数据操作、数据预处理
发布时间:2024年01月14日
1.数据类型:

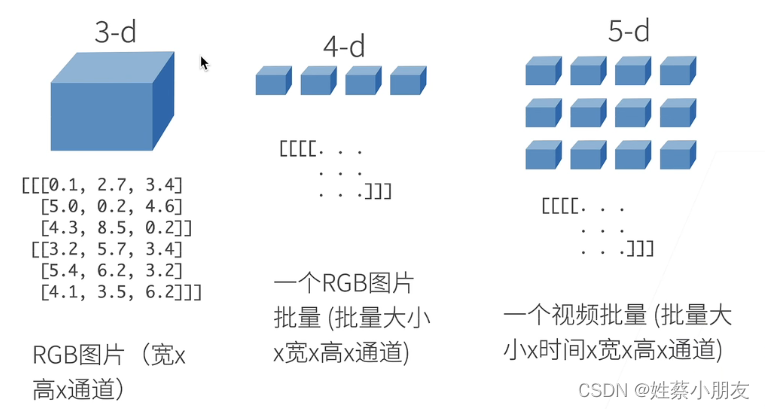
2.数组元素操作:
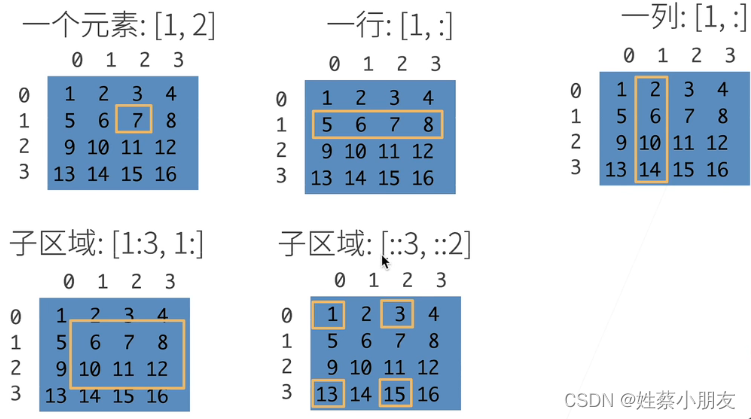
3.数据预处理:
import os
import pandas as pd
import numpy as np
#创建csv文件并写入数据
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
#读csv文件
data = pd.read_csv(data_file)
'''处理缺失值方式:将数值型列的缺失值用该列均值填充,将有缺失值的非数值型列作为新的列
inputs取所有行+第0,1列。outputs取所有行+第2列
'''
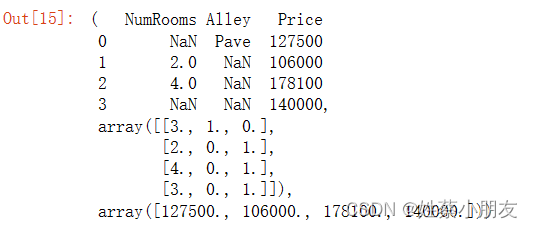
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
#均值代替
inputs = inputs.fillna(inputs.mean(numeric_only=True))
#pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
#现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。
X, y = np.array(inputs.to_numpy(dtype=float)), np.array(outputs.to_numpy(dtype=float))
data, X, y
文章来源:https://blog.csdn.net/m0_53881899/article/details/135579441
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于JAVA的APK检测管理系统 开源项目
- C++设计模式 #8 抽象工厂(Abstract Factory)
- 16.【TypeScript 教程】TypeScript 泛型(Generic)
- 微信投票小程序源码系统 多功能强化版 带完整的安装部署教程
- HarmonyOS应用程序包快速修复
- 图像文件怎么才能转换为Excel
- 如何创作出优秀的电子邮件营销(EDM)?
- SecureCRT 键盘输入无反应
- 查看各个文件夹大小的linux命令
- 浅谈缓存最终一致性的解决方案