Linux network — 网络层收发包流程及 Netfilter 框架浅析
Linux network — 网络层收发包流程及 Netfilter 框架浅析
1. 前言
??本文主要对 Linux 系统内核协议栈中网络层接收,发送以及转发数据包的流程进行简要介绍,同时对 Netfilter 数据包过滤框架的基本原理以及使用方式进行简单阐述。
2. 基础网络知识
2.1 网络分层模型
??OSI 模型中将网络划分为七层,但在目前实际广泛使用的 TCP/IP 协议框架体系内,我们一般将网络划分为五层,从下到上依次为物理层,链路层,网络层,传输层以及应用层。两者的区别在于 OSI 模型在应用层对数据包做了更细致的划分。两者的关系如下图所示:
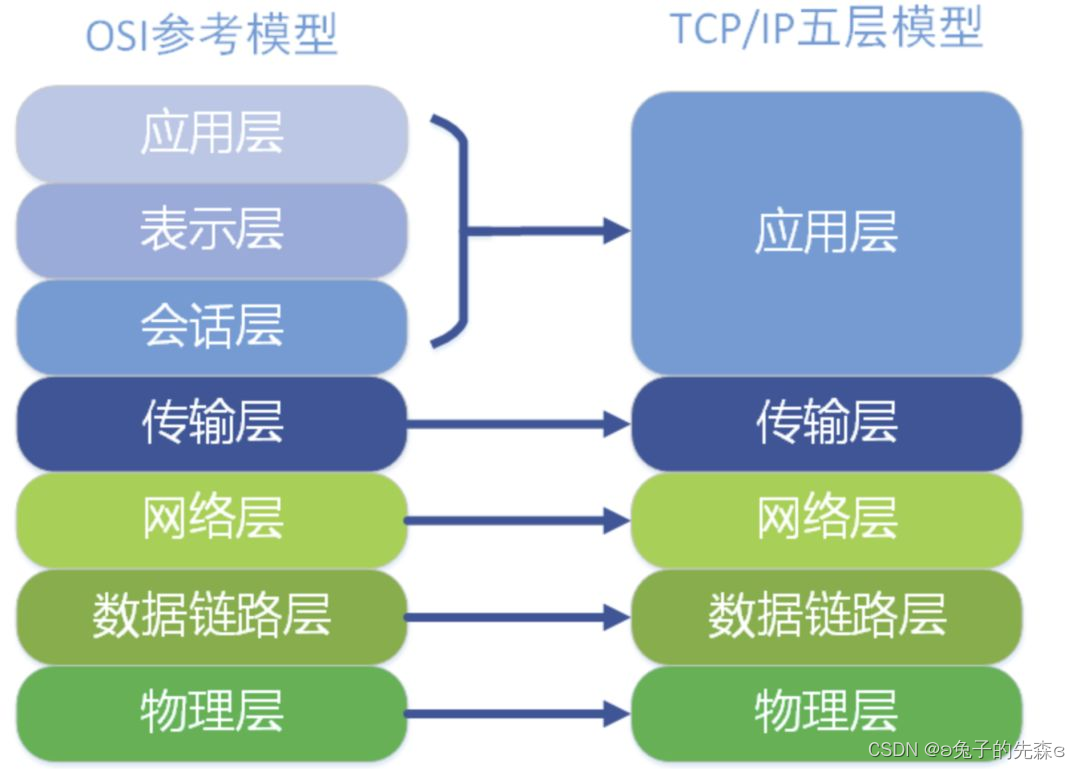 ??在 TCP/IP 协议框架体系的五层网络模型中,每一层负责处理的数据包协议或类型均存在差异,物理层主要负责在物理载体上的数据包传输,如 WiFi,以太网,光纤,电话线等;数据链路层主要负责链路层协议解析(主要为以太网帧,其他类型此处暂不考虑),网络层主要负责 IP 协议(包括 IPv4 和 IPv6)解析,传输层负责传输层协议解析(主要为 TCP,UDP 等),而传输层以上我们均归类为应用层,主要包括各类应用层协议,如我们常用的 HTTP,FTP,SMTP,DNS,DHCP 等。
??在 TCP/IP 协议框架体系的五层网络模型中,每一层负责处理的数据包协议或类型均存在差异,物理层主要负责在物理载体上的数据包传输,如 WiFi,以太网,光纤,电话线等;数据链路层主要负责链路层协议解析(主要为以太网帧,其他类型此处暂不考虑),网络层主要负责 IP 协议(包括 IPv4 和 IPv6)解析,传输层负责传输层协议解析(主要为 TCP,UDP 等),而传输层以上我们均归类为应用层,主要包括各类应用层协议,如我们常用的 HTTP,FTP,SMTP,DNS,DHCP 等。
??在 TCP/IP 协议框架体系内,下层协议对上层协议透明,即上层协议无需关注下层协议的实现逻辑和机制。
2.2 数据包协议分层
??在 TCP/IP 协议框架体系内,上层协议报文被作为下层协议的数据载荷(Data Payload),存储在下层协议的数据段区域中进行传输。结合这一特性,我们常见的几类网络协议嵌套关系如下图所示:
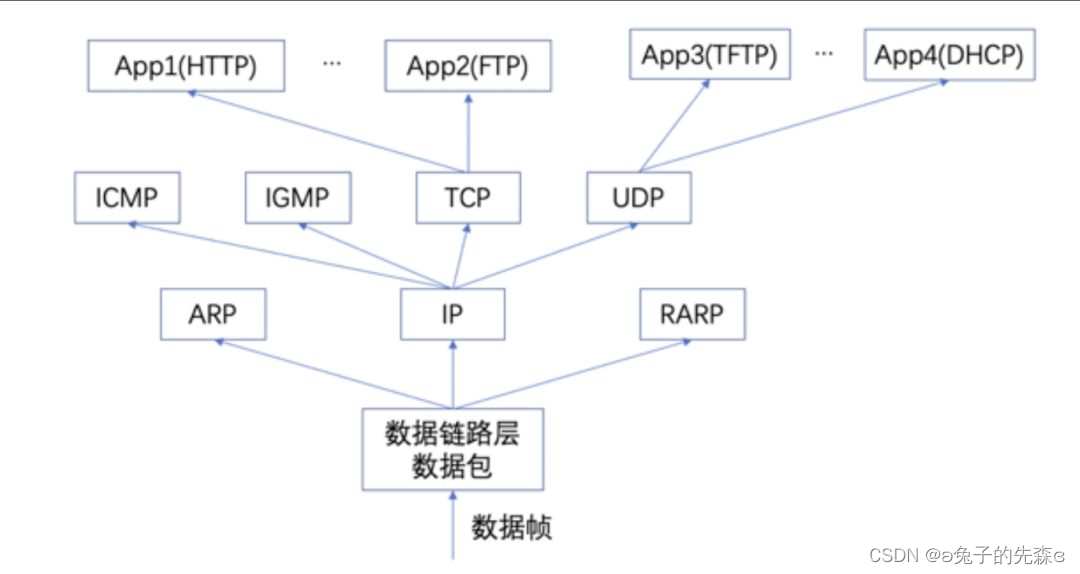 ??从上图我们可以清晰地看到各类协议之间的嵌套关系,如使用 HTTP 协议的应用 App1 在传输层封装在 TCP 协议中,TCP 协议在网络层又封装到 IP 协议中,最后交到数据链路层中。其他应用层 App 也类似。
??从上图我们可以清晰地看到各类协议之间的嵌套关系,如使用 HTTP 协议的应用 App1 在传输层封装在 TCP 协议中,TCP 协议在网络层又封装到 IP 协议中,最后交到数据链路层中。其他应用层 App 也类似。
??网际报文控制协议(ICMP,使用该协议的 Ping 工具),以及网际组管理协议(IGMP,组播多播中的控制报文)是直接嵌套到 IP 数据包中,而不依赖于 TCP 或 UDP。
??地址解析协议(ARP)和反解析协议(RARP)则是直接嵌套在数据链路层数据包中进行传输。
注:在本文中,我们只大概了解整体的网络框架,各协议的具体内容这里不做赘述。
2.3 sk_buff 结构
??在 Linux 内核中,系统使用 sk_buff 数据结构对数据包进行存储和管理。在数据包接收过程中,该数据结构从网卡驱动收包开始,一直贯穿到内核网络协议栈的顶层,直到用户态程序从内核获取数据。使用图形表示 sk_buff 的结构如下:
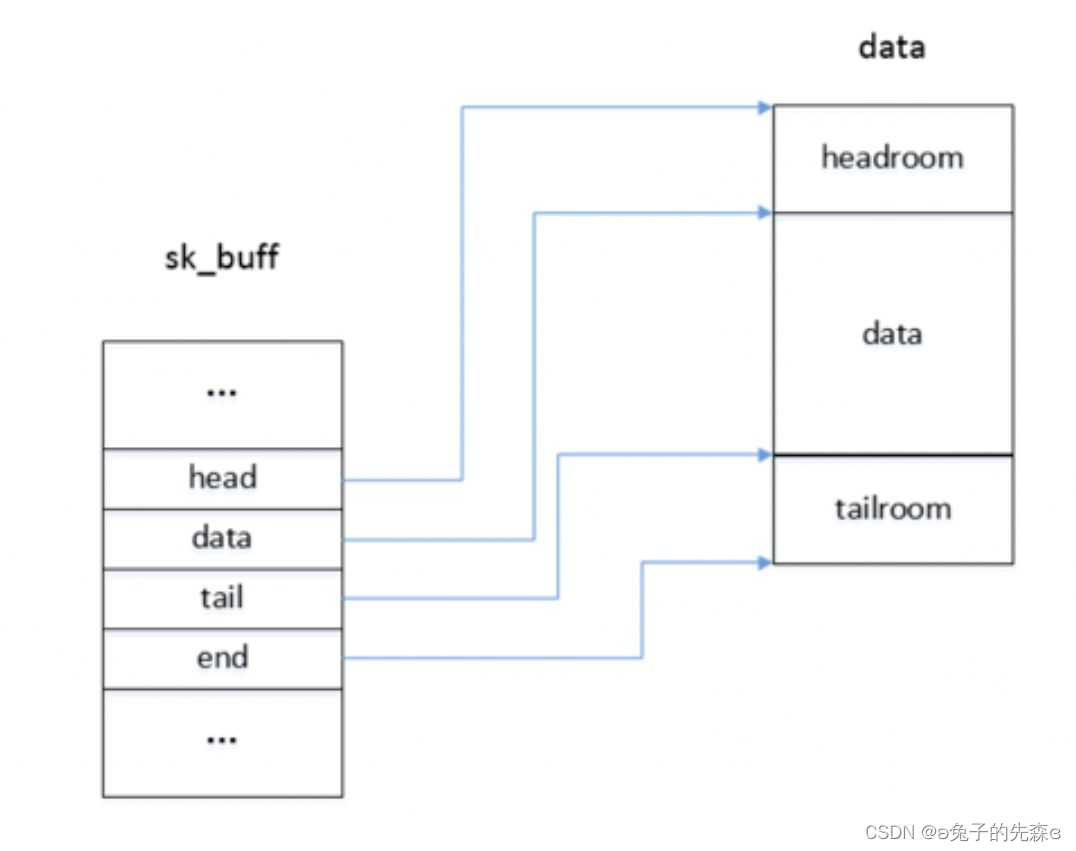 ??在 sk_buff 数据结构中包含了诸多关于数据包存储,定位和管理的指针,数据包在网络协议栈各层次之间进行传输的过程中,内核通过操作指针的方式对数据包进行逐层解析,避免频繁的大数据段拷贝操作,从而提高数据包处理效率(但在某些特殊情况下依然会采用数据包拷贝操作)。
??在 sk_buff 数据结构中包含了诸多关于数据包存储,定位和管理的指针,数据包在网络协议栈各层次之间进行传输的过程中,内核通过操作指针的方式对数据包进行逐层解析,避免频繁的大数据段拷贝操作,从而提高数据包处理效率(但在某些特殊情况下依然会采用数据包拷贝操作)。
2.4 收发包整体框架
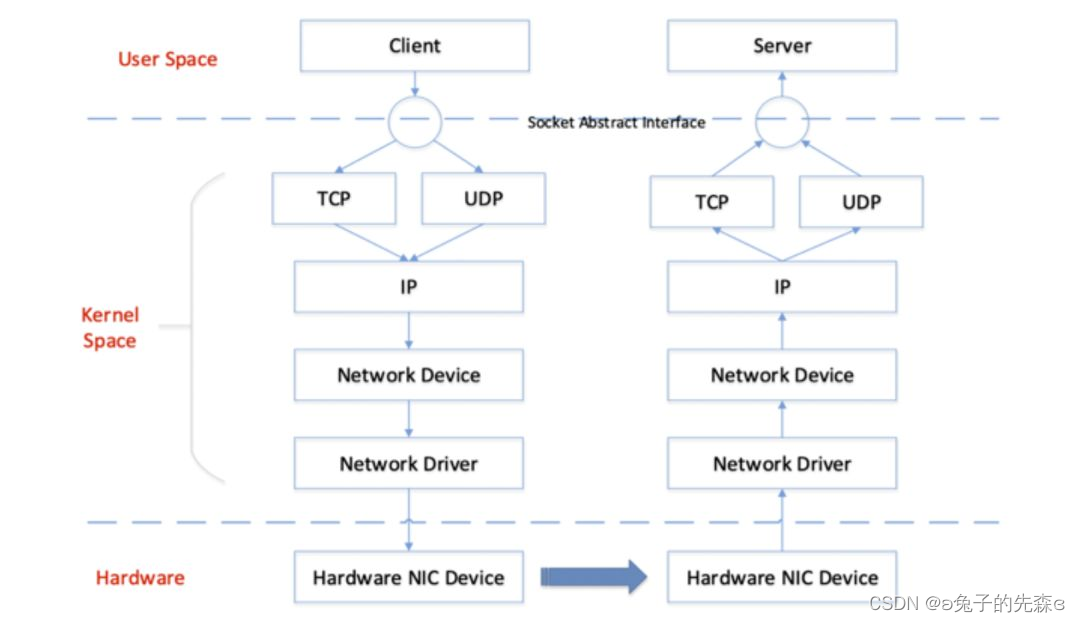
这里我们从客户端和服务端整体框架层面来看数据收发流程:
-
用户态(User Space)程序 Client 向另一台主机上的 Server 发送数据,需要通过调用内核态(Kernel Space)提供给用户态的 Socket 抽象层接口发送数据;
-
Socket 抽象层接口收到用户态数据后,向下交给传输层接口(TCP 或 UDP);
-
传输层负责创建 sk_buff,并将用户数据(应用层数据)填充到缓冲区,做合法性检查后,添加传输层头部,并通过网络层注册的接口将数据包交给网络层处理;
-
网络层收到传输层数据包后,会查询路由表,决定数据包去向,如果是需要发出的数据包,会填充网络层头部,并交到内核虚拟网络接口设备的发送队列中;
-
虚拟网络接口从发送队列获取数据,调用对应网卡驱动发送数据;
Server 端接收数据时,按照相反的过程从网卡驱动中将数据包一层层上交,直到通过 Socket 抽象层接口将用户数据上交到用户态 Server 进程处理。
3. 网络层(IPv4)收发包流程
数据包在实际现网传输过程中,会经过各类交换机,路由器的转发处理,在这个过程中,路由器一般只处理到网络层。这里我们仅对 Linux 内核中网络层接收,发送以及转发数据的流程进行简单介绍。
下图为基于 Linux 2.6.38 版本内核的网络层相关接口在数据包收发过程的调用逻辑图:
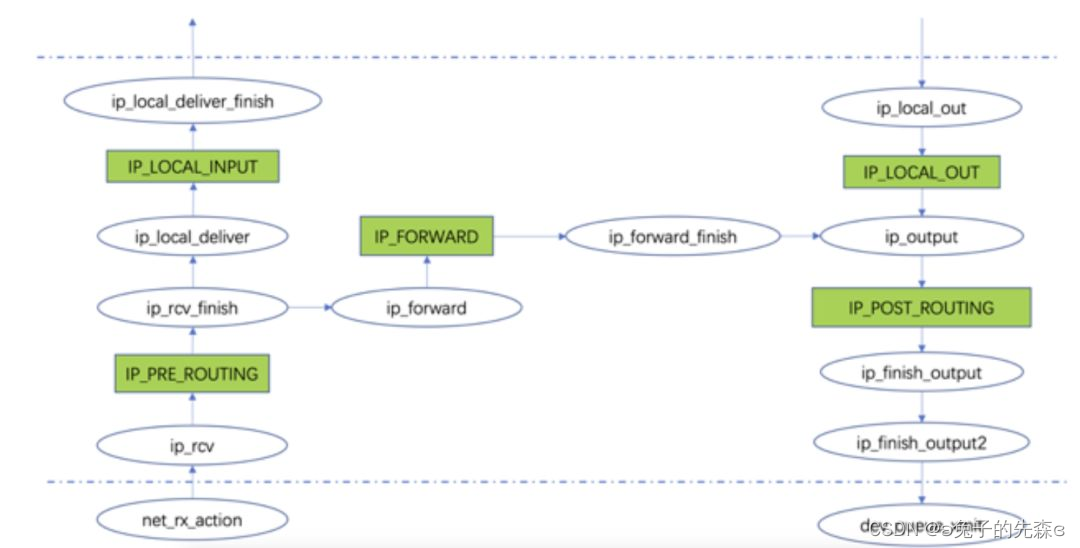 注:
注:
1)不同版本内核在函数名上可能存在一定差异,但整体调用逻辑基本不变;
2)该图仅展示 IPv4 的处理流程,IPv6 不在该图的函数中处理,但整体流程基本相似;
3)该图展示的流程仅为普通单播并且未进行 IP 分片的数据包处理流程,组播,多播,IP 分片的数据包在某些流程上存在差异;
-
从图中可以看到,ip_rcv函数为网络层向下层开放的入口,数据包通过该函数进入网络层进行处理,该函数主要对上传到网络层的数据包进行前期合法性检查,通过后交由 Netfilter 的钩子节点;
-
绿色方框内的IP_PRE_ROUTING为 Netfilter 框架的 Hook 点,该节点会根据预设的规则对数据包进行判决并根据判决结果做相关的处理,比如执行 NAT 转换;
-
IP_PRE_ROUTING节点处理完成后,数据包将交由ip_rcv_finish处理,该函数根据路由判决结果,决定数据包是交由本机上层应用处理,还是需要进行转发;如果是交由本机处理,则会交由ip_local_deliver走本地上交流程;如果需要转发,则交由ip_forward函数走转发流程;
-
在数据包上交本地的流程中,IP_LOCAL_INPUT节点用于监控和检查上交到本地上层应用的数据包,该节点是 Linux 防火墙的重要生效节点之一;
-
在数据包转发流程中,Netfilter 框架的IP_FORWARD节点会对转发数据包进行检查过滤;
-
而对于本机上层发出的数据包,网络层通过注册到上层的ip_local_out函数接收数据处理,处理 OK 进一步交由IP_LOCAL_OUT节点检测;
-
对于即将发往下层的数据包,需要经过IP_POST_ROUTING节点处理;网络层处理结束,通过dev_queue_xmit函数将数据包交由 Linux 内核中虚拟网络设备做进一步处理,从这里数据包即离开网络层进入到下一层;
4. Netfilter 框架
??Netfilter 是 Linux 内核中进行数据包过滤,连接跟踪(Connect Track),网络地址转换(NAT)等功能的主要实现框架;该框架在网络协议栈处理数据包的关键流程中定义了一系列钩子点(Hook 点),并在这些钩子点中注册一系列函数对数据包进行处理。这些注册在钩子点的函数即为设置在网络协议栈内的数据包通行策略,也就意味着,这些函数可以决定内核是接受还是丢弃某个数据包,换句话说,这些函数的处理结果决定了这些网络数据包的“命运”。
下图为 Netfilter 框架的整体组件图:
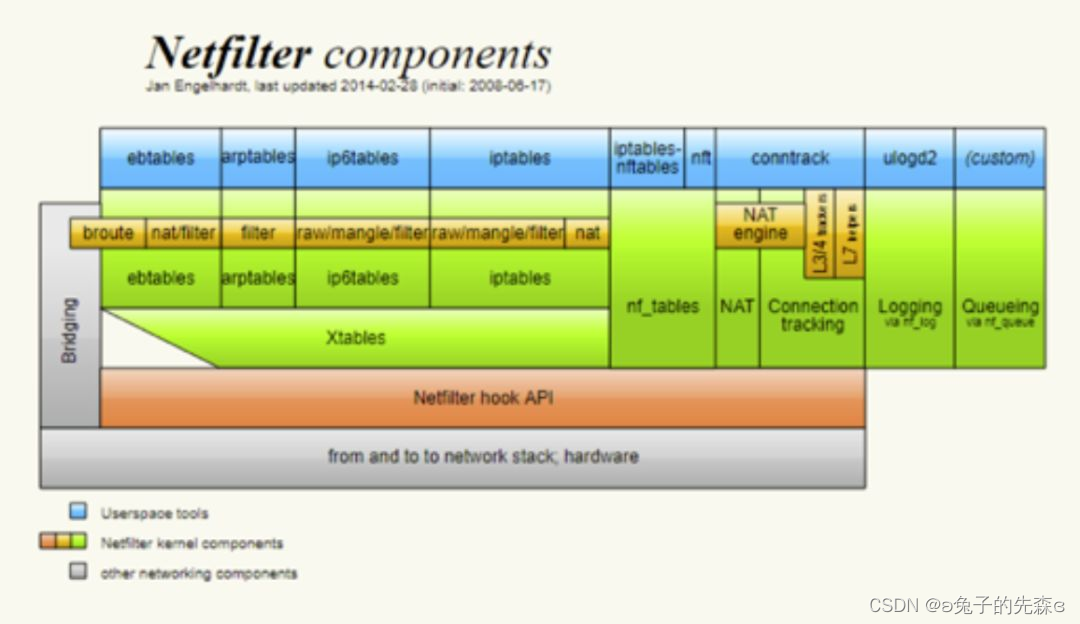 从图中我们可以看到,Netfilter 框架采用模块化设计理念,并且贯穿了 Linux 系统的内核态和用户态。在用户态层面,根据不同的协议类型,为上层用户提供了不同的系统调用工具,比如我们常用的针对 IPv4 协议 iptables,IPv6 协议的 ip6tables,针对 ARP 协议的 arptables,针对网桥控制的 ebtables,针对网络连接追踪的 conntrack 等等。不同的用户态工具在内核中有对应的模块进行实现,而底层都需要调用 Netfilter hook API 接口进行实现。
从图中我们可以看到,Netfilter 框架采用模块化设计理念,并且贯穿了 Linux 系统的内核态和用户态。在用户态层面,根据不同的协议类型,为上层用户提供了不同的系统调用工具,比如我们常用的针对 IPv4 协议 iptables,IPv6 协议的 ip6tables,针对 ARP 协议的 arptables,针对网桥控制的 ebtables,针对网络连接追踪的 conntrack 等等。不同的用户态工具在内核中有对应的模块进行实现,而底层都需要调用 Netfilter hook API 接口进行实现。
从图中我们可以看到,我们常用的 Linux 防火墙工具 iptables 其实也是 Netfilter 框架中的一个组件。接下来我们就以 IPv4 为例,描述 iptables 在 Netfilter 框架中生效的基本原理,同时,我们也看一下如果我们希望在内核中添加我们自己的处理函数,我们该怎么做。
4.1 IPv4 网络层的 Netfilter Hook 点
在第二章已经提及,Linux 内核中,Netfiler 在网络层设置了多个 Hook 点,这里我们不考虑实际的处理函数,仅看 Netfilter 的钩子节点,从而将网络层处理流程进行简化,如下图:
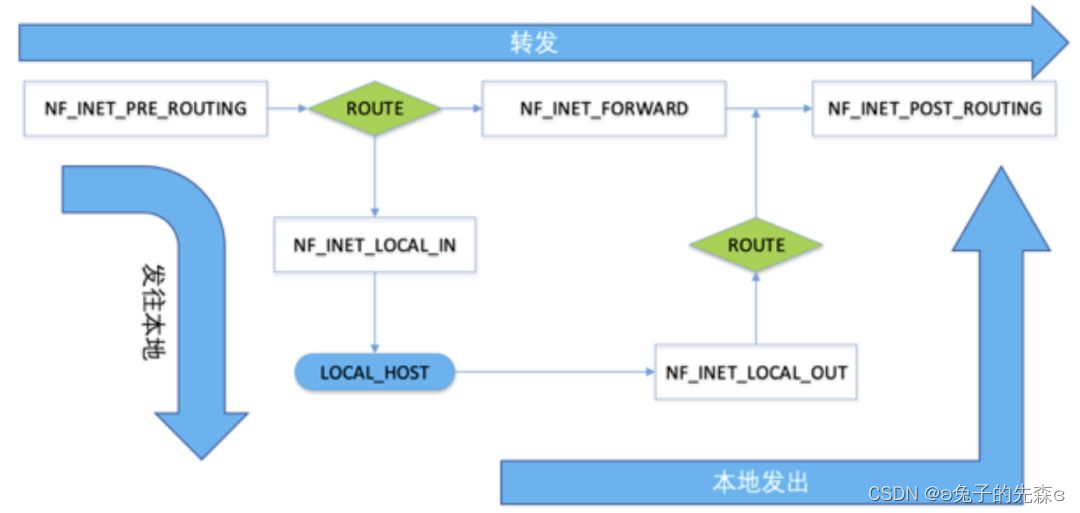 其中,矩形方框中的即为 Netfilter 的钩子节点。从图中可以看到,三个方向的数据包需要经过的钩子节点不完全相同:
其中,矩形方框中的即为 Netfilter 的钩子节点。从图中可以看到,三个方向的数据包需要经过的钩子节点不完全相同:
-
发往本地:NF_INET_PRE_ROUTING–>NF_INET_LOCAL_IN
-
转发:NF_INET_PRE_ROUTING–>NF_INET_FORWARD–>NF_INET_POST_ROUTING
-
本地发出:NF_INET_LOCAL_OUT–>NF_INET_POST_ROUTING
4.2 iptables 工具
iptables 在用户态提供了表格和链的概念。包含的表格有 filter,nat,mangle 以及 raw。而每个表格下包含不同的链,如下图所示: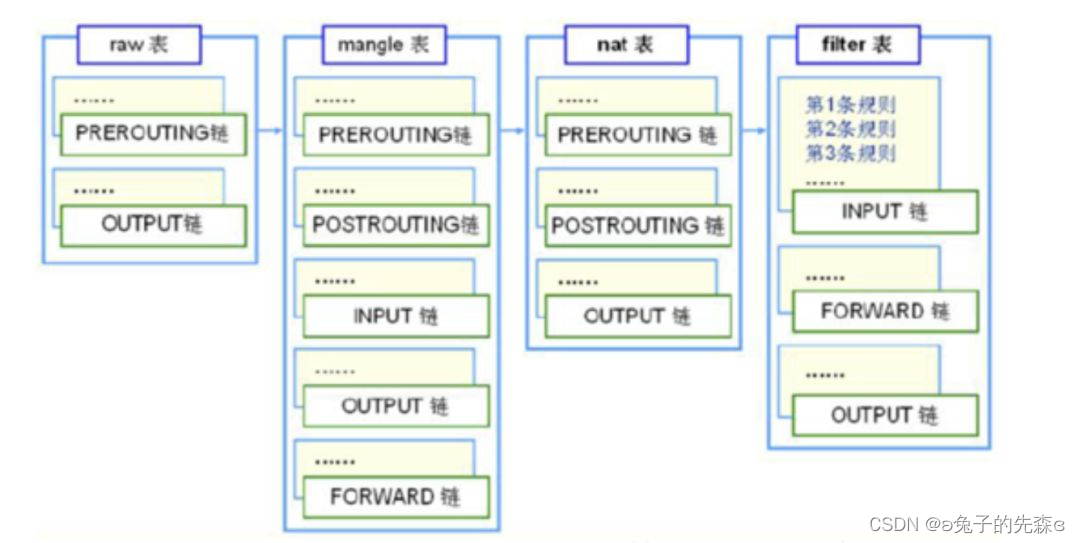 ptables 中每个表格的作用不同,以我们比较常用的 filter 表为例,其主要起到数据包过滤和拦截作用,包含 INPUT,FORWARD 和 OUTPUT 三个链,根据链的名字我们可以知道,这三个链分别被放置到 Netfilter 三个不同的钩子节点中生效。INPUT 链是在NF_INET_LOCAL_IN节点,FORWARD 链是在NF_INET_FORWARD节点,OUTPUT 链则是在NF_INET_LOCAL_OUT节点。其他表格的链也类似。
ptables 中每个表格的作用不同,以我们比较常用的 filter 表为例,其主要起到数据包过滤和拦截作用,包含 INPUT,FORWARD 和 OUTPUT 三个链,根据链的名字我们可以知道,这三个链分别被放置到 Netfilter 三个不同的钩子节点中生效。INPUT 链是在NF_INET_LOCAL_IN节点,FORWARD 链是在NF_INET_FORWARD节点,OUTPUT 链则是在NF_INET_LOCAL_OUT节点。其他表格的链也类似。
以如下 iptables 指令为例:
iptables -t filter -A INPUT -s 172.16.0.0/16 -p udp --dport 53 -j DROP
该指令是在 filter 表的 INPUT 链中添加一条过滤规则,凡是收到源地址为 172.16.0.0/16,传输层协议为 UDP 并且目的端口为 53 的数据包(即 DNS 数据包),都将该数据包丢弃。在 Linux 内核中,这一个指令会在 Netfilter 网络层NF_INET_LOCAL_IN节点生成处理操作,凡是经过这个钩子节点的数据包,在前面规则都通过的情况下,都必须经过这一规则的检查,如果符合这条规则的匹配条件,则该数据包会被丢弃;如果不符合,则进行下一条规则的匹配。
在 Linux 内核内部,使用 iptables 工具下发的指令规则,会存储在内核中的 Xtables 模块中,这部分内容这里不再深入分析。
4.3 Netfilter 重要数据结构及相关函数
- 钩子点枚举类型
上面提到的网络层中 Netfilter 的几个钩子节点,在内核中是以枚举数据类型进行标记的。如下:
// include/linux/netfilter.h
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};
- 注册和解注册钩子函数
// include/linux/netfilter.h
/* Function to register/unregister hook points. */
int nf_register_hook(struct nf_hook_ops *reg);
void nf_unregister_hook(struct nf_hook_ops *reg);
int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n);
void nf_unregister_hooks(struct nf_hook_ops *reg, unsigned int n);
这些函数用于将自定义的钩子操作(struct nf_hook_ops)注册到指定的钩子节点中。
- 钩子操作数据结构
// include/linux/netfilter.h
struct nf_hook_ops {
struct list_head list;
/* User fills in from here down. */
nf_hookfn *hook;
struct module *owner;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
这个结构体中存储了自定义的钩子函数(nf_hookfn),函数优先级(priority),处理协议类型(pf),钩子函数生效的钩子节点(hooknum)等信息。
- 钩子函数声明
// include/linux/netfilter.h
typedef unsigned int nf_hookfn(unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *));
如果我们自己实现一个内核模块,该模块需要在 Netfilter 框架的几个钩子节点中对经过的数据包进行处理,则该内核模块需要向 Netfilter 中的钩子节点注册钩子函数,我们需要按照 nf_hookfn 函数的声明类型,提供我们自己的实现,再按照之前提供的注册接口将相关数据类型注册到内核中使之生效。
4.4 一个 Demo
如下为在网络上找到的一个内核模块 Demo,该模块的基本功能是将经过 IPv4 网络层 NF_INET_LOCAL_IN 节点的数据包的源 Mac 地址,目的 Mac 地址以及源 IP,目的 IP 打印出来。代码如下所示:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/types.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/tcp.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
MODULE_LICENSE("GPLv3");
MODULE_AUTHOR("SHI");
MODULE_DESCRIPTION("Netfliter test");
static unsigned int
nf_test_in_hook(unsigned int hook, struct sk_buff *skb, const struct net_device *in,
const struct net_device *out, int (*okfn)(struct sk_buff*));
static struct nf_hook_ops nf_test_ops[] __read_mostly = {
{
.hook = nf_test_in_hook,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_FIRST,
},
};
void hdr_dump(struct ethhdr *ehdr) {
printk("[MAC_DES:%x,%x,%x,%x,%x,%x"
"MAC_SRC: %x,%x,%x,%x,%x,%x Prot:%x]\n",
ehdr->h_dest[0],ehdr->h_dest[1],ehdr->h_dest[2],ehdr->h_dest[3],
ehdr->h_dest[4],ehdr->h_dest[5],ehdr->h_source[0],ehdr->h_source[1],
ehdr->h_source[2],ehdr->h_source[3],ehdr->h_source[4],
ehdr->h_source[5],ehdr->h_proto);
}
#define NIPQUAD(addr) \
((unsigned char *)&addr)[0], \
((unsigned char *)&addr)[1], \
((unsigned char *)&addr)[2], \
((unsigned char *)&addr)[3]
#define NIPQUAD_FMT "%u.%u.%u.%u"
static unsigned int
nf_test_in_hook(unsigned int hook, struct sk_buff *skb, const struct net_device *in,
const struct net_device *out, int (*okfn)(struct sk_buff*)) {
struct ethhdr *eth_header;
struct iphdr *ip_header;
eth_header = (struct ethhdr *)(skb_mac_header(skb));
ip_header = (struct iphdr *)(skb_network_header(skb));
hdr_dump(eth_header);
printk("src IP:'"NIPQUAD_FMT"', dst IP:'"NIPQUAD_FMT"' \n",
NIPQUAD(ip_header->saddr), NIPQUAD(ip_header->daddr));
return NF_ACCEPT;
}
static int __init init_nf_test(void) {
int ret;
ret = nf_register_hooks(nf_test_ops, ARRAY_SIZE(nf_test_ops));
if (ret < 0) {
printk("register nf hook fail\n");
return ret;
}
printk(KERN_NOTICE "register nf test hook\n");
return 0;
}
static void __exit exit_nf_test(void) {
nf_unregister_hooks(nf_test_ops, ARRAY_SIZE(nf_test_ops));
}
module_init(init_nf_test);
module_exit(exit_nf_test);
这个 Demo 程序是个内核模块,模块入口为module_init传入的init_nf_test函数。
在init_nf_test函数中,其通过 Netfilter 提供的 nf_register_hooks 接口将自定义的nf_test_opt注册到钩子节点中。nf_test_opt为struct nf_hook_ops类型的结构体数组,其内部包含了所有关键元素,比如钩子函数的注册节点(此处为NF_INET_LOCAL_IN)以及钩子函数(nf_test_in_hook)。
在nf_test_in_hook函数内部,其检查每一个传递过来的数据包,并将其源 Mac 地址,目的 Mac 地址,源 IP 地址以及目的 IP 地址打印出来。最后返回NF_ACCEPT,将数据包交给下一个钩子函数处理。
4.5 NAT 和 conntrack
NAT(Network Address Translation)技术现如今被广泛应用于路由器等网络设备中,其在解决 IPv4 地址紧缺的问题上起到了至关重要的作用,但与此同时也存在一定的安全隐患。
而 conntrack(连接追踪)也是广泛应用于路由器网络设备中的模块,其根据数据包的五元组以及 NAT 的转换结果,记录每一条连接的状态,在提升设备转发效率上起到了很大的作用,但另一方面,记录连接信息需要消耗一部分资源,也会导致设备出现性能瓶颈。
5. 总结
Linux 网络协议栈是 Linux 内核中非常重要的子系统之一,虽然上层应用的开发维护工作极少涉及修改内核网络部分的工作,但了解其设计思想,基本工作原理,也可以为我们日常工作带来比较不少的帮助,特别是涉及到前后台网络交互,服务器网络性能相关的工作时。
这篇文章所涉及的内容也仅仅是 Linux 网络协议栈中网络层的极小一部分,如下为 Linux 内核中数据包流向的整体脉络图以及 Netfilter 的整体生效节点:
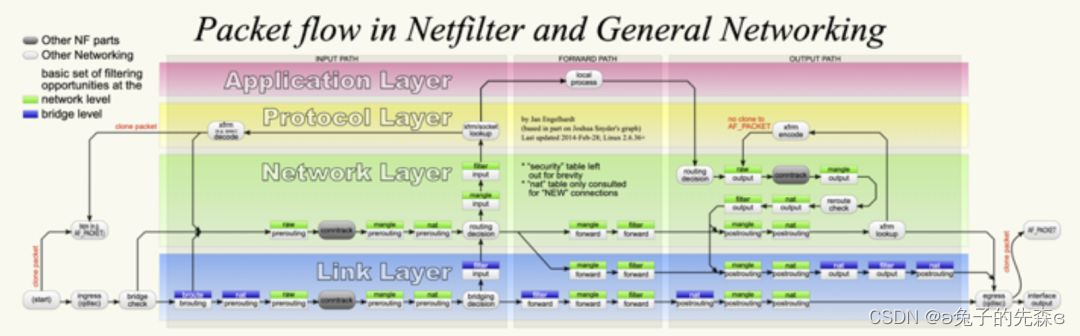 从上图可以看到,除了在网络层,链路层中 Netfilter 也被广泛地应用,ebtables 是 Netfilter 提供给用户态的链路层配置接口(工具),其生效机制与 iptables 基本类似。
从上图可以看到,除了在网络层,链路层中 Netfilter 也被广泛地应用,ebtables 是 Netfilter 提供给用户态的链路层配置接口(工具),其生效机制与 iptables 基本类似。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!