AIGC系列之:实时出图的SDXL Turbo模型介绍

原理介绍
????????StabilityAI在刚刚发布Stable Video Diffusion之后,2023年11月29日又发布了爆炸性模型:SDXL Turbo,SDXL Turbo是在SDXL 1.0的基础上采用新的蒸馏方案,让模型只需要一步就可以生成高质量图像,主要焦点是速度,因为它能够实时生成图像。目前代码,模型和技术报告已经开源。简而言之,SDXL Turbo是SDXL 1.0的一个蒸馏版本,专为实时合成而训练。
????????SDXL Turbo是基于SDXL 1.0经过实时合成训练开发而成,是一种快速生成的文本到图像模型,可以在单个网络评估中从文本提示合成逼真的图像。SDXL-Turbo基于一种称为对抗扩散蒸馏(Adversarial Diffusion Distillation, ADD)的新型训练方法,该方法允许在1到4步内以高图像质量采样大规模基础图像扩散模型。该方法使用分数蒸馏来利用大规模现成的图像扩散模型作为教师信号,并将其与对抗损失相结合,以确保即使在一个或两个采样步骤的低步范围内也能获得高图像保真度。
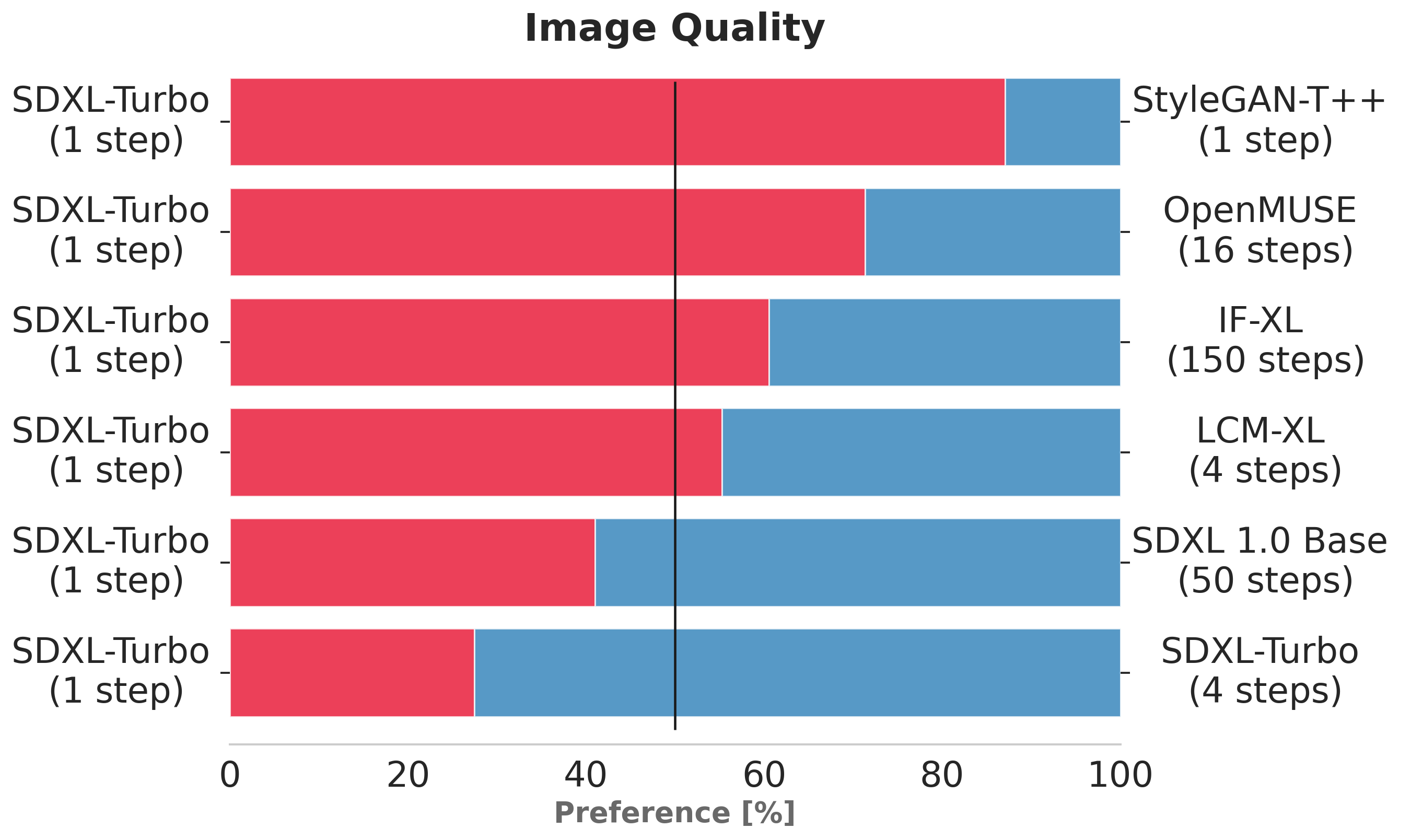

上面的图表评估了用户对SDXL-Turbo的偏好,而不是其他单步和多步模型。在图像质量和快速跟踪方面,仅一步评估的SDXL-Turbo比四个(或更少)步骤评估的LCM-XL更受人们的青睐。此外,SDXL-Turbo使用四个步骤进一步提高了性能。
使用方法
????????SDXL Turbo已经集成到Huggingface的transformers库中了,这里做一个简单的展示如何使用,首先可以先安装transformers库
pip install diffusers transformers accelerate --upgrade????????SDXL-Turbo在文生图中不使用guidance_scale或negative_prompt,所以用guidance_scale=0.0禁用它。该模型最好生成512x512大小的图像,但更大的图像也可以工作。一个步骤就足以生成高质量的图像。
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
????????当使用SDXL-Turbo进行图像到图像的生成时,请确保num_inference_steps *强度大于或等于1。image-to-image管道将运行int(num_interence_steps * strength)步,例如在下面的例子中0.5 * 2.0 = 1步。
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image
import torch
pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png").resize((512, 512))
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]
总结分析
优点:
-
可以实现生成模型的实时应用,出图速度更快,等待时间短,出图效果和SDXL基本一致。
缺点:
-
生成的图像是固定分辨率的(512x512像素),模型不能达到完美的真实感;
-
该模型不能呈现清晰的文本;
-
人脸和一般人可能无法正确生成;
-
模型的自动编码部分是有损的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!