DuNST详解:将Self-Training机制融入受控文本生成中
DuNST Dual Noisy Self Training for Semi-Supervised Controllable Text Generation
文章的主要工作
(1)第一个将自我训练纳入半监督可控语言生成中并提出一种新颖有效的ST方法的工作。
(2)证明 DuNST 探索了更大的潜在文本空间并扩展了泛化边界,为我们的方法提供了理论解释。
(3)对三个属性可控的生成任务进行了深入的实验,证明了 DuNST 在提高控制精度和生成文本的竞争质量方面的优越性,进一步扩展了强大的 PLM 用于 NLG 的能力。
DuNST方法
定义
让 x x x 为文本, y y y 为属性标签, D l = { ( x i , y i ) } D_l = \{ (x_i, y_i) \} Dl?={(xi?,yi?)} 是一个带有配对文本及其相应标签的标记数据集, D u = { x i } D_u = \{ x_i \} Du?={xi?} 是来自同一领域的无标记数据集。我们的目标是学习一个由 θ \theta θ 参数化的属性可控生成器 G = g θ ( x ∣ y ) G = g_{\theta}(x|y) G=gθ?(x∣y)(例如,一个大型的PLM),以生成高质量的文本 x ~ g θ ( x ∣ y ) x \sim g_{\theta}(x|y) x~gθ?(x∣y)(以自回归方式),满足给定的标签 y y y。我们还赋予我们的模型能力,通过联合学习一个文本分类器 C = q ? ( y ∣ x ) C = q_{\phi}(y|x) C=q??(y∣x) 为 x ∈ D u x \in D_u x∈Du? 生成伪属性标签。我们同时对 G G G 和 C C C 用一个共享的PLM作为双重过程来建模和优化(见第3.2节)。
在DuNST的训练过程中(见第3.3节),由 C C C 预测的伪标签有助于覆盖更多未见样本,从而扩展了学习的分布边界,而由 G G G 生成的噪声伪文本有助于扰动先前学习的空间,进一步提高泛化。
双重生成与分类
我们联合学习文本的条件分布 g θ ( x ∣ y ) g_{\theta}(x|y) gθ?(x∣y) 和标签 q ? ( y ∣ x ) q_{\phi}(y|x) q??(y∣x) 来匹配真实的分布。然而,我们并不直接使用传统的交叉熵损失函数来优化它们,而是采用变分方法。具体来说,我们引入了一个潜在变量 z z z 来捕获底层语义,因此我们有 q ( x ∣ y ) = ∫ q ( x , z ∣ y ) d z q(x|y) = \int q(x, z|y)dz q(x∣y)=∫q(x,z∣y)dz。我们可以通过分解 q ( x , z ∣ y ) = q ( x ∣ z , y ) ? q ( z ∣ y ) q(x, z|y) = q(x|z, y) * q(z|y) q(x,z∣y)=q(x∣z,y)?q(z∣y) 来采样生成文本 x x x。为了实现这个目标,我们将生成损失最小化为:
L g = ? E p ψ ( z ∣ x , y ) [ log ? q θ ( x ∣ z , y ) ] + K L [ p ψ ( z ∣ x , y ) ∣ ∣ q θ ( z ∣ y ) ] , (1) L_g = -\mathbb{E}_{p_{\psi}(z|x,y)}[\log q_{\theta}(x|z, y)] + KL[p_{\psi}(z|x, y)||q_{\theta}(z|y)],\tag{1} Lg?=?Epψ?(z∣x,y)?[logqθ?(x∣z,y)]+KL[pψ?(z∣x,y)∣∣qθ?(z∣y)],(1)
其中 p ψ ( z ∣ x , y ) p_{\psi}(z|x, y) pψ?(z∣x,y) 和 q θ ( z ∣ y ) q_{\theta}(z|y) qθ?(z∣y) 分别是 z z z 的后验分布和先验分布的近似,KL 是指Kullback-Leibler散度。优化这个损失相当于最大化 q θ ( x ∣ y ) q_{\theta}(x|y) qθ?(x∣y) 的下界。
后验 p ψ ( z ∣ x , y ) p_{\psi}(z|x, y) pψ?(z∣x,y) 通常假设为多元高斯分布 N ( μ p o s t , σ p o s t ) N(\mu_{post}, \sigma_{post}) N(μpost?,σpost?),并通过 [ μ p o s t , log ? σ p o s t ] = M L P ( [ h x , h y ] ) [ \mu_{post}, \log \sigma_{post} ] = MLP([h_x, h_y]) [μpost?,logσpost?]=MLP([hx?,hy?]) 近似,其中 h x = Encoder ( x ) h_x = \text{Encoder}(x) hx?=Encoder(x), h y h_y hy? 是标签 y y y 的嵌入表示。编码器是Transformer编码器,MLP是多层感知机。同样,我们可以构建先验 q θ ( z ∣ y ) q_{\theta}(z|y) qθ?(z∣y) 为高斯分布 N ( μ g e n p r i o r , σ g e n p r i o r ) N(\mu_{gen}^{prior}, \sigma_{gen}^{prior}) N(μgenprior?,σgenprior?),其中 [ μ g e n p r i o r , log ? σ g e n p r i o r ] = M L P ( h y ) [ \mu_{gen}^{prior}, \log \sigma_{gen}^{prior} ] = MLP(h_y) [μgenprior?,logσgenprior?]=MLP(hy?)。对称地,我们通过以下方式优化分类:
L c = ? E p ψ ( z ∣ x , y ) [ log ? q ? ( y ∣ z , x ) ] + K L [ p ψ ( z ∣ x , y ) ∣ ∣ q ? ( z ∣ x ) ] . (2) L_c = -\mathbb{E}_{p_{\psi}(z|x,y)}[\log q_{\phi}(y|z, x)] + KL[p_{\psi}(z|x, y)||q_{\phi}(z|x)].\tag{2} Lc?=?Epψ?(z∣x,y)?[logq??(y∣z,x)]+KL[pψ?(z∣x,y)∣∣q??(z∣x)].(2)
文本是由自回归Transformer解码器生成的, x = Decoder ( z ) x = \text{Decoder}(z) x=Decoder(z),标签是由 y = M L P ( z ) y = MLP(z) y=MLP(z) 预测的, z z z 在训练时从后验分布抽样,在测试时从先验分布抽样。 G G G 和 C C C 大部分参数共享(例如,编码器),以及相同的后验分布 p ψ ( z ∣ x , y ) p_{\psi}(z|x, y) pψ?(z∣x,y),以增强文本与相应标签的联系,并更好地利用通过这两个方向学到的知识。
最终的损失函数如下计算:
L = λ g L g + λ c L c , (3) \mathcal{L} = \lambda_g L_g + \lambda_c L_c,\tag{3} L=λg?Lg?+λc?Lc?,(3)
其中 λ g \lambda_g λg? 和 λ c \lambda_c λc? 是超参数,用于平衡分类与生成的重要性。这种变分双重学习进一步增强了可控性和文本多样性,并有助于精炼伪标签。
双重噪声自我训练
仅通过自生成文本增强的模型将越来越多地利用之前学到的空间,但失败于进行更多的探索,导致属性分布受限,因此控制精度的提升有限(见表1)。将噪声注入到伪文本中是促进探索的一种实践方式。然而,典型的合成噪声(例如,随机地在伪文本中洗牌令牌)鼓励各向同性探索,这可能会偏离有效空间,并且对于自然语言生成过于嘈杂。
为了解决这个问题,我们提出了两种新颖而有效的软噪声类型以实现更安全的探索,即高温生成和软伪文本。
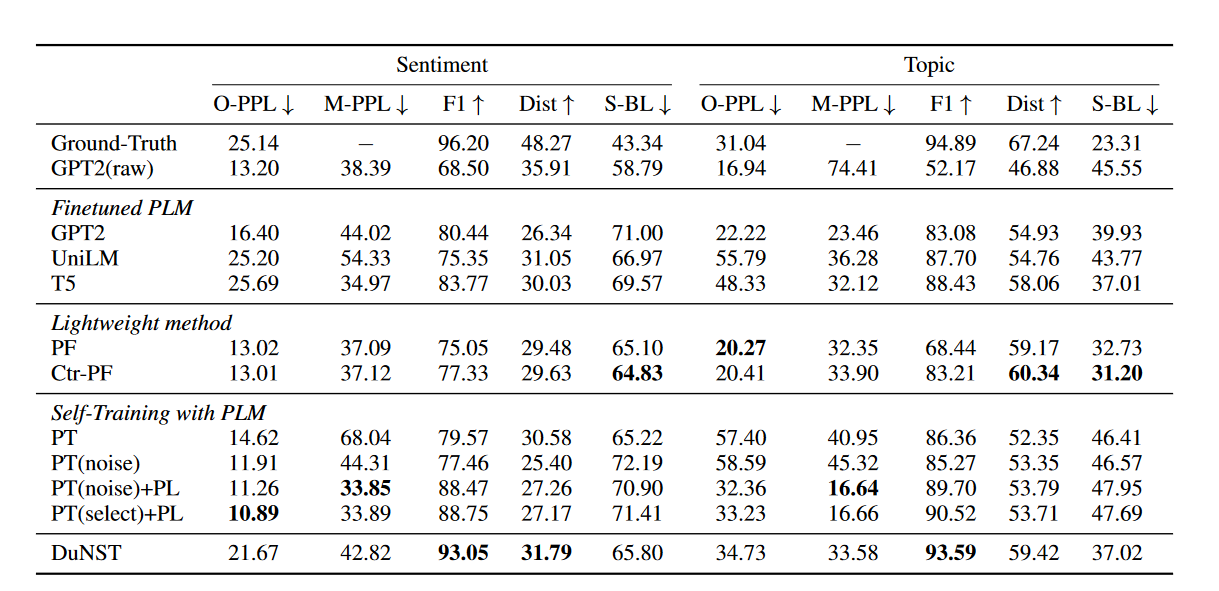
表 1:IMDb 数据集(情绪)和 AGNews 数据集(主题)的结果。
高温生成(HTG):我们在softmax层引入温度 τ \tau τ:
d m = σ ( G ( y , x ^ < m , z ) τ ) , (4) d^m = \sigma(\frac{G(y, \hat{x}_{<m}, z)}{\tau}),\tag{4} dm=σ(τG(y,x^<m?,z)?),(4)
其中 d m d^m dm 是第 m m m 个令牌的输出分布, x ^ < m \hat{x}_{<m} x^<m? 是之前生成的 m ? 1 m-1 m?1 个令牌, σ \sigma σ 表示softmax。较低的 τ \tau τ(例如, τ < 1 \tau < 1 τ<1)会导致更尖锐的分布,因此激励更确定的输出(通常用于NMT)。相反地,我们选择 τ > 1 \tau > 1 τ>1 来鼓励更多样化但语义上合理的(高生成概率)令牌,这可以增强局部平滑性并帮助探索更多潜在方向。此外,通过调整 τ \tau τ 可以轻松控制噪声程度以获得更好的权衡。
软伪文本(SPT):HTG提高了伪文本的多样性,但也存在抽样无效令牌和在自回归生成中传播错误的风险。此外,HTG产生离散的伪文本(文本空间中的一个点),因此需要大量的抽样伪文本(点)来覆盖小区域(见图2)。因此,我们进一步提出生成软伪文本,其中我们直接存储输出令牌分布 d d d,并让 G G G 直接学习重现 d d d。然后我们用以下公式替换公式(1):
L
g
′
=
?
log
?
q
θ
(
x
∣
z
,
y
)
+
K
L
[
p
ψ
(
z
∣
x
,
y
)
∣
∣
q
θ
(
z
∣
y
)
]
,
x
,
y
∈
D
L
,
D
P
L
L'_g = - \log q_{\theta}(x|z, y) + KL[p_{\psi}(z|x, y)||q_{\theta}(z|y)], x, y \in D_L, D_{PL}
Lg′?=?logqθ?(x∣z,y)+KL[pψ?(z∣x,y)∣∣qθ?(z∣y)],x,y∈DL?,DPL?
=
K
L
[
d
∣
∣
q
θ
(
x
∣
z
,
y
)
]
+
K
L
[
p
ψ
(
z
∣
x
,
y
)
∣
∣
q
θ
(
z
∣
y
)
]
,
x
,
y
∈
D
P
T
.
(5)
= KL[d||q_{\theta}(x|z, y)] + KL[p_{\psi}(z|x, y)||q_{\theta}(z|y)], x, y \in D_{PT}.\tag{5}
=KL[d∣∣qθ?(x∣z,y)]+KL[pψ?(z∣x,y)∣∣qθ?(z∣y)],x,y∈DPT?.(5)
- D l D_l Dl?: 表示带标签的数据集(labeled dataset
- D P L D_{PL} DPL?: 表示伪标签数据集(pseudo-labeled dataset)
- D P T D_{PT} DPT?: 这可能指的是伪训练数据集(pseudo-training dataset)
损失函数 L g ′ L'_g Lg′? 被用于调整模型在这三种不同类型的数据上的表现。对于带标签的数据 D l D_l Dl?,模型直接学习匹配真实标签;对于伪标签数据 D P L D_{PL} DPL?,模型可能会利用自身生成的标签来进一步训练;而对于伪训练数据 D P T D_{PT} DPT?,模型可能会在更探索性或正则化的方式下训练,以提高其对于不确定性的处理能力。
这样的SPT充当了一种迭代方式的知识蒸馏。通过这种方式,我们避免了在
d
d
d 中丢失相关的语义信息并减少了所需的样本,进一步扩展了泛化边界。
完整算法在算法1中描述。

-
初始化训练:
- 使用带标签的数据集 D L D_L DL? 对基模型 G G G 和 C C C 进行联合训练。
- 优化公式(3)定义的损失函数。
- 保存最好的模型作为 G 0 G_0 G0? 和 C 0 C_0 C0?。
-
循环训练:
- 对于每个训练周期(epoch),从 1 循环到 MaxEpoch(最大周期数)。
- 对于无标签数据集
D
U
D_U
DU? 中的每个样本
x
i
x_i
xi?:
- 使用上一周期的模型 C epoch ? 1 C_{\text{epoch}-1} Cepoch?1? 来预测其标签 y ^ i \hat{y}_i y^?i?。
- 创建一个伪标签数据集 D P L D_{PL} DPL?,包含无标签数据点 x i x_i xi? 和它们的伪标签 y ^ i \hat{y}_i y^?i?。
-
生成软伪文本:
- 对于属性集
Y
Y
Y 中的每个属性
y
j
y_j
yj?:
- 采样 t t t 个先验 { z k } k = 1 t \{z_k\}_{k=1}^t {zk?}k=1t?,遵循 q θ ( z ∣ y j ) q_{\theta}(z|y_j) qθ?(z∣yj?) 分布。
- 对于每个采样的
z
k
z_k
zk?:
- 计算最长为 MaxLength 的软伪令牌分布 d k m d^m_k dkm?,使用模型 G epoch ? 1 G_{\text{epoch}-1} Gepoch?1? 和公式(4)。
- 将 y k y_k yk? 设置为 y j y_j yj?,建立与 d k m d^m_k dkm? 相关联的标签。
- 创建一个软伪文本数据集 D P T D_{PT} DPT?,包含软伪令牌分布 d k d_k dk? 和它们的标签 y k y_k yk?。
- 对于属性集
Y
Y
Y 中的每个属性
y
j
y_j
yj?:
-
训练更新:
- 使用 D P T D_{PT} DPT?, D P L D_{PL} DPL?,和 D L D_L DL? 对模型 G epoch ? 1 G_{\text{epoch}-1} Gepoch?1?, C epoch ? 1 C_{\text{epoch}-1} Cepoch?1? 进行训练。
- 优化结合了公式(3)和公式(5)定义的损失函数。
- 更新模型参数为 G epoch G_{\text{epoch}} Gepoch? 和 C epoch C_{\text{epoch}} Cepoch?。
-
算法结束:
- 当达到最大训练周期 MaxEpoch 后,训练结束。
通过这种方法,模型在训练过程中不断更新,同时使用生成的伪标签和软伪文本来增强训练,这可能有助于模型在处理无标签数据时提高其性能和泛化能力。伪标签数据 D P L D_{PL} DPL? 和软伪文本数据 D P T D_{PT} DPT? 在这个过程中起到增强学习的作用,它们分别提供了伪标签和文本生成的软输出来训练模型。
理论分析
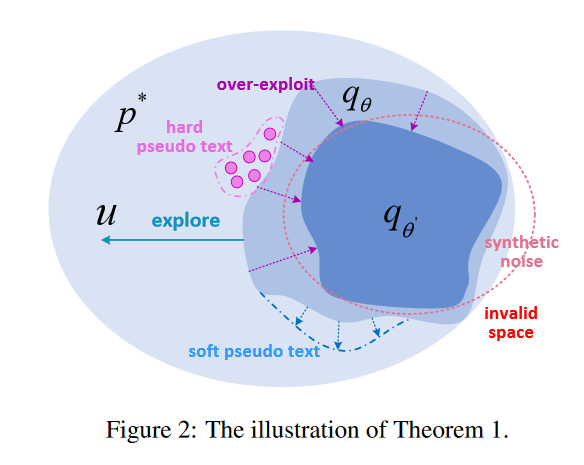
定理1. 优化DuNST的训练目标等价于近似最小化以下上界:
K L [ p ? ∣ ∣ q θ ] + K L [ p θ ′ ∣ ∣ q θ ] + K L [ u ∣ ∣ q θ ] , (6) KL[p^*||q_{\theta}] + KL[p^{\theta'}||q_{\theta}] + KL[u||q_{\theta}],\tag{6} KL[p?∣∣qθ?]+KL[pθ′∣∣qθ?]+KL[u∣∣qθ?],(6)
其中 p ? p^* p? 是真实文本分布, q θ q_{\theta} qθ? 和 q θ ′ q_{\theta'} qθ′? 分别是当前和上一次ST迭代时模型的估计,而 u u u 是噪声分布。
在定理1中,第一个KL项对应于方程(3)的优化,它近似了真实分布。第二个项对应于经典的自训练,它作为一种正则化手段。如图2所示,这种正则化迫使模型拟合已经学习的空间,导致过度利用。最后一个是噪声项,用于增强探索。与各向同性合成噪声(太嘈杂)和硬伪文本(太稀疏)相比,DuNST搭配软伪文本能够探索潜在方向,更平滑地覆盖更大的空间,从而进一步推动边界。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C //练习 6-5 编写函数undef,它将从由lookup和install维护的表中删除一个变量及其定义。
- NodeJs 第三章 文件I/O、文件流
- 三端负电源电压调节器79LXX,具有一系列固定电压输出,适用于小于100mA电源供给的场合
- 自学黑客(网络/信息安全)技术——2024最新
- Java并发基础:深度解析Reentrant可重入性实现
- 《算法通关村——再次透彻理解动态规划》
- 【汽车销售数据】2015~2023年各厂商各车型的探索 数据分析可视化
- 使用Python进行Yolo目标检测的带txt标签进行数据增强
- 评价类问题:层次分析法
- mybatis-plus 动态表SQL解析器