数据处理四 基于图像hash进行数据整理(删除重复图片、基于模版查找图片)
一、背景知识
1.1 什么是hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出。这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。与指纹一样,就是以较短的信息来保证文件的唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。 活动开发中经常使用的MD5和SHA都是历史悠久的Hash算法。
hash算法的特点:
- 从hash值不可以反向推导出原始的数据
不可逆 - 输入数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的值
唯一对应 - hash算法的冲突概率要小
冲突概率小 - 哈希算法的执行效率要高效,长的文本也能快速地计算出哈希值
高效计算
由于hash的原理是将输入空间的值映射成hash空间内,而hash值的空间远小于输入空间(输入空间是无限长度,而hash空间是有限的)。根据抽屉原理,一定会存在不同的输入被映射成相同输出的情况。那么作为一个好的hash算法,就需要这种冲突的概率尽可能小。
以上内容参考自:https://zhuanlan.zhihu.com/p/309675754
一般使用hash算法是为了校验文件是否被篡改或有传输损失。例如:某网站提供了文件下载地址和文件hash,我们下载文件后可以通过校验hash,确认文件没有发生传输损失(我下载的文件hash值,与网站公布的hash值一致)。又例如:某计算机考试,让学生提交作业文档和文档hash值给老师,确保作业未被篡改。
1.2 图片hash
哈希相似度算法(Hash algorithm),它的作用是对每张图片生成一个固定位数的Hash 值(指纹 fingerprint)字符串,然后比较不同图片的指纹,结果越接近,就说明图片越相似。图像Hash算法准确的说有三种,分别为平均哈希算法(aHash)、感知哈希算法你(pHash)和差异哈哈希算法(dHash)。
图像hash与上文中描述的hash算法目的不同,图像hash主要可用于判断或查找相似的图片,我们要尽可能的是图像hash值具有意义,与内容相关。他应当具备以下特点:
-
1、高效计算,能适应于不同尺寸的图像(
图像hash都要进行resize(8x8)) -
2、存在相似性,使相似的图像hash值相似(
根据图像的内容生成hash值)三种Hash算法都是通过获取图片的hash值,再比较两张图片hash值的汉明距离来度量两张图片是否相似。两张图片越相似,那么两张图片的hash数的汉明距离越小。
平均哈希算法(aHash)
平均哈希算法是三种Hash算法中最简单的一种,它通过下面几个步骤来获得图片的Hash值,这几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 算像素均值;(4)根据相似均值计算指纹。具体算法如下所示:

得到图片的ahash值后,比较两张图片ahash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。汉明距离:字符串差异计算,相同位置下字符不同,则距离值加1
感知哈希算法(pHash)
感知哈希算法是三种Hash算法中较为复杂的一种,它是基于DCT(离散余弦变换)来得到图片的hash值,其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 计算DCT;(4)缩小DCT; (5)算平均值;(6) 计算指纹。具体算法如下所示:

得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
差异哈希算法(dHash)
相比pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 算差异值;(4) 计算指纹。具体算法如下所示:

得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
以上内容参考自:https://www.cnblogs.com/Yumeka/p/11260808.html
二、图片hash的运用
2.1 删除重复图片
要删除文件夹内重复的图片,可以使用 imagededup库。 imagededup是一个基于Python的图片查重工具库,它简化了在图像集合中查找精确重复和近似重复的任务。可以使用CNN(卷积神经网络)、PHash、DHash、WHash(小波散列)、以及AHash这几种方法之一对图像生成编码,然后根据编码进行比对图像是否重复,并提供一些工具生成图片重复项快照?。

通过 pip 安装
安装命令
pip install imagededup
具体使用案例
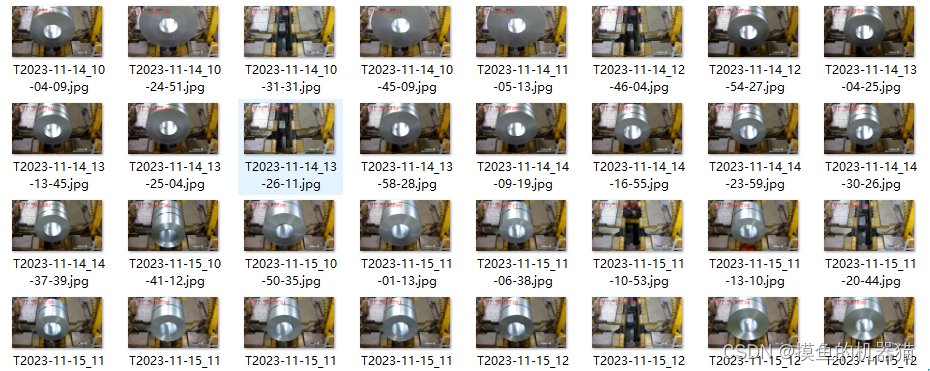
对一个文件夹内相同图片进行去重操作。本博文运用的是PHash(感知hash算法)。原始文件夹内的数据如下图所示:
注意如果是windows系统的话要加上if name==‘main’: ,因为它会默认使用多线程进行处理,不加的话会报错。
完整代码:
import os
from imagededup.methods import PHash
def process_file(img_path):
"""
处理图片去重
:return:
"""
try:
phasher = PHash()#WHash、AHash
# 生成图像目录中所有图像的二值hash编码
encodings = phasher.encode_images(image_dir=img_path)
#print(encodings)
# 对已编码图像寻找重复图像
duplicates = phasher.find_duplicates(encoding_map=encodings)
print(duplicates)
only_img = [] # 唯一图片
like_img = [] # 相似图片
for img, img_list in duplicates.items():
if img not in only_img and img not in like_img:
only_img.append(img)
like_img.extend(img_list)
# 删除文件
for like in like_img:
print("like: ",like)
like_src = os.path.join(img_path, like)
if os.path.exists(like_src):
os.remove(like_src)
except Exception as e:
print(e)
if __name__ == "__main__":
img_path = "D:/实战项目/图像清理/1123"
process_file(img_path)
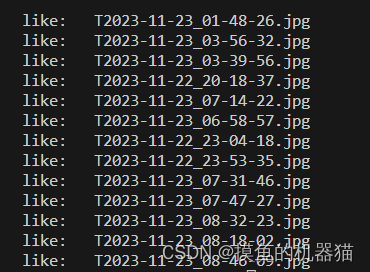
代码运行输出如下所示:like即为找出的相似图片
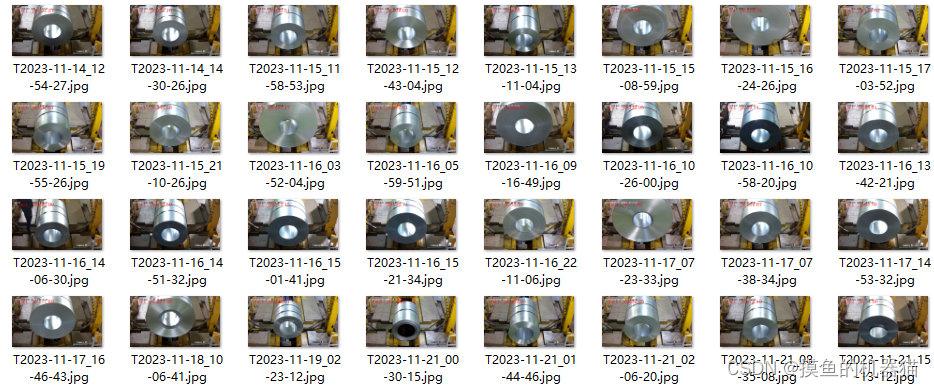
代码运行后,文件夹内的图片如下所示,将大部分重复的图像进行删除。
这个方法的核心步骤是通过计算图片的哈希值进行比较,因为哈希值在一定程度上能够反映出图片的内容特征,所以相同或相似的图片的哈希值也会相对接近。通过利用哈希值进行比较,能够快速找出重复的图片并删除。
需要注意的是,由于哈希值是通过将图片文件转化为数值进行计算得出的,所以不能保证100%的准确性。在实际操作中,可能会存在一些不同的图片被误判为重复图片,或者相同的图片被误判为不同图片的情况。因此,在删除重复图片之前,建议先备份图片并进行人工审核,确保没有误删重要的图片。
2.2 基于模板查找图片
基于模板查找图片是在给定模版图片的情况下,到图像数据库下查找出类似的图片。在本次任务重,模版图片为没有钢卷的图像(图像数据库的图像基本分为有钢卷和无钢卷)。
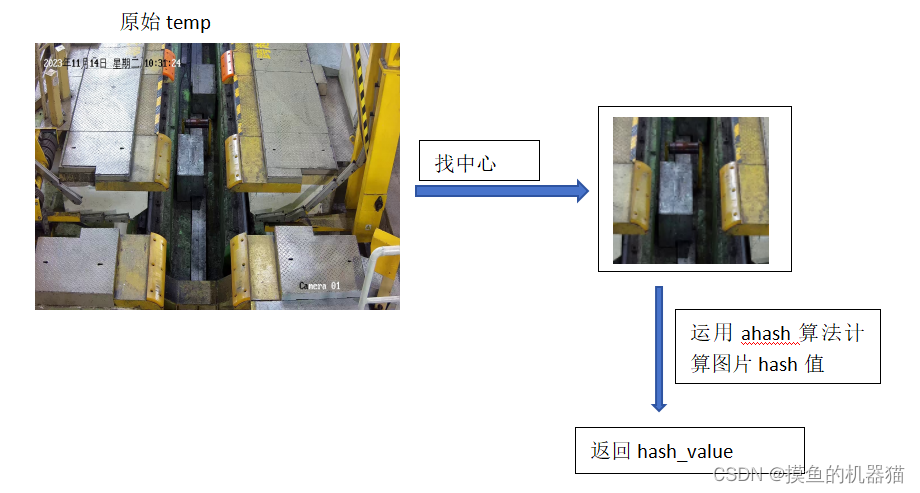
根据实际数据情况,将数据分为有钢卷和没钢卷,因为钢卷在图像的中心,所以不需要计算周围的相似区域(相似区域会混淆hash值)。故此,我们定义chash函数,其步骤如下,具体如下图所示。
1、将图像resize到固定尺寸
2、截取出图像的中心区域
3、计算图像中心区域的ahash值(可以根据效果调整,选择其他的hash算法)
根据模版图片删除相似图片的步骤如下:
- 1、获取文件夹内所有图片 => all_list
- 2、读取模版图片 => temp_mat
- 3、计算模版图片chash值 => temp_hash
根据个人数据情况使用hash算法,如ahash、dhash、phash等 - 4、计算每一个图片hash值 =>img_hash
- 5、将all_list里面的图片hash值(img_hash)和模版图片hash值(temp_hash)进行对比,相同则移动到temp文件夹内
完整代码如下
import cv2,os
import numpy as np
# 均值哈希算法
def ahash(image):
# 将图片缩放为8*8的
image = cv2.resize(image, (8,8), interpolation=cv2.INTER_CUBIC)
# 将图片转化为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
# s为像素和初始灰度值,hash_str为哈希值初始值
s = 0
ahash_str = ''
# 遍历像素累加和
for i in range(8):
for j in range(8):
s = s+gray[i, j]
# 计算像素平均值
avg = s/64
# 灰度大于平均值为1相反为0,得到图片的平均哈希值,此时得到的hash值为64位的01字符串
ahash_str = ''
for i in range(8):
for j in range(8):
if gray[i,j]>avg:
ahash_str = ahash_str + '1'
else:
ahash_str = ahash_str + '0'
result = ''
for i in range(0, 64, 4):
result += ''.join('%x' % int(ahash_str[i: i + 4], 2))
# print("ahash值:",result)
return result
# 差异值哈希算法
def dhash(image):
# 将图片转化为8*8
image = cv2.resize(image,(9,8),interpolation=cv2.INTER_CUBIC )
# 将图片转化为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
dhash_str = ''
for i in range(8):
for j in range(8):
if gray[i,j]>gray[i, j+1]:
dhash_str = dhash_str + '1'
else:
dhash_str = dhash_str + '0'
result = ''
for i in range(0, 64, 4):
result += ''.join('%x'%int(dhash_str[i: i+4],2))
# print("dhash值",result)
return result
# 计算hash值
def phash(img):
img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
img=img.astype(np.float32)
#step2:离散余弦变换
img=cv2.dct(img)
img=img[0:8,0:8]
sum=0.
hash_str=''
#step3:计算均值
# avg = np.sum(img) / 64.0
for i in range(8):
for j in range(8):
sum+=img[i,j]
avg=sum/64
#step4:获得哈希
for i in range(8):
for j in range(8):
if img[i,j]>avg:
hash_str=hash_str+'1'
else:
hash_str=hash_str+'0'
return hash_str
# 中心hash算法
def crop_center(image):
image = cv2.resize(image, (900,900))
image=image[300:600,300:600]
#image=image[350:550,350:550]
return image
def chash(image):
cimage=crop_center(image)
hash_value=ahash(cimage)
return hash_value
# 计算两个哈希值之间的差异
def campHash(hash1, hash2):
n = 0
# hash长度不同返回-1,此时不能比较
if len(hash1) != len(hash2):
return -1
# 如果hash长度相同遍历长度
for i in range(len(hash1)):
if hash1[i] != hash2[i]:
n = n+1
return n
if __name__ == "__main__":
#读取并计算模版图片中心的ahash值
temp_mat='temp.jpg' #模版路径
temp=cv2.imread(temp_mat)
temp_hash = chash(temp)
print('temp的ahash值',temp_hash)
#创建temp文件夹,用于保存和模版相似的图片
del_path="temp/"
os.makedirs(del_path,exist_ok=True)
#读取并计算文件夹内图片中心的ahash值
img_path = "图片路径/"
all_list=os.listdir(img_path)
for p in all_list:
img=cv2.imread(img_path+p)
img_hash = chash(img)
#计算图片和模版图片hash值的差异,并将差异小于10的图片移动到temp文件夹内
dif= campHash(temp_hash,img_hash)
#print('img的ahash值',dif,p)
#continue
if dif<10:
print('img的ahash值',dif,p)
os.rename(img_path+p,del_path+p)
图片路径中图片如下
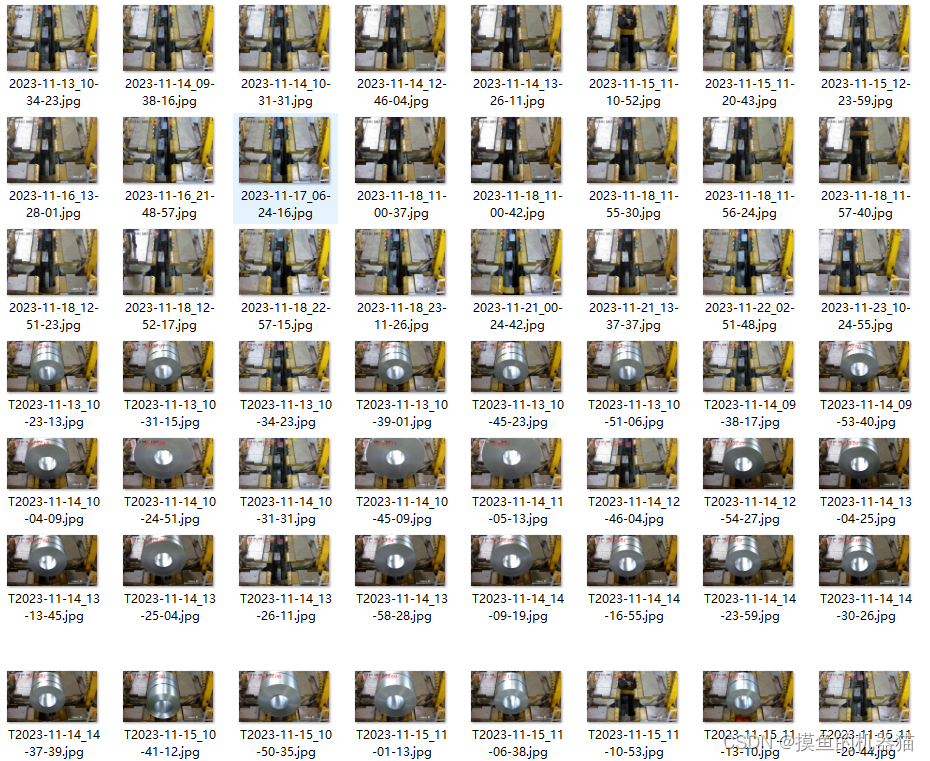
temp.jpg 模版图片如下所示

代码执行完后找到的重复图像如下
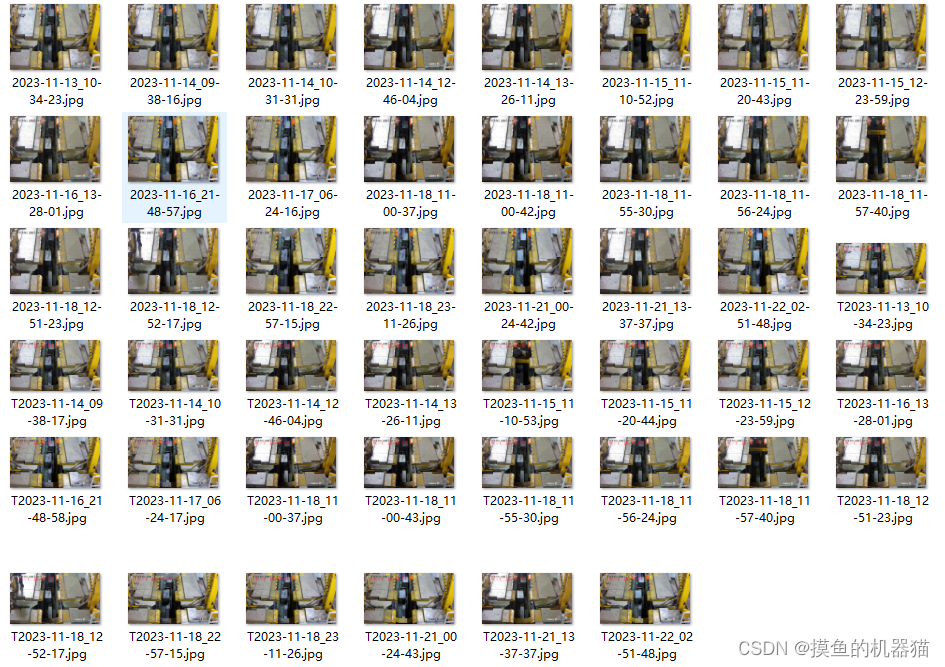
代码执行时输出如下所示
img的ahash值 3 T2023-11-15_11-20-44.jpg
img的ahash值 2 T2023-11-15_12-23-59.jpg
img的ahash值 6 T2023-11-16_13-28-01.jpg
img的ahash值 7 T2023-11-16_21-48-58.jpg
img的ahash值 8 T2023-11-17_06-24-17.jpg
img的ahash值 7 T2023-11-18_11-00-37.jpg
img的ahash值 9 T2023-11-18_11-00-43.jpg
img的ahash值 6 T2023-11-18_11-55-30.jpg
img的ahash值 5 T2023-11-18_11-56-24.jpg
img的ahash值 9 T2023-11-18_11-57-40.jpg
img的ahash值 5 T2023-11-18_12-51-23.jpg
img的ahash值 5 T2023-11-18_12-52-17.jpg
img的ahash值 6 T2023-11-18_22-57-15.jpg
img的ahash值 8 T2023-11-18_23-11-26.jpg
img的ahash值 6 T2023-11-21_00-24-43.jpg
img的ahash值 5 T2023-11-21_13-37-37.jpg
img的ahash值 6 T2023-11-22_02-51-48.jpg
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!