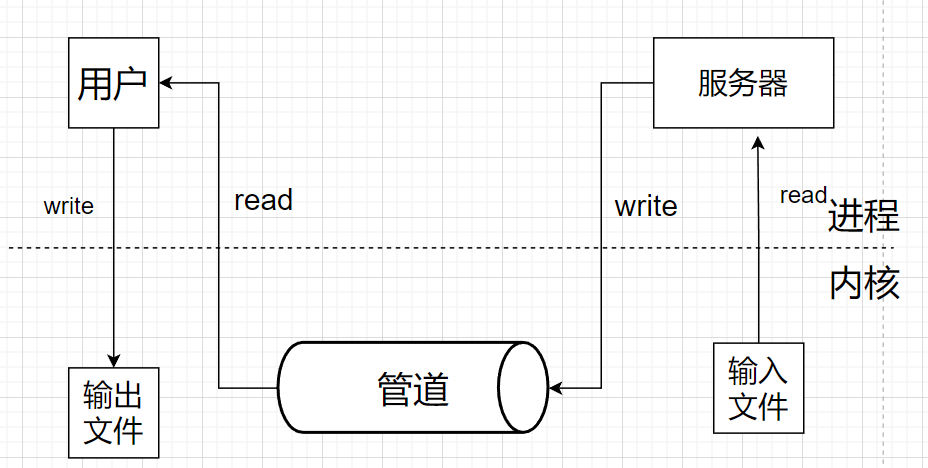
我们观察上图的话,很明显可以发现管道通信的话我们需要进行4次拷贝
- 服务端将信息从输入文件拷贝到输入文件的缓冲区中
- 将服务端的信息拷贝到管道中
- 用户端将管道中的信息拷贝到用户端的缓冲区中
- 将用户端临时缓冲区的信息拷贝到输出文件中
再来看看共享内存通信:
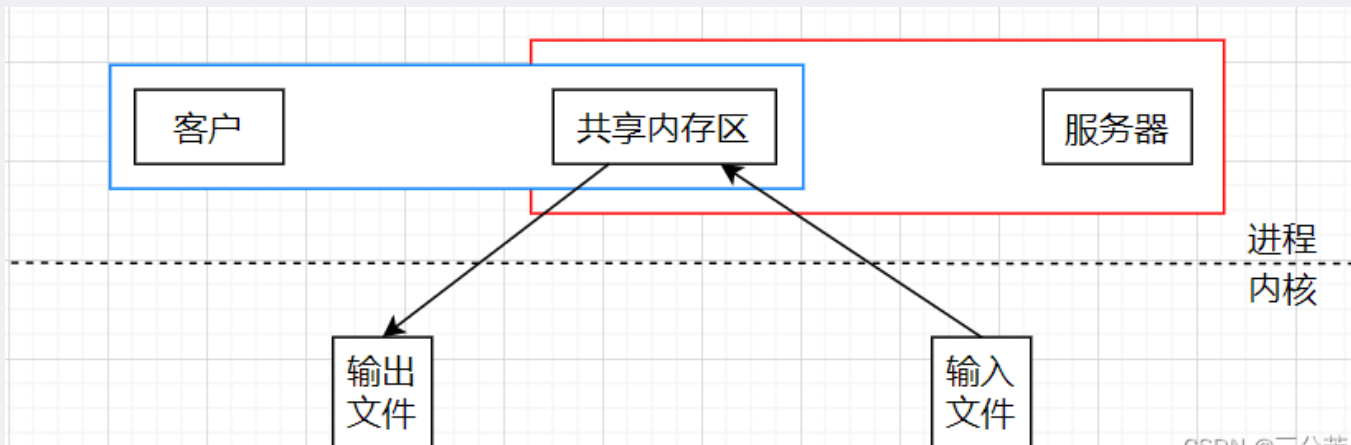
从这张图可以看出,使用共享内存进行通信,将一个文件从一个进程传输到另一个进程只需要进行两次拷贝操作:
- 从输入文件到共享内存。
- 从共享内存到输出文件。
从以往的 学习中,我们可以得知影响进程间通信时间最严重的是IO
所以共享内存是所有进程间通信方式中最快的一种通信方式,因为该通信方式需要进行的拷贝次数最少。但是共享内存也是有缺点的,我们知道管道是自带同步与互斥机制的,但是共享内存并没有提供任何的保护机制,包括同步与互斥。
临界资源、临界区、原子性、互斥
- 临界资源:
被多个进程能够同时看到的资源,叫做临界资源(管道,共享内存中的资源都属于临界资源)
如果没有对临界资源进行任何保护,对于临界资源的访问,双方进程在进行访问的时候,就会都是乱序的,可能会因为读写交叉而导致各种乱码、废弃数据、访问控制方面的问题。
- 临界区:
对多个进程而言,访问临界资源的代码,叫做临界区。(在之前写的进程代码中,只有一部分代码会访问临界资源,这部分代码就叫做临界区)
- 原子性:
我们把一件事情,要么没做,要么做完了,称之为原子性
- 互斥:
缓冲区的信息拷贝到输出文件中
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!