爬虫基础简介
发布时间:2024年01月18日
爬虫带来的风险
- 爬虫干扰了被访问网站的正常运营
- 爬虫爬取了受到法律保护的特定类型的数据或信息
如何正确使用爬虫
- 时长优化自己的程序,避免干扰被访问网站的正常运行
- 在使用,传播爬取到的数据时,如果发现了涉及到用户隐私商业机密等敏感内容需要及时停止爬取或传播
爬虫的分类
- 通用爬虫:搜索引擎抓取系统(封装的爬虫程序)的重要组成部分。抓取的是互联网中的一整张页面数据
- 聚焦爬虫:建立在通用爬虫的基础之上。抓取的是页面中的局部内容先使用通用爬虫,再使用聚焦爬虫
- 增量式爬虫:检测网站中数据更新的情况,只会爬取网站中更新的数据
反爬机制
相关门户网站可以通过指定相应的策略或技术手段防止爬虫程序进行网站数据的爬取
反反爬策略
爬虫程序也能应用相关技术破解反爬机制
robots.txt协议
规定了网站中哪些能够被爬虫爬取,哪些不能被爬取 ?
robots文件是一个纯文本文件,也就是常见的.txt文件。在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。因此,robots的优化会直接影响到搜索引擎对网站的收录情况。 ?
robots文件必须要存放在网站的根目录下。也就是 域名/robots.txt 是可以访问文件的。
> <https://taobao.com/robots.txt>
> 更多关于robots协议的见:<https://zhuanlan.zhihu.com/p/342575122>
>
http协议纯文本传输协议
- 概念:就是服务器与客户端进行数据交互的一种形式。
- 常用的请求头信息:
- User-Agent:请求载体的身份标识
- ?Connection:请求完毕后是断开连接还是保持连接。
- ?常用的相应头信息:
? ? ????????Content-Type:服务器响应回客户端的数据类型
https协议安全的http(超文本传输协议)协议
- 区别:比http多了数据加密
- 加密方式:
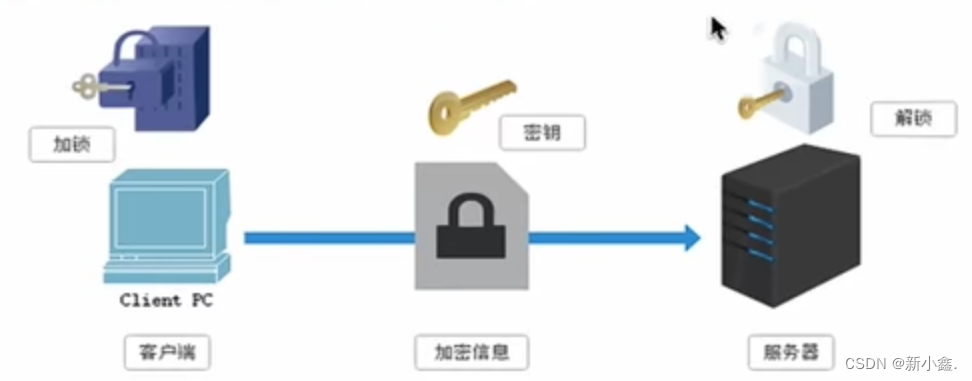
- 对称密钥加密:客户端把要发送给服务器的数据进行加密(密文),将密文和密钥一起打包发给服务器端,服务器就能使用密钥把数据解密,从而使用数据。但是在数据传输过程中密文和密钥容易同时被截取就会被第三方获取到数据。
- 非对称密钥加密:服务器将“公开密钥”发送给客户端,客户端按照公密将数据加密后再把数据发送给服务器,服务器接受到信息在通过自己的“私有密钥”进行解密。解密的要是根本就不会进行传输,因此也就避免了被挟持的风险的。但这种方式的效率比较低,处理起来比较复杂;如何保证接收端想发送端发出公开密钥的时候,发送端确保收到的是预先要发送的,而不会被挟持,只要是发送密钥就有可能有被挟持的风险。
?- 证书密钥加密https采用的加密方式:服务器端指定加密方式(公钥),发送给证书认证机构审核公钥,对公钥进行数字签名用于防伪,将防伪后的公钥封装到证书中,再将证书发送给客户端。客户端接受公钥后,使用携带数字签名的公钥对数据进行加密,发送给服务器,服务器再使用私钥解密。能够保证客户端接受到的公钥是服务器发来的
文章来源:https://blog.csdn.net/weixin_74118846/article/details/135629180
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法训练营Day41(动态规划3)
- RT-Thread 内核基础(四)
- iptables 技术简介
- 鸿蒙开发之数据持久化存储Preferences
- 使用哈希表(散列表)+顺序二叉树实现电话簿系统(手把手讲解)
- [已解决] Ubuntu远程桌面闪退+登录显示“远程桌面由于数据加密错误 , 这个会话将结束“
- UI设计中的插画运用优势(上)
- php中的继承和接口
- 为什么MySQL用B+树做索引而不使用其他的数据结构呢?
- linux/CentOS 7安装Nginx