《面向复杂仿真元建模的序贯近邻探索实验设计方法》论文复现
发布时间:2023年12月29日

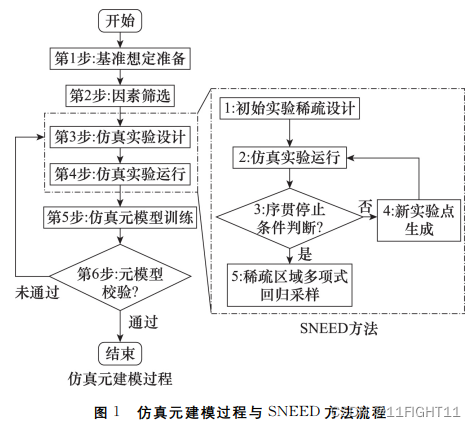
# peaks函数热力图
from matplotlib import pyplot as plot
import numpy as np
import math
from mpl_toolkits.mplot3d import Axes3D
#python绘图显示中文
plot.rcParams['font.sans-serif']=['SimHei']
plot.rcParams['axes.unicode_minus'] = False
#创建画布
fig = plot.figure(figsize=(16,4))
#axes = Axes3D(figure)
# X=差值,Y=距离,Z概率
#生成x,y
X1 = np.arange(-10,5,0.05)
Y1 = np.arange(-5,10,0.05)#前两个参数为自变量取值范围
X1,Y1 = np.meshgrid(X1,Y1)
#peaks1
#z关于x,y的函数关系式,生成z
#Z1 = (5 * ((1 - X1) ** 2)) * (np.exp((-(X1 ** 2)) - ((Y1 + 1) ** 2)))
#Z2 = (5 * ((X1 / 5) - (Y1 ** 5))) * (np.exp(-(X1 ** 2) - (Y1 ** 2)))
#Z3 = 6 * (np.exp(-((X1 + 1) ** 2) - (Y1 ** 2)))
#Z1 = Z1 - Z2 - Z3
Z1 = 5*(1-X1)**2*(np.exp(-X1**2-(Y1+1)**2))-5*(X1/5-Y1**5)*(np.exp(-X1**2-Y1**2))-6*(np.exp(-(X1+1)**2-Y1**2))
#绘制模型
#子图13d坐标系建立
axes1=fig.add_subplot(121,projection='3d')
axes1.plot_surface(X1,Y1,Z1,cmap='rainbow')
#axes1.contourf(X1,Y1,Z1,zdir='z',offset=-2,cmap='rainbow')
#axes1.set(facecolor = "white")
axes1.set_xlabel('X')
axes1.set_ylabel('Y')
axes1.set_zlabel('Z')
#axes1.view_init(5,-75)#坐标系旋转,高程(XY平面上方60度),方位角(绕Z轴逆时针旋转度数)
axes2=fig.add_subplot(122)
plot.pcolor(X1,Y1,Z1,cmap ="rainbow")
axes2.set_xlabel('X')
axes2.set_ylabel('Y')
plot.show()
#创建画布
fig = plot.figure(figsize=(16,4))
#peaks2
z1=10*(X1+3)**2*np.exp(-(X1+5)**2-(Y1-5)**2)
z2=8*(X1/5-5*Y1)*np.exp(-(X1**2+Y1**2)/4)
z3=8*np.exp(-(6*X1+1)**2-(3*Y1)**2)
Z2 =z1-z2+z3
#绘制模型
#子图13d坐标系建立
axes1=fig.add_subplot(121,projection='3d')
axes1.plot_surface(X1,Y1,Z2,cmap='rainbow')
#axes1.contourf(X1,Y1,Z1,zdir='z',offset=-2,cmap='rainbow')
#axes1.set(facecolor = "white")
axes1.set_xlabel('X')
axes1.set_ylabel('Y')
axes1.set_zlabel('Z')
#axes1.view_init(-10,0)#坐标系旋转,高程(XY平面上方60度),方位角(绕Z轴逆时针旋转度数)
axes2=fig.add_subplot(122)
plot.pcolor(X1,Y1,Z2,cmap ="rainbow")
axes2.set_xlabel('X')
axes2.set_ylabel('Y')
plot.show()
#1.图1结果和原图不一致
from matplotlib import pyplot as plot
import numpy as np
import math
from mpl_toolkits.mplot3d import Axes3D
#python绘图显示中文
plot.rcParams['font.sans-serif']=['SimHei']
plot.rcParams['axes.unicode_minus'] = False
#创建画布
fig = plot.figure(figsize=(16,4))
#子图13d坐标系建立
axes1=fig.add_subplot(121,projection='3d')
#axes = Axes3D(figure)
# X=差值,Y=距离,Z概率
#生成x,y
X = np.arange(0,1,0.1)
Y = np.arange(0,2**0.5,0.1)#前两个参数为自变量取值范围
x=[math.pow(i,2) for i in X]
y=[math.pow(i,2) for i in Y]
X,Y = np.meshgrid(X,Y)
#生成z
#Z = (X**2+Y**2)/2*(2/math.pi*(np.arctan(X/Y)))**2 #z关于x,y的函数关系式,
Z1=(X**2+Y**2)/3
Z2=2/math.pi
Z3=Z2*(np.arctan(X/Y))
Z=Z1*(Z3**2)
#绘制模型
axes1.plot_surface(X,Y,Z,cmap='rainbow')
#axes1.contourf(X,Y,Z,zdir='z',offset=-2,cmap='rainbow')
axes1.set(facecolor = "white")
axes1.set_xlabel('X:差值')
axes1.set_ylabel('Y:距离')
axes1.set_zlabel('Z:概率')
axes1.view_init(30, -130)#坐标系旋转
#原论文图1中X>0,Y>0
# X^2=差值,Y^2=距离,Z概率
axes2=fig.add_subplot(122,projection='3d')
X1,Y1 = np.meshgrid(x,y)
Z1 = (X1+Y1)/3*(2/math.pi*np.arctan(np.sqrt(X1/Y1)))**2 #z关于x,y的函数关系式,此处为锥面
axes2.plot_surface(X1,Y1,Z1,cmap='rainbow')
#axes2.patch.set_facecolor('blue')
axes2.set_xlabel('X:差值平方')
axes2.set_ylabel('Y:距离平方')
axes2.set_zlabel('Z:概率')
axes2.view_init(30, -130)
plot.show()
import numpy as np
import time
from matplotlib import pyplot as plot
import numpy as np
import math
from mpl_toolkits.mplot3d import Axes3D
import random
import os
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, ward
# 现在为包含簇之间距离的linkage_array绘制树状图
from sklearn.cluster import AgglomerativeClustering
seed=13
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED']=str(seed)
x=np.linspace(-12,4,num=11)
y=np.linspace(-6,10,num=11)
X=[]
Y=[]
for i in range(len(x)-1):
xi=random.uniform(x[i],x[i+1])
X.append(xi)
for i in range(len(y)-1):
yi=random.uniform(y[i],y[i+1])
Y.append(yi)
#print(X)
#print(len(X))
X,Y = np.meshgrid(X,Y)
Z = 5*(1-X)**2*(np.exp(-X**2-(Y+1)**2))-5*(X/5-Y**5)*(np.exp(-X**2-Y**2))-6*(np.exp(-(X+1)**2-Y**2))
Z1 = Z.ravel()
Z1=np.array(Z1)
Z1=np.array(Z1).reshape(-1, 1)
print(len(Z1))
fig =plot.figure(figsize=(30,24))
ax1=fig.add_subplot(331)
ax1.grid()
ax1.scatter(X,Y)
ax2=fig.add_subplot(332,projection='3d')
ax2.plot_surface(X,Y,Z,cmap='rainbow')
ax2.set_xlabel('X')
ax2.set_ylabel('Y')
ax2.set_zlabel('Z')
X1 = X.ravel()
X1=np.array(X1)
X1=np.array(X1).reshape(-1, 1)
Y1 = Y.ravel()
Y1=np.array(Y1)
Y1=np.array(Y1).reshape(-1, 1)
samplesxy=np.hstack((X1,Y1))
samples=np.hstack((X1,Y1,Z1))
class Node(object):
'''结点对象'''
def __init__(self, item=None, label=None, dim=None, parent=None, left_child=None, right_child=None):
self.item = item # 结点的值(样本信息)
self.label = label # 结点的标签
self.dim = dim # 结点的切分的维度(特征)
self.parent = parent # 父结点
self.left_child = left_child # 左子树
self.right_child = right_child # 右子树
class KDTree(object):
'''kd树'''
def __init__(self, aList, labelList):
self.__length = 0 # 不可修改
self.__root = self.__create(aList,labelList) # 根结点, 私有属性, 不可修改
def __create(self, aList, labelList, parentNode=None):
'''
创建kd树
:param aList: 需要传入一个类数组对象(行数表示样本数,列数表示特征数)
:labellist: 样本的标签
:parentNode: 父结点
:return: 根结点
'''
dataArray = np.array(aList)
m,n = dataArray.shape
labelArray = np.array(labelList).reshape(m,1)
if m == 0: # 样本集为空
return None
# 求所有特征的方差,选择最大的那个特征作为切分超平面
var_list = [np.var(dataArray[:,col]) for col in range(n)] # 获取每一个特征的方差
max_index = var_list.index(max(var_list)) # 获取最大方差特征的索引
# 样本按最大方差特征进行升序排序后,取出位于中间的样本
max_feat_ind_list = dataArray[:,max_index].argsort()
mid_item_index = max_feat_ind_list[m // 2]
if m == 1: # 样本为1时,返回自身
self.__length += 1
return Node(dim=max_index,label=labelArray[mid_item_index], item=dataArray[mid_item_index], parent=parentNode, left_child=None, right_child=None)
# 生成结点
node = Node(dim=max_index, label=labelArray[mid_item_index], item=dataArray[mid_item_index], parent=parentNode, )
# 构建有序的子树
left_tree = dataArray[max_feat_ind_list[:m // 2]] # 左子树
left_label = labelArray[max_feat_ind_list[:m // 2]] # 左子树标签
left_child = self.__create(left_tree,left_label,node)
if m == 2: # 只有左子树,无右子树
right_child = None
else:
right_tree = dataArray[max_feat_ind_list[m // 2 + 1:]] # 右子树
right_label = labelArray[max_feat_ind_list[m // 2 + 1:]] # 右子树标签
right_child = self.__create(right_tree,right_label,node)
# self.__length += 1
# 左右子树递归调用自己,返回子树根结点
node.left_child=left_child
node.right_child=right_child
self.__length += 1
return node
@property
def length(self):
return self.__length
@property
def root(self):
return self.__root
def transfer_dict(self,node):
'''
查看kd树结构
:node:需要传入根结点对象
:return: 字典嵌套格式的kd树,字典的key是self.item,其余项作为key的值,类似下面格式
{(1,2,3):{
'label':1,
'dim':0,
'left_child':{(2,3,4):{
'label':1,
'dim':1,
'left_child':None,
'right_child':None
},
'right_child':{(4,5,6):{
'label':1,
'dim':1,
'left_child':None,
'right_child':None
}
}
'''
if node == None:
return None
kd_dict = {}
kd_dict[tuple(node.item)] = {} # 将自身值作为key
kd_dict[tuple(node.item)]['label'] = node.label[0]
kd_dict[tuple(node.item)]['dim'] = node.dim
kd_dict[tuple(node.item)]['parent'] = tuple(node.parent.item) if node.parent else None
kd_dict[tuple(node.item)]['left_child'] = self.transfer_dict(node.left_child)
kd_dict[tuple(node.item)]['right_child'] = self.transfer_dict(node.right_child)
return kd_dict
def transfer_list(self,node, kdList=[]):
'''
将kd树转化为嵌套字典的列表输出
:param node: 需要传入根结点
:return: 返回嵌套字典的列表,格式如下
[{'item': (9, 3),
'label': 1,
'dim': 0,
'parent': None,
'left_child': (3, 4),
'right_child': (11, 11)
},
{'item': (3, 4),
'label': 1,
'dim': 1,
'parent': (9, 3),
'left_child': (7, 0),
'right_child': (3, 15)
}]
'''
if node == None:
return None
element_dict = {}
element_dict['item'] = tuple(node.item)
element_dict['label'] = node.label[0]
element_dict['dim'] = node.dim
element_dict['parent'] = tuple(node.parent.item) if node.parent else None
element_dict['left_child'] = tuple(node.left_child.item) if node.left_child else None
element_dict['right_child'] = tuple(node.right_child.item) if node.right_child else None
kdList.append(element_dict)
self.transfer_list(node.left_child, kdList)
self.transfer_list(node.right_child, kdList)
return kdList
def _find_nearest_neighbour(self, item):
'''
找最近邻点
:param item:需要预测的新样本
:return: 距离最近的样本点
'''
itemArray = np.array(item)
if self.length == 0: # 空kd树
return None
# 递归找离测试点最近的那个叶结点
node = self.__root
if self.length == 1: # 只有一个样本
return node
while True:
cur_dim = node.dim
if item[cur_dim] == node.item[cur_dim]:
return node
elif item[cur_dim] < node.item[cur_dim]: # 进入左子树
if node.left_child == None: # 左子树为空,返回自身
return node
node = node.left_child
else:
if node.right_child == None: # 右子树为空,返回自身
return node
node = node.right_child
def knn_algo(self, item, k=1):
'''
找到距离测试样本最近的前k个样本
:param item: 测试样本
:param k: knn算法参数,定义需要参考的最近点数量,一般为1-5
:return: 返回前k个样本的最大分类标签
'''
if self.length <= k:
label_dict = {}
# 获取所有label的数量
for element in self.transfer_list(self.root):
if element['label'] in label_dict:
label_dict[element['label']] += 1
else:
label_dict[element['label']] = 1
sorted_label = sorted(label_dict.items(), key=lambda item:item[1],reverse=True) # 给标签排序
return sorted_label[0][0]
item = np.array(item)
node = self._find_nearest_neighbour(item) # 找到最近的那个结点
if node == None: # 空树
return None
# print('靠近点%s最近的叶结点为:%s'%(item, node.item))
node_list = []
distance = np.sqrt(sum((item-node.item)**2)) # 测试点与最近点之间的距离
least_dis = distance
# 返回上一个父结点,判断以测试点为圆心,distance为半径的圆是否与父结点分隔超平面相交,若相交,则说明父结点的另一个子树可能存在更近的点
node_list.append([distance, tuple(node.item), node.label[0]]) # 需要将距离与结点一起保存起来
# 若最近的结点不是叶结点,则说明,它还有左子树
if node.left_child != None:
left_child = node.left_child
left_dis = np.sqrt(sum((item-left_child.item)**2))
if k > len(node_list) or least_dis < least_dis:
node_list.append([left_dis, tuple(left_child.item), left_child.label[0]])
node_list.sort() # 对结点列表按距离排序
least_dis = node_list[-1][0] if k >= len(node_list) else node_list[k-1][0]
# 回到父结点
while True:
if node == self.root: # 已经回到kd树的根结点
break
parent = node.parent
# 计算测试点与父结点的距离,与上面距离做比较
par_dis = np.sqrt(sum((item-parent.item)**2))
if k >len(node_list) or par_dis < least_dis: # k大于结点数或者父结点距离小于结点列表中最大的距离
node_list.append([par_dis, tuple(parent.item) , parent.label[0]])
node_list.sort() # 对结点列表按距离排序
least_dis = node_list[-1][0] if k >= len(node_list) else node_list[k - 1][0]
# 判断父结点的另一个子树与结点列表中最大的距离构成的圆是否有交集
if k >len(node_list) or abs(item[parent.dim] - parent.item[parent.dim]) < least_dis : # 说明父结点的另一个子树与圆有交集
# 说明父结点的另一子树区域与圆有交集
other_child = parent.left_child if parent.left_child != node else parent.right_child # 找另一个子树
# 测试点在该子结点超平面的左侧
if other_child != None:
if item[parent.dim] - parent.item[parent.dim] <= 0:
self.left_search(item,other_child,node_list,k)
else:
self.right_search(item,other_child,node_list,k) # 测试点在该子结点平面的右侧
node = parent # 否则继续返回上一层
# 接下来取出前k个元素中最大的分类标签
label_dict = {}
node_list = node_list[:k]
# 获取所有label的数量
for element in node_list:
if element[2] in label_dict:
label_dict[element[2]] += 1
else:
label_dict[element[2]] = 1
sorted_label = sorted(label_dict.items(), key=lambda item:item[1], reverse=True) # 给标签排序
return sorted_label[0][0],node_list
def left_search(self, item, node, nodeList, k):
'''
按左中右顺序遍历子树结点,返回结点列表
:param node: 子树结点
:param item: 传入的测试样本
:param nodeList: 结点列表
:param k: 搜索比较的结点数量
:return: 结点列表
'''
nodeList.sort() # 对结点列表按距离排序
least_dis = nodeList[-1][0] if k >= len(nodeList) else nodeList[k - 1][0]
if node.left_child == None and node.right_child == None: # 叶结点
dis = np.sqrt(sum((item - node.item) ** 2))
if k > len(nodeList) or dis < least_dis:
nodeList.append([dis, tuple(node.item), node.label[0]])
#nodeList.append([list(node.item), node.label[0]])
return
self.left_search(item, node.left_child, nodeList, k)
# 每次进行比较前都更新nodelist数据
nodeList.sort() # 对结点列表按距离排序
least_dis = nodeList[-1][0] if k >= len(nodeList) else nodeList[k - 1][0]
# 比较根结点
dis = np.sqrt(sum((item-node.item)**2))
if k > len(nodeList) or dis < least_dis:
nodeList.append([dis, tuple(node.item), node.label[0]])
#nodeList.append([list(node.item), node.label[0]])
# 右子树
if k > len(nodeList) or abs(item[node.dim] - node.item[node.dim]) < least_dis: # 需要搜索右子树
if node.right_child != None:
self.left_search(item, node.right_child, nodeList, k)
return nodeList
def right_search(self,item, node, nodeList, k):
'''
按右中左顺序遍历子树结点
:param item: 测试的样本点
:param node: 子树结点
:param nodeList: 结点列表
:param k: 搜索比较的结点数量
:return: 结点列表
'''
nodeList.sort() # 对结点列表按距离排序
least_dis = nodeList[-1][0] if k >= len(nodeList) else nodeList[k - 1][0]
if node.left_child == None and node.right_child == None: # 叶结点
dis = np.sqrt(sum((item - node.item) ** 2))
if k > len(nodeList) or dis < least_dis:
nodeList.append([dis, tuple(node.item), node.label[0]])
#nodeList.append([list(node.item), node.label[0]])
return
if node.right_child != None:
self.right_search(item, node.right_child, nodeList, k)
nodeList.sort() # 对结点列表按距离排序
least_dis = nodeList[-1][0] if k >= len(nodeList) else nodeList[k - 1][0]
# 比较根结点
dis = np.sqrt(sum((item - node.item) ** 2))
if k > len(nodeList) or dis < least_dis:
nodeList.append([dis, tuple(node.item), node.label[0]])
#nodeList.append([list(node.item), node.label[0]])
# 左子树
if k > len(nodeList) or abs(item[node.dim] - node.item[node.dim]) < least_dis: # 需要搜索左子树
self.right_search(item, node.left_child, nodeList, k)
return nodeList
def node_listtoarray(nodelist):
n=len(nodelist)
nodelistarray=[]
for i in range(n):
dis=nodelist[i][0]
x=nodelist[i][1][0]
y=nodelist[i][1][-1]
z=nodelist[i][-1]
nodelistarray.append([x,y,z,dis])#sqrtdis
nodelistarray=np.array(nodelistarray)
return (nodelistarray)
def normsamples(neibors):
x=neibors[:,0]
y=neibors[:,1]
z=neibors[:,2]
normneibors=[]
for i in range(len(x)):
if max(x)-min(x)!=0:
xnormi=(x[i]-min(x))/(max(x)-min(x))
else:
xnormi=x[i]
if max(y)-min(y)!=0:
ynormi=(y[i]-min(y))/(max(y)-min(y))
else:
ynormi=y[i]
if max(z)-min(z)!=0:
znormi=(z[i]-min(z))/(max(z)-min(z))
else:
znormi=z[i]
normneibors.append([xnormi,ynormi,znormi])
normneibors=np.array(normneibors)
return (normneibors)
def newpoints(oldpoint,itneibor):
newpointss=[]
gp=[]
for i in range(1,len(itneibor)):
xmeani=(oldpoint[0]+itneibor[i][0])/2
ymeani=(oldpoint[1]+itneibor[i][1])/2
diffxi=abs(oldpoint[0]-itneibor[i][0])
diffyi=abs(oldpoint[1]-itneibor[i][1])
xi=xmeani+int(random.sample([1,-1], 1)[0])*1/6*random.uniform(0,diffxi)
yi=ymeani+int(random.sample([1,-1], 1)[0])*1/6*random.uniform(0,diffyi)
zi=5*(1-xi)**2*(np.exp(-xi**2-(yi+1)**2))-5*(xi/5-yi**5)*(np.exp(-xi**2-yi**2))-6*(np.exp(-(xi+1)**2-yi**2))
thenew=[xi,yi,zi]
itneibor=normsamples(itneibor)
grad=itneibor[0][-1]-itneibor[i][-1]
distancesqure=0
for j in range(len(oldpoint)-1):#(x,y) no z
distancesqure+=(itneibor[0][j]-itneibor[i][j])**2
distance=distancesqure**0.5
delta=2/math.pi*np.arctan(grad/distance)
generateprobability=(grad**2+distancesqure)/3*(delta**2)
if generateprobability>=1.50e-1:
newpointss.append(thenew)
gp.append(generateprobability)
newpointss=np.array(newpointss)
gp=np.array(gp)
#newpoints_p= np.column_stack((newpointss,gp))
return (newpointss)
def allnewpointsai(samples):
dataArray=samples[:,0:-1]
label=samples[:,-1]
kd_tree = KDTree(dataArray,label)
allnewnpoints=samples
for i in range(len(samples)):
label, node_list = kd_tree.knn_algo(dataArray[i],k=20)
nodeneibor=node_listtoarray(node_list)
newpoint=newpoints(dataArray[i],nodeneibor)
if len(newpoint)!=0:
allnewnpoints=np.vstack((allnewnpoints,newpoint))
return (allnewnpoints[len(samples):])
ps=[]
newpoints1=allnewpointsai(samples)
ps1=len(newpoints1)/(len(newpoints1)+len(samples))
ps.append(ps1)
print("第1次迭代产生{0}个点,占比{1}".format(len(newpoints1),len(newpoints1)/(len(newpoints1)+len(samples))))
samples=np.vstack((samples,newpoints1))
for i in range(1,100):
newpointsi=allnewpointsai(samples)
psi=len(newpointsi)/(len(newpointsi)+len(samples))
ps.append(psi)
if ps[i]>0.1 and abs(ps[i-1]-ps[i])>0.005:
print("第{0}次迭代产生{1}个点,占比{2}".format(i+1,len(newpointsi),len(newpointsi)/(len(newpointsi)+len(samples))))
samples=np.vstack((samples,newpointsi))
else:
break
文章来源:https://blog.csdn.net/weixin_43490216/article/details/135268673
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!