【MYSQL】MYSQL 的学习教程(十三)之 MySQL的加锁规则

1. MySQL 加锁全局视角
MySQL 分成了 Server 层和存储引擎两部分,每当执行一个查询时,Server 层负责生成执行计划,然后交给存储引擎去执行。其整个过程可以这样描述:
- Server 层向 Innodb 获取到扫描区间的第 1 条记录
- Innodb 通过 B+ 树定位到扫描区间的第 1 条记录,然后返回给 Server 层
- Server 层判断是否符合搜索条件,如果符合则发送给客户端,不符合,则跳过。接着继续向 Innodb 要下一条记录
- Innodb 继续根据 B+ 树的双向链表找到下一条记录,会执行具体的 row_search_mvcc 函数做加锁等操作,返回给 Server 层
- Server 层继续处理该条记录,并向 Innodb 要下一条记录
- 继续不停执行上述过程,直到 Innodb 读到一条不符合边界条件的记录为止
通过上面这个过程,明白两个重要的认识:
- Innodb 并不是一次性把所有数据找到,然后返回给 Server 层的,而是会循环很多次
- row_search_mvcc 这个函数是做具体的加锁、加什么锁的重要逻辑,并且由于 Server 层与 Innodb 会循环多次,因此该函数也是会执行多次的
弄懂了上面两个认识,会对后续大家理解有很大帮助。例如:对于 select * from user where id >= 5 进行分析的时候,为什么会出现说第一次加锁是精确查询?它明明是范围查询呀!这是因为第一次是要寻找到 id = 5 的记录,对于 Innodb 来说,它就是精确查找,不是范围查找。随后找到 id = 5 的记录之后,就要找 id > 5 的记录了,此时就变成了范围查找了
2. MySQL 加锁规则
对于 RC 隔离级别,加的排他锁(X锁),是比较好理解的,哪里更新就锁哪里。RR 隔离级别加锁有一定的规则
锁规则一共包括:两个原则、两个优化和一个 bug
- 原则 1:加锁的基本单位都是 next-key lock。next-key lock(临键锁)是前开后闭区间
- 原则 2:查找过程中访问到的对象才会加锁
- 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁(Record lock)
- 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁(Gap lock)
- 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止
说明:
- 对于原则 1 说的:加锁的基本单位是 Next-Key 锁,意思是默认都是先加上 Next-Key,之后根据 2 个优化点选择性退化为行锁或间隙锁
- 对于原则 2 说的:访问到的对象才会加锁,意思是如果直接索引覆盖到了,不需要回表,那么就不会对聚簇索引加锁。这样的话,其他事务就可以对聚簇索引进行操作,而不会阻塞
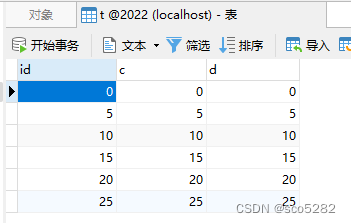
测试数据:
CREATE TABLE `t` (
`id` int NOT NULL,
`c` int NULL DEFAULT NULL,
`d` int NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `c`(`c`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
INSERT INTO `t` VALUES (0, 0, 0);
INSERT INTO `t` VALUES (5, 5, 5);
INSERT INTO `t` VALUES (10, 10, 10);
INSERT INTO `t` VALUES (15, 15, 15);
INSERT INTO `t` VALUES (20, 20, 20);
INSERT INTO `t` VALUES (25, 25, 25);
3. 七个案例
分7个案例去分析哈:
- 等值查询间隙锁
- 非唯一索引等值锁
- 主键索引范围锁
- 非唯一索引范围锁
- 唯一索引范围锁 bug
- 普通索引上存在"等值"的例子
- limit 语句减少加锁范围
3.1 案例一:等值查询间隙锁
我们同时开启 A、B、C三个会话事务,如下:

发现事务 B 会阻塞等待,而 C 可以执行成功
分析流程:
- 在事务 A 中,要查找 id = 7 的记录,其查找过程为:从左到右查找 id 聚簇索引,依次对比 0、5 两个索引,发现不对。接着,对比 10 这个索引,发现 7 <10,于是停止搜索。根据原则 1,默认给其加上一个 Next-Key 锁,即 (5, 10]
- 同时根据优化 2,这是一个等值查询 (id=6),而 id=10 不满足查询条件。所以 next-key lock 退化成间隙 Gap 锁,因此最终加锁的范围是 (5,10)
3.2 案例二:非唯一索引等值锁
按顺序执行事务会话A、B、C,如下:

发现事务B可以执行成功,而 C 阻塞等待
分析流程:
- 在事务 A 中,要查找 c=5 的记录,其中 c 是非唯一索引。其查找过程为:从左到右查找 c 索引,找到了 c=5 的索引,根据原则 1,对其加 Next-Key 锁,即 (0,5]
- 由于普通索引可能重复,因此其还会继续往后搜索,接着搜索到 10,根据原则 2,访问到的都要加锁,因此再给其加 Next-Key 锁,即 (5,10]
- 根据优化2:等值判断,向右遍历,最后一个值 10 不满足 c = 5 这个等值条件,因此退化成间隙锁 (5,10)
- 根据原则 2 :只有访问到的对象才会加锁,事务 A 的这个查询使用了覆盖索引,没有回表,并不需要访问主键索引,因此主键索引上没有加任何锁,事务会话 B 是对主键 id 的更新,因此事务会话 B 的 update 语句不会阻塞
3.3 案例三:主键索引范围锁
按顺序执行事务会话A、B、C,如下:

事务 B:插入 id = 12 时阻塞;插入 id = 6 时顺利执行;
事务 C:阻塞
分析流程:
- 事务 A 开始执行的时候,要找到 id 为 10 的记录,于是从左到右找到了 id 为 10 的索引。根据原则 1 会给其加 Next-Key 锁,即 (5,10]
- 又因为 id 是主键,也就是唯一值,因此根据优化1:索引上的等值查询,给唯一索引加锁时,next-key lock 退化为行锁(Record lock)。所以只加了 id=10 这个行锁
- 接着继续进行范围查找,找到 id=15 这一行,继续加 Next-Key 锁 (10,15]。这时候 id=15 大于 11,因此其不再查找
事务会话 A 执行完后,加的锁是 id=10 这个行锁,以及临键锁 next-key lock(10,15]
3.4 案例四:非唯一索引范围锁
按顺序执行事务会话 A、B、C,如下:

发现事务会话 B 和事务会话 C 的执行 SQL 都被阻塞了
分析流程:
- 事务 A 开始执行的时候,要找到 id 为 10 的记录,根据原则 1 加了 Next-Key 锁,即 (5,10]。 由于索引 C 是非唯一索引,不符合优化1,因此不会退化为行锁
- 接着继续进行范围查找,找到 id=15 这一行停下来,因此还需要加 next-key lock (10,15]
3.5 案例五:唯一索引范围锁 bug
按顺序执行事务会话 A、B、C,如下:

事务 B 阻塞;事务 C 阻塞
分析流程:
- 事务 A 开始执行的时候, 0、5、10 都不满足条件,找到 id = 15 的行满足,根据原则1,会加上next-key lock(10,15]
- 因为 id 是主键,即唯一的,因此循环判断到 id = 15 这一行就应该停止了
- 根据一个 bug:InnoDB 会往前扫描到第一个不满足条件的行为止,直到扫描到 id = 20。而且由于这是个范围扫描,因此索引 id 上的 (15,20] 这个 next-key lock 也会被锁上
3.6 案例六:普通索引上存在"等值"的例子
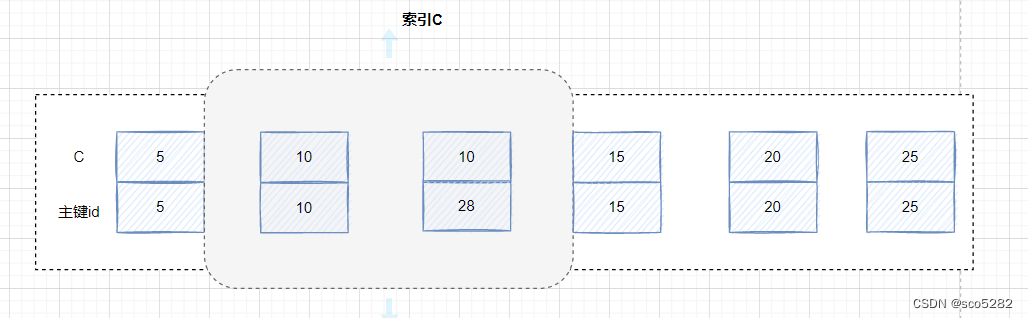
插入一条数据:
insert into t values(28,10,66);
则 c 索引树如下:

c 索引值有相等的,但是它们对应的主键是有间隙的。比如(c=10,id=10)和(c=10,id=28)之间
按顺序执行事务会话A、B、C,如下:

事务 B 阻塞;事务 C 顺利执行
分析流程:
- 事务 A 开始执行的时候,要找到 c 为 10 的记录,根据原则 1,加一个(c=5,id=5) 到 (c=10,id=10)的 next-key lock(5, 10]
- 由于 c 是非唯一索引,会继续向右进行范围查找,直到碰到 (c=15, id=15) 这一行,循环才结束,会加一个 next-key lock(10, 15]。根据优化 2,这是一个等值查询,向右查找到了不满足条件的行,所以会退化成间隙锁 (10, 15)
在索引 c 上的加锁范围,就是下图灰色阴影部分的:
3.7 案例七:limit 语句减少加锁范围
事务A、B执行如下:
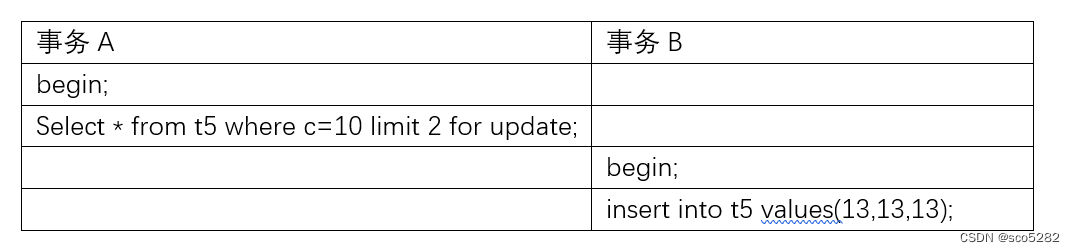
事务 B 顺利执行
分析流程:
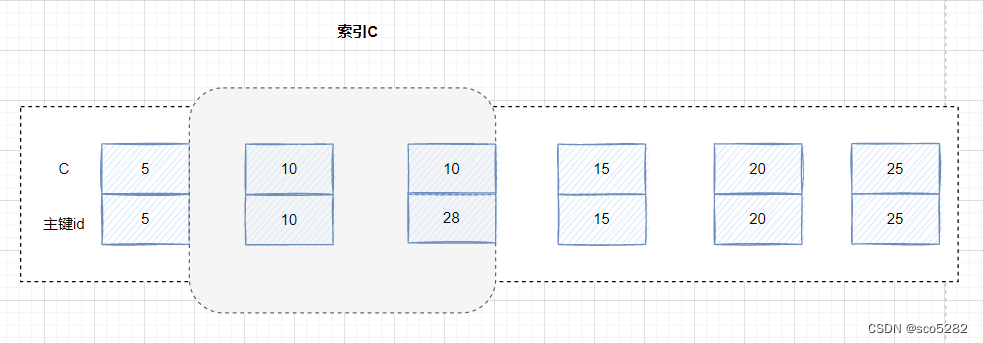
- 事务 A 开始执行的时候,要找到 c 为 10 的记录,根据原则 1,加一个(c=5,id=5) 到 (c=10,id=10)的 next-key lock(5, 10]
- 因为明确加了limit 2的限制后,因此在遍历到 (c=10, id=30) 这一行之后,满足条件的语句已经有两条,循环就结束了
如下图所示:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 网络爬虫第1天之数据解析库的使用
- 美易官方:美国电商巨头eBay宣布裁员约1000人
- 【PostgreSQL】从零开始:(三十二)数据类型-范围类型
- 多元高斯分布:条件分布推导
- vivado IP Revision Control
- 医学图像的图像处理、分割、分类和定位-1
- Golang简单实现IO操作
- 1901年-2022年全球气象数据CRU TS下载
- 如何在anaconda里安装basemap和pyproj库
- 最好用的Redis客户端:RedisInsight安装部署教程, 官方亲儿子真香, 2种安装方式(包含Docker方式), 超详细教程