华为云分布式云原生UCS,助力MetaERP构建企业级高可用分布式业务
本文分享自华为云社区《华为云分布式云原生UCS,助力MetaERP构建企业级高可用分布式业务》,作者:云容器大未来。
引言
华为云最近成为《Forrester Wave?: Multicloud Container Platforms, Q4 2023》报告中唯一入选的中国厂商,市场表现强劲。华为云分布式云原生 UCS 作为本次参评的关键服务,其在多云容器应用中的价值获得了测评的一致认可。同时12月初,UCS 通过中国信息通信研究院分布式云原生能力测评,华为云成为首批通过分布式云原生能力评估的企业。
对于 UCS 来说,除了来自权威机构的认定外,越来越多的来自最终用户的大规模生产实践才是对 UCS 能力的最大认可。特别是近来频发的单集群现网事故,使得基于多集群的容灾多活引起了越来越多的关注,引发了对服务可用性的更深入思考。
本文我们将结合华为 MetaERP 的生产应用案例详细介绍 UCS 多集群的容灾多活实践。MetaERP 业务复杂,服务规模大,可用性要求高。基于 UCS 的多集群方案,在兼容原有单集群流水线、运维工具、监控视图的前提下,不仅提供了原有单集群的基于节点、AZ 等传统环境故障的容灾能力,同时也提供了多集群特有的集群整体故障、软件故障容灾。在整个生产实践中,客户反馈最重要的是多集群方案引入的灰度集群环境解决了单集群本地升级风险的问题,全面提升了服务可用性。
技术背景
随着以 Kubernetes 为核心的云原生技术的普及和应用,越来越多的大规模生产业务都运行在 Kubernetes 平台上。其提供了便捷的容器实例扩缩容、极致的负载弹性、无缝的应用迁移,帮助用户构建大规模、扩展性要求高的云原生应用。此外 Kubernetes 提供的节点、AZ 等反亲和部署能力,在单个节点或者整个AZ故障时,保证有一定的可用实例提供服务,客观上也帮助用户提高了应用的可用性。
但是,近来不断出现的各种单集群故障导致严重的业务故障的案例,给最终客户带来了极大的不便,单个 Kubernetes 集群在越来越多可用性要求较高的场景下遇到了严重挑战。Kubernetes 自身作为一个软件平台,其控制面和数据面自身组件的潜在故障经过厂商的保证,发生几率不高,但一旦发生会产生极大的影响。 特别是近来业内多个重大的故障案例中单集群Kubernetes 版本的原地升级异常,导致集群内部署的所有业务不可用,引发了全局的业务断服宕机。
这种现象的根本原因是存在一个无限大的爆炸半径。就像把所有鸡蛋放在一个结实的篮子里,一旦篮子有问题,没有一个鸡蛋能幸存。更糟糕的是随着业务增长,这个早期还是结实能用的篮子,随着时间推移越来越破旧,但这个过程中却有更多的鸡蛋一直不断地塞进来,因此篮破蛋打是早晚要面对的事。解决这类问题的直观且根本的思路是减小爆炸半径,把鸡蛋分开放到多个篮子里。
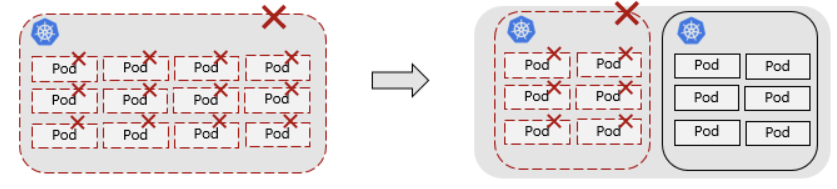
理论上这个道理很简单,不要垂直扩展单个集群,而是水平扩展集群数。但是真正实践中并没有这么简单。MetaERP用户早期选择把大量服务集中部署在大集群的一个主要原因是想降低平台的运维成本,单个 Kubernetes 集群的运维已经耗费了团队很多精力,多个Kubernetes集群理论上会导致管理和运维成本线性地增加。在 MetaERP 为代表的大规模企业应用实践中,面临多个复杂问题:如何灵活地控制负载和多种资源对象在多个集群间部署、升级、弹性;如何管理多集群的入口流量;如何控制多集群的内部流量。总的来说,即如何将理论上的多集群可用性转化为客户的实际价值。最重要的是 MetaERP 对以上能力的前提是多集群能力与和其原有的单集群使用方式兼容,包括原有单集群命令行工具、CICD 流水线、扩展组件调用的集群 API 等尽量保持不变,同时保持面向应用的多集群统一的资源管理视图、监控运维视图等。UCS 的多集群解决方案一一解答了以上问题。
方案
节点、AZ等传统环境故障容灾
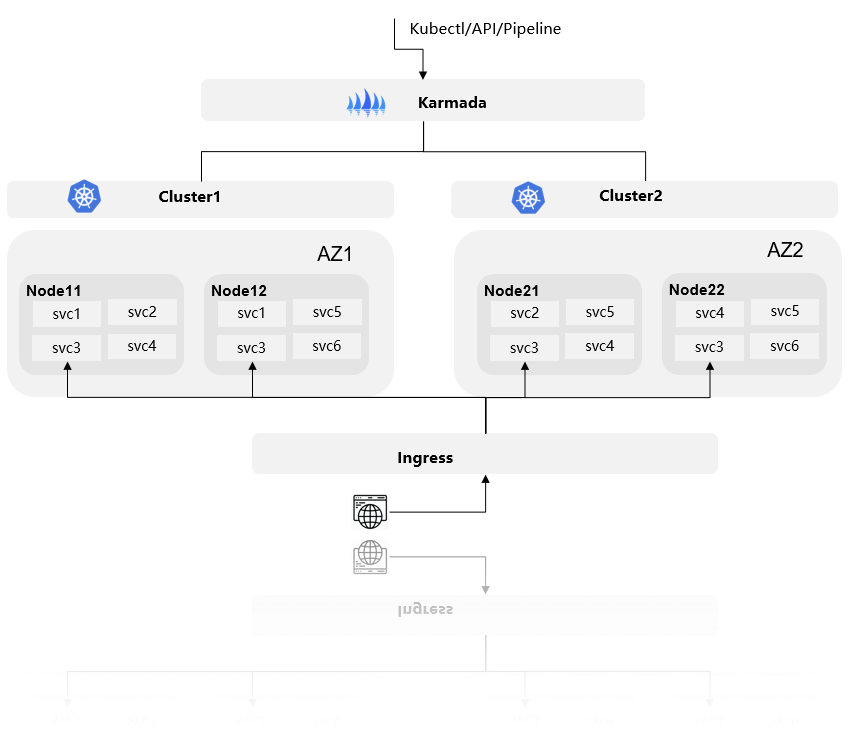
首先,UCS 内置的 Karmada 多集群资源管理允许用户根据策略动态地将负载分布式部署到舰队管理的多个集群中。每个集群管理的节点来自不同的可用区 (AZ),因此负载的各个实例被智能地分布在不同的可用区,从而具备了跨可用区的高可用性。
当某个节点发生故障时,该节点上的负载实例将完全失效。此时,访问该服务的流量不仅会被重新分发到本集群其他节点的对应副本,还会分发到其他集群中对应的副本,确保了服务的整体可用性。
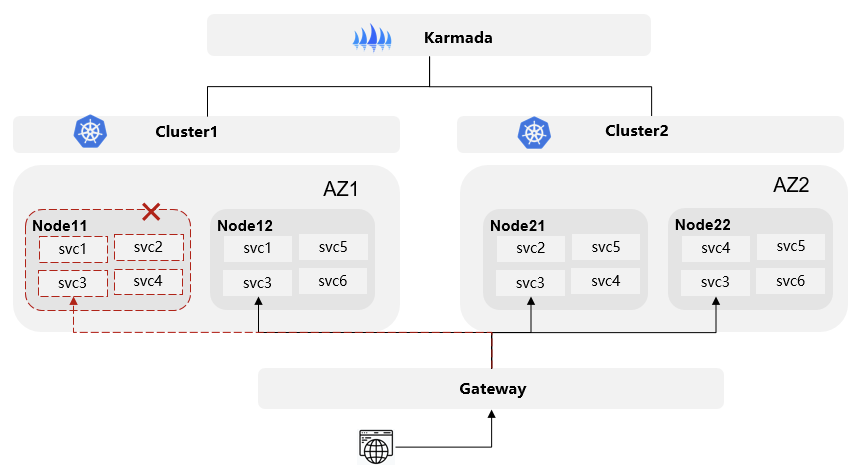
当某个AZ故障时,该区域的节点全部失效,导致负载实例不可用。流量自动转移到其他集群,即其他AZ的对应副本上,用户的业务完全不受影响。
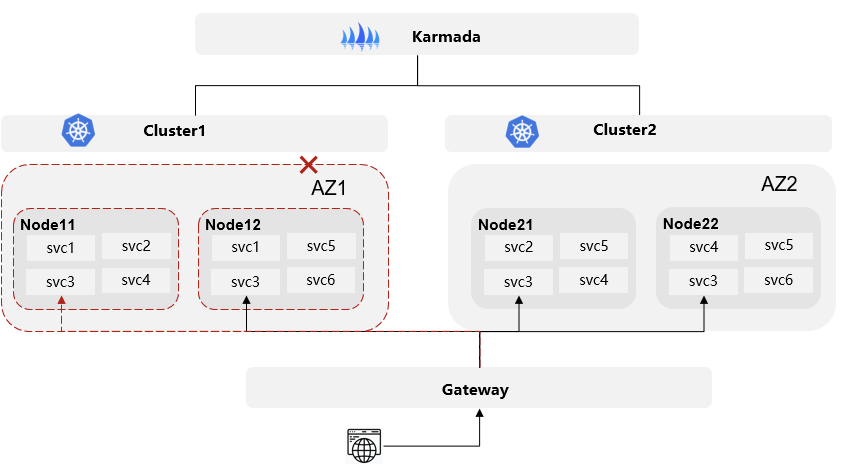
通过以上分析,UCS多集群方案覆盖了MetaERP原有的单集群提供的AZ级别、节点级别的服务可用性,同时还增加了单集群不具备的功能,帮助全面提高业务的可用性。
集群软件故障容灾
除了环境故障外,另外一个可能对业务产生潜在影响的是集群软件自身的故障,虽然这种故障发生的几率低,但是一旦发生,对业务影响很大。在客户应用中曾经出现过Kube-apiserver过载导致集群故障、集群数据面异常导致负载不能正常创建等问题。在单集群环境下,基于常规的故障检测和倒换机制,平台和业务可采取的有效手段非常有限。
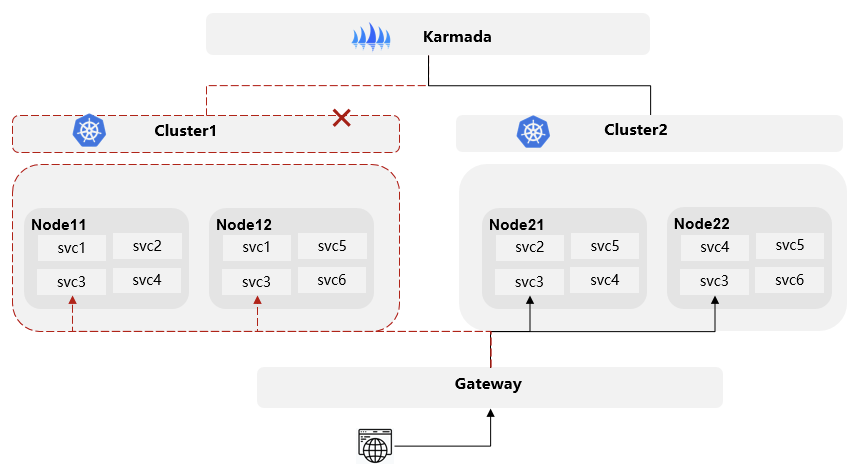
基于UCS多集群方案,当检测到一个集群故障时,Karmada可以动态地将目标是该故障集群的流量切换到另外一个可用集群的服务后端上。同时根据策略配置,可以动态地将负载实例从故障集群迁移到其他可用集群。也支持用户根据自身对业务的判断,在紧急情况下,当发现一个集群状态不健康时,管理员可以将一个集群的负载整体隔离掉,快速高效地进行故障隔离,最大限度保证业务总体可用性。
集群升级故障容灾
在实践中,UCS多集群方案为MetaERP业务带来最大收益在于集群升级过程的保障。在业务升级中,引入各种灰度升级策略是常见的做法,然而,在集群平台升级时,应用这种灰度机制却相当困难。如果待升级集群版本本身存在问题或与现有业务不兼容,可能导致现有业务受升级影响。例如,集群升级Master证书不匹配、容器文件系统变更影响Jar包加载顺序导致应用启动异常,或者不当的现网集群版本升级路径导致集群无法正常启动等问题,都可能导致整个集群的业务受影响。
通过 UCS 多集群方案,用户在升级时可选择一个集群作为独立的灰度环境进行升级,等待最终业务验收确认升级成功后再升级另一个集群。这种方式避免了在单集群场景下,集群升级失败导致全部业务不可用的情况。
以下是详细的操作步骤:
1. 在业务低谷时间窗内进行集群升级。首先,选择一个待升级的集群作为灰度环境,并配置规则将全部流量切换到另一个集群。
2. 对灰度集群的平台组件执行升级,并观察各个组件的正常运行情况。
3. 观察灰度集群内负载的运行情况,确保负载与灰度集群环境匹配并正常运行。
4. 将少量流量切换至灰度集群,进行部分负载的灰度发布,从最终业务视角观察服务的运行状态。当基于业务确认灰度集群运行正常时,逐步将全量流量切换至灰度集群。
5. 对另一个集群执行灰度升级过程,确保每个集群都经过类似的测试和确认。
在以上的第二到第四步骤中,如果出现问题,可以立即修复灰度集群,而不会影响最终用户的访问。通过这种集群灰度升级的方式,确保升级过程中出现的问题不会对用户业务造成影响。
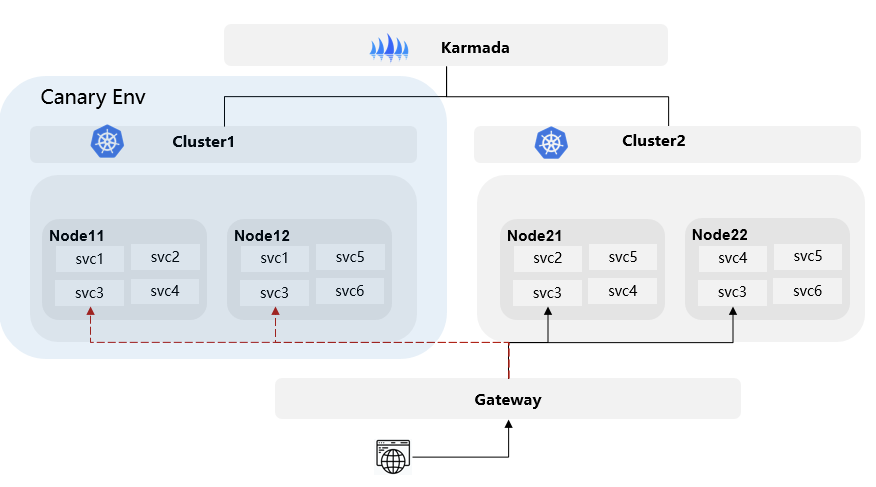
入口和内部流量统一多活策略
与传统的容灾多活仅仅基于入口流量控制不同,UCS 与高性能服务网格集成,能够在应用内部执行一致的流量动作。在容灾场景下,通过网格代理和入口 Gateway 基于统一的流量策略进行切换。对于同一目标服务,无论流量源自内部服务访问还是外部访问,都可以根据统一的策略隔离异常实例,确保服务的高可用性。
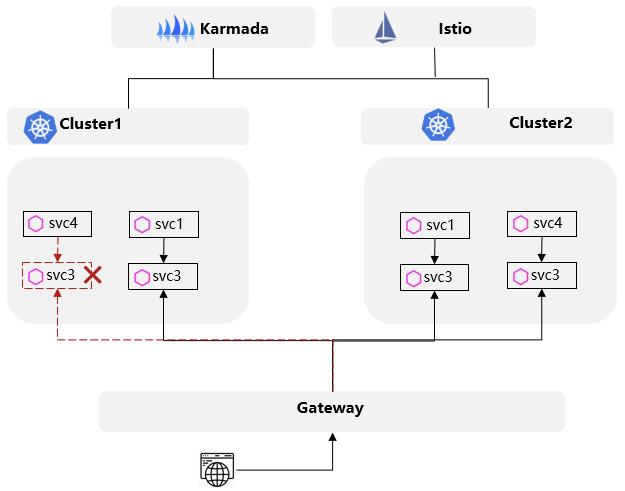
流量迁移伴随应用迁移多重能力
在许多容灾解决方案中,仅仅切换流量可能看似解决了主要问题,但实际上仍然存在不完善之处。在前述场景中,将流量从一个被标记为不健康的集群实例隔离后,实际提供服务的后端数量可能会少于用户最初预期的数量,从客观上来说,这会导致服务整体能力受损,这显然不满足 MetaERP 可用性要求高的业务。UCS 提供的多集群故障迁移方案不仅仅局限于流量切换,还结合了跨集群负载迁移和根据用户实际场景进行的数据迁移,构建了立体化的故障应对机制。也就是说,除了保证业务连续性通过流量切换外,还通过多集群中的负载管理,在异常集群中的负载迁移到其他集群中,确保始终有足够数量的负载实例向用户提供服务,以确保服务的可用性。这种结合了流量迁移和负载迁移的方式,保障了用户业务的可用性,确保了总体服务质量符合用户期望。
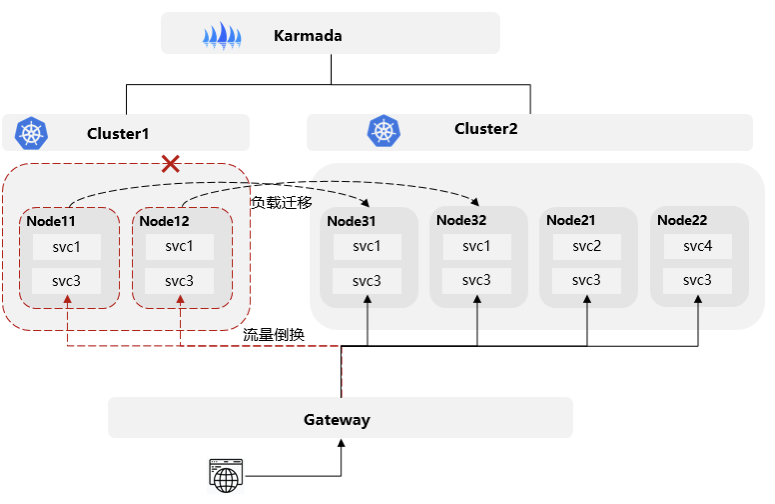
单集群一致体验,简化运维
UCS 多集群容灾方案中以集群粒度进行故障管理,与仅能在实例、节点或 AZ 粒度进行故障检测和隔离的单集群方案不同,能够快速隔离整个集群以实现故障快速隔离,从而提升应用的可用性。但这些能力的提供并未增加用户的管理和运维复杂度。UCS 多集群舰队提供了与单集群完全兼容的API和对象模型,使得原有的单集群运维平台工具可以无缝对接。MetaERP 原有流水线无需过多修改即可连接舰队API,实现集群Deployments、Service、Secret、ConfigMap、Role、RoleBinding 等 Kubernetes 资源资源的创建、升级。
同时,UCS 基于 Karmada 的多集群资源管理能力,根据用户配置的策略将舰队级别的资源分发到舰队管理的多个集群。MetaERP 运维人员可以通过原有的Kubernetes 命令行工具对舰队中的资源进行统一运维管理,与单集群体验基本一致。此外,面向应用的舰队级别监控视图也与单集群内的业务监控保持一致。
多集群的采用不仅突破了单集群的容量限制,还大幅提升了平台的总体容量,满足了 MetaERP 业务的大规模增长需求。
总结
在 MetaERP 基于 UCS 多集群方案中,不仅涵盖了传统容灾场景中资源和环境故障的处理,还包括了应对平台自身、软件故障以及平台升级过程的能力,显著增强了业务的整体可用性。这种方案不受限于云上同 Region 多 AZ 的部署方式,也能灵活适用于跨 Region 环境、多云环境和混合云环境。通过基于分布式环境的部署,它能有效地管理多集群的负载和流量,在分布式云环境中实现容灾多活,进一步提高用户业务的可用性。
这里介绍到的多集群能力只是分布式云原生 UCS 产品功能的一部分。分布式云为用户提供了将云能力根据其场景分发到各个物理位置的灵活性,同时通过在云上统一管理运维,简化了用户的使用。作为业界最早的分布式云产品,华为云的分布式云原生 UCS 采用云原生方式将厂商的硬件、软件、基础架构和服务分发到用户数据中心、边缘、其他云等多种位置,以满足用户对低时延、本地数据处理、数据驻留合规性或容灾多活等应用场景的需求。在基于多云多集群高可用的分布式应用管理基础上,在多集群的舰队上构建全域统一的动态流量、应用配置、零信任安全、 DevOps、应用运维等能力,满足 MetaERP 等大规模企业用户不断增长的应用现代化需求。
同时,UCS 多集群方案的核心组件 Karmada 在服务分布式云原生客户场景中持续成熟,并于本月正式晋级为 CNCF 孵化项目。未来,Karmada 将继续探索云原生多集群领域的技术创新,让基于 Karmada 的多云方案更深度地融入云原生技术生态。
未来,UCS 将持续引领多云容器平台的发展,助力用户实现更高效、更智能的云原生应用部署与管理。
参考:
- 《Forrester Wave?: Multicloud Container Platforms, Q4 2023》测评:华为云成为中国唯一入选多云容器平台报告的云厂商-华为云
- 中国信通院分布式云原生能力评估:https://mp.weixin.qq.com/s/ba7kIS8C4p-Ue3L3DgwWtA
- Karmada晋级CNCF孵化项目:https://www.cncf.io/blog/2023/12/12/karmada-brings-kubernetes-multi-cloud-capabilities-to-cncf-incubator/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 手机APP测试——如何进行安装、卸载、运行?
- SpringBoot入门到精通-Spring Boot Jasypt Encrypt 演示
- 【学习笔记】CF1864H Asterism Stream
- windows 安装sql server 华为云文档
- (Matlab)基于CNN-Bi_LSTM的多维回归预测(卷积神经网络-双向长短期记忆网络)
- Spring-aop切面并取出参数转换为实体参数测试
- 前端工程化
- 【IC设计】我爱运动,我爱乒乓!
- 如何将一个字符串转换为整数?
- 【LV12 DAY15 WDT】